Risposte alle 10 domande più frequenti su Databricks Clean Rooms
Collaborazione sui dati incentrata sulla privacy e semplificata con Databricks Clean Rooms
- Collabora con i partner su dati sensibili senza esporre i record grezzi.
- Usa Delta Sharing per importare dati esterni, come Snowflake o BigQuery, in una Clean Room.
- Supporta casi d'uso tra cui risoluzione dell'identità, pubblicità, sanità e finanza.
La collaborazione sui dati è la spina dorsale dell'innovazione moderna nel campo dell'AI, specialmente quando le organizzazioni collaborano con partner esterni per ottenere nuove informazioni dettagliate. Tuttavia, la privacy dei dati e la protezione della proprietà intellettuale rimangono sfide importanti per consentire la collaborazione e al contempo salvaguardare i dati sensibili.
Per colmare questo divario, i clienti di tutti i settori utilizzano le Clean Room di Databricks per eseguire analisi condivise su dati sensibili e consentire una collaborazione che metta la privacy al primo posto.
Di seguito abbiamo raccolto le 10 domande più frequenti sulle Clean Room. Questi illustrano cosa sono le Clean Room, come proteggono i dati e la proprietà intellettuale (IP), come funzionano su più cloud e piattaforme e cosa serve per iniziare. Iniziamo subito.
1. Che cos'è una “data clean room”?
Una data clean room è un ambiente sicuro in cui tu e i tuoi partner potete lavorare insieme su dati sensibili per estrarre informazioni dettagliate utili, senza condividere i dati grezzi sensibili sottostanti.
In Databricks, si crea una clean room, si aggiungono gli asset che si desidera utilizzare e si eseguono solo notebook approvati all'interno di un ambiente isolato, sicuro e governato.

2. Quali sono alcuni esempi di casi d'uso delle clean room?
Le clean room sono utili quando più parti devono analizzare dati sensibili senza condividere i propri dati grezzi. Ciò è spesso dovuto a normative sulla privacy, contratti o alla tutela della proprietà intellettuale.
Sono utilizzati in molti settori industriali, tra cui pubblicità, sanità, finanza, settore pubblico, trasporti e monetizzazione dei dati.
Alcuni esempi includono:
Pubblicità e marketing: risoluzione dell'identità senza esporre PII, pianificazione e misurazione delle campagne, monetizzazione dei dati per i retail media e collaborazione tra brand.
- Partner come Epsilon, The Trade Desk, Acxiom, LiveRamp e Deloitte utilizzano le clean room di Databricks per la risoluzione dell'identità.
Servizi finanziari: Banche, assicuratori e società di carte di credito combinano i dati per migliorare le attività operative, il rilevamento delle frodi e l'analisi.
- Esempi: Mastercard utilizza le clean room per abbinare e analizzare i dati PII per il rilevamento delle frodi; Intuit abbina in modo sicuro i dati dei richiedenti prestiti con quelli degli istituti di credito per trovare richiedenti idonei.
Le clean room proteggono i dati dei clienti, consentendo al contempo la collaborazione e l'arricchimento dei dati.
3. Quali tipi di data asset è possibile condividere in una clean room?
Puoi condividere una vasta gamma di asset gestiti da Unity Catalog in Databricks Clean Rooms:
- Tabelle (gestite, esterne e federate): dati strutturati come transazioni, eventi o profili cliente.
- Viste: sezioni filtrate o aggregate delle tue tabelle.
- Volumi: file come immagini, audio, documenti o librerie di codice private.
- Notebook: Notebook SQL o Python che definiscono l'analisi che vuoi eseguire.
Ecco come appare in pratica:
- Un retailer, un marchio CPG e una società di ricerche di mercato condividono viste anonimizzate che includono: ID cliente con hash, metriche di vendita aggregate e dati demografici regionali per analizzare congiuntamente la copertura della campagna.
- Una piattaforma di streaming e un'agenzia pubblicitaria condividono tabelle di impression delle campagne e un notebook che calcola le metriche sul pubblico multipiattaforma.
- Una banca e un partner fintech condividono volumi contenenti modelli di ML per il rischio e le frodi e usano un notebook per eseguire lo scoring congiunto dei modelli, mantenendo privati i singoli record.
4. Quali sono le differenze rispetto a Delta Sharing? Perché dovrei usare una clean room invece?
Mettiamola così: Delta Sharing è la scelta giusta quando una delle parti necessita di un accesso di sola lettura ai dati nel proprio ambiente e può visualizzare i record sottostanti.
