Scalabilità dei piccoli LLM con NVIDIA MPS
I modelli di piccole dimensioni stanno rapidamente diventando più potenti e applicabili in un'ampia varietà di casi d'uso aziendali. Allo stesso tempo, ogni nuova generazione di GPU offre molta più compute e larghezza di banda della memoria. Il risultato? Anche con carichi di lavoro ad alta concorrenza, i piccoli LLM spesso lasciano inutilizzata gran parte della compute e della larghezza di banda della memoria della GPU.
Per casi d'uso come il completamento del codice, il recupero di informazioni, la correzione grammaticale o i modelli specializzati, i nostri clienti aziendali eseguono molti di questi piccoli modelli linguistici su Databricks e noi spingiamo costantemente le GPU al loro limite. Il Multi-Process Service di NVIDIA (MPS) sembrava uno strumento promettente: consente a più processi di inferenza di condividere un singolo contesto GPU, permettendo alle loro operazioni di memoria e compute di sovrapporsi, ricavando di fatto molto più lavoro dallo stesso hardware.
Ci siamo prefissati di testare rigorosamente se l'MPS offra un throughput per GPU più elevato nei nostri ambienti di produzione. Abbiamo riscontrato che l'MPS offre vantaggi significativi in termini di throughput in queste condizioni:
- Modelli linguistici molto piccoli (≤3B di parametri) con contesto da breve a medio (<2k token)
- Modelli linguistici molto piccoli (<3B) in carichi di lavoro di solo prefill
- Engine con un overhead della CPU significativo
La spiegazione chiave, basata sui nostri studi di ablazione, è duplice: a livello di GPU, l'MPS consente una sovrapposizione significativa dei kernel quando i singoli motori lasciano sottoutilizzata la larghezza di banda di compute o di memoria, in particolare durante le fasi a predominanza di attenzione nei modelli di piccole dimensioni; inoltre, come utile effetto collaterale, può anche mitigare i colli di bottiglia della CPU come l'overhead dello scheduler o l'overhead dell'elaborazione delle immagini nei carichi di lavoro multimodali, partizionando il batch totale tra i motori e riducendo il carico della CPU per motore.
Cos'è l'MPS?
Il Multi-Process Service (MPS) di NVIDIA è una funzionalità che consente a più processi di condividere una singola GPU in modo più efficiente, multiplexando i loro kernel CUDA sull'hardware. Come afferma la documentazione ufficiale di NVIDIA:
Il Multi-Process Service (MPS) è un'implementazione alternativa e compatibile a livello binario della CUDA Application Programming Interface (API). L'architettura di runtime MPS è progettata per abilitare in modo trasparente applicazioni CUDA multi-processo cooperative.
In parole più semplici, MPS fornisce un'implementazione CUDA compatibile a livello binario all'interno del driver che consente a più processi (come i motori di inferenza) di condividere la GPU in modo più efficiente. Invece che i processi serializzino l'accesso (lasciando la GPU inattiva tra un turno e l'altro), i loro kernel e le attività operative di memoria vengono sottoposti a multiplexing e sovrapposti dal server MPS quando le risorse sono disponibili.
Lo scenario dello scaling: quando è utile MPS?
In una data configurazione hardware, l'utilizzo effettivo dipende fortemente dalle dimensioni del modello, dall'architettura e dalla lunghezza del contesto. Poiché i recenti modelli linguistici di grandi dimensioni tendono a convergere su architetture simili, utilizziamo la famiglia di modelli Qwen2.5 come esempio rappresentativo per esplorare l'impatto delle dimensioni del modello e della lunghezza del contesto.
Gli esperimenti seguenti hanno confrontato due motori di inferenza identici in esecuzione sulla stessa GPU NVIDIA H100 (con MPS abilitato) con una baseline a istanza singola, utilizzando carichi di lavoro omogenei perfettamente bilanciati.
