Che cos'è l'apprendimento automatico operativo?
Distribuzione di modelli ML in produzione per previsioni in tempo reale su dati live, che richiedono infrastrutture per la fornitura, il monitoraggio, la riqualificazione e l'integrazione
- I modelli di distribuzione includono API REST per previsioni sincrone, punteggio batch per inferenza offline, distribuzione edge su dispositivi e modelli integrati all'interno di applicazioni che bilanciano latenza, throughput e vincoli di risorse.
- Il monitoraggio tiene traccia dell'accuratezza delle previsioni, delle metriche delle prestazioni del modello, della deriva dei dati che rileva le modifiche alla distribuzione, della deriva dei concetti che identifica le modifiche alle relazioni, dell'utilizzo delle risorse e dei KPI aziendali che misurano l'impatto del modello.
- Le pratiche MLOps includono pipeline CI/CD per la distribuzione del modello, trigger di riaddestramento automatizzati, framework di test A/B, distribuzioni canary che riducono al minimo i rischi, funzionalità di rollback e procedure di risposta agli incidenti per i guasti del modello.
Autore: Kevin Stumpf, co-fondatore e CTO
Nel 2015, quando abbiamo iniziato a implementare la piattaforma di machine learning di Uber, Michelangelo, abbiamo notato uno schema interessante: l'80% dei modelli di ML lanciati sulla piattaforma alimentava casi d'uso di machine learning operativo, che hanno un impatto diretto sull'esperienza degli utenti finali (rider e driver di Uber). Solo il 20% riguardava casi d'uso di machine learning analitico finalizzati al supporto del processo decisionale.
Il rapporto tra ML operativo e ML analitico era l'esatto opposto di quello osservato nella maggior parte delle altre aziende che applicavano il ML "nel mondo reale", dove il ML analitico la faceva da padrone. In retrospettiva, la massiccia adozione del ML operativo da parte di Uber è tutt'altro che sorprendente: Michelangelo ne rendeva estremamente semplice l'implementazione e l'azienda disponeva di una lunga serie di casi d'uso ad alto impatto. Oggi, a distanza di 7 anni, la dipendenza di Uber dal ML operativo è ulteriormente aumentata: senza di esso, avremmo prezzi delle corse antieconomici, previsioni dei tempi di arrivo (ETA) pessime e centinaia di milioni di dollari persi a causa delle frodi. In breve, senza il ML operativo, l'azienda si troverebbe di fatto paralizzata.
Il ML operativo è stato fondamentale per il successo di Uber e, per molto tempo, è sembrato appannaggio esclusivo dei giganti tecnologici. Ma la buona notizia è che negli ultimi sette anni molte cose sono cambiate. Sono emerse nuove tecnologie e tendenze che consentono a qualsiasi azienda di passare da un utilizzo prevalentemente basato sul ML analitico all'adozione del ML operativo; di seguito, condividiamo alcuni suggerimenti per chiunque voglia intraprendere questo percorso. Entriamo nel vivo.
ML operativo vs. ML analitico
Per machine learning operativo si intende l'utilizzo, da parte di un'applicazione, di un modello di ML per prendere in modo autonomo e continuo decisioni che impattano sul business in tempo reale. Queste applicazioni sono mission-critical e vengono eseguite "online", in produzione, all'interno dello stack operativo di un'azienda.
Esempi comuni includono sistemi di raccomandazione, classificazione dei risultati di ricerca, pricing dinamico, rilevamento delle frodi e approvazione delle richieste di prestito.
Il "fratello maggiore" del ML operativo nel mondo "offline" è il machine learning analitico. Si tratta di applicazioni che aiutano gli utenti aziendali a prendere decisioni migliori grazie al machine learning. Le applicazioni di ML analitico risiedono nello stack analitico dell'azienda e in genere alimentano direttamente report, dashboard e strumenti di business intelligence.
Esempi comuni includono la previsione delle vendite, le previsioni di abbandono e la segmentazione dei clienti.
