Introduzione ai data lake
I data lake forniscono un archivio dati completo e autorevole in grado di alimentare analisi, business intelligence e machine learning.

Introduzione ai data lake
Che cos'è un data lake?
Un data lake è un archivio centrale che conserva grandi quantità di dati nel loro formato nativo e grezzo. A differenza di un data warehouse gerarchico, che archivia i dati in file o cartelle, un data lake utilizza un'architettura piatta e oggetti di storage per memorizzarli. Lo storage a oggetti salva i dati insieme a metadati e a un identificatore univoco, semplificando la ricerca e il recupero delle informazioni attraverso regioni diverse e migliorando le prestazioni. Grazie all'uso di storage a oggetti a basso costo e di formati aperti, i data lake consentono a numerose applicazioni di sfruttare i dati disponibili.
I data lake sono stati sviluppati per superare i limiti dei data warehouse. Sebbene garantiscano analisi altamente performanti e scalabili, i data warehouse sono costosi, proprietari e incapaci di gestire molti dei casi d’uso moderni che le aziende vogliono essere in grado di affrontare. I data lake vengono spesso utilizzati per consolidare tutti i dati di un'organizzazione in un'unica posizione centrale, dove possono essere salvati "così come sono", senza dover imporre uno schema (ossia una struttura formale dei dati) in anticipo, come invece richiede un data warehouse. In un data lake è possibile salvare dati in qualunque fase di lavorazione: i dati grezzi vengono acquisiti e archiviati accanto alle fonti di dati strutturate e tabellari dell'organizzazione (come le tabelle dei database), e alle tabelle intermedie generate durante il processo di raffinazione. A differenza della maggior parte dei database e dei data warehouse, i data lake possono elaborare tutti i tipi di dati, compresi dati non strutturati e semi-strutturati come immagini, video, audio e documenti, che sono oggi fondamentali per casi d'uso di machine learning e analisi avanzata.
Perché utilizzare un data lake?
Prima di tutto, i data lake utilizzano formati aperti; questo permette di evitare il vincolo a un sistema proprietario tipico dei data warehouse, un requisito sempre più importante nelle architetture dati moderne. Sono inoltre altamente durevoli e a basso costo grazie alla loro capacità di scalare e sfruttare lo storage a oggetti. Inoltre, le analisi avanzate e il machine learning sui dati non strutturati rappresentano oggi una delle priorità strategiche principali per le aziende. La capacità unica di acquisire dati grezzi in una vasta gamma di formati (strutturati, non strutturati e semi-strutturati), insieme ai vantaggi citati, rende il data lake la soluzione naturale per l'archiviazione dei dati.
Se progettati correttamente, i data lake consentono di:

Alimenta data science e machine learning
I data lake consentono di trasformare i dati grezzi in dati strutturati pronti per analisi SQL, data science e machine learning con bassa latenza. I dati grezzi possono essere conservati indefinitamente a costi contenuti per un utilizzo futuro nel machine learning e nelle analisi.

Centralizza, consolida e cataloga i tuoi dati
Un data lake centralizzato elimina i problemi tipici dei silos di dati (come la duplicazione dei dati, le molteplici policy di sicurezza e le difficoltà di collaborazione), mettendo a disposizione degli utenti a valle un unico posto in cui trovare tutte le fonti di dati.

Integra in modo rapido e trasparente fonti e formati diversi
Qualsiasi tipo di dato può essere raccolto e conservato indefinitamente in un data lake, inclusi dati batch e streaming, video, immagini, file binari e altro. Inoltre, dal momento che il data lake funge da landing zone per i nuovi dati, il sistema è sempre aggiornato.

