Smetti di codificare manualmente le pipeline di Change Data Capture
Come AutoCDC automatizza CDC e Dimensioni a Variazione Lenta
di Matt Jones, Zoé Durand, Phoebe Weiser, Bilal Aslam e Ray Zhu
- Perché le pipeline CDC e SCD codificate manualmente sono fragili, complesse e costose da gestire su larga scala
- Come AutoCDC automatizza in modo dichiarativo i pattern CDC basati su SCD di Tipo 1, SCD di Tipo 2 e snapshot
- Guadagni reali in termini di correttezza, prestazioni e costi derivanti dai carichi di lavoro AutoCDC in produzione
Ho provato AutoCDC da Snapshots in Python e sono rimasto stupito da come 4 righe di codice potessero sostituire quello che prima facevo in 1.500 righe di codice. —Senior Data Engineer, Fortune 500 Aerospace & Defense Company
Change data capture (CDC) e slowly changing dimensions (SCD) sono fondamentali per i moderni carichi di lavoro di analytics e AI. I team si affidano a loro per mantenere accurate le tabelle downstream man mano che i dati operativi cambiano, sia che ciò significhi mantenere una visione attuale del business o preservare il contesto storico completo.
Eppure, in pratica, le pipeline CDC sono spesso tra le più difficili da costruire e gestire. I team creano regolarmente complesse logiche MERGE personalizzate per gestire aggiornamenti, eliminazioni e dati in arrivo in ritardo: stratificando tabelle di staging, funzioni finestra e ipotesi di sequenziamento che sono difficili da comprendere e ancora più difficili da mantenere man mano che le pipeline evolvono.
In questo post, esamineremo i pattern CDC e SCD che data engineer e professionisti SQL incontrano ogni giorno, perché questi pattern sono difficili da implementare manualmente e come AutoCDC in Lakeflow Spark Declarative Pipelines li automatizza in modo dichiarativo, offrendo al contempo miglioramenti significativi in termini di prezzo e prestazioni.
CDC e SCD sono ancora difficili per i data engineer
Anche per i team che comprendono bene questi pattern, farli funzionare correttamente e mantenerli tali nel tempo è dove le cose si complicano. Man mano che i volumi di dati crescono e i casi d'uso si espandono, le pipeline diventano fragili; i problemi di correttezza emergono tardi; e anche piccole modifiche richiedono attente riscritture per evitare di corrompere le tabelle downstream.
Mantenimento delle tabelle SCD di tipo 1
Le tabelle SCD di tipo 1 sovrascrivono le righe esistenti per riflettere lo stato più recente. Anche questo caso "semplice" incontra rapidamente delle sfide:
- Gli aggiornamenti arrivano fuori sequenza
- Gli eventi duplicati devono essere deduplicati in modo coerente
- Le eliminazioni devono essere applicate correttamente
- La logica deve rimanere idempotente durante i tentativi e i riprocessamenti
Ciò che spesso inizia come un semplice MERGE INTO si evolve in una logica profondamente nidificata con tabelle di staging, funzioni finestra e ipotesi di sequenziamento difficili da comprendere (o da modificare in sicurezza). Nel tempo, i team diventano riluttanti a toccare queste pipeline.
Mantenimento della cronologia SCD di tipo 2
SCD di tipo 2 introduce ulteriore complessità:
- Tracciamento delle versioni delle righe e delle finestre di validità
- Gestione degli aggiornamenti in arrivo in ritardo senza corrompere la cronologia
- Garantire che esista sempre una sola versione "corrente" in un dato momento
Gli errori qui non sempre si manifestano in modo evidente. Spesso emergono settimane dopo come sottili derive metriche, o la necessità di ricostruire interamente le tabelle storiche.
Estrazione dei dati di modifica da diverse origini
Non tutti i sistemi emettono log CDC puliti. Alcuni sistemi emettono feed di dati di modifica nativi, mentre altri no - spesso perché il team che consuma i dati non controlla il database upstream - costringendo i team a ricostruire le modifiche confrontando snapshot successivi di una tabella di origine.
Il supporto per entrambi richiede tipicamente logiche di ingestione ed elaborazione separate; diverse ipotesi di correttezza; e più percorsi di codice da mantenere e debuggare.
