Community Editionに代わり、Free Editionでは無料でより充実した機能をご利用いただけます。ぜひ今日からぜひFree Editionをお試しください。
2020年4月14日初稿、2020年4月21日更新
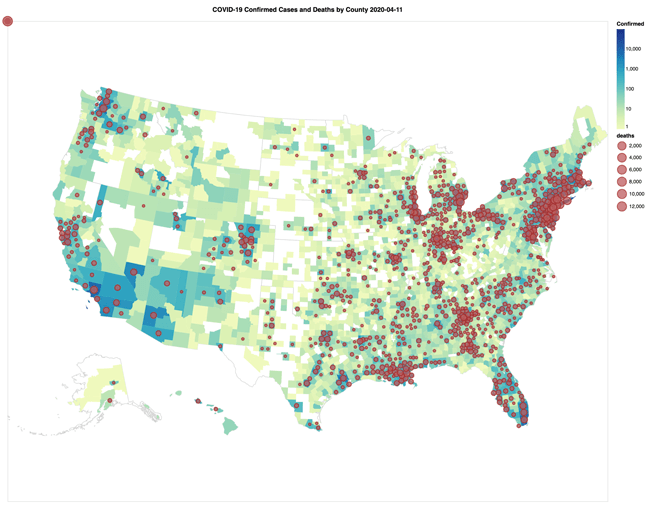
新型コロナウイルス感染症(COVID-19)の感染拡大による混乱の中、データエンジニアやデータサイエンティストの多くが「データコミュニティとして何ができるだろうか」と自問し続けています。データコミュニティは、この短期間で実際に大きな貢献をしており、その代表例として、米国ジョンズ・ホプキンス大学のシステム科学工学センター(CSSE)が提供するデータリポジトリが挙げられます。このデータセットは�、COVID-19(2019-nCoV)について最も広く利用されているものの1つです。次のGIF動画は、3月22日から4月14日にかけての検査確定症例(郡地域)と死亡者(円で表現)の比例数を視覚的に示しています。
他にも、病原体の進化をリアルタイムで追跡できる新型コロナウイルスのゲノム情報などの例があります(マウスのクリックで感染と系統が再生を再生します)。
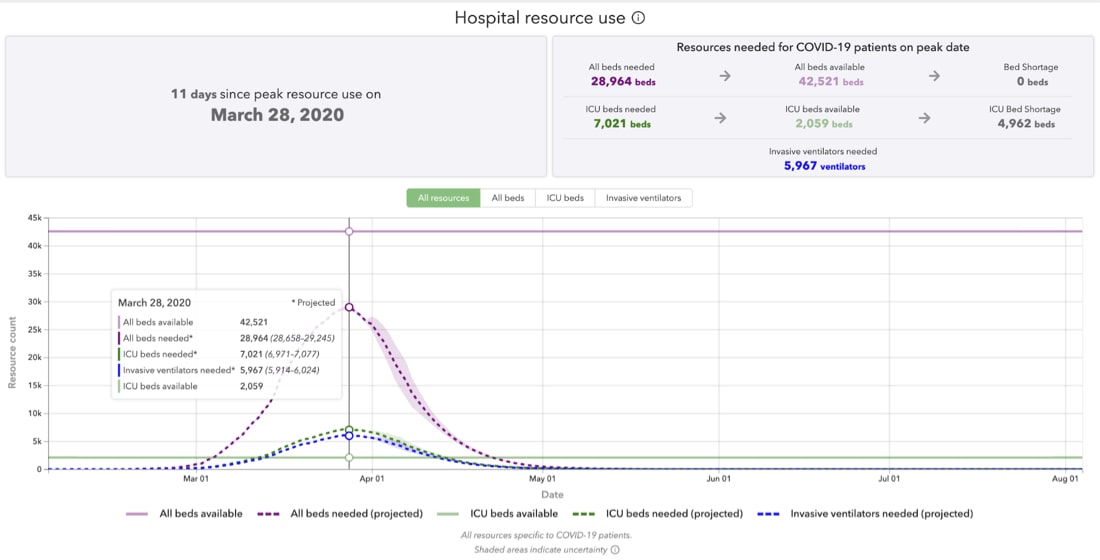
病院からのリソース使用率のモデリングの有力な例には、ワシントン大学保健指標評価研究所(IHME)によるCOVID-19に関する予測があります。次のスクリーンショットは、病院リソースの予測使用率のメトリックを示しており、2020年3月28日がリソース使用量のピークであったことがわかります。
いかに貢献できるか
データブリックスでは、COVID-19の克服は現時点で世界で最も困難な問題であり、重要な意思決定を支援するには、基礎となるデータを理解することが大切だと考えています。そこで私たちは、データ探索の初心者からデータ専門家までの誰もがこの取り組みに参加できるよう、対策を講じました。
