data Lake su Azure
Sorgente di dati completa e autorevole per alimentare la tua lakehouse
Cos'è un data lake?
Dati, analisi e carichi di lavoro IA possono essere eseguiti su una piattaforma semplice, aperta e collaborativa, nativa per il cloud, che si integra facilmente con gli strumenti di sicurezza e gestione dell'azienda, consentendo di estendere le politiche di governance esistenti, per operare con la massima tranquillità e più controllo.

Che cos'è un Azure data lake?
Un Azure data lake includecloud servizi scalabili, di archiviazione dati e analitiche. Azure data lake Storage consente alle organizzazioni di archiviare dati di qualsiasi dimensione, formato e velocità per un'ampia varietà di casi d'uso di elaborazione, analitiche e Data Science . Se utilizzato con altri servizi Azure , ad esempio Azure Databricks , Azure data lake Storage rappresenta un modo molto più conveniente per archiviare e recuperare dati nell'intera organizzazione.
Che i tuoi dati siano grandi o piccoli, veloci o lenti, strutturati o non strutturati, Azure data lake si integra con identità, gestione e sicurezza Azure per semplificare la gestione dei dati e la governance. L'archiviazione di Azure crittografa automaticamente i dati e Azure Databricks fornisce strumenti per salvaguardare i dati e soddisfare le esigenze di sicurezza e conformità della tua organizzazione.

Perché ti serve un Azure data lake?
i data Lake sono in formato aperto, quindi gli utenti evitano di vincolarsi a un sistema proprietario come un data warehouse. Gli standard e i formati aperti sono diventati sempre più importanti nelle moderne architetture di dati. I data Lake sono inoltre estremamente durevoli e a basso costo grazie alla loro capacità di Scale e sfruttare l'archiviazione di oggetti. Inoltre, le analisi avanzate e machine learning su dati non strutturati rappresentano oggi alcune delle priorità più strategiche per le imprese. La capacità unica di acquisire dati grezzi in una varietà di formati (strutturati, non strutturati e semistrutturati) insieme agli altri vantaggi menzionati rendono un data lake la scelta chiara per l'archiviazione dei dati.
Se adeguatamente architettati, i data Lake offrono la possibilità di:
- Power Data Science e machine learning
- Centralizza, consolida e cataloga i tuoi dati
- Integra rapidamente e senza soluzione di continuità diverse sorgenti di dati e formati
- Democratizza i tuoi dati offrendo agli utenti strumenti self-service
Qual è la differenza tra un Azure data lake e un Azure data warehouse?
Un data lake è una posizione centrale che contiene una grande quantità di dati nel loro formato nativo non elaborato, nonché un modo per organizzare grandi volumi di dati altamente diversificati. Rispetto a un data warehouse gerarchico, che archivia i dati in file o cartelle, un data lake utilizza un'architettura piatta per archiviare i dati. i data Lake sono generalmente configurati su cluster di hardware di base scalabile. Di conseguenza, puoi archiviare i dati grezzi nel lago nel caso in cui siano necessari in una data futura, senza preoccuparti del formato, delle dimensioni o della capacità di archiviazione dei dati.
Inoltre, data lake clusters possono esistere on-premise o nel cloud. Storicamente, il termine "data lake" è stato spesso associato allo storage di oggetti orientato a Hadoop, ma oggi il termine si riferisce generalmente alla categoria più ampia di storage di oggetti. Lo storage a oggetti memorizza i dati con tag di metadati e un identificatore univoco, che semplifica l'individuazione e il recupero dei dati tra le regioni e migliora le prestazioni. La piattaforma Databricks Lakehouse rende disponibili tutti i dati nel tuo data lake per qualsiasi numero di casi d'uso basato su dati / guidato dai dati.

Perché usare Delta Lake il formato per il Azure data lake?
