データ分析の目的とプロセス
Databricks を活用した データ分析によるビジネス価値の創出
によって Takaaki Yayoi による投稿
Community Editionに代わり、Free Editionでは無料でより充実した機能をご利用いただけます。ぜひ今日からぜひFree Editionをお試しください。
こちらはデータブリックスユーザー会の第一回イベントで発表された内容となります。こちらからサンプルノートブックをダウンロードできます。
- データ分析はビジネス上の課題を解決するための手段の 1 つです。
- データ分析というと予測モデル構築が脚光を浴びがちですが、データをビジネス価値につなげる長い道のりのほんの一部です。
この記事では、データ分析を通じでビジネス価値創出につなげるために辿るプロセス�を、実例を含めてご紹介します。
データ分析の(終わり無き)長いプロセス
個人的経験を踏まえたものですが、データ分析プロジェクトは以下のフローになるかと思います。最後までたどり着けないプロジェクトもたくさんありました。
- ビジネス課題の特定
- データ分析における仮説の立案
- データ分析アプローチの検討
- データソースの調査、分析データの入手
- 分析データの読み込み
- 探索的データ分析(EDA: Exploratory Data Analysis)
- 分析データの前処理
- 分析アルゴリズムの検討
- 分析パイプラインのレビュー
- モデルの構築
- モデルの評価
- モデルのチューニング
- モデルのデプロイ
- 精度・性能のモニタリング
ステップ 1〜4:ヒアリング + ホワイトボードを前にしたディスカッション
いきなりデータ分析を始めるプロジェクトはまず存在しません。データ分析には必ずビジネスにつながる目的があるべきです。
- ステップ 1:ビジネス課題の特定
あるマーケティング担当者の悩み:「マーケティングを効率的に進めるために、年収の高いお客様を簡単に特定できないだろうか?」
ビジネス課題: 富裕層を特定することによるマーケティングの効率化 - ステップ 2:データ分析における仮説の立案
あるデータサイエンティストの思い:「デモグラフィック情報から収入を予測できれば、ユーザー情報登録時に年収を予測できるのではないか?」
データ分析における仮説: デモグラフィック情報から年収を予測できる - ステップ 3:データ分析アプローチの検討
マーケティング担当者とデータサイエンティストの議論:「具体的な年収を予測するのではなく、年収が一定額以上か未満かを識別するだけで十分ではないか」
データ分析アプローチ: 年収が 5 万ドル以上か否かを分類する二値分類問題に取り組む - ステップ 4:データソースの調査、分析データの入手
データサイエンティストと DWH 担当者の会話:「過去に蓄積したデモグラフィック情報と年収情報は利用できそうだ」
分析データ: 過去に蓄積したデモグラフィック情報、年収情報
ちなみに意外と大変なのはステップ 4 です。データの由来、スキーマ、更新頻度などの確認です。いろんな人に聞いて回らないとわからないケースもしばしばです。
ステップ 5:データの読み込み
上で述べたとおり、デモグラフィック情報に基づいて、年収が 5 万ドル以上か否かを分類する二値分類問題に取り組みます。データセットは、UCI Machine Learning Repository にあるものを利用します。このデータは既に Databricks ランタイムに格納されています。本記事では、データ処理、機械学習パイプライン、機械学習アルゴリズムなどの MLlib の機能をデモンストレーションします。
大抵の場合、分析データを入手した後にすることはデータの中身の確認でしょう。Databricks では柔軟にノートブック上での作業を行えるように、多くのマジックコマンドがサポートされています。下のセルにある %fs もその 1 つです。Databricks のファイルシステムに格納されているファイルの一部を表示します。
| %fs head –maxBytes=1024 databricks-datasets/adult/adult.data |

データセットにはカラム名が含まれていないため、カラム名とデータタイプを指定するスキーマを作成します。作成したスキーマを指定して CSV ファイルを読み込みます。
# スキーマの定義
# ファイルを読み込みます |
ステップ 6:探索的データ分析(EDA: Exploratory Data Analysis)
データを理解するための EDA は非常に重要です。EDA を通じて取り扱うデータの素性を理解することで、以降のデータ分析での手戻りを減らすことができます。
モデル構築、評価に向けて、データセットをラン�ダムにトレーニングデータとテストデータに分割します。また、再現性を確保するために乱数のシードを設定しています。
あらゆる前処理を実行する前の生の状態でデータを分割すべきです。これにより、モデルを評価する際、テストデータが未知のデータに近い状態を維持することができます。
| trainDF, testDF = dataset.randomSplit([0.8, 0.2], seed=42) print(“トレーニングデータ:”, trainDF.cache().count()) # 何回かトレーニングするのでデータをキャッシュします print(“テストデータ:”, testDF.count()) |
データを確認しましょう。EDA! EDA!