対策の一環として、COVID-19データセットの分析の入門編として「COVID-19の分析:データコミュニティはいかに貢献できるか」をテーマとした技術トークのセッションを3月の下旬に開催しました。本セッションでは、Apache Spark™、Python、pandas、BERTなどのさまざまなオープンソースプロジェクトを用いて、探索的データ分析と自然言語処理(NLP)を行いました。また、これらのNotebookをダウンロードできる�ようにして、ローカルのPython仮想環境、クラウドコンピューティング、Databricks Community Editionなど、ユーザーが好む環境を選択して使用できるようにしました。
このセッションでは、新型コロナウイルスに関する研究データセットのCORD-19(COVID-19 Open Research Dataset Challenge)を分析し、次の点を確認しました。
- 数千のJSONファイルが存在し、各ファイルに参照文献など研究論文のテキストの詳細が含まれているが、JSONスキーマは複雑で、データ処理の作業は難しくなる場合がある。これに対して、Apache SparkはこれらのJSONファイルのスキーマを迅速かつ自動的に推論できるため、このNotebookを使用して、数千ものJSONファイルをわずか数個のParquetファイルに保存し、探索的データ分析を容易に実行できる。
- 大半のテキストは構造化されておらず、筆頭著者の国名の特定ができないなど、データ品質の問題がある。このNotebookでは、このデータをクリーンアップし、ISO Alpha 3の国名コードを特定する手順を提供している。これにより、筆頭著者の国別の論文数をマッピングできる。
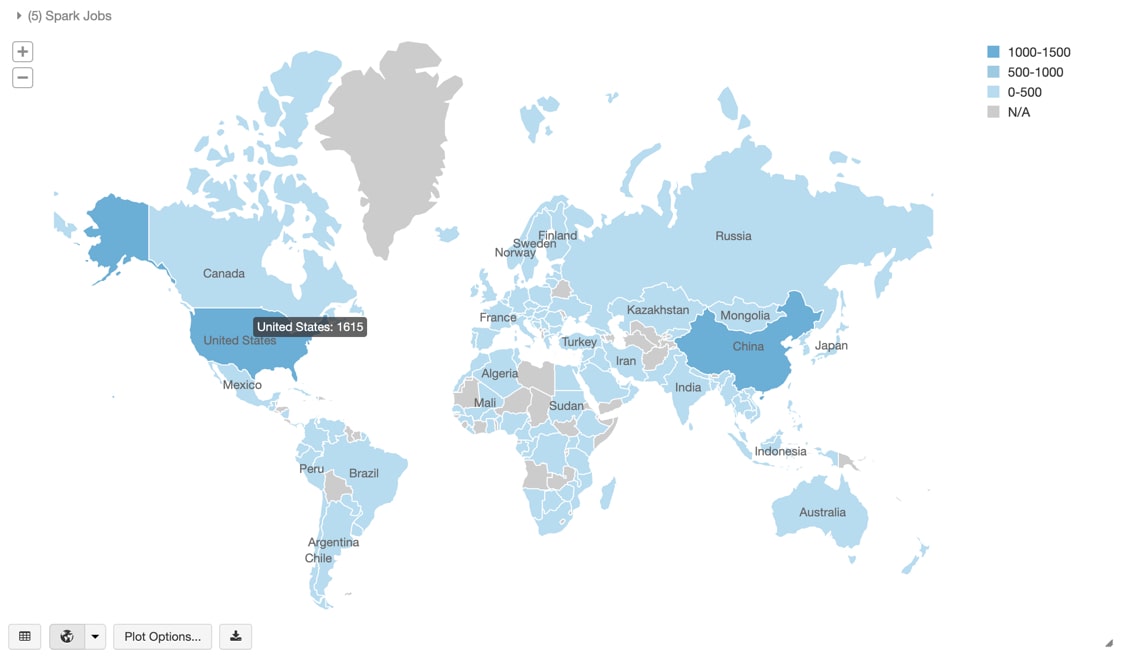
