Costruisci ETL di produzione con i flussi dichiarativi di Lakeflow
Progettata per le moderne analisi e i carichi di lavoro AI, questa architettura di riferimento fornisce una solida base scalabile per la costruzione e l'automazione di pipeline di estrazione, trasformazione, caricamento (ETL) su dati batch e in streaming.
Riassunto dell'architettura
Questa architettura di riferimento è ben adatta per le organizzazioni che cercano di unificare i pipeline di batch e streaming sotto un unico framework dichiarativo, garantendo allo stesso tempo l'affidabilità, la qualità e la governance dei dati ad ogni stadio. Sfrutta la piattaforma Databricks Data Intelligence per semplificare la gestione dei pipeline, imporre aspettative sui dati e fornire intuizioni in tempo reale con osservabilità e automazione integrate.
Supporta una vasta gamma di scenari di ingegneria e analisi dei dati, dall'ingestione e trasformazione dei dati a flussi di lavoro complessi con controlli di qualità in tempo reale, logica aziendale e recupero automatico. Le organizzazioni che adottano questa architettura cercano spesso di modernizzare l'ETL legacy, ridurre il sovraccarico operativo e accelerare la consegna di dati curati e di alta qualità per l'intelligence aziendale, l'apprendimento automatico e le applicazioni operative.
Casi Tecnici di Utilizzo
- Questa architettura consente pipeline di cattura dei dati di modifica (CDC) che applicano incrementalmente gli aggiornamenti dai sistemi sorgente nel lakehouse
- Gli ingegneri dei dati possono costruire modelli a dimensione variabile lentamente (SCD) per gestire modelli dimensionali negli strati analitici
- Le pipeline di streaming possono essere costruite in modo resiliente per gestire eventi fuori ordine e dati in ritardo con watermark e checkpointing
- Gli ingegneri dei dati possono imporre l'evoluzione dello schema e le regole di qualità automatizzate utilizzando vincoli dichiarativi
- Gli ingegneri dei dati possono automatizzare il tracciamento della genealogia dei dati e la registrazione degli audit su tutto il pipeline senza strumentazione manuale
Casi d'uso aziendali
- Le aziende di vendita al dettaglio e di beni di consumo (CPG) possono utilizzare questa architettura per costruire cruscotti in tempo reale che monitorano le vendite, l'inventario e il comportamento dei clienti su più canali
