Una storia di tre API Apache Spark: RDD, DataFrame e Dataset
Quando usarli e perché
di Jules Damji
Tra le gioie degli sviluppatori, nessuna è più allettante di un set di API che li rendano produttivi, facili da usare, intuitive ed espressive. Uno dei punti di forza di Apache Spark per gli sviluppatori sono state le sue API facili da usare, per operare su grandi set di dati, in diverse lingue: Scala, Java, Python e R.
In questo blog, esploro tre set di API—RDD, DataFrame e Dataset—disponibili in Apache Spark 2.2 e versioni successive; perché e quando dovresti usare ciascun set; ne delineo i benefici in termini di prestazioni e ottimizzazione; ed elenco scenari in cui usare DataFrame e Dataset invece di RDD. Principalmente, mi concentrerò su DataFrame e Dataset, perché in Apache Spark 2.0, queste due API sono state unificate.
La nostra principale motivazione dietro questa unificazione è la nostra ricerca di semplificare Spark limitando il numero di concetti che devi imparare e offrendo modi per elaborare dati strutturati. E attraverso la struttura, Spark può offrire astrazioni di livello superiore e API come costrutti di linguaggio specifici del dominio.
Resilient Distributed Dataset (RDD)
RDD è stata l'API principale rivolta agli utenti in Spark fin dalla sua nascita. Al centro, un RDD è una raccolta distribuita immutabile di elementi dei tuoi dati, partizionata tra i nodi del tuo cluster che possono essere elaborati in parallelo con un'API di basso livello che offre trasformazioni e azioni.
Quando usare gli RDD?
Considera questi scenari o casi d'uso comuni per l'utilizzo degli RDD quando:
- desideri trasformazioni e azioni di basso livello e controllo sul tuo set di dati;
- i tuoi dati non sono strutturati, come flussi multimediali o flussi di testo;
- vuoi manipolare i tuoi dati con costrutti di programmazione funzionale piuttosto che espressioni specifiche del dominio;
- non ti preoccupa imporre uno schema, come un formato colonnare, durante l'elaborazione o l'accesso agli attributi dei dati per nome o colonna; e
- puoi rinunciare ad alcuni benefici di ottimizzazione e prestazioni disponibili con DataFrame e Dataset per dati strutturati e semi-strutturati.
Cosa succede agli RDD in Apache Spark 2.0?
Potresti chiedere: gli RDD vengono relegati a cittadini di seconda classe? Vengono deprecati?
La risposta è un sonoro NO!
Inoltre, come noterai di seguito, puoi passare senza problemi da DataFrame o Dataset a RDD a tuo piacimento—tramite semplici chiamate di metodi API—e DataFrame e Dataset sono costruiti sopra gli RDD.
DataFrames
Come un RDD, un DataFrame è una raccolta distribuita immutabile di dati. A differenza di un RDD, i dati sono organizzati in colonne nominate, come una tabella in un database relazionale. Progettato per rendere l'elaborazione di grandi set di dati ancora più facile, DataFrame consente agli sviluppatori di imporre una struttura su una raccolta distribuita di dati, consentendo astrazioni di livello superiore; fornisce un'API di linguaggio specifico del dominio per manipolare i tuoi dati distribuiti; e rende Spark accessibile a un pubblico più ampio, oltre agli ingegneri di dati specializzati.
Nella nostra anteprima del webinar Apache Spark 2.0 e nel blog successivo, abbiamo menzionato che in Spark 2.0, le API DataFrame si uniranno alle API Dataset, unificando le capacità di elaborazione dei dati tra le librerie. Grazie a questa unificazione, gli sviluppatori hanno ora meno concetti da imparare o ricordare, e lavorano con un'unica API di alto livello e type-safe chiamata Dataset.