(出典:「COVID-19の分析:データコミュニティはいかに貢献できるか」)
- データをクリーンアップすることで、各種NLPアルゴリズムの適用が可能になり、データから新たな気づきを得ることができる。このNotebookは、論文の抄録(論文あたり7,800から1,100文字)の一般化や、研究論文タイトルをもとにしたワードクラウドの作成など(下図)、さまざまなタスクに利用できる。
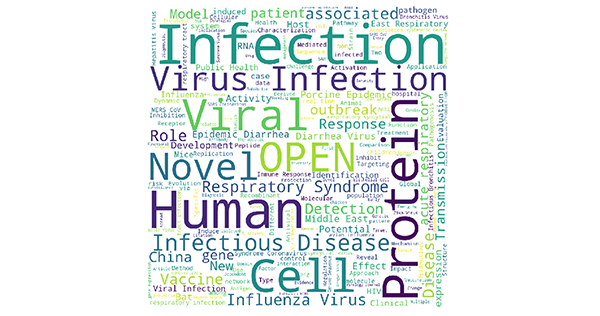
(出典:「COVID-19の分析:データコミュニティはいかに貢献できるか」)
データの重要性
データアナリスト、データエンジニア、データサイエンティストの多くが認めるように、データの品質は探索的データ分析に大きな影響を及ぼします。ブログ、A Few Useful Things to Know about Machine Learning(2012年10��月)(機械学習について知っておくべきこと)に、次のような記述があります。
「ダメなアルゴリズムと膨大なデータの組み合わせは、賢いアルゴリズムと少なめの量のデータの組み合わせに勝つ(アルゴリズムの善し悪しより、データ量が重要)」
ここで重要なのは、高品質データを大量に持つことの重要性を強調していることです。ただし、特徴量エンジニアリングの大切さや、データだけでは不十分であるといった、機械学習における他の側面を矮小化する意図はありません。
データコミュニティの多くは、さまざまなSARS-CoV-2(原因)とCOVID-19(疾患)のデータセットをKaggleやGitHubで利用できるように、適宜取り組んでいます。
私たちは、データブリックスまたは Databricks Community Editionを使用しているユーザーが分析をより簡単に実行できるように、研究用のさまざまな COVID-19 データセットを定期的に更新、提供しています(非営利目的)。現在、更新しているのは下記のデータセットです。今後さらに追加される予定です。