- Integrando i dati provenienti da transazioni, interazioni digitali e sistemi CRM, le istituzioni finanziarie possono supportare il rilevamento delle frodi e la segmentazione dei clienti
- Le organizzazioni sanitarie possono elaborare e normalizzare i dati dei dispositivi medici e le cartelle cliniche dei pazienti per ottenere intuizioni cliniche e rapporti di conformità
- I produttori possono combinare i dati dei sensori IoT con i log storici per guidare la manutenzione predittiva e l'ottimizzazione della catena di fornitura
- I fornitori di telecomunicazioni possono unificare i dati del CRM e della telemetria di rete per modellare l'abbandono dei clienti e i modelli di utilizzo in tempo quasi reale
Capacità chiave
- Sviluppo di pipeline dichiarative: Definisci le pipeline utilizzando SQL o Python, astrai la logica di orchestrazione
- Supporto per batch e streaming: Gestisci sia i carichi di lavoro in tempo reale che quelli programmati in un framework unificato
- Controllo della qualità dei dati: Applica le aspettative direttamente nella pipeline per rilevare, bloccare o mettere in quarantena i dati errati
- Osservabilità e discendenza: Monitoraggio integrato, allarmi e tracciamento visivo della discendenza migliorano la trasparenza e il troubleshooting
- Gestione degli errori e recupero: Rileva e recupera automaticamente da errori in qualsiasi fase del pipeline
- Governance con Unity Catalog: Applica controlli di accesso granulari, audita l'uso dei dati e mantiene la classificazione dei dati in tutto lo stack
- Esecuzione ottimizzata: Sfrutta Spark e Photon sotto il cofano per un elaborazione scalabile e ad alte prestazioni
- Operazioni automatizzate: Le pipeline possono essere versionate, distribuite e gestite attraverso CI/CD, con supporto per la pianificazione e la parametrizzazione
Dataflow
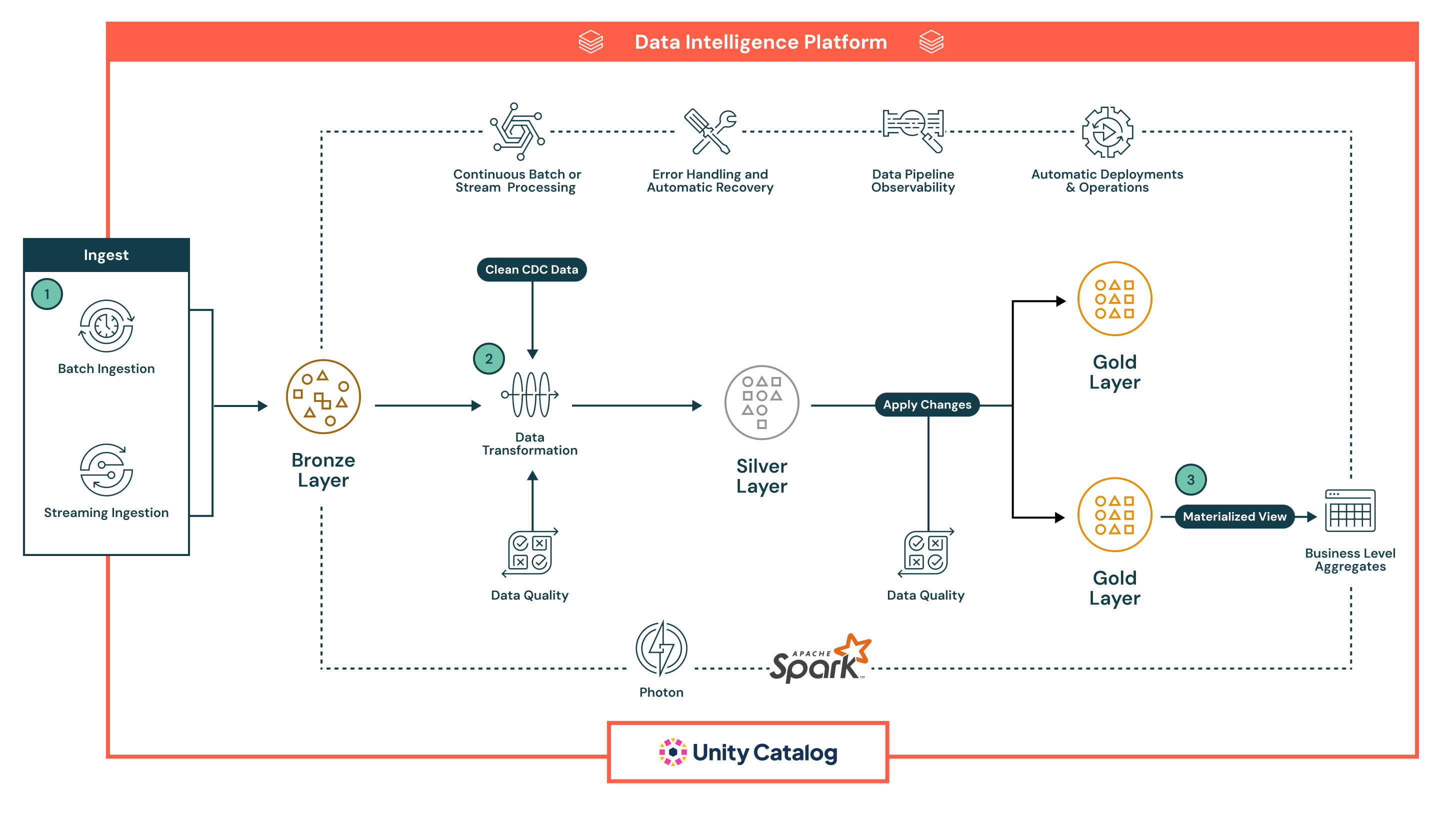
L'architettura segue una robusta architettura a medaglione multistrato medallion architecture, potenziata dalle capacità integrate dei Pipelines Dichiarativi di Lakeflow per l'automazione, la governance e l'affidabilità. Ogni fase del pipeline è dichiarativa, osservabile e ottimizzata sia per i casi d'uso di batch che di streaming:
- I Pipelines Dichiarativi di Lakeflow supportano sia l'ingestione batch che streaming, fornendo un modo unificato e automatizzato per portare i dati nel lakehouse.
