Che cos'è la virtualizzazione dei dati?
Accedi e interroga i dati da più fonti senza spostarli o replicarli fisicamente, creando un livello virtuale unificato
- Comprendere cos'è la virtualizzazione dei dati e come astrae l'accesso ai dati tra sistemi diversi attraverso un'interfaccia unificata.
- Scoprire come la virtualizzazione riduce lo spostamento dei dati, semplifica l'architettura e fornisce accesso in tempo reale a fonti dati distribuite.
- Scoprire casi d'uso tra cui query federate, integrazione di sistemi legacy e analisi agili senza complessi processi ETL.
Che cos'è la virtualizzazione dei dati?
La virtualizzazione dei dati è un metodo di integrazione dei dati che consente alle organizzazioni di creare viste unificate delle informazioni provenienti da più sorgenti senza spostare o copiare fisicamente i dati. Come tecnologia chiave della virtualizzazione dei dati, questo approccio alla gestione dei dati consente ai consumatori di dati di accedere a informazioni provenienti da sistemi eterogenei tramite un unico livello virtuale. Invece di estrarre i dati in un repository centrale, la virtualizzazione dei dati inserisce un livello astratto tra i consumatori di dati e i sistemi sorgente. Gli utenti eseguono query su questo livello tramite un'unica interfaccia, mentre i dati sottostanti rimangono nella loro posizione originale.
La virtualizzazione dei dati affronta una sfida fondamentale della moderna gestione dei dati: i dati aziendali sono distribuiti su molteplici sorgenti, tra cui database, data lake, applicazioni cloud e sistemi legacy. Gli approcci tradizionali di integrazione dei dati richiedono la costruzione di pipeline complesse per spostare i dati in un data warehouse centrale prima che l'analisi possa iniziare. La virtualizzazione dei dati elimina questo ritardo fornendo accesso in tempo reale ovunque risiedano le informazioni.
L'interesse per la virtualizzazione dei dati ha subito un'accelerazione con l'adozione di ambienti multi-cloud, architetture lakehouse e modelli di condivisione dei dati tra organizzazioni. Queste tendenze moltiplicano il numero di sorgenti a cui i team devono accedere, rendendo il consolidamento fisico sempre meno praticabile. La virtualizzazione dei dati offre un modo per unificare l'accesso senza unificare lo storage.
La tecnologia di virtualizzazione dei dati crea un livello di virtualizzazione che si interpone tra i consumatori di dati e i sistemi sorgente. Questo livello virtuale consente agli utenti aziendali di eseguire query sui dati presenti in data lake, data warehouse e servizi di storage cloud senza dover comprendere le complessità tecniche di ciascuna sorgente. Implementando la virtualizzazione dei dati, le organizzazioni consentono ai propri team di combinare dati provenienti da più sorgenti in tempo reale, mantenendo al contempo una governance centralizzata.
È importante sgombrare il campo da un equivoco comune: la virtualizzazione dei dati e la visualizzazione dei dati sono due concetti distinti, che risolvono problemi completamente diversi. La virtualizzazione dei dati è una tecnologia di integrazione che crea livelli di accesso su sorgenti distribuite. La visualizzazione dei dati è una tecnologia di presentazione che rappresenta le informazioni sotto forma di diagrammi, grafici e dashboard per supportare la business intelligence. I due approcci sono complementari; la virtualizzazione dei dati fornisce un accesso unificato che gli strumenti di visualizzazione presentano poi in formati leggibili dall'uomo.
Per le organizzazioni che perseguono una gestione agile dei dati, la virtualizzazione dei dati offre un percorso verso insight più rapidi senza l'overhead infrastrutturale degli approcci tradizionali.