| /databricks-datasets/[location] | リソース |
| /../COVID/CORD-19/ | COVID-19 Open Research Dataset Challenge (CORD-19) |
| /../COVID/CSSEGISandData/ | ジョンズ・ホプキンス大学 CSSEによる新型コロナウイルス感染症COVID-19(2019-nCoV)のデータリポリトジ |
| /../COVID/ESRI_hospital_beds/ | Definitive Healthcare社による米国内の病院のベッド数 |
| /../COVID/IHME/ | 米ワシントン大学医学部(IHME)による COVID-19 プロジェクション |
| /../COVID/USAFacts/ | USA Facts:感染者数 | 死亡者数 |
| /../COVID/coronavirusdataset/ | COVID-19のデータサイエンス(韓国) |
| /../COVID/covid-19-data/ | ニューヨーク・タイムズ紙のCOVID-19 データセット |
探索的データ分析のワークショップ
先般の技術トークが高評価をいただけたおかげで、COVID-19データセットを使用したPythonでの探索的データ分析のワークショップシリーズの開催が決まりました。ワークショップの様子はYouTubeで視聴できます。また、Notebookはhttps://github.com/databricks/tech-talksから利用可能になる予定ですので、お好みの環境で使用することができます。
データブリックス環境での Python 入門
このワークショップでは、無償版のDatabricks Community EditionのNotebook環境を使い、Pythonによるプログラミングに必要な簡単な手順を紹介します。Pythonは、データ分析、機械学習、Web開発など、用途の幅広さから人気のあるプログラミング言語です。このワークショップでは、データ分析に重点を置き、Pythonでコーディングを始めるための主要な基本概念を取り上げ、異なるタイプの変数、ループ、関数、条件文を学びます。プログラミングに関する予備知識は必要ありません。
このワークショップの参加対象者:どなたでも参加できます。コンピューターサイエンス専攻の学生、非技術系の方々の参加も歓迎します。プログラミングに関する知識は必要ありません。これまでにPythonのコースを受講したことがある方には、このワークショップは基礎的すぎる内容かもしれません。

pandas を使用したデータ分析
このワークショップでは、データ分析と操作のためのパワフルなオープンソースのPythonパッケージ、pandasを中心に取り組みます。データの読み取り、要約統計量の計算、データ分散の確認、基本的なデータクリーニングと変換の実行、そして簡単なデータの可視化のプロットを行う方法を学びます。ジョンズ・ホプキンス大学のシステム科学工学センター(CSSE)による新型コロナウイルス感染症(COVID-19)のデータセットを使用します。
このワークショップの参加対象者:どなたでも参加できます。コンピューターサイエンス専攻の学生、非技術系の方々の参加も歓迎します。Pythonに関する基礎知識があることが推奨されます。
準備:事前の準備は必要ありませんが、ワークショップは、Pythonに関する基礎知識があることを前提とした内容となっています。初めてPythonに触れる方には、データブリックスのPython入門チュートリアルでの事前学習をお勧めします。