| # データを確認するには、とにかく display! display(trainDF) |

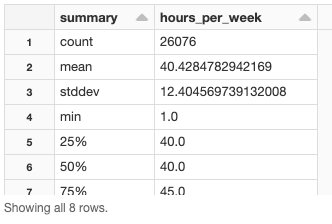
hours_per_week(週当たりの勤務時間)の分布はどうなっているでしょうか?
| display(trainDF.select(“hours_per_week”).summary()) |
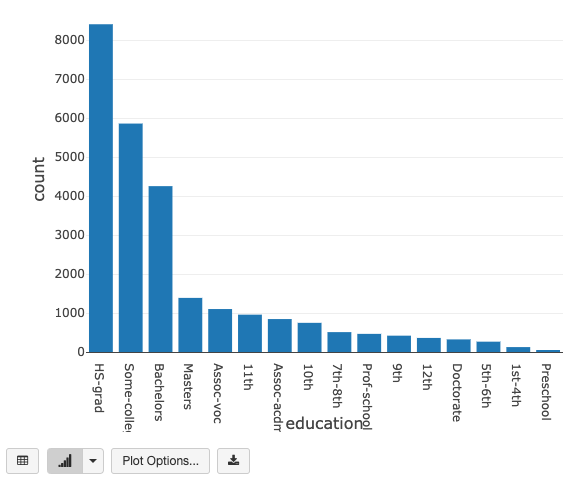
education(最終学歴)はどうなっ��ているでしょうか?
とは言っても、表形式で全体傾向を把握するのには限界があります。「百のテーブルは一のグラフにしかず」です。そんな時には Let’s 可視化!をクリック !
| # 最終学歴でグルーピングして件数をカウント、カウントの昇順でソートして表示 display(trainDF .groupBy(“education”) .count() .sort(“count”, ascending=False)) |
Matplotlib などで可視化のロジックを書くことなしにグラフを表示することができますので、EDA が捗ること間違いなしです。
インターミッション
本記事において、機械学習モデルを構築する際には Apache Spark の機械学習ライブラリ MLlib を使用します。MLlib の機械学習における重要な 3 つのコンセプトは、Transformers、Estimators、そして Pipelines です。
- Transformer:データフレームをインプットとして新たなデータフレームを返却します。Transformers はデータから学習は行わず、モデル学習のためのデータを準備するか、学習した MLlib モデルで予測を行うために、単にルールベースの変換処理を適用します。.transform() メソッドで transformer を呼び出すことができます。
- Estimator:.fit()メソッドを用いてデータフレームからパラメータを学習(fit)し、モデルを返却します。モデルは transformer です。
- Pipeline:複数のステップを容易に実行できるように単一のワークフローにまとめます。機械学習モデル作成には、多くのケースで異なるステップが含まれ、それらを繰り返す必要があります。パイプラインを用いることでこのプロセスを自動化することができます。
Pipeline の詳細に関してはこちらを参照ください。
ステップ 7:分析データの前処理
ここでのゴールは、データセットに含まれる特徴量(教育レベル、既婚・未婚、職業など)から、年収 income のレベルを予測するというものです。まず、MLlib で利用できるように特徴量を操作、前処理を行います。いわゆる特徴量エンジニアリングです。
カテゴリ変数を数値に変換する
線形回帰、ロジスティック回帰などの学習アルゴリズムでは、特徴量が数値である必要があります。上記の成人データセットでは、教育、職業、既婚・未婚のデータがカテゴリ変数となっています。
以下のコードでは、カテゴリ変数を 0 か 1 のみを取る数値変数に変換するために、どのように StringIndexer と OneHotEncoder を使用するのかを説明します。
- StringIndexer は、文字列のカラムをラベルのインデックスに変換します。例えば、”red”、”blue”、”green” をそれぞれ 0、1、2 に変換します。
- OneHotEncoder は、カテゴリ変数のインデックスを二進数のベクトルにマッピングします。当該レコードのカテゴリ変数のインデッ��クスに該当するベクトルの要素に “1” が割り当てられます。
Sparkにおける One-hot エンコーディングは 2 段階のプロセスとなります。最初にStringIndexer を使い、OneHotEncoder を呼び出します。以下のコードブロックでは、StringIndexer と OneHotEncoder を定義しますが、まだデータには適用しません。
from pyspark.ml.feature import StringIndexer, OneHotEncoder
categoricalCols = [“workclass”, “education”, “marital_status”, “occupation”, “relationship”, “race”, “sex”] # 以下の 2 行は estimator となります。後ほどデータセットを変換する際に適用することになる関数を返却します。 # ラベルとなるカラム (“income”) も (“<=50K"、">50K”) の 2 つの値をとる文字列のカラムとなります。 |