Democratizza i tuoi dati offrendo agli utenti strumenti self-service
I data lake offrono un'incredibile flessibilità, consentendo a utenti con competenze, strumenti e linguaggi completamente diversi di svolgere contemporaneamente varie attività di analisi.
Le sfide dei data lake
Nonostante i data lake presentino innegabili vantaggi, molte delle loro promesse non si sono realizzate a causa della mancanza di alcune funzionalità critiche: assenza di supporto per le transazioni, nessun controllo della qualità dei dati o della governance e insufficienti ottimizzazioni delle prestazioni. Di conseguenza, la maggior parte dei data lake aziendali si è trasformata in veri e propri data swamp.
Problemi di affidabilità
Senza gli strumenti adeguati, i data lake possono soffrire di problemi di affidabilità che rendono difficile per data scientist e analisti ragionare correttamente sui dati. Questi problemi possono derivare dalla difficoltà di combinare dati batch e streaming, dalla corruzione dei dati e da altri fattori.
Prestazioni lente
Con l'aumentare della quantità dei dati in un data lake, le prestazioni dei motori di query tradizionali tendono tipicamente a peggiorare. I colli di bottiglia includono la gestione dei metadati, un partizionamento dei dati non ottimale e altro ancora.
Mancanza di funzionalità di sicurezza
I data lake sono difficili da mettere in sicurezza e governare correttamente a causa della mancanza di visibilità e della difficoltà nel cancellare o aggiornare i dati. Questi limiti rendono molto difficile soddisfare i requisiti degli enti regolatori.
Per queste ragioni, un semplice data lake tradizionale non è sufficiente per soddisfare le esigenze delle aziende che vogliono innovare: spesso infatti ci si ritrova con architetture complesse e dati suddivisi in silos, distribuiti tra data warehouse, database e altri sistemi di storage. Semplificare questa architettura unificando tutti i dati in un data lake è il primo passo per le aziende che vogliono sfruttare appieno il machine learning e l’analisi dei dati per competere nel prossimo decennio.
Come i data lakehouse risolvono queste sfide
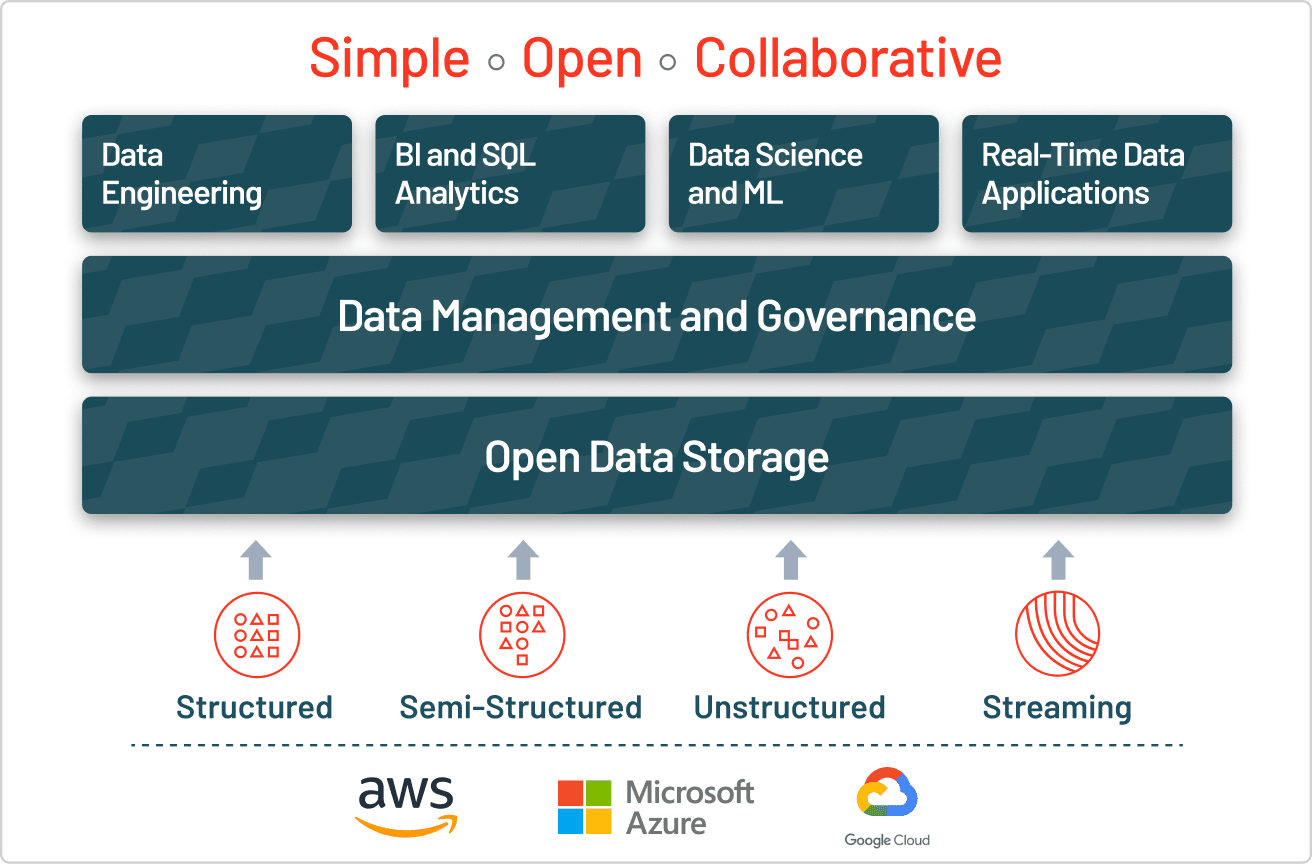
La risposta alle sfide dei data lake è il lakehouse, che aggiunge uno strato transazionale di gestione dello storage al di sopra del data lake. Un lakehouse utilizza strutture e funzionalità di gestione dei dati simili a quelle di un data warehouse, ma le esegue direttamente sui data lake nel cloud. In definitiva, un lakehouse consente ad analisi tradizionali, data science e machine learning di coesistere nello stesso sistema, il tutto in un formato aperto.
Un lakehouse abilita un'ampia gamma di nuovi casi d'uso per analisi aziendali su larga scala, BI e progetti di machine learning in grado di generare enorme valore di business. Gli analisti di dati possono estrarre insight approfonditi interrogando il data lake tramite SQL, i data scientist possono unire e arricchire set di dati per creare modelli di ML via via più accurati, i data engineer possono costruire pipeline ETL automatizzate e gli analisti di business intelligence possono creare dashboard e report più rapidamente e con maggiore facilità. Tutte queste attività possono essere eseguite contemporaneamente sul data lake, senza spostare i dati da un sistema all'altro, anche mentre nuovi dati vengono acquisiti in streaming.
Creare un lakehouse con Delta Lake