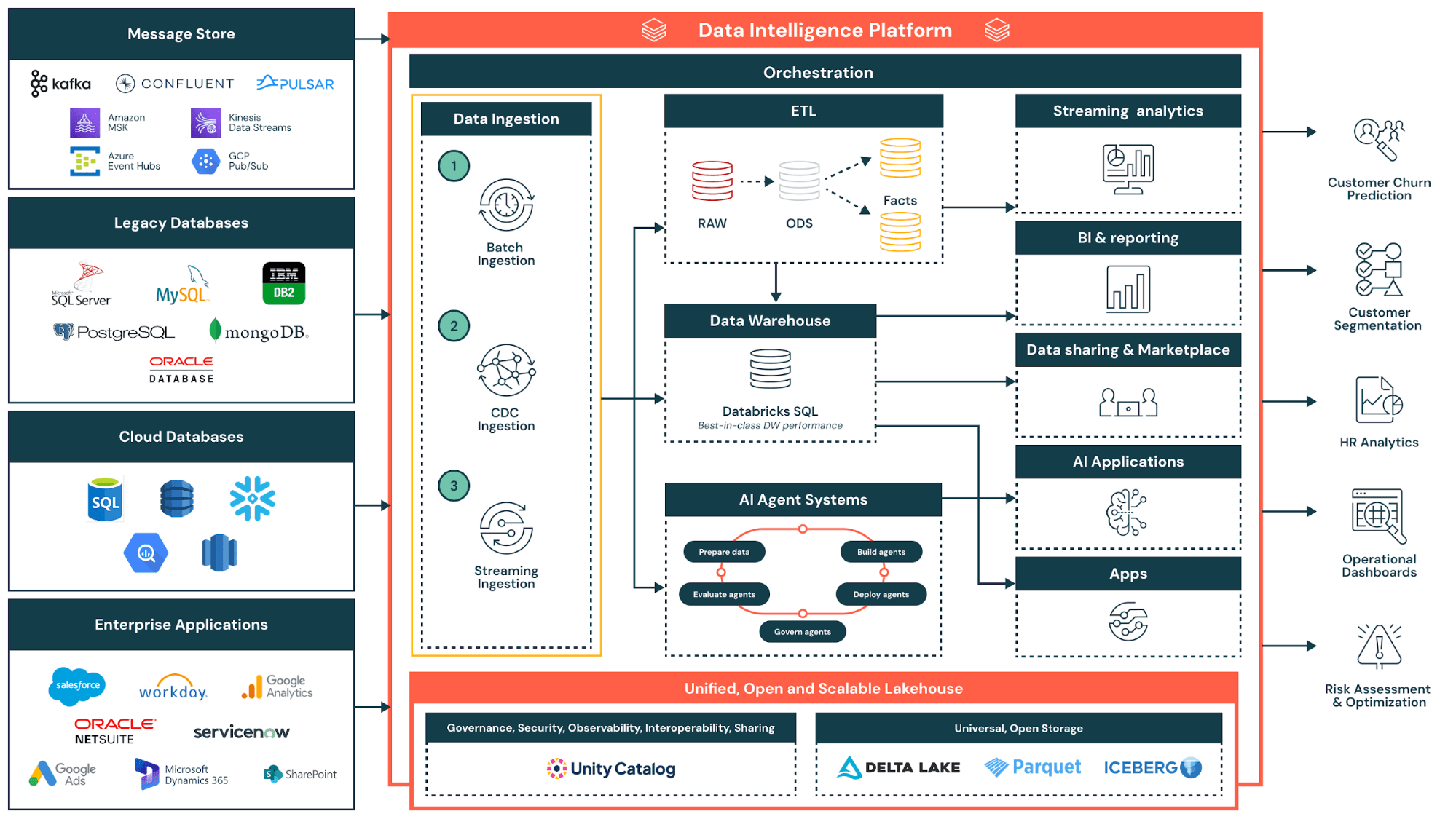
Approfondimento: Processi ETL e strategie di integrazione dei dati
Come funziona la virtualizzazione dei dati: architettura e componenti
L'architettura di virtualizzazione dei dati si basa su tre componenti fondamentali dell’infrastruttura di gestione dei dati: un livello semantico dei dati per le definizioni di business, un livello di virtualizzazione per la federazione delle query e funzionalità di gestione dei metadati per la governance. Le piattaforme moderne integrano questi componenti per creare ambienti di dati virtuali completi, in cui data scientist, utenti di business e consumatori di dati possono accedere a sorgenti e servizi dati senza sapere dove le informazioni siano archiviate.
Il livello di virtualizzazione si colloca tra i consumatori di dati (come analisti, applicazioni e strumenti di BI) e le sorgenti di dati sottostanti. Questo livello gestisce i metadati relativi a dove risiedono i dati, alla loro struttura e alle modalità di accesso. Il livello in sé non archivia alcun dato; funziona come un motore intelligente di instradamento e traduzione. Le soluzioni di governance come Unity Catalog possono gestire questi metadati in modo centralizzato, fornendo un punto di controllo unico per le policy di individuazione e di accesso.