Gestione delle pipeline CDC nel tempo
Anche una volta che una pipeline CDC è corretta, deve comunque sopravvivere a riprocessamenti e backfill, evoluzione dello schema, guasti e riavvii. La logica CDC creata manualmente tende a diventare più fragile nel tempo man mano che queste realtà si accumulano, aumentando il rischio operativo e i costi di manutenzione.
Automazione di complessi pattern CDC con data engineering dichiarativo
AutoCDC è stato progettato per standardizzare questi comuni pattern CDC e SCD dietro un'astrazione dichiarativa. Invece di codificare manualmente *come* le modifiche devono essere applicate, i team dichiarano *quali semantiche* desiderano, e la piattaforma gestisce l'ordinamento, lo stato e l'elaborazione incrementale.
| Carico di lavoro CDC | AutoCDC | Logica MERGE / Snapshot scritta manualmente |
|---|---|---|
| Mantenimento delle tabelle di stato corrente (SCD Tipo 1) | La definizione dichiarativa della pipeline gestisce automaticamente sequenziamento, deduplicazione ed eliminazioni | Logica MERGE personalizzata con funzioni finestra e regole di sequenziamento |
| Mantenimento delle tabelle storiche (SCD Tipo 2) | Gestione automatica delle versioni con tracciamento della cronologia integrato | Logica MERGE in più passaggi per chiudere e inserire versioni dei record |
| Inferenza delle modifiche da origini snapshot | Supporto CDC snapshot integrato | Pipeline di confronto snapshot manuali con join e confronti |
| Gestione affidabile delle pipeline nel tempo (dati in ritardo, tentativi, riprocessamento) | Ordinamento automatico ed esecuzione idempotente | Richiede salvaguardie personalizzate e logica aggiuntiva |
| Impronta di codice e complessità operativa | Circa 6-10 righe di definizione dichiarativa della pipeline | 40-200+ righe di logica di pipeline personalizzata |
Ciò offre ai team un modo coerente e ripetibile per implementare CDC e SCD attraverso le pipeline, anziché reinventare il pattern ogni volta (che è il valore fondamentale della programmazione dichiarativa in generale, e di Spark Declarative Pipelines in particolare).
Quando si elaborano record di modifica da un feed di dati di modifica (CDF), AutoCDC gestisce automaticamente i record fuori sequenza e applica correttamente gli aggiornamenti in base a una colonna di sequenza dichiarata. Per mostrare come funziona in pratica, consideriamo il feed CDC di esempio di seguito:
| userId | name | city | operation | sequenceNum |
|---|---|---|---|---|
| 124 | Raul | Oaxaca | INSERT | 1 |
| 123 | Isabel | Monterrey | 1 | 1 |
| 125 | Mercedes | Tijuana | INSERT | 2 |
| 126 | Lily | Cancun | INSERT | 2 |
| 123 | null | null | DELETE | 6 |
| 125 | Mercedes | Guadalajara | UPDATE | 6 |
| 125 | Mercedes | Mexicali | UPDATE | 5 |
| 123 | Isabel | Chihuahua | UPDATE | 5 |
Ricorda, dovresti scegliere SCD Tipo 1 per mantenere solo i dati più recenti, o scegliere SCD Tipo 2 per mantenere i dati storici. Iniziamo con il Tipo 1.
Automazione del mantenimento SCD Tipo 1 (origini feed dati di modifica)
In questo esempio, un feed di dati di modifica contiene inserimenti, aggiornamenti ed eliminazioni per una tabella utente. L'obiettivo è mantenere una visione corrente di ogni record, dove i nuovi aggiornamenti sovrascrivono i valori precedenti.
Tabella di output per SCD Tipo 1
| id | name | city |
|---|---|---|
| 124 | Raul | Oaxaca |
| 125 | Mercedes | Guadalajara |
| 126 | Lily | Cancun |
L'utente 123 (Isabel) è stato eliminato, quindi non appare nell'output. L'utente 125 (Mercedes) mostra solo l'ultima città (Guadalajara) perché SCD Tipo 1 sovrascrive i valori precedenti.
