Architettura di riferimento per l'ingestione dei dati
Questa architettura di riferimento per l'ingestione dei dati fornisce una base semplificata, unificata ed efficiente per il caricamento dei dati da diverse fonti aziendali nella Piattaforma di Intelligenza dei Dati Databricks.
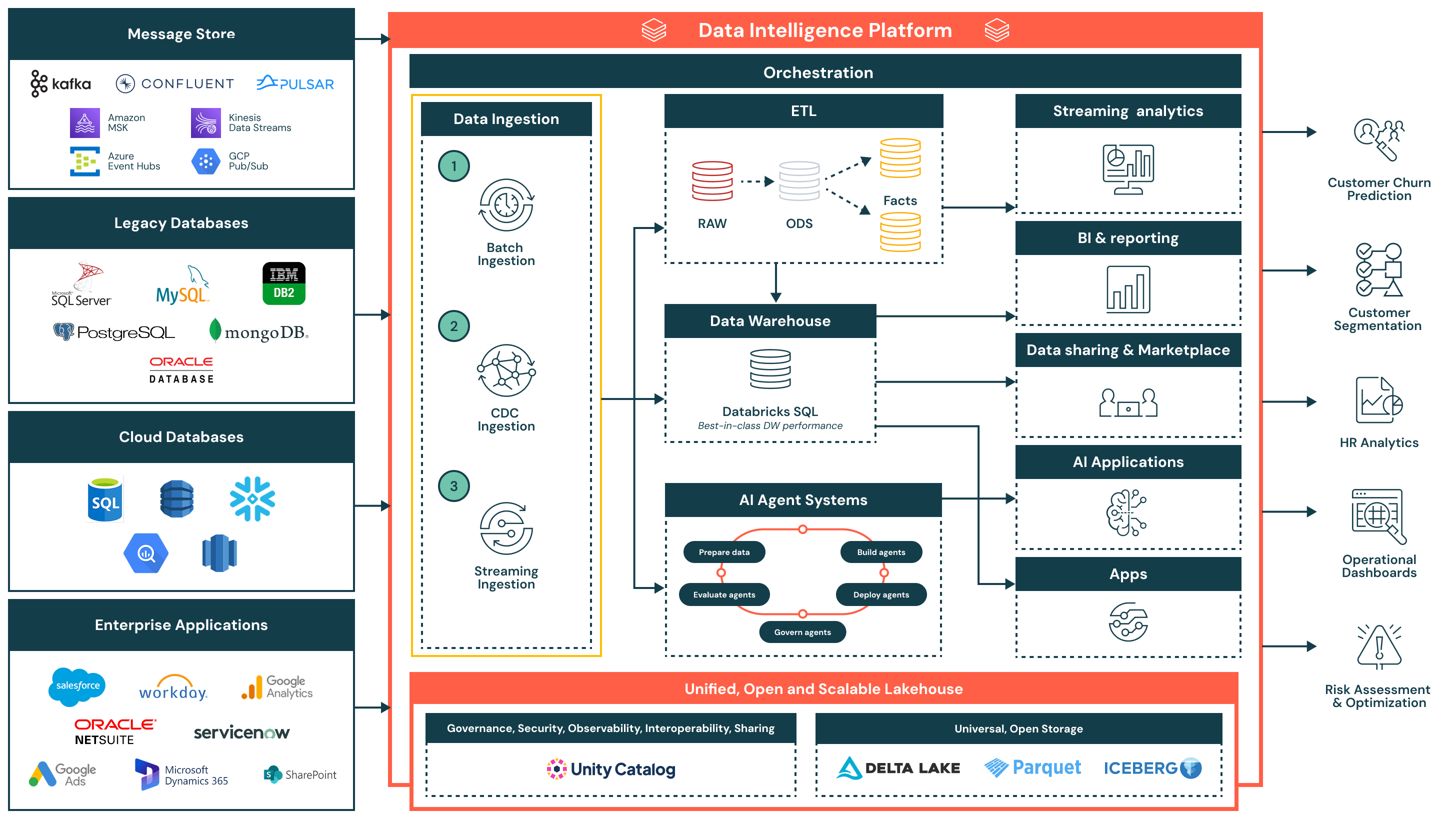
Riassunto dell'architettura
L'architettura di riferimento per l'ingestione dei dati supporta una vasta gamma di modelli di ingestione, tra cui batch, change data capture (CDC) e streaming, garantendo al contempo governance, performance e interoperabilità. Una volta ingeriti, i dati vengono raffinati e resi disponibili per l'analisi, l'IA e la condivisione sicura dei dati in tutta l'organizzazione.
Questa architettura è ideale per le organizzazioni che cercano di modernizzare e operativizzare i flussi di dati riducendo al contempo la complessità e il sovraccarico di integrazione. È costruita attorno a tre principi chiave:
- Semplice e a bassa manutenzione: Le pipeline di ingestione sono facili da costruire e gestire, consentendo un tempo di valore più rapido, meno colli di bottiglia operativi e un accesso più ampio ai dati tra i team
- Unificata con l'architettura del lakehouse: I dati fluiscono direttamente nel lakehouse utilizzando formati aperti e governati dal Catalogo Unity - garantendo la coerenza tra i casi d'uso di BI, AI e operativi
- Flusso efficiente end-to-end: Dall'ingestione alla trasformazione e consegna, la piattaforma supporta un elaborazione incrementale ed efficiente che minimizza la duplicazione, la latenza e l'uso delle risorse
Casi d'uso
Casi Tecnici di Utilizzo
- Periodico ingestione batch da file piatti, esportazioni o API nelle zone di staging
- Cattura dei cambiamenti dei dati (CDC) ingestione per sincronizzare incrementalmente gli aggiornamenti dai sistemi transazionali come Oracle o PostgreSQL
- Ingestione in streaming di eventi in tempo reale da Kafka o code di messaggi per l'uso in cruscotti in tempo reale o sistemi di allerta
- Armonizzando l'ingestione attraverso sistemi legacy, database nativi del cloud e applicazioni SaaS aziendali
- Alimentando dati curati e trasformati in data warehouse, applicazioni AI e API esterne
Casi d'uso aziendali
- Previsione dell'abbandono dei clienti ingerendo dati comportamentali, transazionali e di supporto
- Alimentazione dei cruscotti esecutivi con metriche operative fresche dai sistemi ERP e CRM
- Segmentazione dei clienti combinando dati di campagna, vendite e utilizzo del prodotto
- Conduzione di analisi HR integrando dati da Workday e piattaforme di produttività
- Esecuzione di valutazioni del rischio analizzando transazioni e feed di allerta in tempo quasi reale
Flusso di ingestione dei dati e capacità chiave
- Ingestione batch