ここでは、特徴量エンジニアリングとモデル構築のステップ全てを 1 つのパイプラインにまとめます。その前に上のコードブロックで構築した stringIndexer estimator を適用することで estimator や transformer がどのように動作するのかを詳しく見てみましょう。
データセットを変換する StringIndexerModel を返却するように .fit() メソッドを呼び出します。
そして、StringIndexerModel の .transform() メソッドを呼び出すことで�、特徴量を変換し、結果を格納するカラム …Index が追加された新たなデータフレームが返却されます。必要であれば、表示結果を右にスクロールして追加されたカラムを参照してください。
| stringIndexerModel = stringIndexer.fit(trainDF) display(stringIndexerModel.transform(trainDF)) |

全ての特徴量カラムを一つの特徴量ベクトルにまとめる
多くの MLlib アルゴリズムでは、入力として単一の特徴量カラムが必要となります。それぞれの行の特徴量カラムは、予測に用いる特徴量に対応するベクトルを保持します。
MLlibは、一連のカラムから単一のベクトルカラムを作成する VectorAssembler transformer を提供します。
下のコードブロックではどのように VectorAssembler を使用するのかを説明します。
from pyspark.ml.feature import VectorAssembler
# ここには、データセットの数値カラムと one-hot エンコードされた2値のベクトル両方が含まれます。 |
ステップ8:分析アルゴリズムの検討
分析アルゴリズムは、データとビジネス課題に応じて使い分けることになると思います。EDA の過程でも「この辺りのアルゴリズムだろうな」などと当たりをつけながらデータを見ていきます。
- お客様を分類したい:クラスタリング(k-means や階層型クラスタリング)
- 値やラベルを予測したい : 回帰、決定木、ランダムフォレスト、SVM、NN など
- 画像や動画を判別したい:ディープラーニングなど
- 組み合わせを予測したい:アソシエーション分析
- テキストを分類したい:BERT など
ステップ 9:分析パイプラインのレビュー
どのタイミングでレビューを行うのかは、チームやプロジェクトによるのではないでしょうか。しかし、リモートワークが浸透した昨今、ここまで開発したロジックを簡単にシェアできる機能があると便利だと思いませんか?
安心してください。Databricks にはあります!
以下の機能を利用いただくことで、チーム間で連携しながら開発を進めることができます。
- コメント機能
- 同時編集機能
- アクセス権管理機能
- バージョン管理機能
- git 連携機能
- アーカイブ機能
- (地味ですが)セルへのリンク機能
ステップ 10:モデルの構築
ここでは予測にロジスティック回帰(英語)モデルを使います。
パイプラインの�構築
Pipeline は、transformers、estimators が含まれる順番付きのリストです。データセットに適用する変換処理の再現性を確保し、自動化するために、パイプラインを定義することができます。
StringIndexer で見たのと同様に、Pipeline も estimator です。pipeline.fit() メソッドが、transformer である PipelineModel を返却します。
from pyspark.ml import Pipeline
# これまでに作成したステージを組み合わせてパイプラインを定義します # パイプラインモデルを定義します # テストデータセットにパイプラインモデルを適用します |
モデルによる予測結果を表示します。features カラムは、one-hot エンコーディングを実行した後、多くのケースで要素のほとんどが 0 となる sparse vector(英語)となります。
| display(predDF.select(“features”, “label”, “prediction”, “probability”)) |

ステップ11:モデルの評価