Quando un utente invia una query, il motore di virtualizzazione dei dati determina quali sorgenti di dati contengono le informazioni pertinenti. Traduce quindi la query nel linguaggio nativo di ogni sistema, che si tratti di SQL per i database relazionali, di chiamate API per le applicazioni cloud o di protocolli di accesso ai file per i data lake. Infine, il motore federa la richiesta tra i sistemi e assembla i risultati in una risposta unificata.
La virtualizzazione dei dati abilita la federazione delle query, che descrive questo modello di esecuzione distribuita. Le query complesse vengono suddivise in sottoquery, ciascuna instradata verso la sorgente appropriata. I risultati tornano al livello di virtualizzazione, che li unisce e li trasforma prima di fornire un'unica risposta all'utente. Lakehouse Federation, ad esempio, consente agli utenti di eseguire query su database esterni, warehouse e applicazioni cloud direttamente dal lakehouse, senza dover prima migrare i dati. L'ottimizzazione delle prestazioni avviene tramite tecniche come il predicate pushdown, in cui la logica di filtraggio viene eseguita alla sorgente anziché in modo centralizzato.
Le piattaforme moderne implementano inoltre join pushdown, column pruning e caching intelligente. Quando le sorgenti presentano tempi di risposta variabili, il motore esegue le query in parallelo e applica meccanismi di gestione dei timeout per evitare che le sorgenti più lente blocchino i risultati. Queste ottimizzazioni aiutano le query virtualizzate ad avvicinarsi alle prestazioni delle query su dati consolidati fisicamente.
La virtualizzazione dei dati nativa del lakehouse offre un ulteriore vantaggio: una governance unificata sia sui dati federati che su quelli interni. Utilizzando Unity Catalog per gestire le policy di accesso, le organizzazioni applicano le stesse regole di sicurezza ai database esterni e alle tabelle del lakehouse. Gli utenti interrogano dati virtualizzati e dati fisici all'interno della stessa istruzione SQL, senza dover gestire sistemi o permessi separati.
Virtualizzazione dei dati vs. ETL: differenze principali
L'ETL tradizionale (Extract, Transform, Load) sposta fisicamente i dati dai sistemi sorgente verso un data warehouse o data lake centralizzato. Questo crea copie, introduce latenza tra i cicli di estrazione e richiede una manutenzione continua delle pipeline. La virtualizzazione dei dati adotta l'approccio opposto: i dati restano dove sono e vengono interrogati su richiesta.
Ciascun approccio risponde a casi d'uso diversi. Vediamo in che modo si differenziano lungo alcune dimensioni chiave:
Movimento dei dati: l'ETL copia i dati in un repository centrale. La virtualizzazione dei dati interroga i dati in loco, senza creare duplicati.
Freschezza dei dati: l'ETL fornisce dati aggiornati all'ultimo ciclo di refresh, che può risalire a ore o giorni prima. La virtualizzazione dei dati fornisce accesso in tempo reale ai dati live delle sorgenti.
Tempo di accesso agli insight: l'ETL richiede la costruzione delle pipeline prima che l'analisi possa iniziare, un processo che spesso richiede settimane o mesi. La virtualizzazione dei dati fornisce accesso immediato una volta configurate le connessioni.
Trasformazioni complesse: l'ETL eccelle nell'elaborazione multi-step e nell'analisi storica. La virtualizzazione dei dati gestisce join e filtri, ma incontra difficoltà con logiche di trasformazione elaborate.
La maggior parte delle organizzazioni utilizza entrambi gli approcci in combinazione. ETL ed ELT gestiscono trasformazioni complesse, analisi delle tendenze storiche e carichi di lavoro batch critici in termini di prestazioni. La virtualizzazione dei dati fornisce accesso agile e in tempo reale per analisi ad-hoc e dashboard operative. La scelta dipende dalle caratteristiche del carico di lavoro piuttosto che da considerazioni ideologiche.
Approfondimento: Unity Catalog per la governance unificata e i modelli di architettura dei dati
Vantaggi principali: accesso in tempo reale senza spostamento dei dati
Il valore di business della virtualizzazione dei dati risiede nella velocità, nella riduzione dei costi e nella semplificazione della governance. La virtualizzazione dei dati consente alle organizzazioni di ridurre i costi di archiviazione, migliorare l'accesso ai dati per gli utenti aziendali e semplificare l'infrastruttura su sorgenti eterogenee.
1. Riduzione dei costi di archiviazione e infrastruttura
La virtualizzazione dei dati crea valore immediato attraverso la riduzione dei costi di replica dei dati. Eliminare la duplicazione significa che le organizzazioni smettono di pagare per archiviare più copie delle stesse informazioni su data warehouse, data mart e ambienti di analisi. I risparmi sullo spazio di archiviazione aumentano con la crescita dei volumi, mentre i team evitano la complessità infrastrutturale legata al mantenimento di copie sincronizzate.