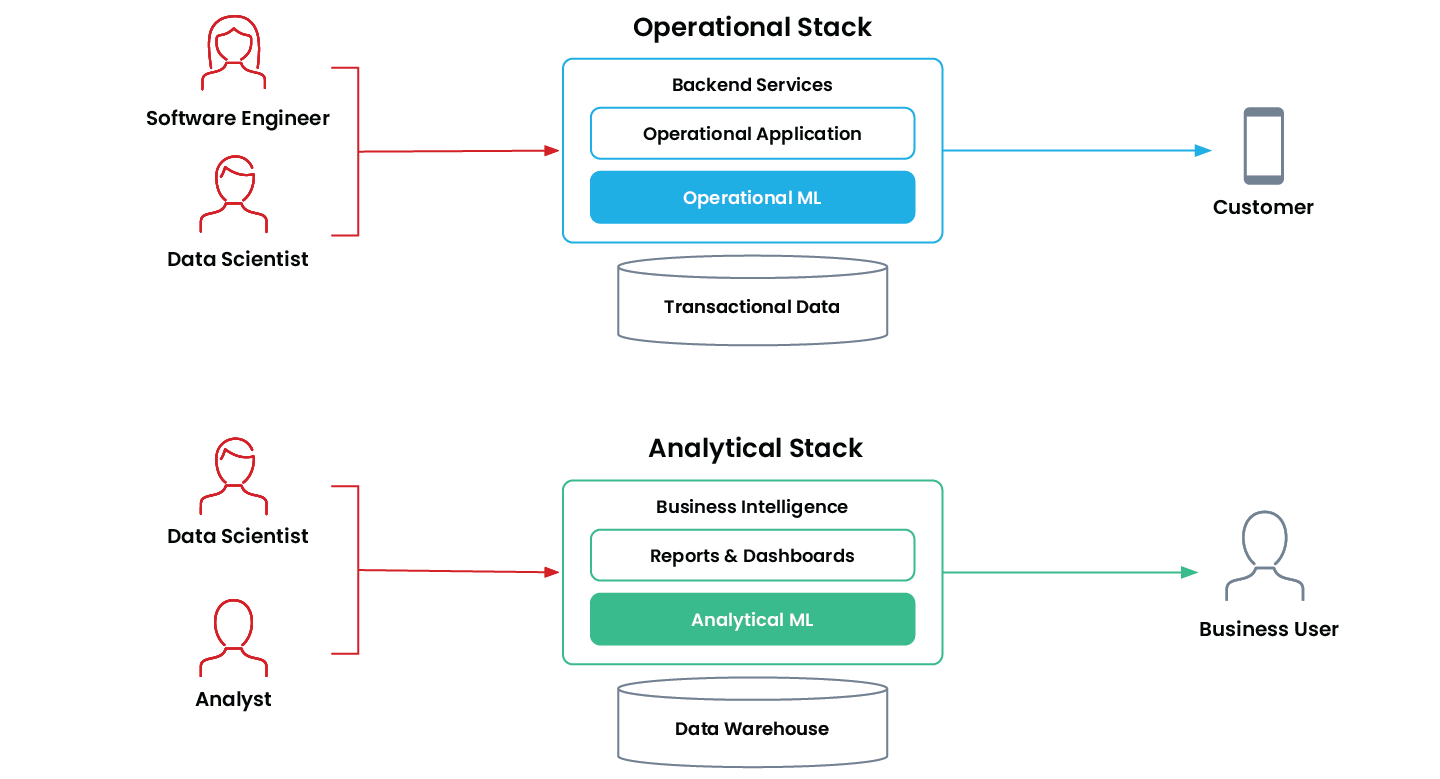
ML operativo e ML analitico vengono utilizzati per scopi diversi e hanno requisiti tecnici differenti.