Le Clean Room aggiungono uno spazio sicuro e controllato per l'analisi di più parti quando i dati devono rimanere privati. I partner possono unire gli asset di dati, eseguire codice approvato reciprocamente e restituire solo gli output che tutte le parti concordano. Questo è utile quando devi rispettare rigide garanzie di privacy o supportare flussi di lavoro regolamentati. Infatti, i dati condivisi nelle Clean Room utilizzano ancora il protocollo Delta Sharing dietro le quinte.
Ad esempio, un rivenditore potrebbe utilizzare Delta Sharing per fornire a un fornitore l'accesso in sola lettura a una tabella delle vendite, in modo che possa vedere l'andamento delle vendite dei prodotti. Le stesse due parti utilizzerebbero una Clean Room quando devono unire dati più ricchi e sensibili da entrambe le parti (come le caratteristiche dei clienti o l'inventario dettagliato), eseguire notebook approvati e condividere solo output aggregati come le previsioni della domanda o gli articoli a maggior rischio.
5. Come vengono protetti i dati sensibili e la proprietà intellettuale (IP) nella clean room?
Le Clean Room sono progettate in modo che i tuoi partner non vedano mai i tuoi dati grezzi o la tua proprietà intellettuale. I tuoi dati rimangono nel tuo Unity Catalog e condividi solo asset specifici nella clean room tramite Delta Sharing, il tutto controllato da notebook approvati.
Per applicare queste protezioni in una clean room:
- I collaboratori vedono solo gli schemi (nomi e tipi di colonne), non i dati effettivi a livello di riga.
- Solo i Notebook approvati da te e dai tuoi partner possono essere eseguiti su un ambiente di compute serverless in un ambiente isolato.
- I Notebook scrivono in tabelle di output temporanee, così puoi controllare esattamente cosa esce dalla clean room.
- Il traffico di rete in uscita è limitato tramite i controlli di uscita serverless (SEG).
- Per proteggere la proprietà intellettuale o il codice proprietario, puoi confezionare la tua logica come libreria privata, archiviarla in un volume di Unity Catalog e fare riferimento ad essa nei Notebook della camera bianca senza rivelare il codice sorgente.
6. I collaboratori su cloud diversi possono accedere alla stessa clean room?
Sì. Le Clean Room sono progettate per la collaborazione multicloud e cross-region, a condizione che ogni partecipante disponga di un'area di lavoro abilitata per Unity Catalog e che Delta Sharing sia abilitato sul proprio metastore. Ciò significa che un'organizzazione che utilizza Databricks su Azure può collaborare in una clean room con partner su AWS o GCP.
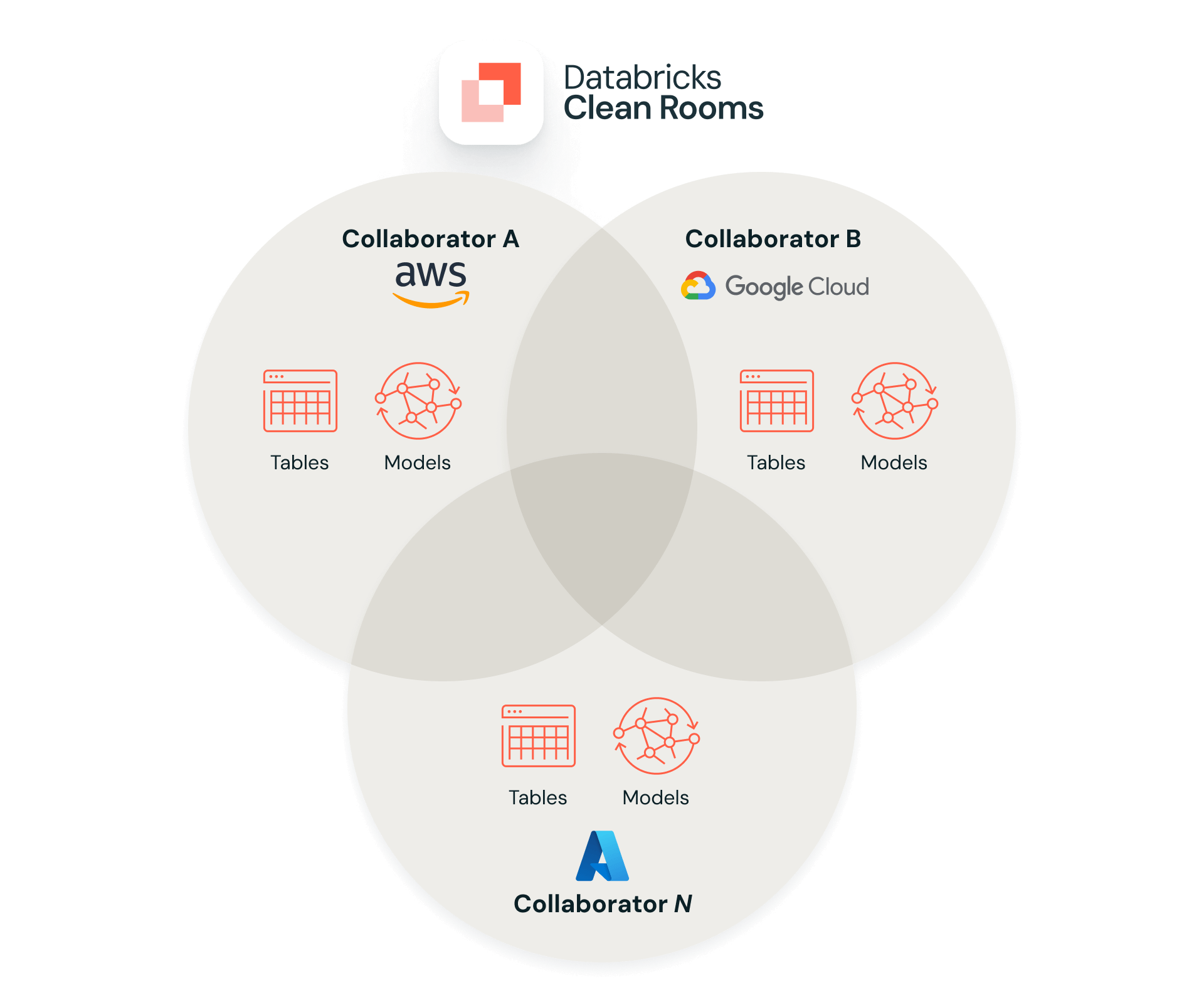
7. Posso importare dati da Snowflake, BigQuery o altre piattaforme in una clean room?