scikit-learn による機械学習
scikit-learnは、データサイエンティストに最も人気のあるオープンソース機械学習ライブラリの1つです。このワークショップでは、機械学習の基礎、異なるタイプの機械学習、簡単な機械学習モデルの構築方法について段階的に説明します。ここでは、機械学習モデルを適用して評価する手法に焦点を当てるため、機械学習の背景にある統計的概念は学習内容に含まれません。ジョンズ・ホプキンス大学システム科学工学センター(CSSE)による新型コロナウイルス感染症(COVID-19)のデータセットを使用します。
このワークショップの参加対象者:どなたでも参加できます。コンピューターサイエンス専攻の学生、非技術系の方々の参加も歓迎します。Pythonおよびpandasに関する基礎知識があることを前提としています。初めてPythonおよびpandasに触れる場合は、事前学習として、データブリックスのPython入門チュートリアルを視聴した後に、pandasでデータ分析チュ�ートリアルに登録されることをお勧めします。

Apache Spark の概要
このワークショップでは、ビッグデータ処理エンジンとして最もポピュラーな Apache Spark の基礎について説明します。Sparkを活用して、データインジェスト、Spark UIの分析、分散コンピューティングの理解を深める方法を学習します。ニューヨーク・タイムズ紙の公開データを使用します。Sparkの予備知識は不要ですが、Pythonの経験があることが強く推奨されます。
このワークショップの参加対象者:どなたでも参加できます。コンピューターサイエンス専攻の学生、非技術系の方々の参加も歓迎します。Pythonおよびpandasに関する基礎知識があることを前提としています。初めてPythonおよびpandasに触れる方には、事前学習として、データブリックスのPython入門チュートリアルの視聴をお勧めします。