2. Insight quasi in tempo reale per i consumatori di dati
Le query vengono eseguite su sistemi live anziché su copie obsolete nei data warehouse. Ad esempio, le società di servizi finanziari usano questa capacità per il rilevamento delle frodi; i rivenditori al dettaglio monitorano l'inventario sui diversi canali man mano che le transazioni avvengono; i sistemi sanitari possono accedere alle cartelle cliniche aggiornate dei pazienti durante gli episodi di cura. L'analisi in tempo reale diventa possibile senza dover costruire pipeline di streaming.
3. Infrastruttura semplificata
Implementando la virtualizzazione dei dati, le organizzazioni centralizzano regole di accesso, policy di sicurezza e metadati in un livello di dati virtuale, invece di replicare la governance su più sistemi. Gli amministratori definiscono le policy una sola volta, anziché gestirle separatamente in ciascuna sorgente. Quando la virtualizzazione dei dati è integrata in una piattaforma lakehouse anziché distribuita come infrastruttura standalone, i team evitano di dover mantenere un ulteriore sistema.
4. Riduzione del time-to-value per le iniziative aziendali
Le organizzazioni riportano una riduzione dei tempi di consegna da settimane a giorni o ore. L'accelerazione deriva dall'eliminazione dei mesi solitamente necessari per progettare, costruire, testare e mantenere pipeline ETL per ogni nuovo caso d'uso analitico.
Questi vantaggi si applicano soprattutto a scenari che coinvolgono sorgenti di dati eterogenee, requisiti in rapida evoluzione e un'enfasi sulla freschezza dei dati rispetto alla profondità storica.
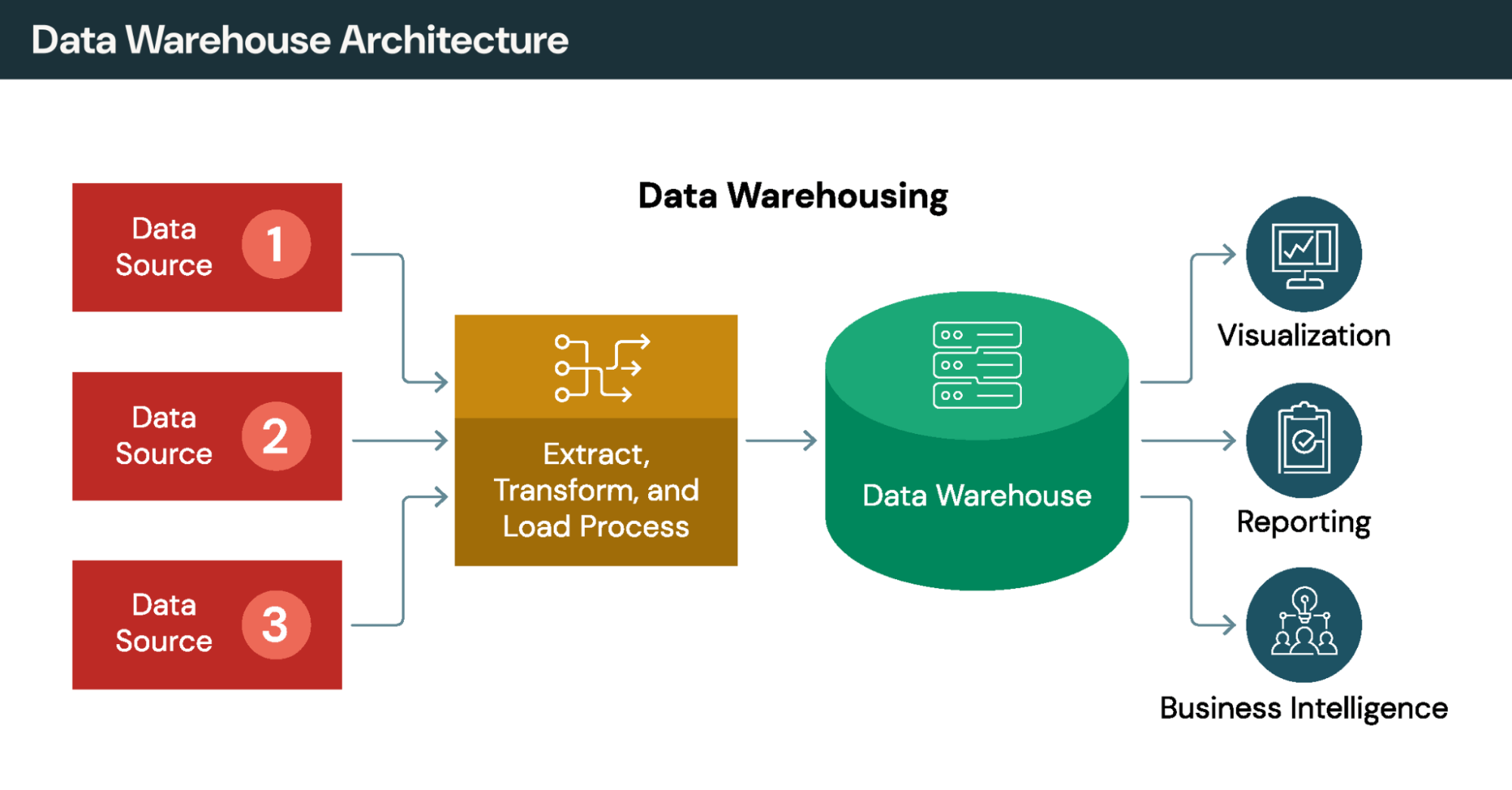
Approcci di integrazione a confronto
