Che cosa è lo strato convoluzionale?
Uno strato di rete neurale che applica filtri convoluzionali apprendibili ai dati di input, rilevando caratteristiche spaziali attraverso campi recettivi localizzati
- Applica piccoli kernel (tipicamente filtri 3x3 o 5x5) che scorrono sulle immagini di input con parametri di passo e riempimento, utilizzando pesi condivisi per ridurre drasticamente i parametri rispetto ai livelli completamente connessi.
- Rileva caratteristiche spaziali gerarchiche: i livelli iniziali identificano bordi e texture, i livelli intermedi riconoscono forme e pattern, i livelli più profondi rilevano oggetti complessi e concetti semantici.
- Solitamente seguito da funzioni di attivazione (ReLU), normalizzazione batch e livelli di pooling per l'invarianza della traduzione, che costituiscono i componenti fondamentali delle reti neurali con nucleo reticolare (CNN) per la visione artificiale.
Nel deep learning, una rete neurale convoluzionale (CNN o ConvNet) è una classe di reti neurali profonde tipicamente utilizzate per riconoscere pattern (elementi o schemi) presenti nelle immagini, ma anche per analisi di dati spaziali, visione artificiale, elaborazione del linguaggio naturale, elaborazione di segnali e molti altri scopi. L'architettura di una rete convoluzionale riproduce il pattern di connettività dei neuroni del cervello umano ed è ispirata all'organizzazione della corteccia visiva. Questa tipologia specifica di rete neurale artificiale deve il suo nome a una delle operazioni più importanti svolte nella rete: la convoluzione.
Che cos'è una convoluzione?
La convoluzione è una procedura ordinata con la quale due sorgenti di informazioni vengono intrecciate; si tratta di un'operazione che converte una funzione in qualcos'altro. Le convoluzioni vengono impiegate da molto tempo solitamente nell'elaborazione di immagini, per renderle più sfuocate o nitide, ma anche per svolgere altre operazioni (ad es. definire meglio i bordi e mettere in rilievo). Le CNN applicano un pattern di connettività locale fra neuroni di strati adiacenti. 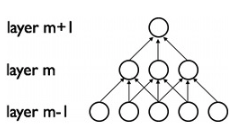 Le reti CNN usano filtri (detti anche kernel) per individuare quali elementi o caratteristiche, ad esempio bordi, sono presenti all'interno di un'immagine. Una CNN svolge quattro operazioni principali:
Le reti CNN usano filtri (detti anche kernel) per individuare quali elementi o caratteristiche, ad esempio bordi, sono presenti all'interno di un'immagine. Una CNN svolge quattro operazioni principali:
- Convoluzione
- Non Linearità (ReLU)
- Pooling o sottocampionamento
- Classificazione (strato completamente connesso)
Il primo strato di una rete neurale convoluzionale è sempre uno strato convoluzionale. Gli strati convoluzionali applicano un'operazione di convoluzione all'input, passando poi il risultato allo strato successivo. Una convoluzione converte tutti i pixel presenti nel suo campo ricettivo in un unico valore. Ad esempio, se si applica una convoluzione a un'immagine, si riducono le dimensioni dell'immagine e si riuniscono tutte le informazioni presenti nel campo in un unico pixel. Il prodotto finale dello strato di convoluzione è un vettore. In base al tipo di problema da risolvere e al tipo di caratteristiche che si intende apprendere, si possono usare diversi tipi di convoluzioni.
Strato convoluzionale 2D
Il tipo di convoluzione più diffuso è lo strato convoluzionale 2D, solitamente abbreviato con conv2D. Un filtro o kernel in uno strato conv2D "sorvola" i dati 2D in ingresso, eseguendo una moltiplicazione per elementi. In questo modo tutti i risultati vengono sommati in un unico pixel di uscita. Il kernel eseguirà la stessa operazione per tutte le posizioni su cui passa, trasformando una matrice bidimensionale di caratteristiche in una matrice 2D differente.
Convoluzione dilatata o "atrous"
Questa operazione aumenta le dimensioni della finestra senza aumentare il numero di pesi, inserendo valori zero nei kernel convoluzionali. Le convoluzioni dilatate (o atrous) possono essere impiegate in applicazioni in tempo reale e applicazioni in cui la potenza di calcolo è minore in quanto i requisiti di RAM sono meno esasperati.
Il playbook sull'AI agentiva per l'enterprise

Convoluzioni separabili
Esistono due tipi principali di convoluzioni separabili: spaziali e in profondità. La convoluzione spaziale riguarda principalmente le dimensioni spaziali di un'immagine e di un kernel: larghezza e altezza. Rispetto alle convoluzioni spaziali, le convoluzioni separabili in profondità lavorano con kernel che non possono essere "fattorizzati" in due kernel più piccoli. Pertanto viene usata con maggiore frequenza.
Convoluzioni trasposte
Questi tipi di convoluzioni sono dette anche deconvoluzioni o convoluzioni frazionate. Uno strato convoluzionale trasposto esegue una normale convoluzione ma inverte la trasformazione spaziale.
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.