Semplifica il testing di PySpark con le funzioni di uguaglianza DataFrame
Introduzione alle funzioni di test di uguaglianza di DataFrame di PySpark, perché sono importanti e come usarle.
Le funzioni di test di uguaglianza DataFrame sono state introdotte in Apache Spark™ 3.5 e Databricks Runtime 14.2 per semplificare lo unit test di PySpark. L'insieme completo di funzionalità descritte in questo post del blog sarà disponibile a partire dalle prossime versioni di Apache Spark 4.0 e Databricks Runtime 14.3.
Scrivi trasformazioni DataFrame più affidabili con le funzioni di test di uguaglianza DataFrame
Lavorare con i dati in PySpark implica l'applicazione di trasformazioni, aggregazioni e manipolazioni ai DataFrame. Man mano che le trasformazioni si accumulano, come puoi essere sicuro che il tuo codice funzioni come previsto? Le funzioni di utilità di test di uguaglianza PySpark forniscono un modo efficiente ed efficace per confrontare i tuoi dati con i risultati previsti, aiutandoti a identificare differenze impreviste e a individuare gli errori nelle prime fasi del processo di analisi. Inoltre, restituiscono informazioni intuitive che individuano con precisione le differenze, in modo da poter intervenire immediatamente senza perdere molto tempo nel debug.
Utilizzo delle funzioni di test di uguaglianza DataFrame
Due funzioni di test di uguaglianza per i DataFrame PySpark sono state introdotte in Apache Spark 3.5: assertDataFrameEqual e assertSchemaEqual. Vediamo come usare ciascuna di esse.
assertDataFrameEqual: questa funzione consente di confrontare due DataFrame PySpark per verificarne l'uguaglianza con una sola riga di codice, controllando se i dati e gli schemi corrispondono. Restituisce informazioni descrittive in caso di differenze.
Vediamo un esempio. Innanzitutto, creeremo due DataFrame, introducendo intenzionalmente una differenza nella prima riga:
Quindi chiameremo assertDataFrameEqual con i due DataFrame:
La funzione restituisce un messaggio descrittivo che indica che la prima riga dei due DataFrame è diversa. In questo esempio, i primi importi elencati per Alfred in questa riga non sono gli stessi (previsto: 1500, effettivo: 1200):
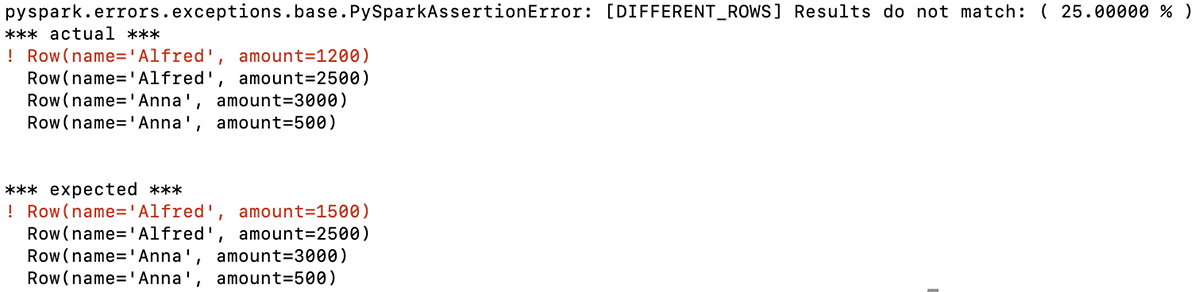
Con queste informazioni, conosci immediatamente il problema con il DataFrame generato dal tuo codice e puoi indirizzare il tuo debug in base a questo.
La funzione ha anche diverse opzioni per controllare la rigidità del confronto DataFrame in modo da poterla adattare in base ai tuoi casi d'uso specifici.
assertSchemaEqual: questa funzione confronta solo gli schemi di due DataFrame; non confronta i dati delle righe. Ti consente di convalidare se i nomi delle colonne, i tipi di dati e la proprietà nullable sono gli stessi per due DataFrame diversi.
Vediamo un esempio. Innanzitutto, creeremo due DataFrame con schemi diversi:
Ora, chiamiamo assertSchemaEqual con questi due schemi DataFrame:
La funzione determina che gli schemi dei due DataFrame sono diversi e l'output indica dove divergono:

In questo esempio, ci sono due differenze: il tipo di dati della colonna amount è LONG nel DataFrame effettivo ma DOUBLE nel DataFrame previsto e, poiché abbiamo creato il DataFrame previsto senza specificare uno schema, anche i nomi delle colonne sono diversi.
Entrambe queste differenze sono evidenziate nell'output della funzione, come illustrato qui.
assertPandasOnSparkEqual non è trattato in questo post del blog poiché è obsoleto da Apache Spark 3.5.1 e la sua rimozione è prevista nella prossima versione di Apache Spark 4.0.0. Per testare l'API Pandas su Spark, vedi Funzioni di test di uguaglianza dell'API Pandas.
Output strutturato per il debug delle differenze nei DataFrame PySpark
Mentre le funzioni assertDataFrameEqual e assertSchemaEqual sono principalmente rivolte allo unit test, in cui in genere si utilizzano set di dati più piccoli per testare le funzioni PySpark, è possibile utilizzarle con DataFrame con più di poche righe e colonne. In tali scenari, puoi recuperare facilmente i dati delle righe per le righe diverse per semplificare ulteriormente il debug.
Vediamo come fare. Useremo gli stessi dati che abbiamo usato in precedenza per creare due DataFrame:
E ora prenderemo i dati che differiscono tra i due DataFrame dagli oggetti di errore di asserzione dopo aver chiamato assertDataFrameEqual:
La creazione di un DataFrame basato sulle righe diverse e la sua visualizzazione, come abbiamo fatto in questo esempio, illustra quanto sia facile accedere a queste informazioni:

Come puoi vedere, le informazioni sulle righe diverse sono immediatamente disponibili per ulteriori analisi. Non devi più scrivere codice per estrarre queste informazioni dai DataFrame effettivi e previsti a scopo di debug.
Questa funzionalità sarà disponibile a partire dalle prossime versioni di Apache Spark 4.0 e DBR 14.3.
Funzioni di test di uguaglianza dell'API Pandas su Spark
Oltre alle funzioni per testare l'uguaglianza dei DataFrame PySpark, gli utenti dell'API Pandas su Spark avranno accesso alle seguenti funzioni di test di uguaglianza DataFrame:
assert_frame_equalassert_series_equalassert_index_equal
Le funzioni forniscono opzioni per controllare la rigidità dei confronti e sono ottime per lo unit test dell'API Pandas sui DataFrame Spark. Forniscono esattamente la stessa API delle funzioni di utilità di test di pandas, quindi puoi usarle senza modificare il codice di test pandas esistente che desideri eseguire utilizzando l'API Pandas su Spark.
Ecco un paio di esempi che dimostrano l'uso di assert_frame_equal con parametri diversi, confrontando l'API Pandas sui DataFrame Spark:
In questo esempio, gli schemi dei due DataFrame sono diversi. L'output della funzione elenca le differenze, come mostrato qui:

Possiamo specificare che vogliamo che la funzione confronti i dati delle colonne anche quando le colonne non hanno lo stesso tipo di dati usando l'argomento check_dtype, come in questo esempio:
Poiché abbiamo specificato che assert_frame_equal deve ignorare i tipi di dati delle colonne, ora considera i due DataFrame uguali.
Queste funzioni consentono anche confronti tra oggetti API Pandas su Spark e oggetti pandas, facilitando i controlli di compatibilità tra diverse librerie DataFrame, come illustrato in questo esempio:
L'utilizzo delle nuove funzioni di test di uguaglianza DataFrame PySpark e API Pandas su Spark è un ottimo modo per assicurarsi che il tuo codice PySpark funzioni come previsto. Queste funzioni ti aiutano non solo a individuare gli errori, ma anche a capire esattamente cosa è andato storto, consentendoti di identificare rapidamente e facilmente dove si trova il problema. Dai un'occhiata alla pagina Testing PySpark per maggiori informazioni.
Queste funzioni saranno disponibili a partire dalla prossima versione di Apache Spark 4.0. DBR 14.2 lo supporta già.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.