I metodi di integrazione tradizionali, come l'ETL spostano fisicamente i dati in repository centrali. La virtualizzazione dei dati adotta un approccio diverso: accede ai dati in loco senza replicarli. Le organizzazioni spesso combinano entrambe le strategie: ETL per trasformazioni complesse e virtualizzazione dei dati per un accesso agile.
Approfondimento: Funzionalità di analisi in tempo reale e data warehousing moderno
Il playbook sull'AI agentiva per l'enterprise

Casi d'uso pratici e applicazioni di settore
La tecnologia di virtualizzazione dei dati si rivela ideale quando le organizzazioni necessitano di un accesso unificato a sistemi operazionali, data lake e applicazioni cloud. La virtualizzazione dei dati consente l'accesso in tempo reale da più sorgenti senza i tempi di realizzazione tipici dei progetti tradizionali di integrazione dei dati. I seguenti esempi illustrano alcuni modelli comuni.
retail
I retailer operano su piattaforme di e-commerce, sistemi dei punti vendita fisici, applicazioni di gestione del magazzino, terminali POS e reti di fornitori. L'implementazione della virtualizzazione dei dati crea visibilità end-to-end sulla supply chain fornendo accesso a più sistemi senza costruire integrazioni punto-punto.
La gestione dell'inventario beneficia in modo particolare della virtualizzazione dei dati in tempo reale. Anziché sincronizzare i conteggi di inventario in batch ogni notte, i retailer interrogano i dati live da tutti i canali per fornire informazioni accurate sulla disponibilità. Questo supporta funzionalità come l'acquisto online con ritiro in negozio, in cui i clienti necessitano di informazioni aggiornate sulle scorte prima di effettuare un ordine. Le organizzazioni che implementano la virtualizzazione dei dati per l'accesso alla supply chain riportano notevoli risparmi sui costi grazie alla riduzione dei costi di mantenimento dell'inventario e al miglioramento dell'accuratezza delle previsioni della domanda.