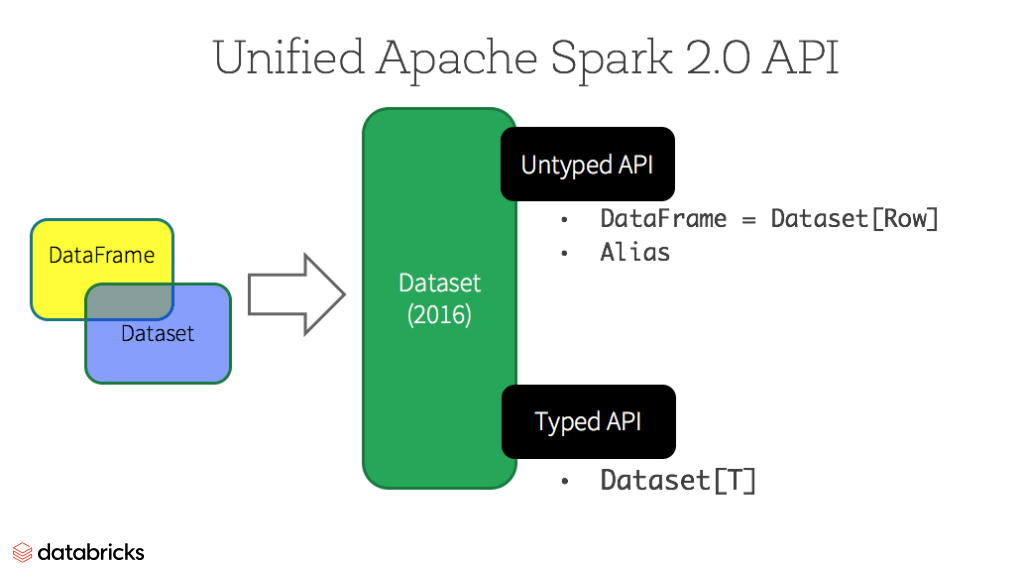
Datasets
A partire da Spark 2.0, Dataset assume due caratteristiche API distinte: un'API strongly-typed (fortemente tipizzata) e un'API untyped (non tipizzata), come mostrato nella tabella sottostante. Concettualmente, considera DataFrame come un alias per una raccolta di oggetti generici Dataset[Row], dove un Row è un oggetto JVM generico untyped. Dataset, al contrario, è una raccolta di oggetti JVM strongly-typed, dettati da una case class definita in Scala o da una classe in Java.
API Typed e Untyped
| Lingua | Astrazione Principale |
|---|---|
| Scala | Dataset[T] & DataFrame (alias per Dataset[Row]) |
| Java | Dataset[T] |
| Python* | DataFrame |
| R* | DataFrame |
Nota: Poiché Python e R non hanno type-safety in fase di compilazione, abbiamo solo API untyped, ovvero DataFrame.
Benefici delle API Dataset
In qualità di sviluppatore Spark, benefici delle API unificate DataFrame e Dataset in Spark 2.0 in diversi modi.
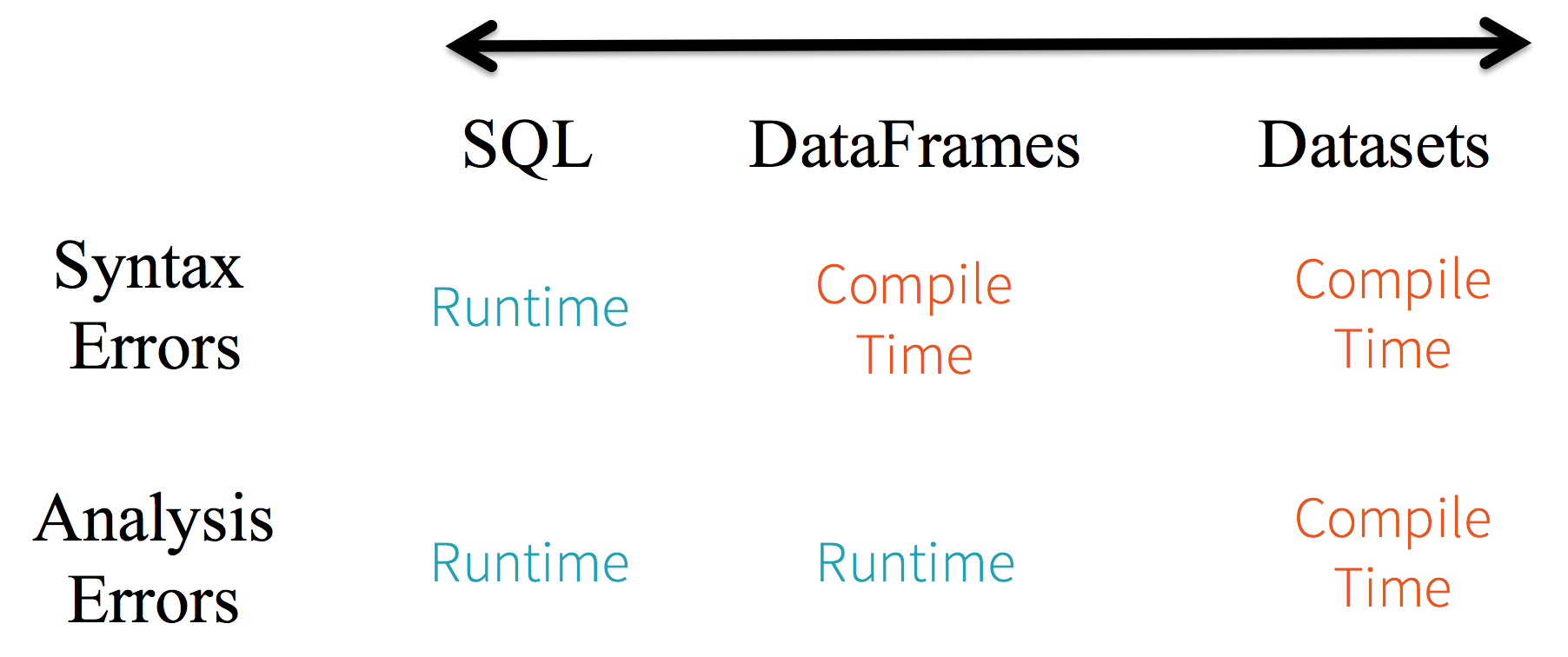
1. Static-typing e type-safety a runtime
Considera il static-typing e la sicurezza a runtime come uno spettro, con SQL meno restrittivo e Dataset più restrittivo. Ad esempio, nelle tue query stringa Spark SQL, non conoscerai un errore di sintassi fino al runtime (il che potrebbe essere costoso), mentre in DataFrame e Dataset puoi rilevare errori in fase di compilazione (il che fa risparmiare tempo e costi agli sviluppatori). Ovvero, se invochi una funzione in DataFrame che non fa parte dell'API, il compilatore la rileverà. Tuttavia, non rileverà un nome di colonna non esistente fino al runtime.
All'estremità dello spettro c'è Dataset, il più restrittivo. Poiché le API Dataset sono tutte espresse come funzioni lambda e oggetti JVM tipizzati, qualsiasi discrepanza di parametri tipizzati verrà rilevata in fase di compilazione. Inoltre, anche l'errore di analisi può essere rilevato in fase di compilazione, quando si utilizzano Dataset, risparmiando così tempo e costi agli sviluppatori.