| ML analitico | ML operativo | |
|---|---|---|
| Automazione delle decisioni | Human-in-the-loop | Completamente autonomo |
| Velocità decisionale | Velocità umana | Tempo reale |
| Ottimizzato per | Elaborazione batch su larga scala | Bassa latenza e alta disponibilità |
| Pubblico principale | Utente aziendale interno | Cliente |
| Abilita | Report e dashboard | Applicazioni in produzione |
| Esempi | Previsione delle vendite Scoring dei lead Segmentazione dei clienti Previsioni di abbandono | Raccomandazioni di prodotti Rilevamento delle frodi Previsione del traffico Pricing in tempo reale |
Caratteristiche del ML analitico e del ML operativo
Machine learning operativo in pratica
Diamo uno sguardo più da vicino a un esempio concreto di machine learning operativo in Uber Eats. Quando apri l'app, ti viene suggerito un elenco di ristoranti e quanto tempo dovrai attendere prima che l'ordine arrivi a casa tua. Ciò che appare semplice nell'app è in realtà piuttosto complesso dietro le quinte:
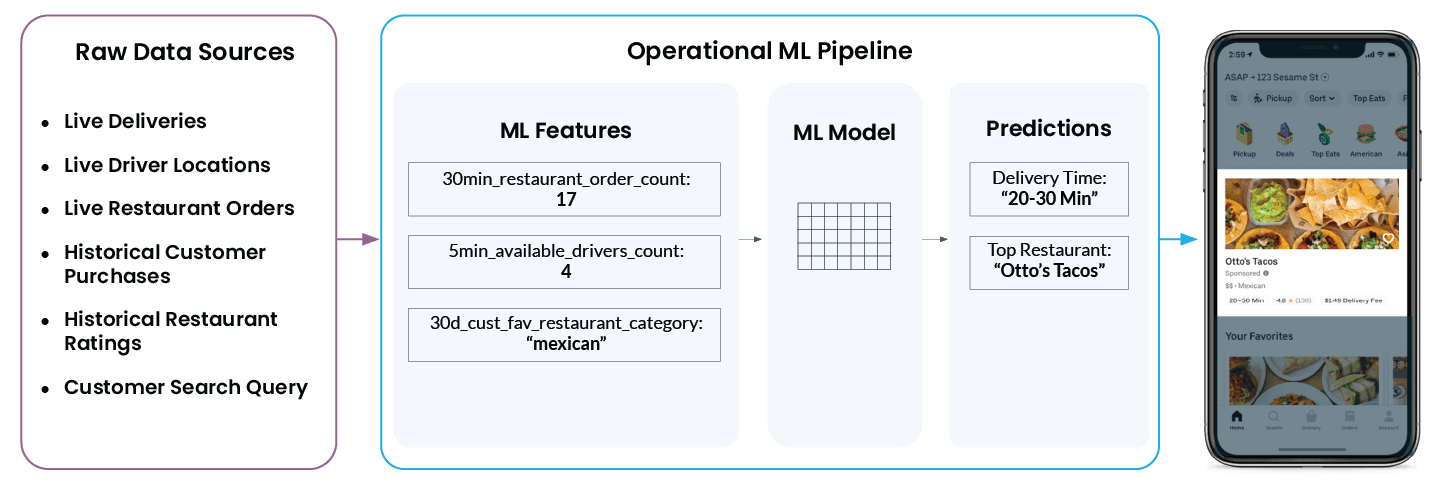
Per arrivare a mostrare "Otto’s Tacos" e "20-30 min" nell'app, la piattaforma di ML di Uber deve prendere in esame un'ampia gamma di dati provenienti da sorgenti di dati grezzi diverse:
- Quanti driver si trovano nelle vicinanze del ristorante in questo momento? Stanno consegnando un ordine o sono disponibili per la prossima assegnazione?
- Quanto è impegnata la cucina del ristorante in questo momento? Più ordini un ristorante sta elaborando, più tempo impiegherà per iniziare a lavorare su un nuovo ordine.
- Quali ristoranti sono stati valutati positivamente o negativamente dal cliente in passato?
- Che tipo di cucina sta cercando attivamente l'utente, se ve n'è una?
- E infine, qual è la posizione attuale dell'utente?
La piattaforma di feature di Michelangelo converte questi dati in feature utilizzabili dai modelli di ML. Questi sono i segnali su cui un modello viene addestrato e che utilizza per fare previsioni in tempo reale. Ad esempio, ‘num_orders_last_30_min’ viene utilizzata come feature di input per prevedere il tempo di consegna che alla fine verrà visualizzato nella tua app mobile.