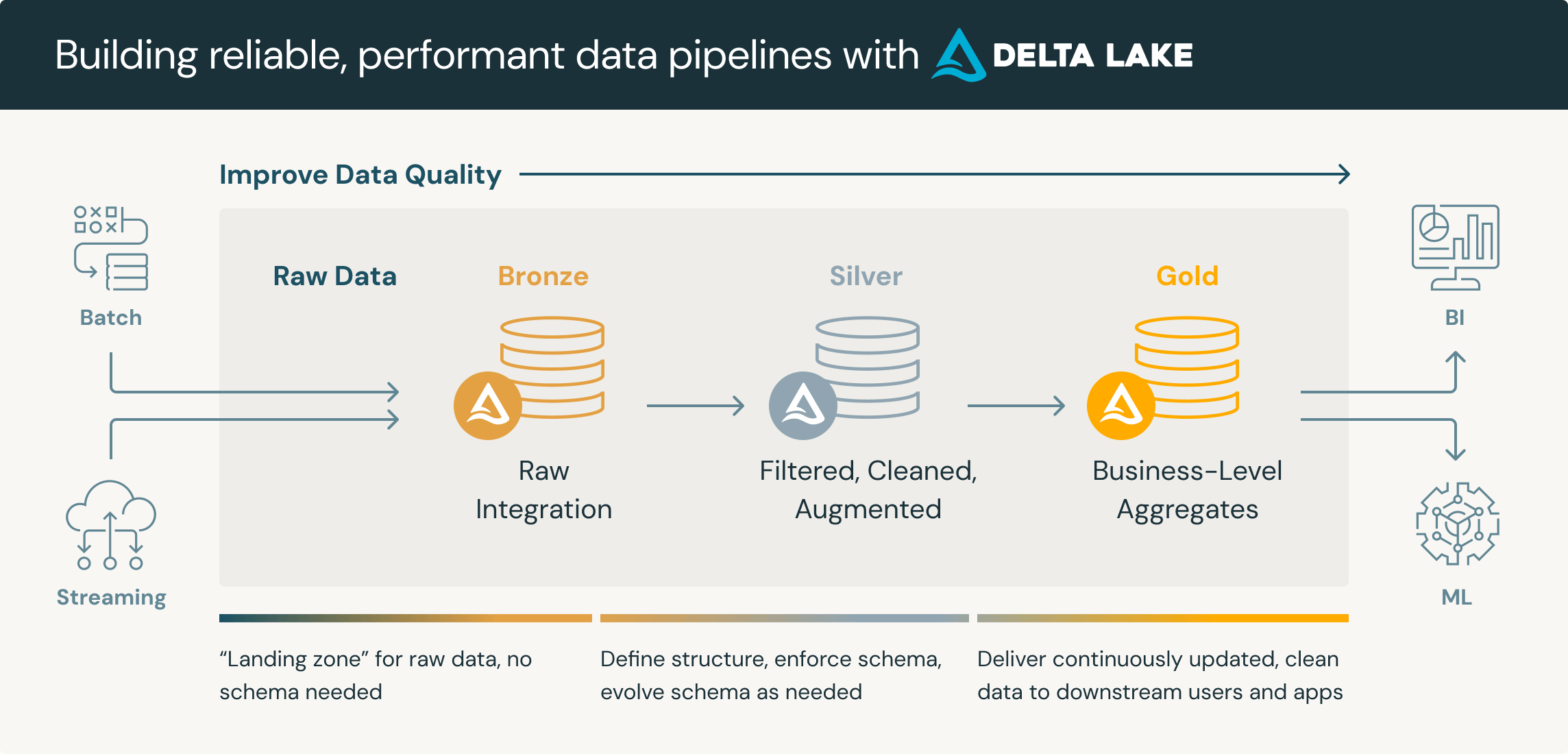
Servizi finanziari
Le società di servizi finanziari utilizzano soluzioni di virtualizzazione dei dati per aggregare dati dei clienti provenienti da transazioni con carta di credito, depositi, sistemi di prestito, piattaforme CRM e fornitori esterni al fine di costruire profili cliente completi. La virtualizzazione dei dati assembla queste viste su richiesta, anziché mantenere record cliente predefiniti che diventano obsoleti tra un aggiornamento e l'altro.
Il rilevamento delle frodi in tempo reale richiede un accesso inferiore al secondo ai modelli di transazione su più conti. I data warehouse orientati al batch non sono in grado di supportare questo requisito di latenza. Anche la conformità normativa ne trae vantaggio: la virtualizzazione dei dati rende possibile una reportistica consolidata tra sistemi diversi, mantenendo al contempo le tracce di audit per la revisione da parte degli enti di controllo.
Sanità
I dati dei pazienti sono sia sensibili che distribuiti tra cartelle cliniche elettroniche, sistemi di fatturazione, archivi di imaging e sistemi informativi di laboratorio. La virtualizzazione dei dati consente ai clinici di accedere a viste unificate dei pazienti durante l'erogazione delle cure, mantenendo i dati presso le rispettive sorgenti. Un medico che esamina la storia clinica di un paziente può visualizzare, tramite un'unica query, i dati dell'assistenza primaria, delle visite specialistiche e dei risultati di laboratorio, anche se ciascun sistema archivia i dati in modo indipendente.
Questa architettura supporta i requisiti di privacy, perché le informazioni sensibili non vengono mai concentrate in un'unica posizione vulnerabile a violazioni. Ospedali e sistemi sanitari possono condividere l'accesso senza trasferire fisicamente i dati tra organizzazioni, rendendo possibile un'assistenza coordinata.