Tutto ciò si traduce in uno spettro di type-safety lungo la sintassi e gli errori di analisi nel tuo codice Spark, con Dataset come il più restrittivo ma comunque produttivo per uno sviluppatore.
2. Astrazione di alto livello e vista personalizzata su dati strutturati e semi-strutturati
DataFrame come raccolta di Dataset[Row] offrono una vista strutturata personalizzata sui tuoi dati semi-strutturati. Ad esempio, supponiamo che tu abbia un enorme set di dati di eventi di dispositivi IoT, espresso in JSON. Poiché JSON è un formato semi-strutturato, si presta bene all'impiego di Dataset come raccolta di Dataset[DeviceIoTData] fortemente tipizzati e specifici.
Potresti esprimere ogni voce JSON come DeviceIoTData, un oggetto personalizzato, con una Scala case class.
Successivamente, possiamo leggere i dati da un file JSON.
Tre cose accadono sotto il cofano nel codice sopra:
- Spark legge il JSON, inferisce lo schema e crea una raccolta di DataFrame.
- A questo punto, Spark converte i tuoi dati in DataFrame = Dataset[Row], una raccolta di oggetti Row generici, poiché non conosce il tipo esatto.
- Ora, Spark converte Dataset[Row] -> Dataset[DeviceIoTData], un oggetto Scala JVM type-specific, come dettato dalla classe DeviceIoTData.
La maggior parte di noi che lavora con dati strutturati è abituata a visualizzare ed elaborare dati in modo colonnare o ad accedere ad attributi specifici all'interno di un oggetto. Con Dataset come raccolta di oggetti tipizzati Dataset[ElementType], ottieni senza problemi sia la sicurezza in fase di compilazione sia una vista personalizzata per oggetti JVM fortemente tipizzati. E il tuo Dataset[T] strongly-typed risultante dal codice sopra può essere facilmente visualizzato o elaborato con metodi di alto livello.
