Che cos'è un Resilient Distributed Dataset (RDD)?
Comprendere la struttura dati fondamentale di Spark per l'elaborazione parallela distribuita e tollerante agli errori
- Scopri cosa sono gli RDD e come funzionano come raccolte di dati immutabili e partizionate per l'elaborazione parallela in Apache Spark.
- Scopri i cinque scenari chiave in cui gli RDD sono la scelta giusta, inclusi dati non strutturati e controllo delle trasformazioni di basso livello.
- Esplora la relazione tra gli RDD e i DataFrame e i Dataset e quando utilizzare ciascuna API.
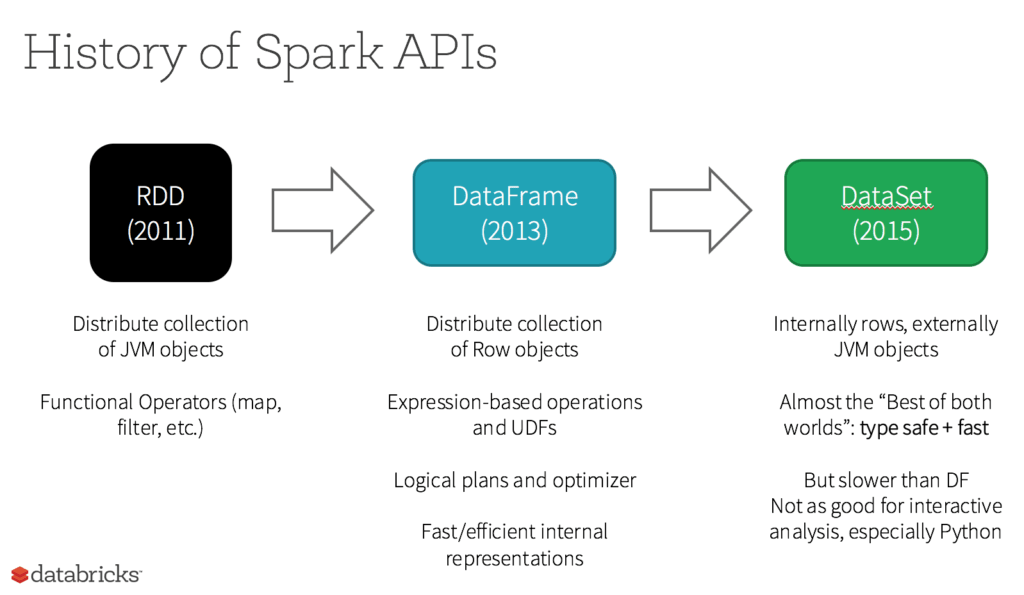
Fin dalla sua concezione, RDD è stata la principale API di Spark rivolta all'utente. In sostanza, un RDD è una raccolta distribuita e immutabile di elementi dei tuoi dati, partizionata tra i nodi di clusters, che può essere gestita in parallelo con un'API di basso livello che offre trasformazioni e azioni.
5 motivi per utilizzare gli RDD:
- vuoi eseguire trasformazioni e azioni di basso livello e controllare il tuo set di dati;
- vuoi operare con dati non strutturati, come flussi multimediali o flussi di testo;
- vuoi manipolare i dati con costrutti di programmazione funzionali anziché con espressioni specifiche del dominio;
- non ti interessa imporre uno schema, come ad esempio il formato a colonne, durante l'elaborazione o l'accesso agli attributi dei dati per nome o colonna;
- puoi a rinunciare ad alcuni dei vantaggi in termini di ottimizzazione e prestazioni disponibili con DataFrames e a set di dati per dati strutturati e semi-strutturati.
Il playbook sull'AI agentiva per l'enterprise

Cosa succede agli RDD in Apache Spark 2.0?
Gli RDD sono relegati a un ruolo secondario? Sono diventati obsoleti? Assolutamente no! La novità è che puoi passare da DataFrame o set di dati a RDD tramite semplici chiamate di metodo API, in qualunque momento ciò si renda necessario, e che DataFrame e set di dati sono basati su RDD.
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.