Quando la virtualizzazione dei dati non è la scelta giusta
La virtualizzazione dei dati presenta limiti chiari. L'elaborazione batch ad alto volume richiede ancora lo spostamento fisico dei dati; elaborare milioni di righe non offre alcun vantaggio in termini di prestazioni rispetto allo spostare i dati una sola volta. Un operatore di pagamento che gestisce milioni di transazioni all'ora, ad esempio, non trarrebbe alcun vantaggio dalla virtualizzazione di quel carico di lavoro. L'analisi storica che richiede snapshot point-in-time necessita di un data warehouse che registri lo stato nel tempo, dal momento che la virtualizzazione dei dati accede esclusivamente ai dati correnti. Le trasformazioni complesse multi-step superano le capacità disponibili, che sono limitate a join, filtri e aggregazioni di tipo database.
Implementazioni di data warehouse di grandi dimensioni, operazioni tra più data center e carichi di lavoro che richiedono una bassa latenza garantita in genere giustificano lo spostamento fisico dei dati tramite pipeline di data engineering.
Approfondimento: Data lake e applicazioni di business intelligence
Considerazioni su governance, sicurezza e qualità
La virtualizzazione dei dati rafforza la governance consolidando il controllo in un livello di virtualizzazione centralizzato. Gli strumenti di virtualizzazione dei dati consentono agli amministratori di definire le policy di sicurezza una sola volta, anziché gestirle separatamente su sorgenti eterogenee.
Le funzionalità di sicurezza nelle piattaforme moderne includono il controllo degli accessi basato sui ruoli, la sicurezza a livello di riga e di colonna e il mascheramento dei dati per i campi sensibili. Il controllo degli accessi basato sugli attributi, associato a tag di classificazione, consente alle policy di accompagnare i dati a prescindere da come gli utenti vi accedono. Indipendentemente dal fatto che gli analisti si connettano tramite query SQL, API REST o strumenti di BI, vengono applicate le stesse regole di sicurezza.
Il tracciamento di audit e lineage consente di sapere chi ha effettuato l'accesso a quali dati, quando e da quale applicazione. Unity Catalog fornisce log di audit e lineage a livello di utente, indipendentemente dal linguaggio utilizzato, a supporto della reportistica di conformità. Questa visibilità supporta normative come GDPR, HIPAA e CCPA, e i requisiti regolamentari del settore finanziario che richiedono una governance dimostrabile.
La freschezza dei dati è intrinseca alla virtualizzazione dei dati, poiché le query interrogano sorgenti live. Tuttavia, questo introduce considerazioni sulla qualità dei dati: se i sistemi contengono errori o incongruenze, la virtualizzazione dei dati espone tali problemi direttamente ai consumatori. Le implementazioni efficaci combinano la virtualizzazione dei dati con il monitoraggio della loro qualità per garantire che la vista unificata ne preservi l'integrità.
La coerenza semantica rappresenta un'ulteriore sfida. Sistemi diversi possono utilizzare nomi diversi per lo stesso concetto, tipi di dato diversi per campi equivalenti o definizioni di business alternative per metriche simili. Il livello di virtualizzazione deve imporre convenzioni di denominazione coerenti affinché, ad esempio, i dati di un cliente nel CRM corrispondano allo stesso cliente nel sistema di fatturazione, anche se ciascun sistema etichetta e formatta i dati in modo diverso. Alcune organizzazioni aggiungono un livello semantico dei dati per definire termini di business e calcoli canonici applicabili a tutte le sorgenti virtualizzate, garantendo così che gli analisti vedano definizioni coerenti indipendentemente dal sistema sottostante che archivia i dati.
Approfondimento: Governance dei dati con Unity Catalog e best practice di gestione dei dati
Best practice di implementazione e selezione degli strumenti
Le organizzazioni che adottano la virtualizzazione dei dati dovrebbero seguire modelli consolidati per garantire un'implementazione di successo. Partire in piccolo: le implementazioni di successo spesso iniziano con un team ridotto che affronta progetti specifici ad alto valore, espandendosi solo dopo aver dimostrato il valore agli stakeholder. Definire per prima cosa la governance, stabilendo proprietà, modelli di sicurezza e standard di sviluppo prima di distribuire la tecnologia. Monitorare regolarmente le prestazioni per identificare query lente, ottimizzare le viste virtuali più utilizzate e regolare le connessioni man mano che i modelli di utilizzo evolvono.