3. Facilità d'uso delle API con struttura
Sebbene la struttura possa limitare il controllo su ciò che il tuo programma Spark può fare con i dati, introduce ricche semantiche e un set semplice di operazioni specifiche del dominio che possono essere espresse come costrutti di alto livello. La maggior parte dei calcoli, tuttavia, può essere eseguita con le API di alto livello di Dataset. Ad esempio, è molto più semplice eseguire operazioni agg, select, sum, avg, map, filter o groupBy accedendo a un oggetto di tipo Dataset DeviceIoTData piuttosto che ai campi dati delle righe RDD.
Esprimere il proprio calcolo in un'API specifica del dominio è molto più semplice e facile che con espressioni di tipo algebra relazionale (in RDD). Ad esempio, il codice seguente filter() e map() crea un altro Dataset immutabile.
4. Prestazioni e Ottimizzazione
Oltre a tutti i vantaggi sopra menzionati, non si possono trascurare i guadagni in termini di efficienza dello spazio e prestazioni nell'uso delle API DataFrame e Dataset per due motivi.
In primo luogo, poiché le API DataFrame e Dataset sono costruite sul motore Spark SQL, utilizzano Catalyst per generare un piano di query logico e fisico ottimizzato. Indipendentemente dalle API DataFrame/Dataset in R, Java, Scala o Python, tutte le query di tipo relazionale vengono sottoposte allo stesso ottimizzatore di codice, fornendo efficienza di spazio e velocità. Mentre l'API di tipo Dataset[T] è ottimizzata per le attività di data engineering, il Dataset[Row] non tipizzato (un alias di DataFrame) è ancora più veloce e adatto all'analisi interattiva.

In secondo luogo, poiché Spark come compilatore comprende il tuo oggetto JVM di tipo Dataset, mappa il tuo oggetto JVM specifico del tipo alla rappresentazione di memoria interna di Tungsten utilizzando Encoder. Di conseguenza, gli Encoder Tungsten possono serializzare/deserializzare in modo efficiente oggetti JVM e generare bytecode compatto che può essere eseguito a velocità superiori.
Quando dovrei usare DataFrame o Dataset?
- Se desideri semantiche ricche, astrazioni di alto livello e API specifiche del dominio, usa DataFrame o Dataset.
- Se il tuo elaborazione richiede espressioni di alto livello, filtri, mappe, aggregazioni, medie, somme, query SQL, accesso colonnare e uso di funzioni lambda su dati semi-strutturati, usa DataFrame o Dataset.
- Se desideri un maggiore grado di type-safety al momento della compilazione, oggetti JVM tipizzati, sfruttare l'ottimizzazione Catalyst e beneficiare della generazione di codice efficiente di Tungsten, usa Dataset.
- Se desideri unificazione e semplificazione delle API tra le librerie Spark, usa DataFrame o Dataset.
- Se sei un utente R, usa DataFrame.
- Se sei un utente Python, usa DataFrame e torna a RDD se hai bisogno di maggiore controllo.
Nota che puoi sempre interagire o convertire senza problemi da DataFrame e/o Dataset a un RDD, tramite una semplice chiamata al metodo .rdd. Ad esempio,
Riassumendo
In sintesi, la scelta di quando usare RDD o DataFrame e/o Dataset sembra ovvia. Mentre il primo offre funzionalità e controllo di basso livello, il secondo consente una vista e una struttura personalizzate, offre operazioni di alto livello e specifiche del dominio, consente di risparmiare spazio ed esegue a velocità superiori.
Esaminando le lezioni apprese dalle prime versioni di Spark, come semplificare Spark per gli sviluppatori, come ottimizzarlo e renderlo performante, abbiamo deciso di elevare le API RDD di basso livello a un'astrazione di alto livello come DataFrame e Dataset e di costruire questa astrazione dati unificata tra le librerie basata sull'ottimizzatore Catalyst e Tungsten.
Scegli una delle due opzioni, DataFrame e/o Dataset o API RDD, che soddisfi le tue esigenze e il tuo caso d'uso, ma non mi sorprenderei se rientrassi nella categoria della maggior parte degli sviluppatori che lavorano con dati strutturati e semi-strutturati.
Prossimi passi?
Puoi provare Apache Spark 2.2 su Databricks.
Puoi anche guardare la presentazione Spark Summit su A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets
Se non ti sei ancora registrato, prova Databricks ora.
Nelle prossime settimane, pubblicheremo una serie di blog su Structured Streaming. Resta sintonizzato.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.