Sì, assolutamente. Lakehouse Federation espone sistemi esterni come Snowflake, BigQuery e warehouse tradizionali come cataloghi esterni in Unity Catalog (UC). Una volta che le tabelle esterne sono disponibili in UC, puoi condividerle nella clean room nello stesso modo in cui condividi qualsiasi altra tabella o vista.
Ecco come funziona a grandi linee: utilizzi Lakehouse Federation per creare connessioni e cataloghi esterni che espongono sorgenti di dati esterne in Unity Catalog, senza dover copiare tutti i dati in Databricks. Una volta che queste tabelle esterne sono disponibili in Unity Catalog, puoi condividerle in una Clean Room proprio come qualsiasi altra tabella o vista gestita da Unity Catalog.
8. Come si esegue un'analisi personalizzata su dati congiunti?
All'interno di una clean room, si fa quasi tutto tramite i notebook. Si aggiunge un notebook SQL o Python che include il codice per l'analisi desiderata, i partner esaminano e approvano il notebook, che a quel punto può essere eseguito.

Un caso semplice: si potrebbe avere un notebook SQL che conta gli ID con hash sovrapposti tra gli acquisti di un retailer e le impression di un media partner, per poi restituire i dati di reach, frequency e conversion.
Più avanzato: si utilizza un notebook Python per unire le feature di entrambe le parti, addestrare un modello o eseguirne lo scoring sui dati combinati e scrivere le previsioni in una tabella di output. Il runner approvato vede gli output, ma nessuno vede i record grezzi dell'altra parte.
9. Come funziona la collaborazione tra più parti?
In una Clean Room di Databricks è possibile far collaborare fino a 10 organizzazioni (la tua più 9 partner) in un unico ambiente sicuro, anche se si trovano su cloud o piattaforme di dati diversi. Ogni team conserva i dati nel proprio Unity Catalog e condivide solo le tabelle, le viste o i file specifici che desidera utilizzare nella camera bianca.
Una volta che tutti hanno aderito, ciascuna parte può proporre notebook SQL o Python e tali notebook devono essere approvati prima di essere eseguiti, in modo che tutte le parti siano a proprio agio con la logica.
10. Ottimo, sembra tutto chiaro. Come posso iniziare?
Ecco un modo semplice per iniziare:
- Verifica che il tuo workspace abbia abilitato Unity Catalog, Delta Sharing e serverless compute.
- Crea un oggetto Clean Room nel tuo metastore di Unity Catalog e invita i tuoi partner con i loro identificatori di condivisione.
- Ciascuna parte aggiunge gli asset di dati e i notebook su cui desidera collaborare.
- Una volta che tutti approvano i notebook, esegui l'analisi e rivedi gli output nel tuo metastore.
Guarda questo video per saperne di più sulla creazione di Clean Room e su come iniziare.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.