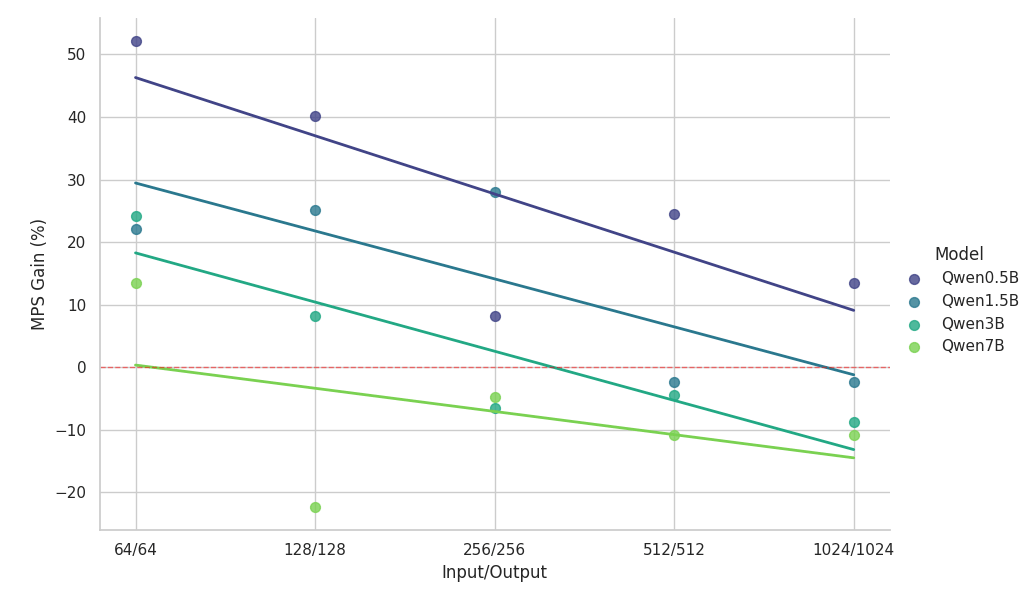
{kind=link}
Osservazioni chiave dallo studio di scalabilità:
- L'MPS offre un aumento del throughput >50% per i modelli di piccole dimensioni con contesti brevi
- I guadagni diminuiscono in modo log-lineare all'aumentare della lunghezza del contesto, a parità di dimensioni del modello.
- I vantaggi si riducono rapidamente all'aumentare delle dimensioni del modello, anche in contesti brevi.
- Per il modello da 7B o il contesto da 2k, il vantaggio scende al di sotto del 10% e alla fine comporta un rallentamento.
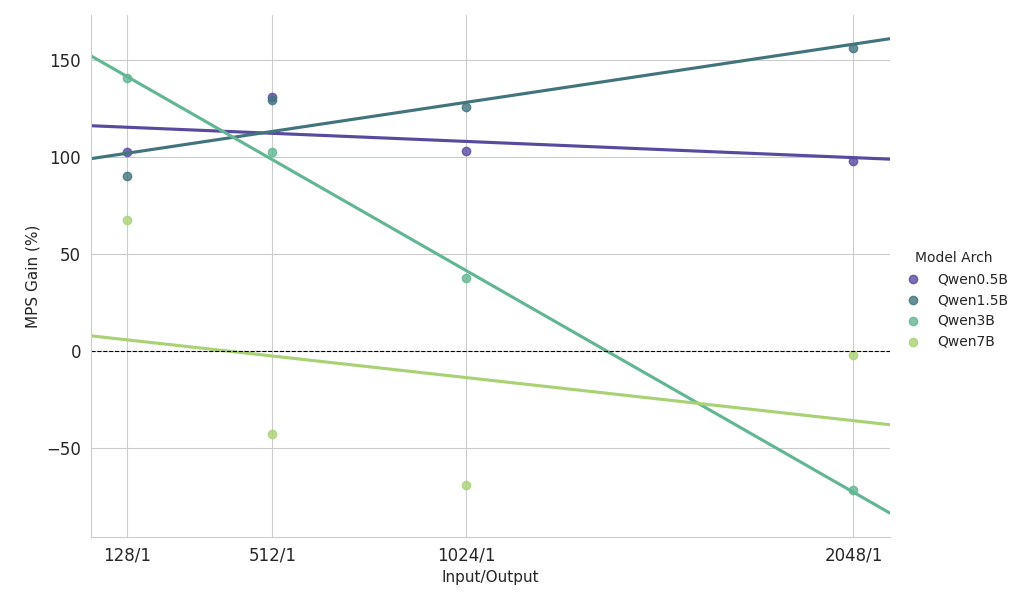
{kind=link}
Osservazioni chiave dallo studio di scaling su un carico di lavoro con prefill intensivo
- Modelli di piccole dimensioni (<3B): l'MPS offre costantemente un miglioramento del throughput superiore al 100%.