Con un approccio tradizionale, ciò richiede una logica MERGE personalizzata per deduplicare gli eventi, imporre l'ordinamento, applicare le eliminazioni e garantire che la pipeline rimanga corretta tra i tentativi o i dati in arrivo in ritardo. AutoCDC sostituisce questa logica fragile con una definizione di pipeline dichiarativa che gestisce automaticamente sequenziamento, deduplicazione, dati in arrivo in ritardo ed elaborazione incrementale, eliminando decine di righe di logica di merge personalizzata.
Vedi l'esempio di codice completo in appendice
Automazione della cronologia SCD Tipo 2 (origini feed dati di modifica)
In molti sistemi analitici, mantenere solo lo stato più recente non è sufficiente: i team necessitano di una cronologia completa di come i record cambiano nel tempo. Questo è il pattern SCD Tipo 2, in cui ogni versione di un record viene archiviata con finestre di validità che indicano quando era attiva.
Tabella di output per SCD tipo 2:
| id | name | city | __START_AT | __END_AT |
|---|---|---|---|---|
| 123 | Isabel | Monterrey | 1 | 5 |
| 123 | Isabel | Chihuahua | 5 | 6 |
| 124 | Raul | Oaxaca | 1 | NULL |
| 125 | Mercedes | Tijuana | 2 | 5 |
| 125 | Mercedes | Mexicali | 5 | 6 |
| 125 | Mercedes | Guadalajara | 6 | NULL |
| 126 | Lily | Cancun | 2 | NULL |
La tabella conserva la cronologia completa. L'utente 123 ha due versioni (terminate alla sequenza 6 quando eliminato). L'utente 125 ha tre versioni che mostrano le modifiche alla città. I record con __END_AT = NULL sono attualmente attivi.
L'implementazione manuale richiede una logica MERGE in più passaggi per chiudere i record precedenti, inserire nuove versioni e garantire che una sola versione rimanga attiva alla volta. AutoCDC automatizza queste transizioni in modo dichiarativo, gestendo automaticamente le colonne di cronologia e la logica di versioning, garantendo al contempo la correttezza anche quando gli aggiornamenti arrivano fuori ordine.
Vedi l'esempio di codice completo in appendice
Inferire la CDC dalle origini snapshot
Non tutti i sistemi di origine emettono log di modifica. In molti casi, i team ricevono snapshot periodici di una tabella di origine e devono dedurre cosa è cambiato tra un'esecuzione e l'altra.
Tradizionalmente, ciò richiede il confronto manuale degli snapshot per rilevare inserimenti, aggiornamenti ed eliminazioni prima di applicare tali modifiche con la logica MERGE. AutoCDC tratta la CDC basata su snapshot come un pattern di prima classe, rilevando automaticamente le modifiche a livello di riga tra gli snapshot e applicandole in modo incrementale senza richiedere logica di diff personalizzata o gestione dello stato.
L'implementazione manuale richiede il rilevamento delle modifiche a livello di riga tra gli snapshot, la chiusura dei record precedentemente attivi e l'inserimento di nuove versioni con finestre di validità aggiornate. AutoCDC deriva automaticamente queste modifiche e applica la semantica SCD Type 2, mantenendo la cronologia delle versioni senza richiedere logica di merge in più passaggi o tracciamento personalizzato dello stato dello snapshot.
Gestione dell'ordinamento, dello stato e del riprocessamento
Lakeflow Spark Declarative Pipelines traccia automaticamente i progressi incrementali e gestisce i dati fuori sequenza. Le pipeline possono recuperare da errori, rielaborare dati storici ed evolvere nel tempo senza applicare duplicati o perdere modifiche.
In pratica, ciò elimina la necessità per i team di gestire autonomamente la logica di sequenziamento, la gestione dei watermark o la sicurezza del riprocessamento: la piattaforma se ne occupa.