COVID-19 データセットの探索
COVID-19 データセットの分析をすぐに開始できるように、tech-talks/samplesフォルダに、ニューヨーク・タイムズ紙のCOVID-19データセットとジョンズ・ホプキンス大学システム科学工学センター(CSSE)による新型コロナウイルス感染症(2019-nCoV)のデータリポリトジのNotebookを追加しました。いずれのデータセットも定期的に更新され、/databricks-datasets/COVIDで利用可能です。
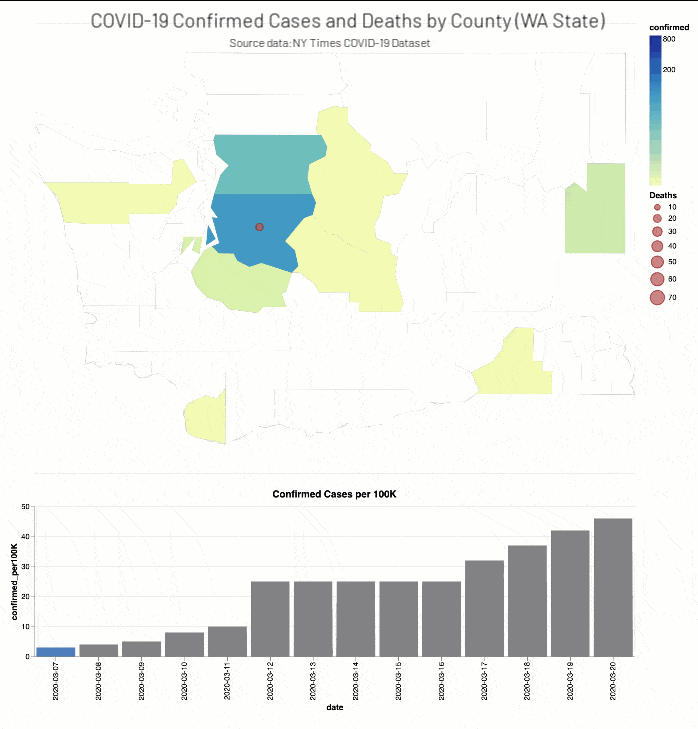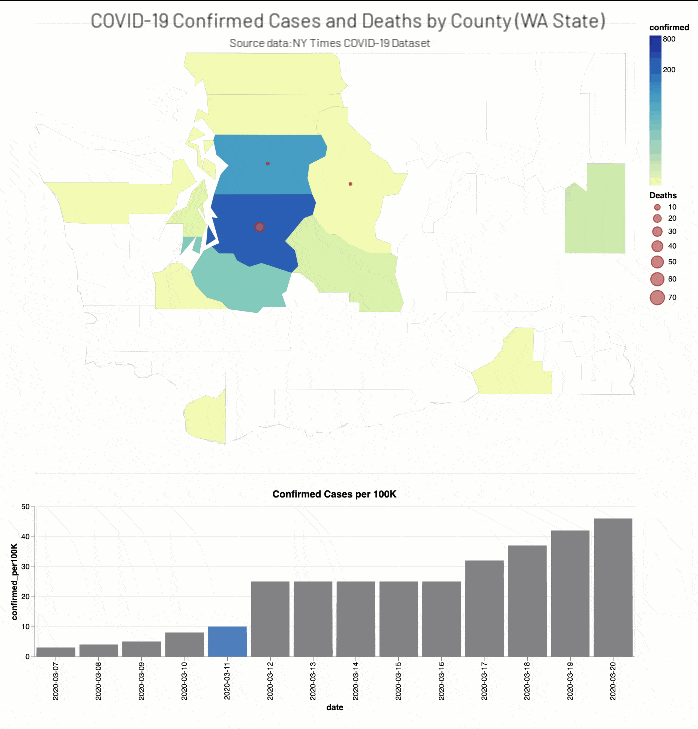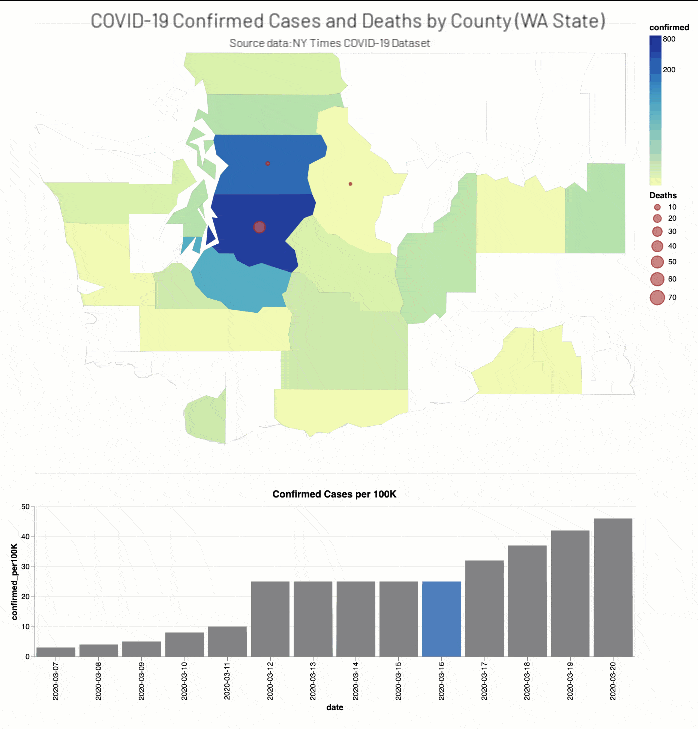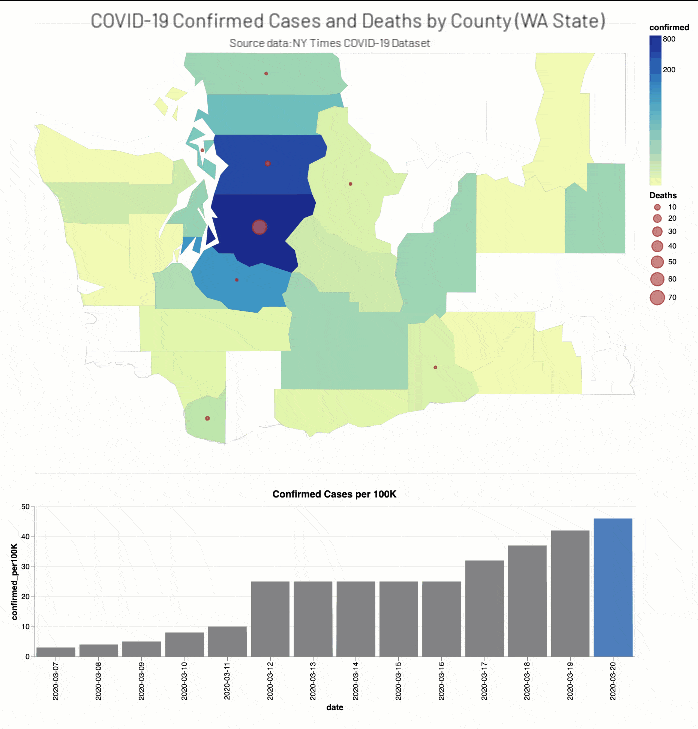
ニューヨーク・タイムズ紙のCOVID-19分析Notebookでは、COVID-19の症例と死亡者に関する分析結果を郡別に掲載しています。
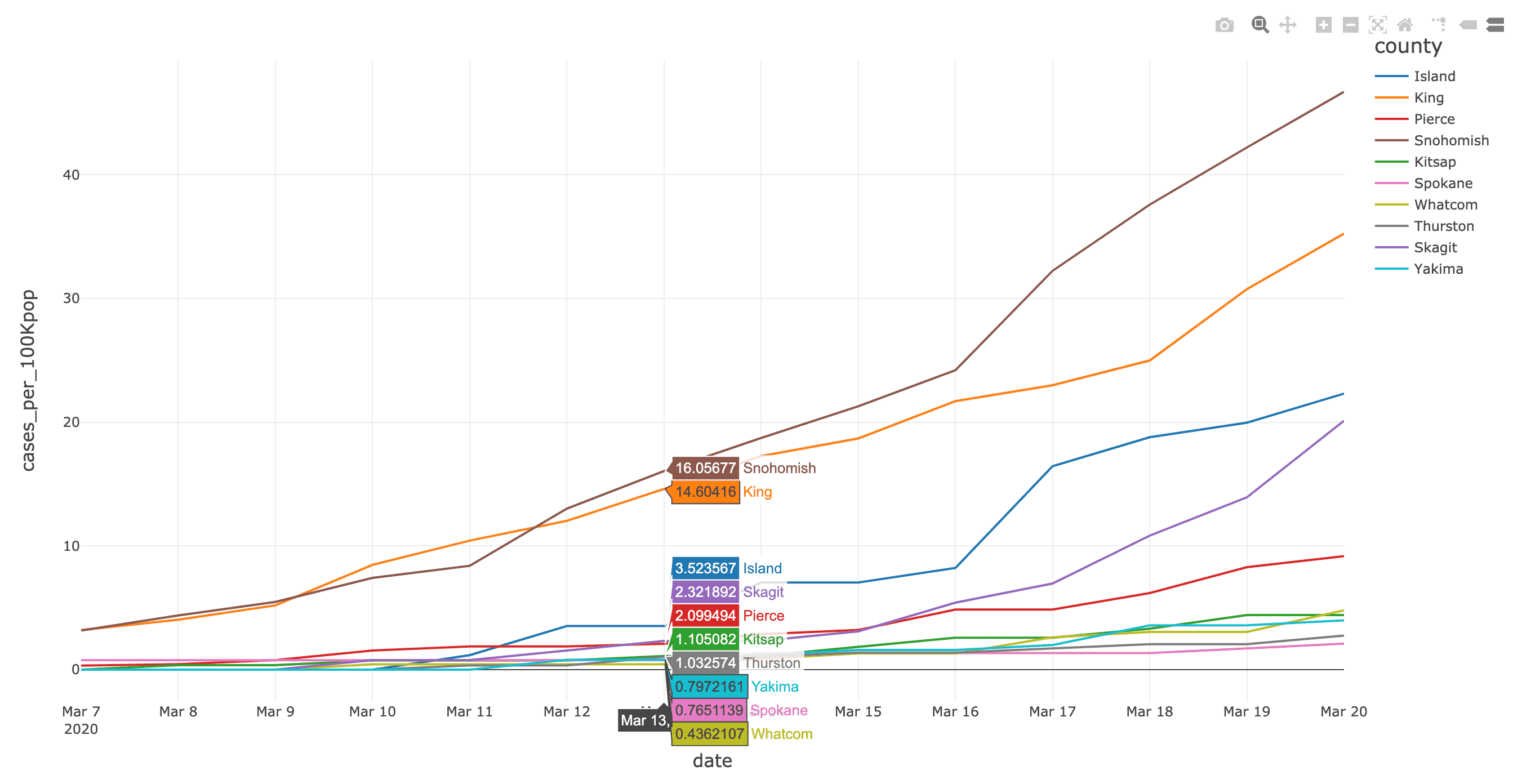
(出典:2020年4月14日現在のニューヨーク・タイムズ COVID-19 データセット)
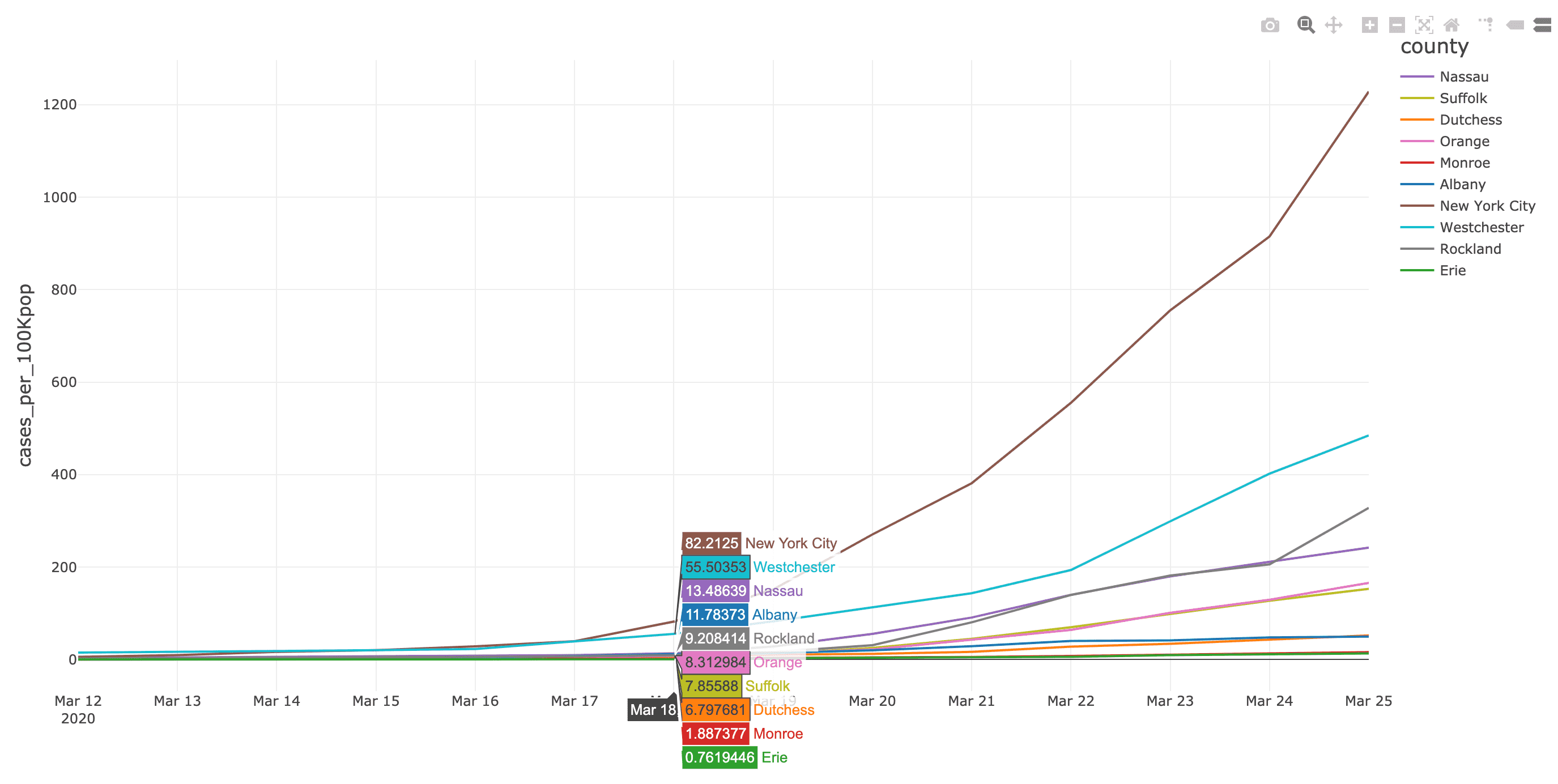
(出典:2020年4月14日現在のニューヨーク・タイムズ COVID-19 データセット)
ジョンズ・ホプキンス大学(JHU)のCOVID-19分析のNotebookに基づく観察結果をいくつか紹介します。
- 2020年4月11日現在、JHUのCOVID-19に関する日次報告のスキーマは3回変更されています。上記のNotebookには、各ファイルのループ処理、日付を取得するファイル名の抽出、および3 つの異なるスキーマをマージするスクリプトが含まれています。
