Sbloccare gli archivi: trasformare documenti non strutturati in un database ricercabile per la scoperta delle acque sotterranee
In che modo Databricks for Good ha aiutato MapAid a sfruttare l'AI per trasformare gli archivi statici in un motore di ricerca operativo per la crisi idrica del Sudan
- MapAid ha collaborato con Databricks for Good per classificare e catalogare quasi 700 documenti idrogeologici scansionati, trasformando una raccolta non strutturata in un database ricercabile.
- Utilizzando l'AI multimodale, il team ha creato una pipeline serverless che classifica i documenti ed estrae informazioni relative all'acqua direttamente dalle immagini delle pagine scansionate.
- Ora i ricercatori possono individuare studi storici rilevanti in pochi secondi e accedere ai registri dei pozzi che alimentano direttamente i modelli di previsione delle acque sotterranee di MapAid, favorendo migliori risultati di perforazione.
Introduzione
In tutto il Sudan, le comunità dipendono dalle acque sotterranee per l'acqua potabile, l'irrigazione e la sopravvivenza, ma la perforazione di un pozzo produttivo è tutt'altro che garantita. La geologia è complessa, gli acquiferi variano notevolmente e una perforazione fallita può costare migliaia di dollari. Decenni di indagini geologiche e relazioni sul campo contengono i dati necessari per migliorare i risultati, ma queste informazioni sono rimaste disperse in vari archivi e non sono mai state organizzate in modo sistematico, risultando invisibili per le persone che ne hanno più bisogno.