Novità: importanti guadagni di prezzo e prestazioni
Oltre a semplificare la logica delle pipeline, i recenti miglioramenti di Databricks Runtime hanno portato sostanziali guadagni sia in termini di prestazioni che di efficienza dei costi per i carichi di lavoro AutoCDC, a partire da novembre 2025:
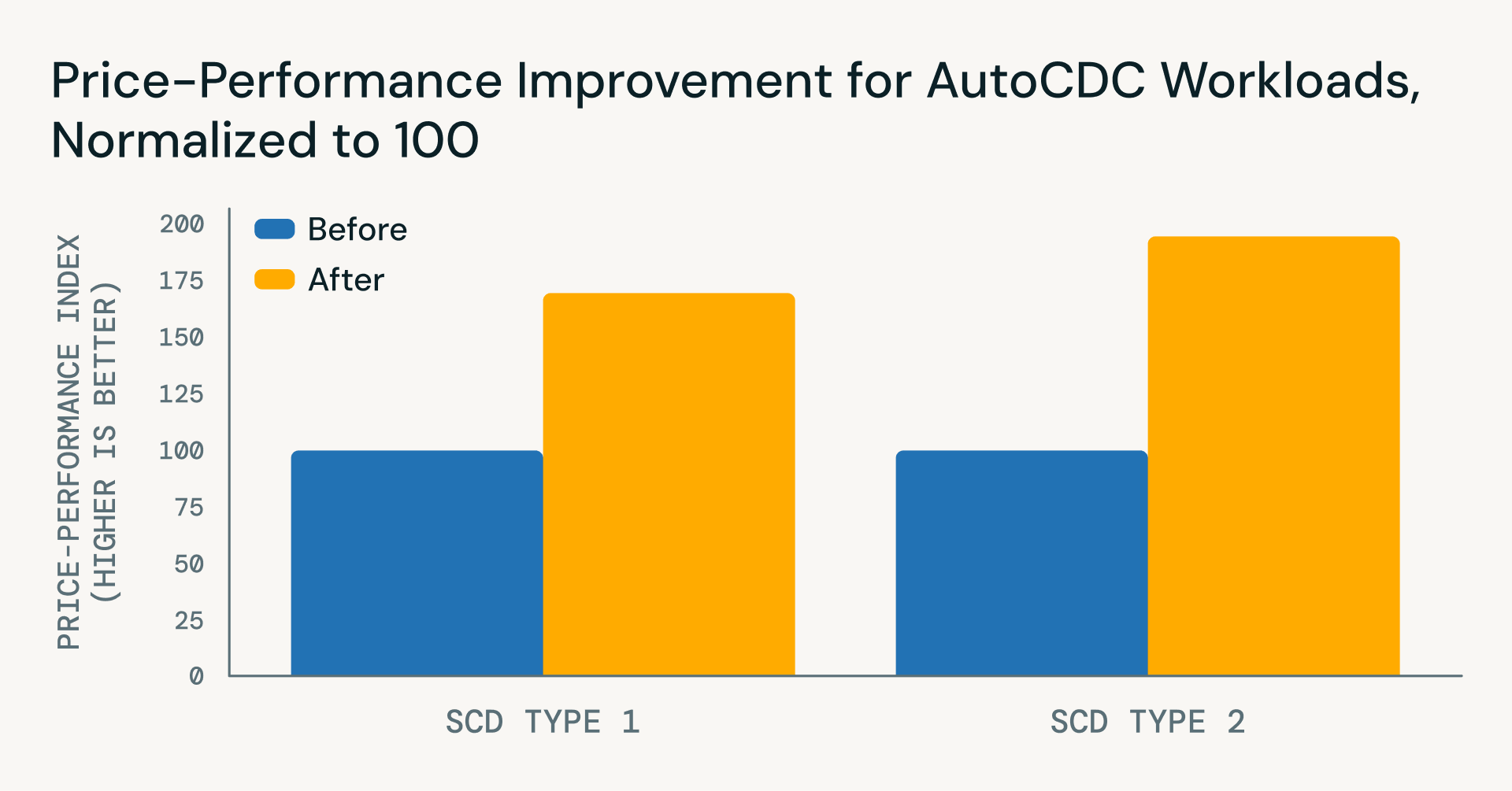
- SCD Type 1
- ~22% di miglioramento della latenza
- ~40% di riduzione dei costi
- ~71% di beneficio netto in termini di rapporto prezzo-prestazioni
- SCD Type 2
- ~45% di riduzione della latenza
- ~35% di riduzione dei costi per gli aggiornamenti incrementali
- ~96% di beneficio netto in termini di rapporto prezzo-prestazioni
Questi guadagni sono importanti per le pipeline reali che vengono eseguite continuamente su larga scala. Mentre MERGE INTO rimane un primitivo fondamentale di Spark, AutoCDC si basa su di esso per gestire i dati fuori sequenza e l'elaborazione incrementale in modo più efficiente all'aumentare dei volumi di dati.