I passaggi che ho descritto sopra, che trasformano i dati grezzi provenienti da una miriade di sorgenti diverse in feature, e le feature in previsioni, sono comuni a tutti i casi d'uso di machine learning operativo. Che un sistema cerchi di rilevare frodi sulle carte di credito, prevedere il tasso di interesse di un prestito auto, suggerire un articolo di giornale nella sezione Esteri o raccomandare il giocattolo migliore per un bambino di 2 anni, le sfide tecniche sono identiche. È proprio questa fondamentale comunanza tecnica che ci ha permesso di costruire una piattaforma centrale unica per tutti i casi d'uso di ML operativo.
Il playbook sull'AI agentiva per l'enterprise

I trend che rendono possibile il machine learning operativo
Uber era nella posizione ideale per sfruttare il ML operativo perché aveva costruito il proprio intero stack tecnologico su un'architettura dati moderna e su principi moderni. Nel corso degli ultimi anni, una modernizzazione simile si è progressivamente estesa ben oltre la Silicon Valley:
I dati storici vengono conservati quasi indefinitamente
I costi di storage dei dati sono crollati negli ultimi anni. Di conseguenza, le aziende sono state in grado di raccogliere, acquistare e archiviare informazioni su ogni punto di contatto con i clienti. Questo è cruciale per il ML: addestrare un buon modello richiede una grande quantità di dati storici. Senza dati, non c'è machine learning.
I silos di dati vengono progressivamente superati
Fin dal primo giorno, Uber ha centralizzato praticamente tutti i suoi dati nel proprio file system distribuito basato su Hive. L'archiviazione centralizzata dei dati (o, in alternativa, l'accesso centralizzato a data store decentralizzati) è importante perché consente ai data scientist, che addestrano i modelli di ML, di sapere quali dati sono disponibili, dove trovarli e come accedervi. La maggior parte delle aziende non ha ancora centralizzato tutti i propri dati (o l'accesso a essi). Tuttavia, trend architetturali come The Modern Data Stack stanno rendendo sempre più concreto il sogno dei data scientist di un accesso ai dati democratizzato.
Lo streaming rende disponibili dati in tempo reale
In Uber, abbiamo avuto la fortuna di avere un "sistema nervoso centrale" per i flussi di dati: Kafka. Molti segnali in tempo reale provenienti da servizi e app mobili vengono trasmessi in streaming tramite Kafka. Questo è fondamentale per il ML operativo.
Non puoi rilevare le frodi se sai solo cos'è successo ieri. Devi sapere cos'è successo negli ultimi 30 secondi. I data warehouse e i data lake sono progettati per l'archiviazione a lungo termine dei dati storici. E negli ultimi anni, abbiamo assistito a un'adozione massiccia di infrastrutture di streaming, come Kafka o Kinesis, per fornire alle applicazioni segnali in tempo reale.
MLOps abilita cicli di iterazione rapidi
In Uber, i singoli ingegneri sono messi nelle condizioni di apportare modifiche quotidiane al sistema in produzione. Questo processo è supportato dall’adozione e dall’automazione dei principi DevOps. Con Michelangelo, abbiamo portato questi principi nel ML operativo prima ancora che il processo venisse chiamato MLOps 🙂. Per noi era importante che i data scientist fossero in grado di addestrare i modelli e distribuirli in produzione in modo sicuro letteralmente nell'arco di una giornata.
Al di fuori di Uber, e ben al di fuori della Silicon Valley, abbiamo visto un numero crescente di early adopter applicare i principi DevOps e l'automazione non solo all'ingegneria del software, ma anche ai team di data science tramite MLOps. Naturalmente, per la maggior parte delle aziende il ML resta ancora molto più difficoltoso dello sviluppo software, per le ragioni che ho illustrato in questo blog. Ma sono convinto che il settore si stia muovendo gradualmente verso un futuro in cui il data scientist medio di una tipica organizzazione Fortune 500 sarà in grado di iterare su un modello di ML operativo più volte al giorno.