Per costruire un lakehouse di successo, le organizzazioni si sono rivolte a Delta Lake, un layer di gestione e governance dei dati in formato aperto che combina il meglio di data lake e data warehouse. Aziende di ogni settore sfruttano Delta Lake per favorire la collaborazione offrendo un'unica fonte attendibile di verità. Garantendo qualità, affidabilità, sicurezza e prestazioni sul data lake, sia per flussi in streaming che batch, Delta Lake elimina i silos e rende l'analisi accessibile a tutta l'organizzazione. Con Delta Lake, i clienti possono creare un lakehouse economico, altamente scalabile e in grado di eliminare la frammentazione dei dati, offrendo analisi self-service agli utenti finali.
Maggiori informazioni su Delta Lake
Differenze tra data lake, data lakehouse e data warehouse
| Data lake | Data lakehouse | data warehouse | |
|---|---|---|---|
| Tipi di dati | Tutti i tipi: dati strutturati, semi-strutturati, non strutturati (grezzi) | Tutti i tipi: dati strutturati, semi-strutturati, non strutturati (grezzi) | Solo dati strutturati |
| Costo | $ | $ | $$$ |
| Formato | Formato aperto | Formato aperto | Formato chiuso e proprietario |
| Scalabilità | Può espandersi per contenere, a basso costo, qualsiasi quantità di dati, indipendentemente dalla tipologia | Può espandersi per contenere, a basso costo, qualsiasi quantità di dati, indipendentemente dalla tipologia | L'espansione diventa esponenzialmente più costosa a causa dei costi dei fornitori |
| Utenza prevista | Limitata: data scientist | Unificata: analisti di dati, data scientist, ingegneri machine learning | Limitata: analisti di dati |
| Affidabilità | Qualità bassa, paludi di dati | Qualità elevata, dati affidabili | Qualità elevata, dati affidabili |
| Facilità d'uso | Difficile: l'esplorazione di grandi quantità di dati grezzi può risultare difficile in assenza di strumenti per organizzarli e catalogarli | Semplice: combina la semplicità e la struttura di un data warehouse con la casistica d'uso più ampia di un data lake | Semplice: la struttura di un data warehouse consente agli utenti di accedere rapidamente e facilmente ai dati per la reportistica e l'analisi |
| Prestazioni | Basse | Elevate | Elevate |
Scopri di più sulle sfide comuni dei data lake
Best practice per i lakehouse
Usa il data lake come landing zone per tutti i tuoi dati
Salva tutti i tuoi dati nel tuo data lake senza trasformarli o aggregarli, così da preservarli per finalità di machine learning e data lineage.
Maschera i dati contenenti informazioni private prima che entrino nel tuo data lake
Le informazioni di identificazione personale (PII) devono essere pseudonimizzate per rispettare il GDPR e poter essere conservate indefinitamente.
Proteggi il tuo data lake con controlli di accesso basati su ruoli e viste
L'aggiunta di ACL (livelli di controllo degli accessi) basati sulle viste consente una regolazione e un controllo più precisi sulla sicurezza del data lake rispetto ai soli controlli basati sui ruoli.
Aumenta affidabilità e prestazioni del tuo data lake utilizzando Delta Lake
Fino a oggi, la natura dei big data ha reso difficile offrire lo stesso livello di affidabilità e prestazioni disponibile nei database. Delta Lake introduce queste importanti funzionalità nei data lake.
Cataloga i dati nel tuo data lake
Utilizza strumenti di data catalog e gestione dei metadati nella fase di acquisizione per abilitare data science e analisi self-service.