Databricksのファイルシステム
によって Takaaki Yayoi による投稿
こちらからサンプルノートブックをダウンロードできます。
Databricksでファイルを取り扱う際には、Databricks File System (DBFS) を理解する必要があります。
本記事では、DBFSの概要をご説明するとともに、具体的な使用例をご説明します。
Databricks File System (DBFS)
Databricks File System (DBFS) はDatabricksのワークスペースにマウントされる分散ファイルシステムです。Databricksクラスターから利用することができます。DBFSはクラウドのオブジェクトストレージを抽象化するものであり、以下のメリットをもたらします:
- オブジェクトストレージ(S3/Azure Blob Storageなど)追加の認証情報なしにオブジェクトストレージにアクセスすることができます。
- ストレージURLではなく、ディレクトリ、ファイルの文法に従ってファイルにアクセスできます。
- ファイルはオブジェクトストレージで永続化されるので、クラスタが削除されてもデータが残ります。
詳細はこちらを参照ください。
Databricks File System (DBFS) — Databricks Documentation
DBFS root
DBFSにおけるデフォルトの場所は「DBFS root」と呼びます。DBFS rootにはいくつかのデータが格納されています。
- /FileStore: インポートされたデータファイル、生成されたグラフプロット、アップ�ロードされたライブラリが格納されます。詳細はこちらを参照ください。
- /databricks-datasets: サンプルのデータセットが格納されます。詳細はこちらを参照ください。
- /databricks-results: クエリ結果の全データをダウンロードする際に生成されるファイルが格納されます。
- /databricks/init: クラスタノードのinit scriptが格納されます。
- /user/hive/warehouse: Databricksで管理するHiveテーブルのメタデータ及びテーブルデータが格納されます。
注意
マウントポイント/mntに書き込まれるデータはDBFS rootの外となります。DBFS rootは共有領域となりますので、アクセスコントロールが設定が必要なデータはマウントポイントなどDBFS rootの外に配置するようにしてください。
UIからDBFSにアクセス
- 画面左のDataアイコン
 をクリックします。
をクリックします。 - 画面上部の「DBFS」ボタンをクリックすることでDBFSの階層構造を参照できます。
注意 管理者の方によって「DBFS browser」が有効になっていることを確認してください。
この他にも、CLI、DBFS API (REST)、Databricksファイルシステムユーティリティ、Spark API、ローカルファイルAPIからもDBFSにアクセスできます。
DBFSとローカルドライバーノードのパス
Databricksでファイルを操作する際には、DBFSにアクセスしているのか、ローカルのクラスタードライバーノードのファイルシステムにアクセスしているのかを意識する必要があります。
ノートブックからファイルシステムにアクセスする際には、%fs、%shといったマジックコマンド、Databricksファイルシステムユーティリティdbutils.fsなどを使用します。
APIやコマンドによって、パスを指定した際、DBFSを参照するのか、ローカルファイルシステムを参照するのかのデフォルトの挙動が異なりますので注意ください。
| コマンド | デフォルト | DBFSへのアクセス | ローカルファイルシステムへのアクセス |
| %fs | DBFS root | パスの先頭にfile:/を追加 | |
| %sh | ローカルドライバーノード | パスの先頭に/dbfsを追加 | |
| dbutils.fs | DBFS root | パスの先頭にfile:/を追加 | |
| pythonのos.コマンド | ローカルドライ��バノード | パスの先頭に/dbfsを追加 |
DBFS rootを参照
以下の二つのコマンドは同じ動作をします。
| %fs ls /tmp |
| %sh ls /dbfs/tmp |
ドライバのローカルファイルシステムを参照
以下の二つのコマンドは同じ動作をします。
| %fs ls file:/tmp |
| %sh ls /tmp |
デモ
以下では、FileStoreの利用法をデモします。FileStoreはファイルを保存したファイルをブラウザから直接参照できる特別なフォルダです。以下のような使い方が可能です
- HTMLやJavaScriptを保存してブラウザから直接アクセスする。アクセスする際にはdisplayHTMLを使う。
- 出力結果を保存してローカルのデスクトップにファイルを保存する。
displayHTML()で使うJavaScriptライブラリをダウンロードし、一旦ドライバのローカルディスクに保存します。
| %scala import sys.process._ |
| %scala “sudo apt-get -y install wget” !! |
file:/tmpのファイル一覧を表示し、ローカルディスクにファイルが保存されたことを確認します。
| %scala display(dbutils.fs.ls(“file:/tmp/d3.v3.min.js”)) |
ローカルの/tmpに保存されているファイルをブラウザから直接参照できるように、
/FileStore/customjsにコピーします
| %scala dbutils.fs.mkdirs(“/FileStore/customjs”) dbutils.fs.cp(“file:/tmp/d3.v3.min.js”, “/FileStore/customjs/d3.v3.min.js”) |
/FileStore/customjsのファイル一覧を表示し、ファイルがコピーされたことを確認します
| %scala display(dbutils.fs.ls(“/FileStore/customjs”)) |
保存したJavaScriptライブラリをブラウザから参照する際には、/filesから参照することになるので、パスは/files/customjs/d3.v3.min.jsとなります
|
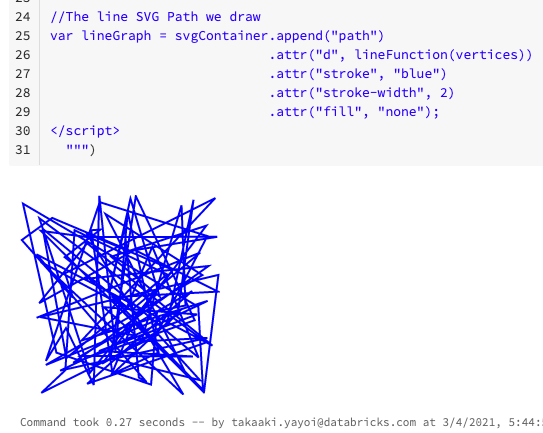
以下のようにノートブック上にd3の描画結果が表示されます。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。