MapAid è un'organizzazione non profit fondata alla Stanford University la cui missione è consentire agli attori umanitari e dello sviluppo, principalmente in Africa, di prendere decisioni basate sui dati attraverso la mappatura potenziata dall'AI. Il loro strumento di punta, l'app WellMapr (gratuita), utilizza l'AI e i dati geospaziali per identificare le zone con acque sotterranee poco profonde, guidando le perforazioni a basso costo per l'acqua potabile e l'irrigazione dei piccoli agricoltori. Un input fondamentale per questi modelli è rappresentato dai dati storici su pozzi, perforazioni e geologia degli acquiferi.
La Sudan Association for Archiving Knowledge (SUDAAK) conserva una delle raccolte più ricche di questi dati: quasi 700 PDF, TIFF e JPG scansionati per un totale di oltre 5.000 pagine di indagini geologiche, relazioni sulla perforazione di pozzi e studi sul campo, disponibili pubblicamente su wossac.com. Tuttavia, la disponibilità non equivale all'accessibilità. Un ricercatore alla ricerca di dati sulle perforazioni in una zona specifica del Sudan dovrebbe esaminare manualmente centinaia di documenti. I dati sono stati digitalizzati, ma senza un sistema di recupero sono rimasti inutilizzati.
Classificazione dei documenti scansionati con l'AI multimodale
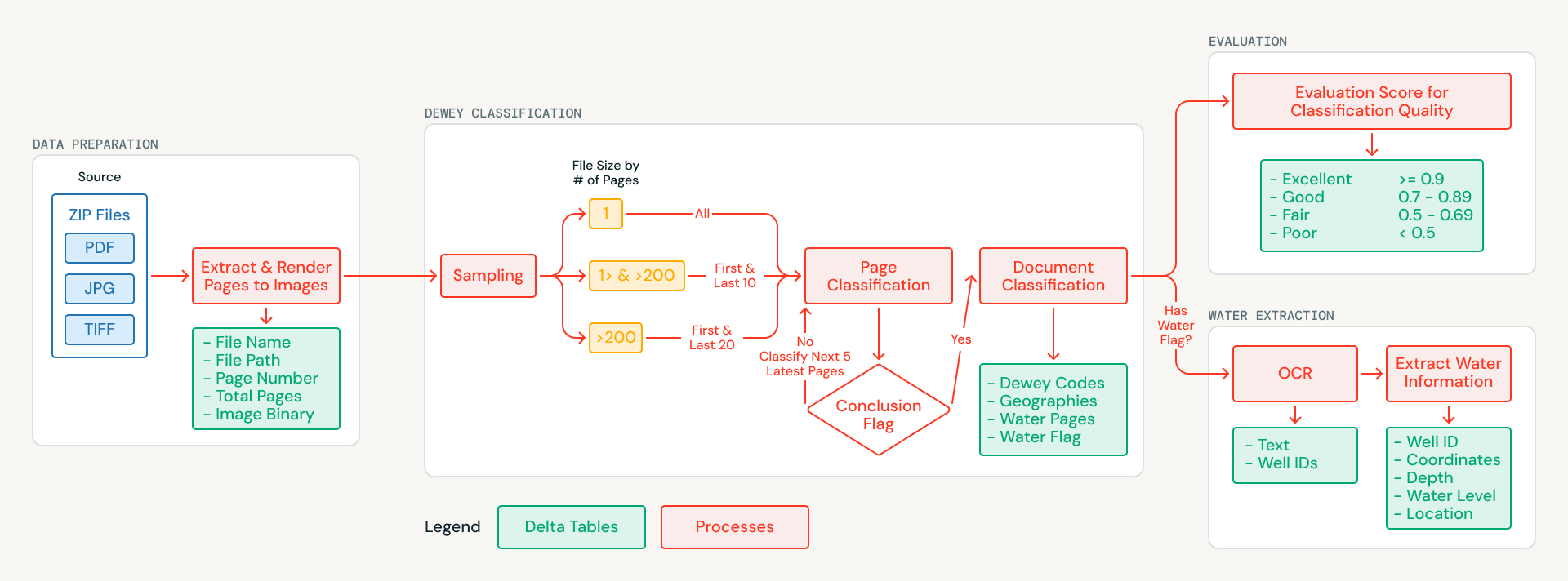
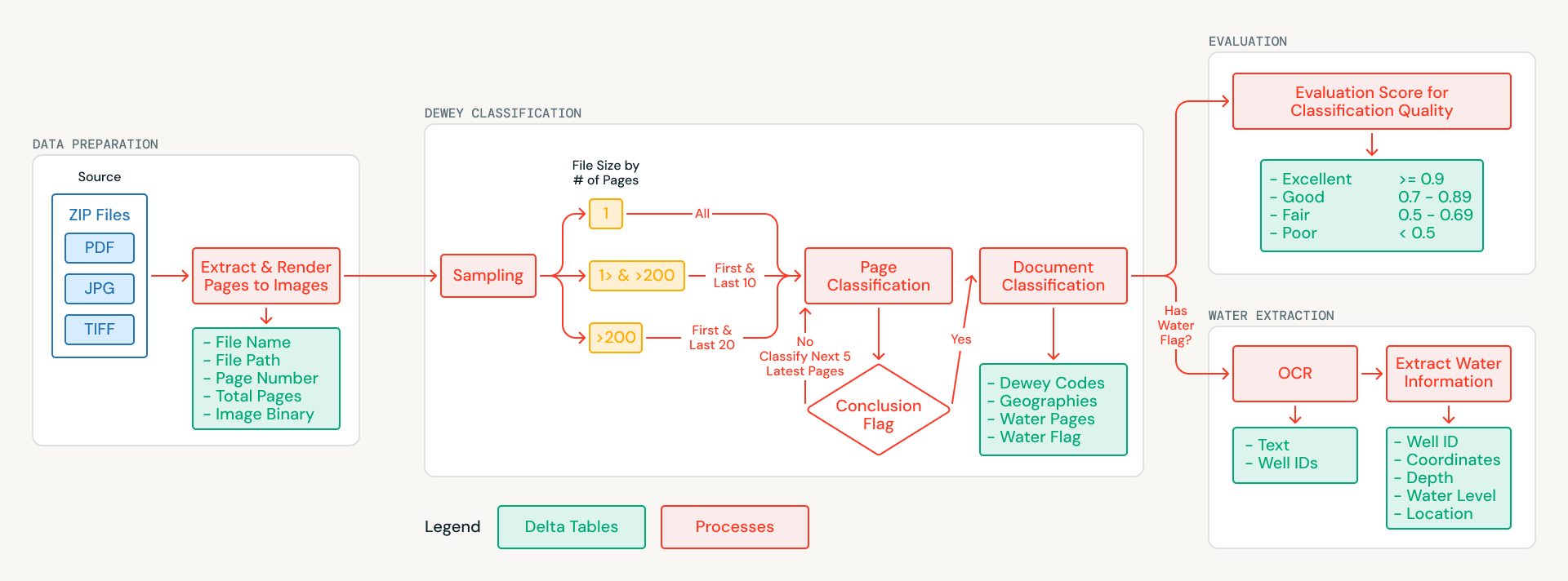
Databricks ha collaborato con MapAid per creare una pipeline basata sull'AI che classifica ogni documento dell'archivio, lo tagga con metadati geografici e tematici ed estrae record strutturati di pozzi e perforazioni dai documenti relativi all'acqua. Il sistema viene eseguito interamente su Databricks ed è pacchettizzato per il deployment con un singolo comando. Questo articolo illustra l'approccio tecnico e come questo possa essere esteso a qualsiasi organizzazione che desideri estrarre conoscenze strutturate da grandi raccolte di documenti scansionati non strutturati.