Ecco come si presenta una moderna architettura dati che abilita il ML operativo:
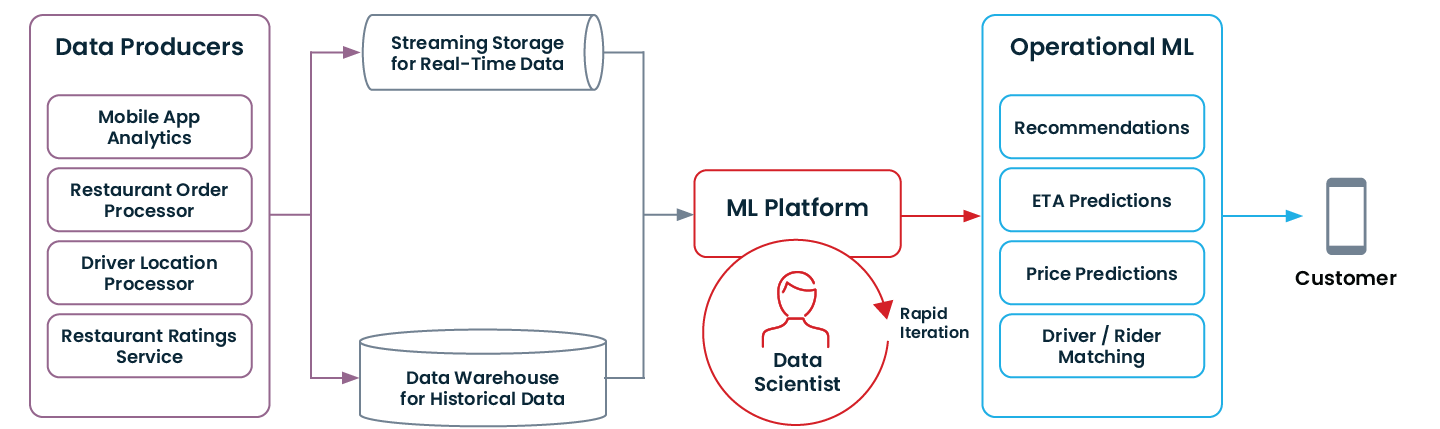
Se la tua organizzazione ha già adottato alcune delle modernizzazioni menzionate sopra (o ha iniziato da zero seguendo questi principi!), potrebbe essere pronta a passare al ML operativo.
Primi passi con il machine learning operativo
Nel 2013, Uber non utilizzava il machine learning in produzione. Al momento, esegue decine di migliaia di modelli in produzione. Questo cambiamento non è avvenuto dall'oggi al domani.
Se stai cercando di sfruttare il ML operativo nella tua organizzazione, ti consiglio di seguire questi passaggi:
Scegli un caso d'uso adatto al machine learning
Non tutti i problemi possono essere risolti con il ML. Criteri che qualificano un problema come potenzialmente adatto al ML:
- Il tuo sistema prende un numero elevato di decisioni molto simili e ripetute (almeno decine di migliaia)
- Prendere la decisione corretta non è banale
- Dopo un certo intervallo di tempo, c'è un modo per determinare se la decisione presa è stata buona o cattiva
In presenza di questi elementi, un'applicazione di machine learning può prendere decisioni, apprendere da esse e migliorare nel tempo.
Scegli un caso d'uso che sia davvero importante
Come accennato in precedenza, il percorso per portare il primo modello in produzione è tutt'altro che semplice. Se il potenziale ritorno della tua prima applicazione di machine learning è limitato, sarà fin troppo facile arrendersi quando le difficoltà aumenteranno. Le priorità cambieranno, la leadership potrebbe diventare impaziente e l'iniziativa finirà per arenarsi. Scegli un caso d'uso ad alto potenziale.
Dai autonomia a un piccolo team e limita gli stakeholder per il tuo primo modello
La probabilità di fallimento di un progetto aumenta con il numero di passaggi di consegna coinvolti nell'addestramento e nella messa in produzione di un modello. Idealmente, dovresti iniziare con un team molto ridotto di 2–3 persone che abbiano accesso a tutti i dati necessari, sappiano addestrare un modello semplice e conoscano lo stack quanto basta per portare un'applicazione in produzione.
Gli ML engineer sono i profili più adatti a spianare la strada, poiché in genere possiedono una rara combinazione di competenze in data engineering, software engineering e data science. È con questo stesso approccio che dovresti scalare i team di machine learning: piccoli gruppi di esperti di ML integrati nei team di prodotto.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.