- L'ingestione batch carica i dati secondo un programma o un trigger, ideale per i flussi di lavoro ETL periodici. Supporta carichi completi e incrementali da storage cloud e database. A differenza degli strumenti tradizionali, il dichiarativo gestisce nativamente l'orchestrazione, i tentativi e l'evoluzione dello schema, riducendo la necessità di pianificatori esterni o script.
- Ingestione in streaming elabora continuamente i dati da fonti come Kafka e Event Hubs utilizzando Structured Streaming. Declarative Pipelines gestisce il checkpointing, la gestione dello stato e l'autoscaling out of the box, eliminando la configurazione manuale tipicamente richiesta nelle pipeline di streaming.
Tutti i dati atterrano prima nello strato Bronze in forma grezza, consentendo piena discendenza, tracciabilità e riprocessamento sicuro. L'approccio dichiarativo delle pipeline, i controlli di qualità integrati e la gestione automatica dell'infrastruttura riducono significativamente la complessità operativa e facilitano la costruzione di pipeline resilienti e di produzione, qualcosa che la maggior parte degli strumenti ETL legacy fatica a fornire nativamente.
- Dopo l'ingestione, i dati possono essere elaborati nel strato Silver, dove vengono puliti, uniti e arricchiti per prepararsi al consumo a valle.
- Le pipeline sono definite utilizzando SQL dichiarativo o Python, rendendo le trasformazioni facili da leggere, mantenere e versionare. Le trasformazioni vengono eseguite utilizzando Apache Spark™ con Photon, fornendo un elaborazione scalabile e ad alte prestazioni.
- I controlli di qualità dei dati vengono applicati in linea utilizzando aspettative, una funzionalità nativa di Declarative Pipelines che consente ai team di imporre regole di convalida (ad es., controlli null, tipi di dati, limiti di intervallo). I dati non validi possono essere configurati per eliminare i record errati, metterli in quarantena o far fallire la pipeline, garantendo che i sistemi a valle ricevano solo dati affidabili.
- La pipeline gestisce automaticamente il tracciamento delle dipendenze dei lavori, i tentativi di task e l'isolamento degli errori, riducendo il sovraccarico operativo. Questo garantisce che i dati elaborati nello strato Silver siano accurati, coerenti e pronti per la produzione, mantenendo al contempo la semplicità operativa.
- Nel strato Gold, la pipeline genera aggregati a livello aziendale e set di dati curati pronti per il consumo.
- Questi output sono ottimizzati per l'uso in dashboard BI, funzionalità di apprendimento automatico e sistemi operativi
- Declarative Pipelines supporta tabelle temporali e logica SCD, consentendo casi d'uso avanzati come il tracciamento storico e la generazione di report di audit
- In tutti gli strati, Declarative Pipelines fornisce un'ampia osservabilità e discendenza delle pipeline.
- L'interfaccia utente mostra grafici di flusso di dati, metriche operative e cruscotti di qualità per supportare la risoluzione rapida dei problemi e la generazione di report di conformità
- Con l'integrazione di Unity Catalog, ogni tabella, colonna e trasformazione è governata attraverso il controllo di accesso centralizzato, la registrazione degli audit e la classificazione dei dati
- Le pipeline sono pronte per la produzione per progettazione.
- I team possono implementare Pipelines Dichiarativi utilizzando definizioni controllate da versione, programmarli tramite Lakeflow Jobs e gestirli attraverso strumenti CI/CD come GitHub Actions o Azure DevOps
- Questa automazione sostituisce gli script fragili e le configurazioni di orchestrazione complesse, aiutando i team di dati a concentrarsi sulla logica aziendale piuttosto che sull'infrastruttura
Consigli

Video on-demand

Video on-demand
Tour di prodotto

Architettura di settore