L'archivio presentava sfide che escludevano l'estrazione di testo tradicional. I documenti sono scansioni di relazioni cartacee, risalenti a molti decenni fa, prive di un livello di testo incorporato. Alcune pagine sono storte, altre combinano inglese e arabo, e molte includono note sul campo scritte a mano. Invece di tentare l'OCR come primo passo, il team ha riformulato il problema come una questione di comprensione visiva: inviare le immagini delle pagine scansionate direttamente a modelli di AI multimodale in grado di interpretare visivamente il contenuto.
Le pagine di ciascun documento vengono renderizzate come immagini e memorizzate nei volumi di Unity Catalog, creando un dataset fondamentale pulito e sottoposto a controllo di versione. Da lì, una strategia di campionamento intelligente riduce i costi di elaborazione: i documenti più brevi vengono analizzati interamente, mentre per i documenti più lunghi vengono campionate le sezioni più informative (frontespizi, introduzioni e conclusioni). Questo ha ridotto il volume di elaborazione dell'AI di oltre il 70% preservando al contempo la qualità della classificazione.
Ogni pagina campionata viene analizzata utilizzando le Databricks AI Functions (ai_query), che supportano nativamente input multimodali e output JSON strutturati. Il modello esamina l'immagine di ogni pagina e restituisce:
- Codici di classificazione decimale Dewey, il sistema universale di classificazione delle biblioteche
- Aree geografiche del Sudan citate nel contenuto
- Un flag di rilevanza idrica che indica se la pagina contiene dati su pozzi, perforazioni o acquiferi
Poiché le AI Functions vengono eseguite direttamente all'interno di SQL, il team ha potuto iterare sui prompt e sugli schemi di output senza dover creare un'infrastruttura di model serving separata. I risultati a livello di pagina vengono aggregati in classificazioni a livello di documento, producendo un catalogo strutturato e ricercabile in cui ogni documento è taggato con l'argomento trattato e l'area di applicazione.
{kind=link}
Estrazione di record strutturati di pozzi e perforazioni
Molti dei documenti contrassegnati come rilevanti per l'acqua contengono esattamente il tipo di informazioni strutturate da cui dipendono i modelli WellMapr di MapAid: ubicazione dei pozzi, profondità di perforazione, misurazioni della falda acquifera e tassi di rendimento. Queste informazioni sono spesso distribuite all'interno del documento, con le coordinate che appaiono in una sezione, le misurazioni della profondità in un'altra e i dati sul rendimento in una tabella riassuntiva diverse pagine dopo. Estrarre e collegare questi dati era un obiettivo centrale della collaborazione.
Per ogni documento rilevante per l'acqua, la pipeline elabora ogni pagina anziché solo il sottoinsieme campionato utilizzato per la classificazione. L'OCR viene eseguito pagina per pagina utilizzando un modello multimodale servito tramite le Foundation Model API, che gestiscono l'inglese, l'arabo e layout complessi, comprese note sul campo scritte a mano, dati tabulari e pagine in formato misto. Durante l'OCR, il sistema applica anche un approccio di riconoscimento delle entità, identificando gli identificatori di pozzi e perforazioni come entità di ancoraggio, in modo che i record che si estendono su più pagine possano essere ricollegati a un unico sito.
Il testo estratto da tutte le pagine viene unito in una rappresentazione unificata del documento, che viene poi elaborata in un secondo passaggio per estrarre record strutturati in formato JSON che acquisiscono nomi dei siti, coordinate GPS, profondità di perforazione, livelli statici dell'acqua e rendimenti dei test di pompaggio. Le Databricks AI Functions impongono risposte vincolate allo schema, garantendo che questi attributi vengano acquisiti in modo coerente anche quando appaiono in formati o sezioni diversi all'interno del documento. Il risultato è un insieme di record strutturati di pozzi e perforazioni pronti per l'integrazione diretta nei modelli di previsione WellMapr di MapAid.
Valutazione automatizzata della qualità su scala
La convalida manuale di centinaia di classificazioni idrogeologiche specializzate richiederebbe risorse significative e una profonda competenza nel settore. Invece di trattare la valutazione come una fase separata da eseguire a posteriori, il team ha integrato la valutazione automatizzata della qualità direttamente nella pipeline come fase di primaria importanza. Un modello di AI separato, chiamato anch'esso tramite AI Functions, funge da giudice: valuta ogni classificazione in base a una rubrica strutturata che copre accuratezza, completezza e coerenza. Per ogni documento, il valutatore confronta i codici decimali Dewey assegnati e i tag geografici con il contenuto della pagina campionata, verificando se le classificazioni sono supportate da ciò che il modello ha effettivamente osservato.