Ecco cinque motivi principali per convertire data Lake da Apache Parquet, CSV, JSON e altri formati al formatoDelta Lake :
- Prevenire il danneggiamento dei dati
- Query più veloci
- Aumenta l'aggiornamento dei dati
- Riprodurre modelli ML
- Ottenere la conformità
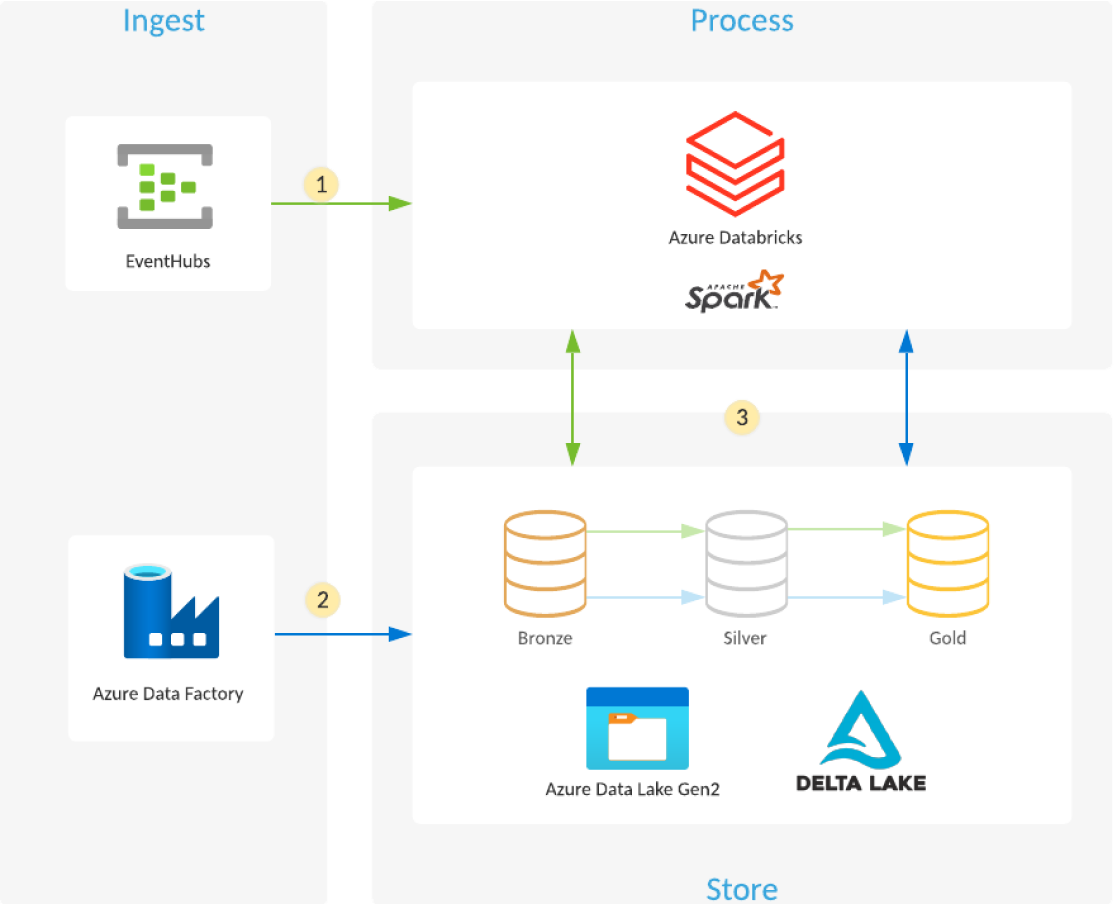
Come si crea un data lake utilizzando Azure Databricks e Azure data lake Storage?
Delta Lake gestito in Azure Databricks fornisce un livello di affidabilità che ti consente di curare, analizzare e ricavare valore dal tuo data lake sul cloud.
- Azure Databricks legge streaming i dati dalle code di eventi, ad esempio Azure Hub eventi , Azure IoT Hub o Kafka, e carica gli eventi non elaborati in Delta Lake tabelle e cartelle ottimizzate e compresse (livello Bronze) archiviate in Azure data lake Storage.
- La pipeline di Azure Data Factory pianificata o attivata copia i dati da diverse sorgenti di dati nel loro formato non elaborato in Azure data lake Storage. Il Auto Loader in Azure Databricks elabora i file non appena arrivano e li carica in tabelle e cartelle Delta Lake ottimizzate e compresse (livello Bronze) archiviate in Azure data lake Storage.
- streaming o pianificato/attivato Azure Databricks legge le nuove transazioni dal livello Bronze e quindi le unisce, pulisce, trasforma e aggrega prima di utilizzare le transazioni ACID (INSERT, UPDATE, DELETE, MERGE) per caricarle in set di dati curati (livelli Silver e Gold ) archiviati in Delta Lake in Azure data lake Storage.