- Modelli di medie dimensioni (~3B): i vantaggi diminuiscono all'aumentare della lunghezza del contesto, portando infine a una regressione delle prestazioni.
- Modelli di grandi dimensioni (>3B): MPS non offre alcun vantaggio in termini di prestazioni per modelli di queste dimensioni.
I risultati dello scaling riportati sopra mostrano che i vantaggi di MPS sono più evidenti per configurazioni con un basso utilizzo della GPU, modelli di piccole dimensioni e contesti brevi, che facilitano una sovrapposizione efficace.
Analisi dei vantaggi: da dove provengono realmente i vantaggi di MPS?
Per individuare esattamente il motivo, abbiamo scomposto il problema nei due componenti fondamentali dei moderni transformers: i layer MLP (multi-layer perceptron) e il meccanismo di Attention. Isolando ogni componente (e rimuovendo altri fattori confondenti come l'overhead della CPU), siamo riusciti ad attribuire i guadagni in modo più preciso.
Risorse GPU necessarie | |||
| N = Lunghezza del contesto | Prefill (compute) | Decodifica (larghezza di banda della memoria) | Decodifica (compute) |
| MLP | O(N) | O(1) | O(1) |
| Att. | O(N^2) | O(N) | O(N) |
I Transformer sono costituiti da layer di Attention e MLP con un diverso comportamento di scaling:
- MLP: Carica i pesi una volta; elabora ogni token in modo indipendente -> Larghezza di banda della memoria e compute costanti per token.
- Attention: carica la cache KV e calcola il prodotto scalare con tutti i token precedenti → Larghezza di banda della memoria lineare e calcolo per token.
Tenendo conto di ciò, abbiamo eseguito ablazioni mirate.
Modelli solo MLP (Attention rimossa)
Per i modelli di piccole dimensioni, il layer MLP potrebbe non saturare il compute anche con più token per batch. Abbiamo isolato l'impatto dell'MLP rimuovendo il blocco di attenzione dal modello.
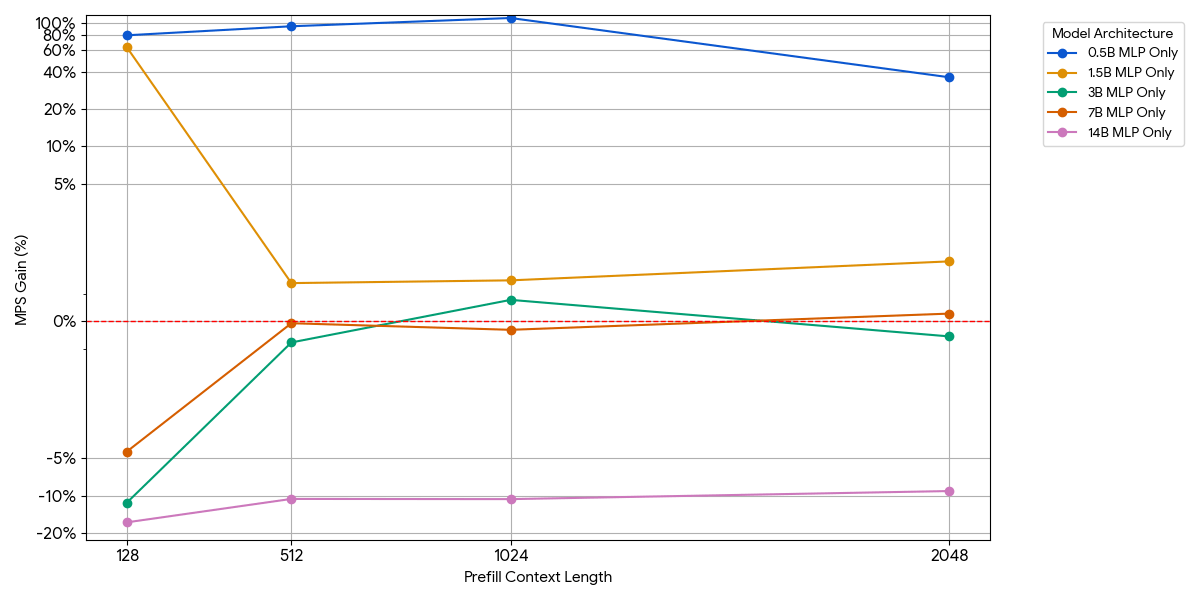
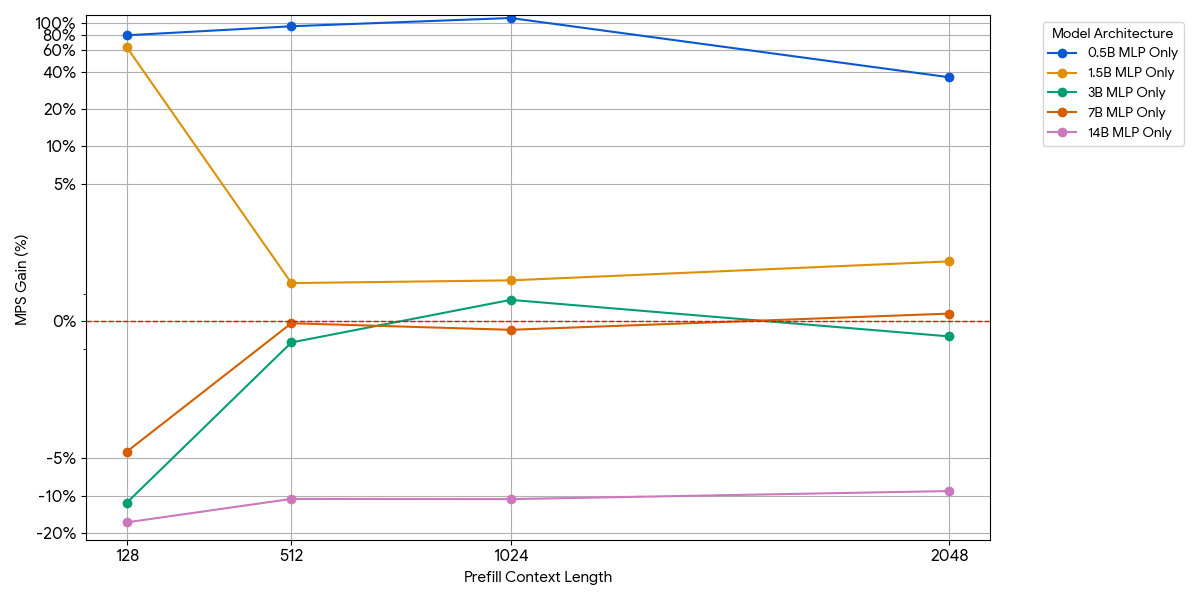{kind=link}
Come mostrato nella figura precedente, i vantaggi sono modesti e svaniscono rapidamente. All'aumentare delle dimensioni del modello o della lunghezza del contesto, un singolo motore satura già il compute (più FLOP per token in MLP più grandi, più token con sequenze più lunghe). Una volta che un motore è vincolato dal compute, l'esecuzione di due motori saturi non offre quasi alcun vantaggio: 1 + 1 <= 1.
Modelli di sola attenzione (MLP rimosso)
Dopo aver riscontrato guadagni limitati dall'MLP, abbiamo preso Qwen2.5-3B e misurato in modo analogo la configurazione solo attention.