Ogni valutazione produce sia una classificazione categoriale (eccellente, buona, discreta o insufficiente) sia una giustificazione scritta che spiega il punteggio, creando una traccia verificabile per ogni decisione presa dalla pipeline. I documenti con un punteggio inferiore a una soglia di confidenza vengono contrassegnati per la revisione manuale, indirizzando il limitato sforzo umano verso i casi in cui è più importante. Nella prima esecuzione completa, solo una piccola frazione di classificazioni ha richiesto l'attenzione umana.
Distribuzione di una soluzione autonoma su Databricks
Un progetto come questo tocca ogni livello dello stack di dati e AI: archiviazione dei file, data engineering, inferenza AI, parsing dell'output strutturato, valutazione della qualità e governance. Databricks ha fornito tutto questo all'interno di un unico workspace. I file di archivio grezzi sono memorizzati nei volumi di Unity Catalog e tutti gli output della pipeline sono scritti in tabelle Delta Lake con affidabilità ACID, evoluzione dello schema e data lineage completo. La pipeline è orchestrata come un Lakeflow Job su un'elaborazione serverless, quindi MapAid paga solo per ciò che consuma ogni esecuzione.
L'intero sistema è pacchettizzato come Databricks Asset Bundle, il che significa che può essere distribuito, aggiornato ed eseguito con un singolo comando. MapAid ha ricevuto una soluzione autonoma che può essere gestita senza competenze specifiche su più servizi cloud. Poiché la logica della pipeline è disaccoppiata dallo specifico archivio che elabora, lo stesso sistema potrebbe essere adattato ad altri archivi idrici, ad altre regioni o ad altri settori in cui grandi raccolte di documenti scansionati devono essere classificate e rese ricercabili.
Cosa significa questo sul campo
Nella sua prima esecuzione completa, la pipeline ha fornito:
- 654 documenti e 5.570 pagine classificati
- Completato in meno di tre ore
- Il 95% delle classificazioni è stato valutato come "eccellente" o "buono" dal valutatore automatico
- Circa il 50% dell'archivio è stato identificato come contenente dati relativi all'acqua
- 299 record strutturati di pozzi e trivellazioni estratti con nomi delle località, profondità e misurazioni della portata
La pipeline ha ridotto quello che avrebbe richiesto settimane o mesi agli esperti del settore in un processo che si completa in poche ore. Ora l'archivio può essere consultato per classificazione, area geografica o presenza di dati sull'acqua. Ogni record estratto con coordinate e dati sulla profondità alimenta direttamente le previsioni sulle acque sotterranee di MapAid, supportando tassi di successo di perforazione più elevati e una fornitura d'acqua più rapida alle comunità bisognose.
Mentre SUDAAK continua a digitalizzare nuovi documenti, la pipeline può elaborare ogni nuovo batch con un singolo comando, garantendo che il catalogo rimanga aggiornato man mano che l'archivio cresce. Il lavoro di MapAid copre l'Africa orientale, inclusi Etiopia e Malawi, e archivi simili non classificati esistono in tutto il continente. La metodologia e l'infrastruttura sono pronte per essere scalate.
Rupert Douglas-Bate, Chief Executive Officer (CEO) di MapAid, ha condiviso la seguente prospettiva sulla partnership: "Il nostro sistema di AI in evoluzione, WellMapr, ha lo scopo di rivoluzionare la ricerca e la localizzazione a basso costo di fonti idriche sotterranee sostenibili, ma ha bisogno di dati sui pozzi d'acqua. La nostra missione per raggiungere questo obiettivo è stata notevolmente accelerata dalla collaborazione con Databricks for Good, che si è messa in contatto con noi tramite il Rotary International. Il progetto Databricks for Good è stato fondamentale per sviluppare la nostra Online Water Library (OWL) con il supporto della Sudan Association for Archiving Knowledge (SUDAAK). Il team di Databricks ha aiutato a trasformare un grande archivio disorganizzato di dati storici su acqua e suolo del Sudan in un sistema strutturato che utilizza la classificazione decimale Dewey. Questo ci consente di identificare rapidamente i dati sui pozzi d'acqua sotterranei sostenibili a un costo contenuto, che ora possono essere utilizzati per aiutare a sviluppare il nostro algoritmo WellMapr. MapAid è lieta di utilizzare OWL come uno strumento di sviluppo vitale per mitigare la siccità, dimostrando che quando i partner giusti si allineano, possiamo ottenere l' 'impossibile' per chi ne ha più bisogno."
Scopri di più su alcuni degli altri nostri progetti pro bono qui sotto:
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.