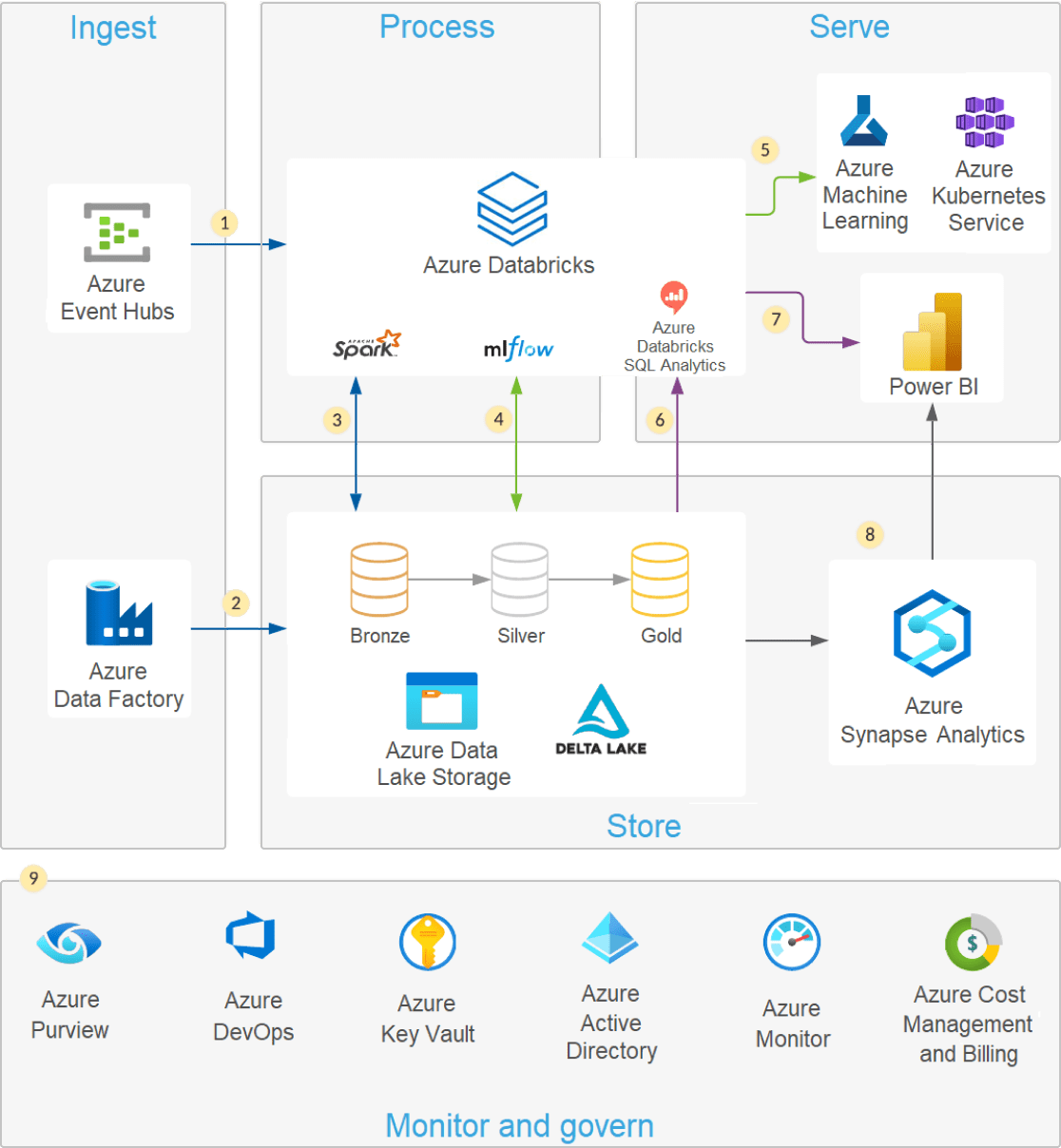
Architettura moderna data lake
Una moderna architettura lakehouse che combina le prestazioni, l'affidabilità e l'integrità dei dati di un warehouse con la flessibilità, Scale e il supporto per i dati non strutturati disponibili in un data lake.
I moderni data lake sfruttano l'elasticità del cloud per archiviare quantità virtualmente illimitate di dati "così come sono", senza la necessità di imporre uno schema o una struttura. Structured Query Language (SQL) è un potente linguaggio di interrogazione per esplorare i tuoi dati e scoprire preziose conoscenze/approfondimento/informazioni dettagliate. Delta Lake è un livello di storage open source che offre affidabilità al data Lake con transazioni ACID, gestione scalabile dei metadati ed elaborazione unificata dei dati streaming ed batch . Delta Lake è completamente compatibile e offre affidabilità al tuo data lake esistente.
Puoi eseguire facilmente query sul tuo data lake utilizzando SQL e Delta Lake con Azure Databricks. Delta Lake ti consente di eseguire query SQL sia sui dati in streaming che su quelli batch senza spostare o copiare i dati. Azure Databricks offre vantaggi aggiuntivi quando si lavora con Delta Lake per proteggere il data lake tramite l'integrazione nativa con i servizi cloud , offre prestazioni ottimali e aiuta a controllare e risolvere i problemi della pipeline di dati.
- Delta Lake si integra con lo storage cloud scalabile o HDFS per contribuire a eliminare i silos di dati
- Esplora le tue query SQL sull'utilizzo dei dati e un livello di transazione conforme ad ACID direttamente sul tuo data lake
- Sfrutta le "tabelle a medaglione" Gold, Silver e Bronze per consolidare e semplificare la qualità dei dati per la tua pipeline di dati e flussi analitici di lavoro
- Utilizza Delta Lake time travel per vedere come sono cambiati i tuoi dati nel tempo
- Azure Databricks ottimizza le prestazioni con funzionalità come la cache Delta, la compattazione dei file e l'esclusione dei dati