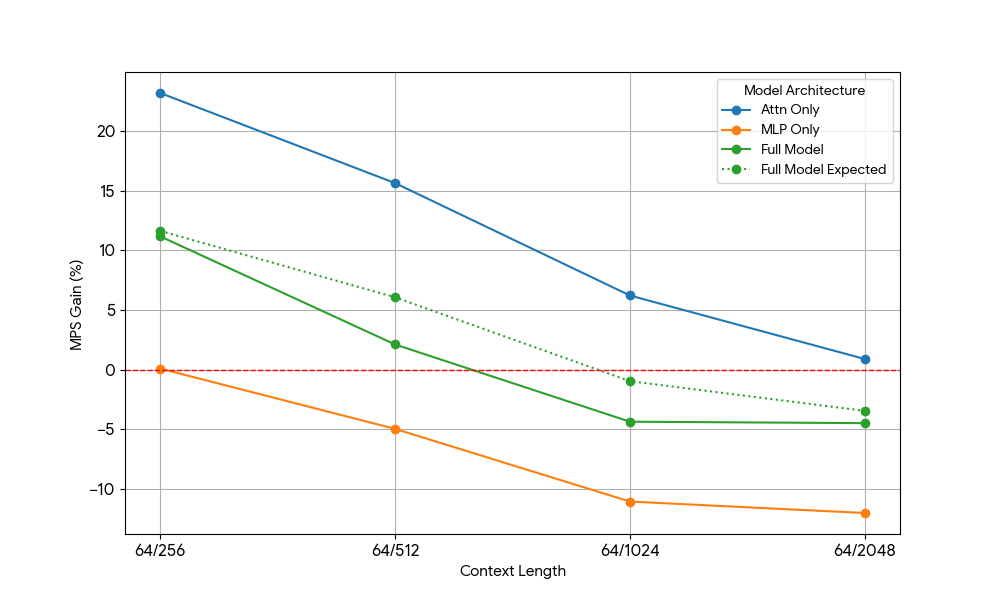
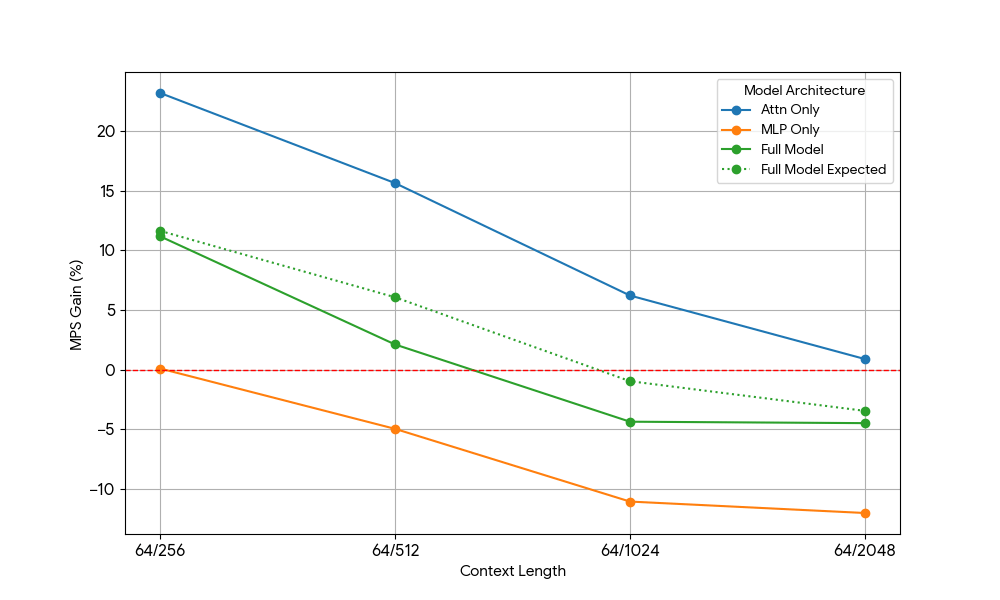{kind=link}
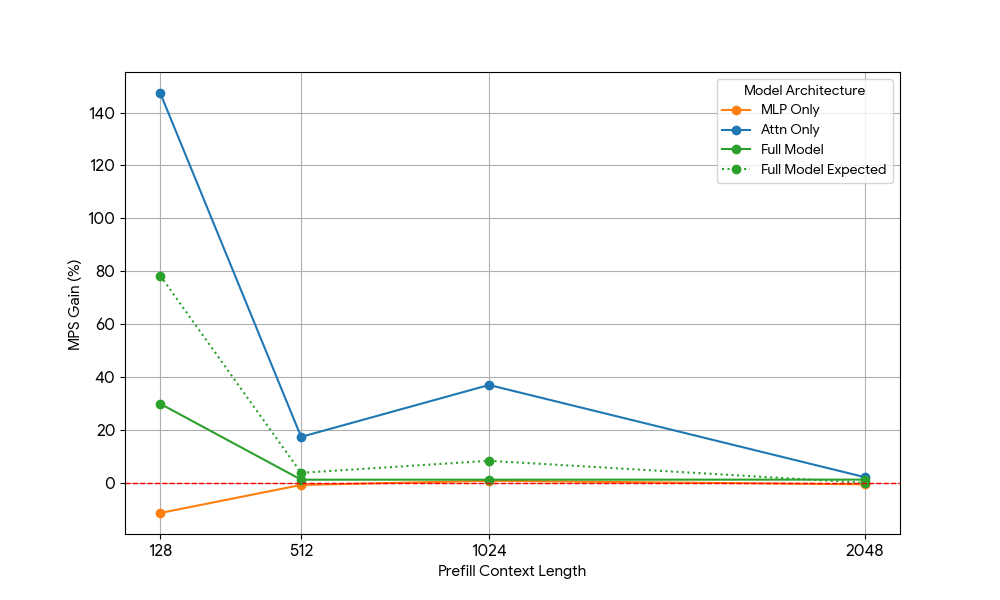
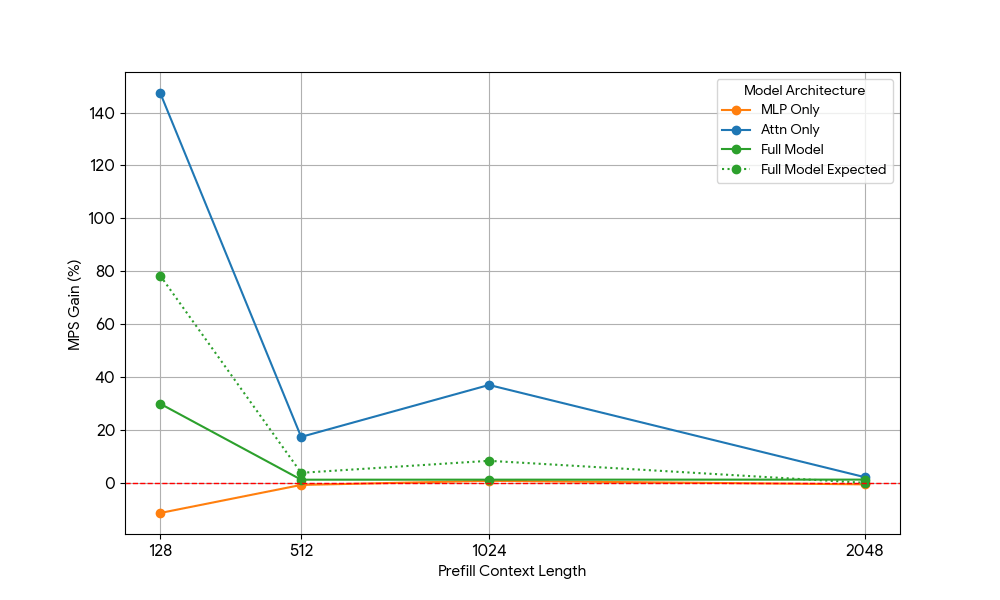{kind=link}
I risultati sono stati sorprendenti:
- I carichi di lavoro di sola attenzione mostrano guadagni MPS significativamente maggiori rispetto al modello completo sia per il prefill che per la decodifica.
- Per la decodifica, i guadagni diminuiscono linearmente con la lunghezza del contesto, il che è in linea con la nostra aspettativa che nella fase di decodifica i requisiti di risorse per l'attention aumentino con la lunghezza del contesto.
- Per il prefill, i guadagni sono calati più rapidamente che per il decode.
Il vantaggio di MPS deriva puramente dai vantaggi di Attention o c'è qualche effetto di sovrapposizione tra Attention e MLP? Per studiare questo fenomeno, abbiamo calcolato il guadagno atteso del modello completo (Full Model Expected Gain) come una media ponderata di solo Attention e solo MLP, con i pesi che rappresentano il loro contributo al tempo di esecuzione (wall time). Questo guadagno atteso del modello completo è sostanzialmente un guadagno derivante puramente dalle sovrapposizioni tra Attn-Attn e MLP-MLP, mentre non tiene conto della sovrapposizione Attn-MLP.