- Carica dati a intervalli programmati o su richiesta da fonti come file piatti, API o esportazioni di database
- Adatto per report giornalieri, carichi di dati storici e snapshot del sistema di record
- Supporta sia carichi completi che incrementali, con programmazione nativa, logica di riprova e trasformazione utilizzando SQL o Python
- Ingestione di change data capture (CDC)
- Cattura le modifiche incrementali dai sistemi transazionali come Oracle, PostgreSQL e MySQL
- Mantiene le tabelle del lakehouse aggiornate senza ricariche complete, migliorando l'efficienza e la freschezza dei dati
- Consente la sincronizzazione dei dati quasi in tempo reale per le tabelle dei fatti, le tracce di audit e gli strati di reporting
- Ingestione di streaming
- Elabora continuamente dati da fonti di eventi come Kafka, Kinesis, Pub/Sub o Event Hubs
- Ideale per cruscotti in tempo reale, sistemi di allerta e rilevamento di anomalie
- Lo Streaming Strutturato gestisce stato, tolleranza ai guasti e throughput, riducendo il sovraccarico operativo
Capacità aggiuntive della piattaforma
- Governance unificata
- Catalogo Unity fornisce una governance unificata, inclusi controllo degli accessi, genealogia e tracciamento degli audit
- I dati sono memorizzati in formati aperti e interoperabili utilizzando Delta Lake e Apache Iceberg™, garantendo flessibilità e interoperabilità tra strumenti e ambienti
- Un livello di orchestrazione centralizzato gestisce la programmazione delle pipeline, le dipendenze, il monitoraggio e il recupero
- Architettura del lakehouse: I dati ingeriti vengono trasformati e modellati nell'architettura medaglione (Bronzo, Argento e Oro), alimentando interrogazioni ad alte prestazioni in Databricks SQL
- Orchestrazione: L'orchestrazione integrata gestisce i flussi di dati, i flussi di lavoro AI e i lavori programmati tra i carichi di lavoro batch e streaming, con supporto nativo per la gestione delle dipendenze e la gestione degli errori
- AI e sistemi di agenti: I dati alimentano i sistemi di agenti per la preparazione delle caratteristiche, la valutazione dei modelli e il dispiegamento di applicazioni alimentate da AI
- Consumo a valle:
- Analisi in streaming: Visualizzazione in tempo reale di metriche chiave e segnali operativi
- BI/analisi: Set di dati curati serviti a strumenti come Power BI, Lakeview e client SQL
- Applicazioni AI: Set di dati governati consumati da pipeline di addestramento e motori di inferenza
- Condivisione dei dati e marketplace: Condivisione sicura di dati interni ed esterni tramite Delta Sharing
- Applicazioni operative: Intelligenza incorporata e intuizioni contestuali negli strumenti aziendali
Consigli

Architettura di riferimento

Architettura di riferimento

Architettura di settore

Architettura di settore
Architettura di riferimento