モデルの評価方法にもいろいろありますが、ここでは ROC カーブで評価を行います。ここまで使用してきている display コマンドには、ROC カーブを表示するオプションが組み込まれています。
| display(pipelineModel.stages[-1], predDF.drop(“prediction”, “rawPrediction”, “probability”), “ROC”) |
![display(pipelineModel.stages[-1], predDF.drop("prediction", "rawPrediction", "probability"), "ROC")](https://www.databricks.com/wp-content/uploads/2021/06/ibjp-big-data-img-8.png)
モデル評価に必要な ROC カーブの AUC(Area Under the Curve)を計算するために BinaryClassificationEvaluator を用い、精度を評価するために MulticlassClassificationEvaluator を用います。
参考情報:
- 曲線下の面積(AUC)
ROC曲線下の面積(Area under the curve: AUC)は分類器(分類のアルゴリズム)の性能の良さを表します。0 から 1 までの値をとり,完全な分類が可能なときの面積は 1 で,ランダムな分類の場合は 0.5 になります。
from pyspark.ml.evaluation import BinaryClassificationEvaluator, MulticlassClassificationEvaluator
bcEvaluator = BinaryClassificationEvaluator(metricName=”areaUnderROC”) mcEvaluator = MulticlassClassificationEvaluator(metricName=”accuracy”) |
AUC が 0.88 となっており、それなりの精度であることがわかります。

ステップ 12:モデルのチューニング
一度のトレーニングで得られたモデルをベストモデルと考えるのは早計です。通常はハイパラメータをチューニングしながらモデルの改善を行っていくことになります。MLlib はハイパーパラメータチューニングと交差検証(cross validation)の手段を提供します。
- ハイパーパラメータチューニングにおいては、ParamGridBuilder を用いることで、モデルのハイパーパラメータの探索空間を定義できます。
- 交差検証においては、CrossValidator を用いることで、estimator(入力データセットに適用するパイプライン)、evaluator、ハイパーパラメータの探索空間、交差検証のフォールド数を定義できます。
モデルをチューニングするために、ParamGridBuilder と CrossValidator を使用します。本例においては、CrossValidator での検証において、3 種類の regParam、3 種類の elasticNetParam から生成される、3 x 3 = 9 のハイパーパラメータの組み合わせを使用します。
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
paramGrid = (ParamGridBuilder() |
MLlibの CrossValidator を呼び出した際、Databricks は MLflow を用いて、自動的に全てのラン(モデルのトレーニング)を追跡します。MLflow の UI(AWS | Azure)を用いて、構築したモデルを比較することができます。下のセルの実行後、画面右上にある Experiment ボタンを押してみてください。MLflow に関してはこちらの記事を参照ください。
本例では、作成したパイプラインを estimator とします。
# 3フォールドのCrossValidatorを作成
import mlflow with mlflow.start_run(): # ベストモデルをテストデータで評価しロギングします。 # ベストモデルをロギングします。 |
ステップ 13:モデルのデプロイ
ベストモデルをデプロイ(配備)して、予測を実行します。デプロイには、いくつかの方法があります。
- 特定の場所にモデルをデプロイし、バッチやストリーミングでデータを�流し込んで予測を行う