Per il carico di lavoro di decodifica, il guadagno atteso del modello completo è leggermente superiore al guadagno effettivo, il che indica un impatto limitato della sovrapposizione Attn-MLP. Inoltre, per il carico di lavoro di pre-riempimento, il guadagno reale del modello completo è molto inferiore ai guadagni attesi da seq 128; una spiegazione ipotetica potrebbe essere che ci sono meno opportunità di sovrapposizione per il kernel Attention non saturo, poiché l'altro motore impiega una frazione significativa di tempo nell'eseguire MLP saturo. Pertanto, la maggior parte del vantaggio di MPS deriva da 2 motori con Attention non saturo.
Vantaggio bonus: recupero del tempo GPU perso a causa dell'overhead della CPU
Gli studi di ablazione di cui sopra si sono concentrati su carichi di lavoro legati alla GPU, ma la forma più grave di sottoutilizzo si verifica quando la GPU rimane inattiva in attesa del lavoro della CPU, come lo scheduler, la tokenizzazione o la pre-elaborazione delle immagini nei modelli multimodali.
In una configurazione a engine singolo, questi stalli della CPU sprecano direttamente cicli della GPU. Con l'MPS, un secondo engine può prendere il controllo della GPU ogni volta che il primo è bloccato dalla CPU, trasformando i tempi morti in compute produttivo.
Per isolare questo effetto, abbiamo scelto deliberatamente un regime in cui i precedenti vantaggi a livello di GPU erano svaniti: Gemma-4B (una dimensione e una lunghezza di contesto in cui attention e MLP sono già ben saturi, quindi i vantaggi della sovrapposizione dei kernel sono minimi).
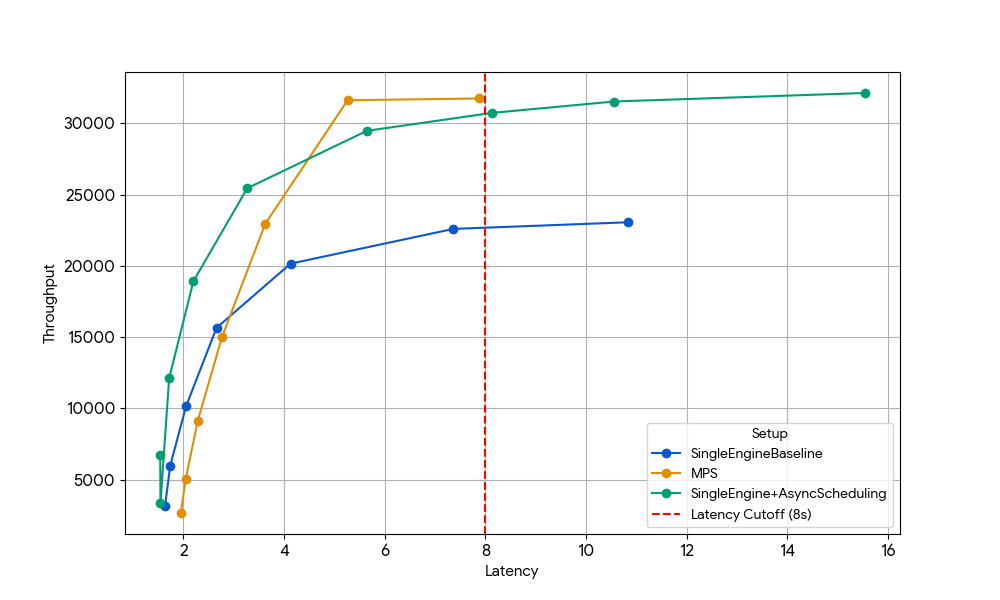
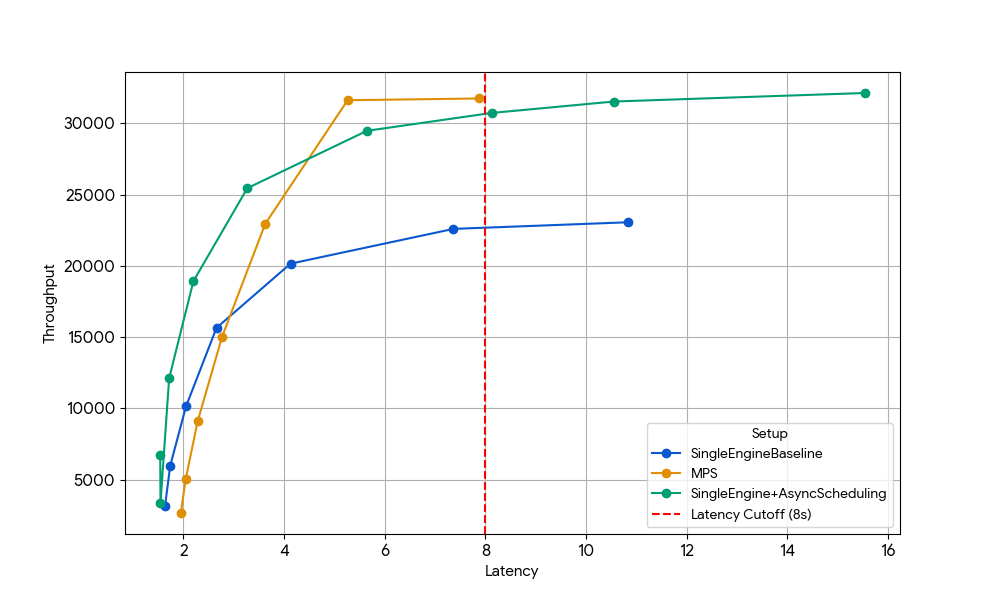{kind=link}
Con una latenza di 8 s, il motore singolo di base (linea blu) è limitato dall'overhead della CPU dello scheduler, limitazione che può essere superata abilitando la pianificazione asincrona in vLLM (linea verde, +33% di throughput) o eseguendo due motori con MPS senza pianificazione asincrona (linea gialla, +35% di throughput). Questo guadagno quasi identico conferma che, in scenari con risorse CPU limitate, MPS può recuperare essenzialmente lo stesso tempo di inattività della GPU che la pianificazione asincrona elimina. MPS può essere utile poiché vLLM v1.0 vanilla presenta ancora un overhead della CPU nel livello dello scheduler, in cui ottimizzazioni come la pianificazione asincrona non sono completamente disponibili.