Successo dei clienti con AutoCDC
I team che eseguono pipeline CDC e SCD in produzione hanno citato esplicitamente AutoCDC come fornitore di valore significativo:
Navy Federal Credit Union utilizza AutoCDC in Lakeflow Spark Declarative Pipelines per alimentare l'elaborazione di eventi su larga scala in tempo reale, gestendo miliardi di eventi applicativi continuamente, eliminando al contempo il codice CDC personalizzato e la manutenzione continua delle pipeline.
La semplicità del modello di programmazione Spark Declarative Pipelines, unita alle sue capacità di servizio, ha portato a un tempo di turnaround incredibilmente rapido. —Jian (Miracle) Zhou, Senior Engineering Manager, Navy Federal Credit Union
Block utilizza AutoCDC in Lakeflow Spark Declarative Pipelines per semplificare la cattura dei dati di modifica e le pipeline di streaming in tempo reale su Delta Lake, sostituendo il codice CDC e la logica di merge scritti a mano con un approccio dichiarativo rapido da implementare e facile da gestire.
Con l'adozione di Spark Declarative Pipelines, il tempo necessario per definire e sviluppare una pipeline di streaming è passato da giorni a ore. —Yue Zhang, Staff Software Engineer, Data Foundations, Block
Valora Group, un importante fornitore svizzero di "foodvenience", utilizza AutoCDC in Lakeflow Spark Declarative Pipelines per semplificare la cattura dei dati di modifica per i dati anagrafici e l'analisi in tempo reale del retail, sostituendo il codice CDC personalizzato con un approccio dichiarativo facile da implementare, ripetere e scalare tra i team.
Abbiamo ottenuto molto facendo CDC in SDP, perché non si scrive codice, è tutto astratto in background. AutoCDC minimizza il numero di righe... è così facile da fare. —Alexane Rose, Data and AI Architect, Valora Holding
Inizia
AutoCDC è disponibile come parte di Lakeflow Spark Declarative Pipelines su Databricks.
Per saperne di più:
- Consulta la documentazione AutoCDC (SQL e Python)
- Esplora esempi per SCD Type 1, SCD Type 2 e CDC basata su snapshot
Prova AutoCDC nelle tue pipeline ed elimina la logica CDC scritta a mano!
Appendice
Esempio SCD Type 1
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import max_by, struct
# Deduplica: mantieni il record più recente per userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Applica SCD Type 1: upsert aggiornamenti, elimina eliminazioni
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(updates.alias("s"), "s.userId = t.userId")
.whenMatchedDelete(condition="s.operation = 'DELETE'")
.whenMatchedUpdate(
condition="s.sequenceNum > t.sequenceNum",
set={"name": "s.name", "city": "s.city", "sequenceNum": "s.sequenceNum"}
)
.whenNotMatchedInsertAll(condition="s.operation != 'DELETE'")
.execute())
| from pyspark import pipelines as dp
from pyspark.sql.functions import col, expr
@dp.view
def users():
return spark.readStream.table("cdc_data.users")
dp.create_streaming_table("target")
dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=1
)
|
Esempio SCD Type 2
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import col, lit, max_by, struct
# Deduplica: mantieni il record più recente per userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Passaggio 1: chiudi le righe attive per i record che vengono aggiornati o eliminati
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(
updates.alias("s"),
"s.userId = t.userId AND t.__END_AT IS NULL AND s.sequenceNum > t.__START_AT"
)
.whenMatchedUpdate(set={"__END_AT": "s.sequenceNum"})
.execute())
# Passaggio 2: inserisci nuove righe per inserimenti e aggiornamenti (non eliminazioni)
new_rows = (updates
.filter("operation != 'DELETE'")
.withColumn("__START_AT", col("sequenceNum"))
.withColumn("__END_AT", lit(None).cast("long"))
.drop("operation"))
new_rows.write.mode("append").saveAsTable("target")
| dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=2
)
|
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.