Come si presenta la virtualizzazione dei dati nella pratica: implementazione reale
Consideriamo un esempio concreto. Un'azienda retail desidera analizzare il valore del ciclo di vita del cliente, ma i dati dei clienti risiedono in Salesforce CRM, la cronologia delle transazioni in un database PostgreSQL e il comportamento sul sito Web in Google Analytics, mentre i dati sui resi rimangono in un sistema Oracle legacy.
L'integrazione dei dati tradizionale richiede la costruzione di pipeline ETL per estrarre, trasformare e caricare tutti questi dati in un unico data warehouse. Questo progetto richiede mesi. Con la virtualizzazione dei dati, un amministratore crea connessioni a ciascuna sorgente e pubblica una vista virtuale che combina i dati tra sistemi diversi. Gli analisti interrogano questa vista come di consueto, utilizzando SQL, o vi collegano direttamente gli strumenti di BI. Visualizzano dati aggiornati da tutte le sorgenti all'interno di uno schema unificato. Quando l'azienda aggiunge in seguito un'app mobile con un proprio database, l'aggiunta di quella sorgente alla vista virtuale richiede giorni, anziché imporre una riprogettazione del data warehouse.
Questo modello supporta anche una strategia di tipo "virtualizza prima, migra dopo". I team iniziano federando le query verso sorgenti esterne, per poi monitorare quali dati vengono consultati più frequentemente. I set di dati ad alto utilizzo diventano candidati alla migrazione fisica in Delta Lake, dove le prestazioni delle query migliorano e i costi di archiviazione possono diminuire. I dati a basso utilizzo rimangono virtualizzati, evitando sforzi di migrazione non necessari.
Valutare software e strumenti di virtualizzazione dei dati
Nel valutare strumenti di virtualizzazione dei dati, dai priorità a tre criteri.
Supporto della diversità delle sorgenti: la piattaforma si connette a tutte le tue sorgenti attuali e previste, inclusi database relazionali, applicazioni cloud, API e archiviazione basata su file? Valuta se supporta i servizi dati di cui hai bisogno. Lacune nella connettività impongono soluzioni di ripiego che compromettono l'accesso unificato promesso dalla virtualizzazione dei dati.
Funzionalità di sicurezza: cerca sicurezza a livello di riga e di colonna, mascheramento, crittografia e una registrazione di audit completa. Queste funzionalità dovrebbero essere applicate in modo coerente, indipendentemente da come gli utenti accedono ai dati virtualizzati.
Funzionalità self-service: gli utenti aziendali possono individuare e accedere ai dati virtualizzati senza l'intervento dell'IT per ogni richiesta? Il valore della virtualizzazione dei dati si riduce se ogni nuova query richiede l'intervento di un amministratore.
Oltre a questi tre aspetti, considera i requisiti di prestazioni delle query, le preferenze sul modello di deployment e il costo totale di proprietà.
Approfondimento: LakeFlow per l'integrazione dei dati e le funzionalità del livello semantico
Conclusione: quando scegliere la virtualizzazione dei dati
La virtualizzazione dei dati risulta ideale per analisi operative in tempo reale, esplorazione periodica di sorgenti eterogenee, sviluppo di proof of concept e scenari in cui la freschezza dei dati conta più delle prestazioni delle query. La virtualizzazione dei dati consente alle organizzazioni di accedere ai dati da più sorgenti senza pipeline complesse, mentre gli approcci tradizionali basati su data warehouse rimangono superiori per trasformazioni complesse, analisi delle tendenze storiche, elaborazione batch ad alto volume e carichi di lavoro analitici sensibili alla latenza.
La domanda non è quale approccio scegliere in modo esclusivo, ma dove ciascuno si inserisce all'interno di un'architettura complessiva. Le organizzazioni implementano sempre più spesso entrambe le tecnologie: virtualizzazione dei dati per accesso agile e sperimentazione, e integrazione fisica quando le caratteristiche del carico di lavoro lo richiedono. Il modello "virtualizza prima, migra dopo" consente ai team di generare valore immediato tramite query federate, utilizzando al contempo dati di utilizzo reali per stabilire quali sorgenti giustificano l'investimento in una migrazione fisica verso Delta Lake o altri storage lakehouse.
Inizia identificando i casi d'uso in cui l'accesso in tempo reale a dati distribuiti crea un chiaro valore di business. Avvia un progetto pilota di virtualizzazione dei dati in quegli ambiti, misura i risultati ed espandi l'iniziativa sulla base del successo dimostrato.
Approfondimento: Framework decisionale ETL vs. ELT
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.