- モデルサーバーにデプロイし、REST API などで予測を行う(モデルサービング)
MLflow を活用することで、モデルサービングおよびモデルの本格デプロイに向けた承認フローなどを容易に構築することができます。
ここでは、テストデータセットに対する予測を行うために、交差検証によって特定されたベストモデルを用います。
| # テストデータセットに対する予測を行うために、交差検証によって特定されたベストモデルを使用 cvPredDF = cvModel.transform(testDF) |
予測結果に対するデータ分析
予測結果のデータセットを見てみます。prediction カラムの値が 0 の場合、<=50K、1 の場合 >50K と予測したことを意味します。
| display(cvPredDF) |

また、SQL を用いて予測結果を年齢別、職業別に集計することができます。SQL を実行するためには、予測結果のデータセットから一時ビューを作成します。
| cvPredDF.createOrReplaceTempView(“finalPredictions”) |
職業ごとの予測結果を見てみます。以下のグラフの prediction は以下のとおり解釈します。
- 0 : 年収が <=50K
- 1 : 年収が >50K
| %sql SELECT occupation, prediction, count(*) AS count FROM finalPredictions GROUP BY occupation, prediction ORDER BY occupation |
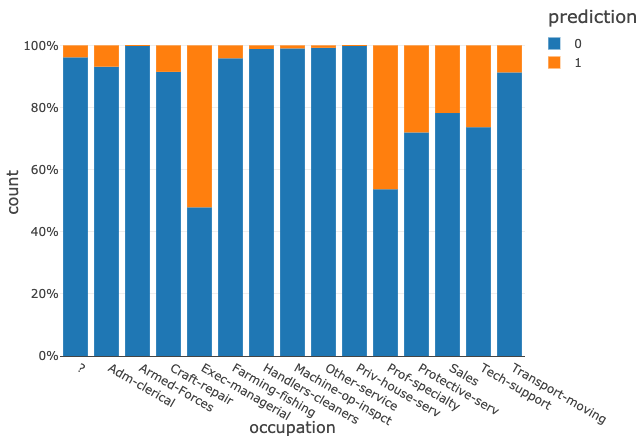
経営者、専門職などでは、高い割合で高収入と予測する傾向が見て取れます。
次に、予測結果を年齢ごとに見てみます。
| %sql SELECT age, prediction, count(*) AS count FROM finalPredictions GROUP BY age, prediction ORDER BY age |
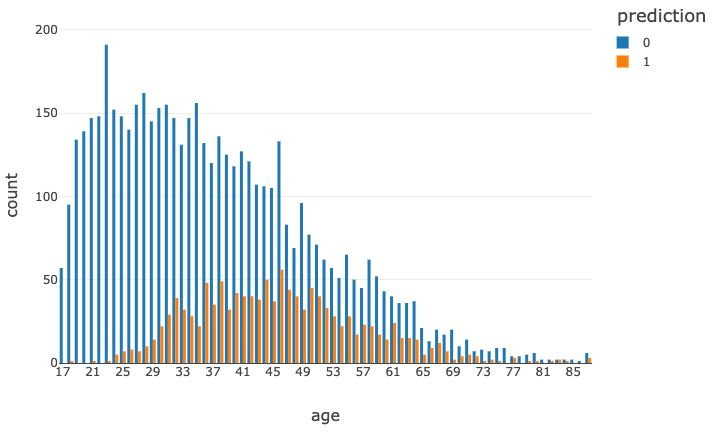
ステップ 14:精度・性能のモニタリング
実運用においては、モデルが定常的に目標とする精度を達成しているのかをモニタリングする必要があります。モデルの経年劣化「ドリフト」を検知した場合には、再学習を行うなどの対応が必要となります。
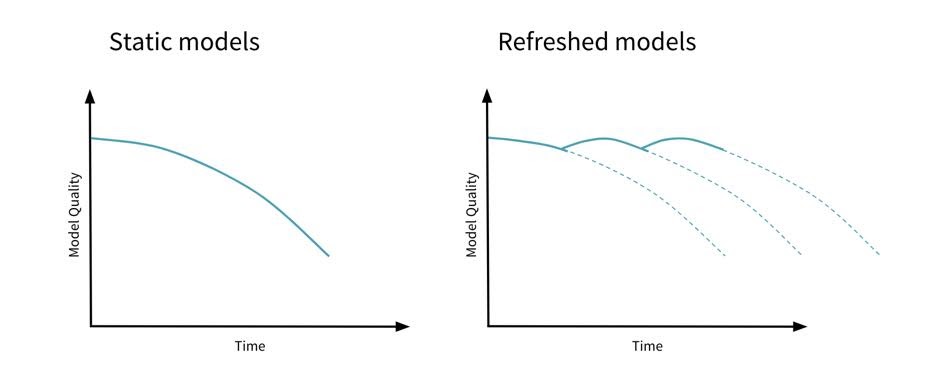
なお、ドリフトには以下の種類があります。
概念ドリフト(concept drift)
目標変数の統計的属性が変化した時、予測しようとする本当の概念もまた変化します。例えば、不正トランザクションにおいては、新たな手口が生まれてくると、不正の定義自体を見直さなくてはなりません。このような変化は概念ドリフトを引き起こします。
データドリフト(data drift)
入力データから選択された特徴量を用いてモデルをトレーニングします。入力データの統計的特性に変化が生じた際に、モデルの品質に影響を及ぼします。例えば、季節性によるデータの変化、個人的嗜好の変化、トレンドなどは入力データのドリフトを引き起こします。
上流データの変化(upstream data changes)
モデル品質に影響を与えうるデータパイプライン上流でのオペレーションの変更が生じる場合があります。例えば、特徴量のエンコーディングにおいて華氏から摂氏に変更があった場合や、特徴量の生成が停止されることで null や欠損値になるなどです。
ここでは、ベストモデルを AUC で評価しますが、実際には評価は一度限りではなく、継続的なオペレーションになります。これがデータ分析が「終わり無き」プロセスたる所以です。
モデルドリフトに関してはこちらの記事を参照ください。
| # AUCと精度を用いてモデルの性能を評価 print(f”Area under ROC curve: {bcEvaluator.evaluate(cvPredDF)}”) print(f”Accuracy: {mcEvaluator.evaluate(cvPredDF)}”) |

今回は、データ分析の終わり無きプロセスの一部フローをお見せしました。
ほぼ全ての作業を Databricks のワークスペースで完結することができることをご覧いただけたかと思います。
是非、Databricks をご利用ください!
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。