- Altairの可視化機能を提供し、米国におけるCOVID-19関連の症例数と死亡者数の指数関数的な増加をスライダーバーを介して静的および動的に視覚化しています。
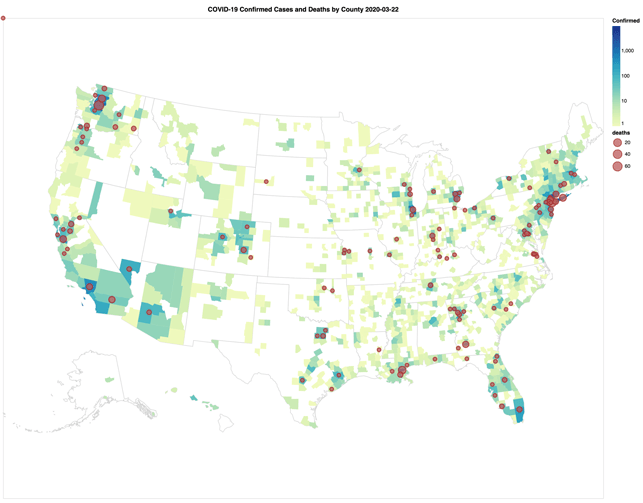
(ジョンズ・ホプキンス大学のCOVID-19データセットを使用)
また、ニューヨーク・タイムズ紙のCOVID-19分析ノートブックには、ワシントン州(2020年3月13日)とニューヨーク州(2020年3月18日)で教育施設を閉鎖した時期��の2週間前後におけるCOVID-19確定症例数と死亡者数(それぞれ総人口に対する実数比例)を、郡の階級区分図と棒グラフで掲載されています。
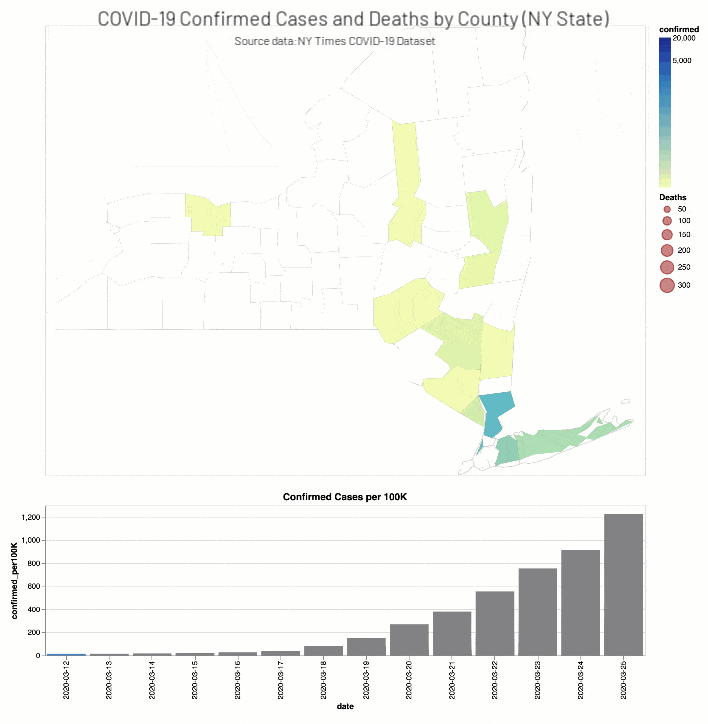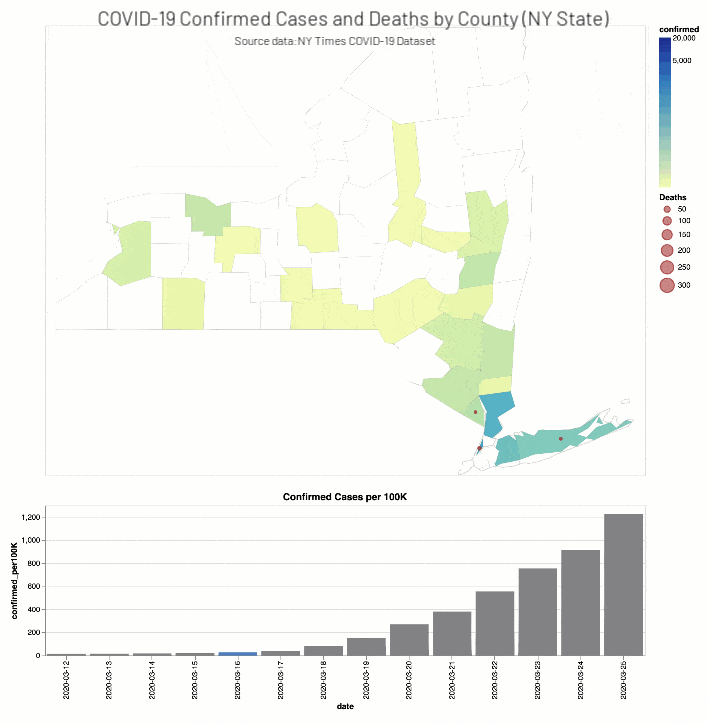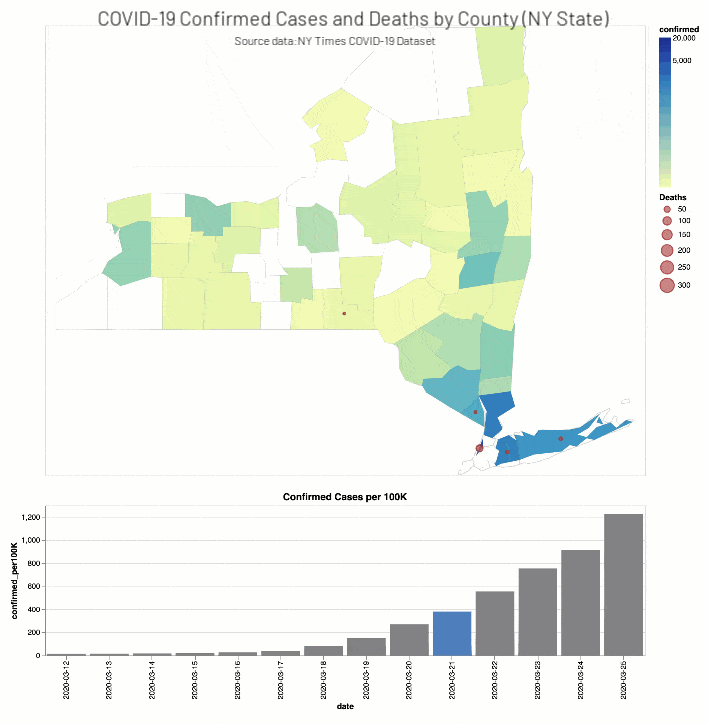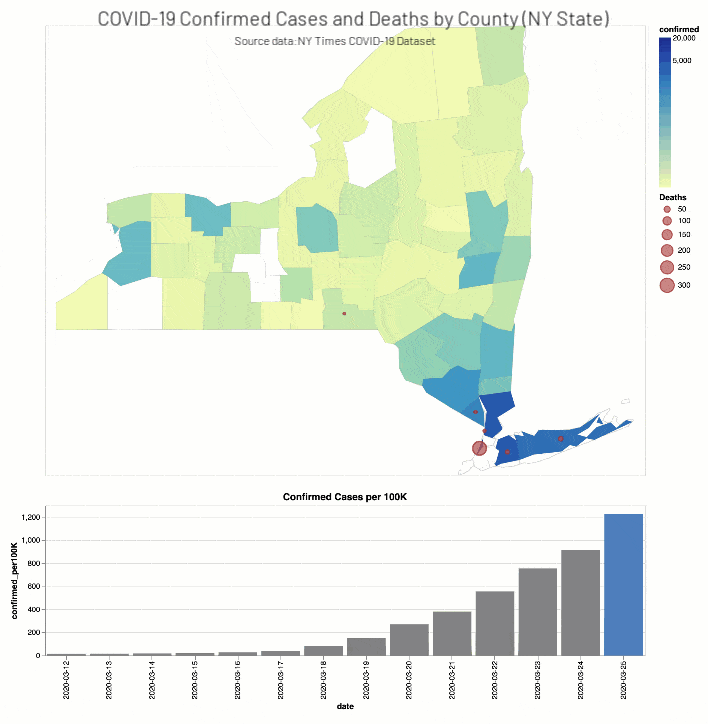
考察
このパンデミック中にデータコミュニティができる支援は、各郡における症例数と死亡者数の増加率の更新や、いち早くソーシャルディスタンスを適用した州における感染者数の推移の提供、また、曲線の平坦化を示したソーシャルディスタンスの効果など、データの背後にあるパターンの重要な洞察を提供することです。COVID-19の核心は、患者の命をいかにして救えるかという医学的な問題ですが、疫学的な問題でもあります。感染者数の増加を抑制するための公衆衛生政策にデータを活用するなど、データへの理解が医学界の的確な意思決定を支援します。

無料の第2版には、pandas UDFのPython型ヒント、新しい日付/時刻の実装など、Spark 3.0のアップデートが含まれています。