Una pallottola, non una pallottola d'argento
In base ai nostri esperimenti, MPS può produrre vantaggi significativi per l'inferenza di modelli di piccole dimensioni in alcune zone operative:
- Engine con un overhead della CPU significativo
- Modelli linguistici molto piccoli (≤3B di parametri) con contesto da breve a medio (<2k token)
- Modelli linguistici molto piccoli (<3B) in carichi di lavoro con prefill intensivo
Al di fuori di questi "sweet spot" (ad es. modelli da 7B+, contesto lungo >8k o carichi di lavoro già "compute-bound"), i vantaggi a livello di GPU non possono essere sfruttati facilmente dall'MPS.
D'altra parte, l'MPS ha introdotto anche una complessità operativa:
- Parti mobili aggiuntive: daemon MPS, configurazione dell'ambiente client e un router/load-balancer per suddividere il traffico tra gli engine
- Maggiore complessità di debug: nessun isolamento tra gli engine → una perdita di memoria o un OOM in un engine può danneggiare o terminare tutti gli altri che condividono la GPU
- Onere di monitoraggio: ora dobbiamo monitorare lo stato del daemon, lo stato della connessione del client, il bilanciamento del carico tra i motori, ecc.
- Modalità di errore fragili: poiché tutti i motori condividono un unico contesto CUDA e un unico demone MPS, un singolo client che si comporta in modo anomalo può corrompere o esaurire le risorse dell'intera GPU, con un impatto istantaneo su ogni motore co-locato.
In breve: MPS è uno strumento preciso e specializzato, estremamente efficace nei regimi ristretti descritti sopra, ma raramente rappresenta un vantaggio generalizzato. Ci è piaciuto molto spingere al limite la condivisione della GPU e scoprire dove si trovano i veri e propri baratri prestazionali. C'è ancora un'enorme quantità di prestazioni non sfruttate e di efficienza dei costi nell'intero stack di inferenza. Se sei appassionato di sistemi di serving distribuiti o di far funzionare gli LLM a un costo 10 volte inferiore in produzione, stiamo assumendo!
Autori: Xiaotong Jiang
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.