ML パイプラインとは何ですか?
ML パイプラインがデータの前処理からモデルの検証まで機械学習ワークフローを自動化および合理化する方法を学びます
によって Databricks Staff による投稿
- MLパイプラインとは何か、そして前処理、特徴抽出、モデルフィッティング、検証を統合されたワークフローにどう統合するのかを理解します。
- パイプラインの2つの主要なステージタイプであるTransformerとEstimatorの違いを学びます。
- Spark MLパイプラインがネイティブパイプラインの作成とチューニングによって、スケーラブルな分散機械学習を実現する仕組みを探ります。
通常、機械学習アルゴリズムを実行する際には、前処理、特徴抽出、モデル適合、検証など一連のステージのタスクが含まれます。例えば、テキスト文書を分類する場合、テキストのセグメンテーションやクリーニング、特徴量の抽出、交差検証での分類モデルのトレーニングなどがあります。各ステージに利用できるライブラリは多数ありますが、特に大規模なデータセットを使用する場合、それぞれのライブラリを全体につなげる作業は容易ではありません。また、ほとんどの機械学習ライブラリは、分散計算用に設計されていないか、パイプラインの作成やチューニングをネイティブにサポートしていません。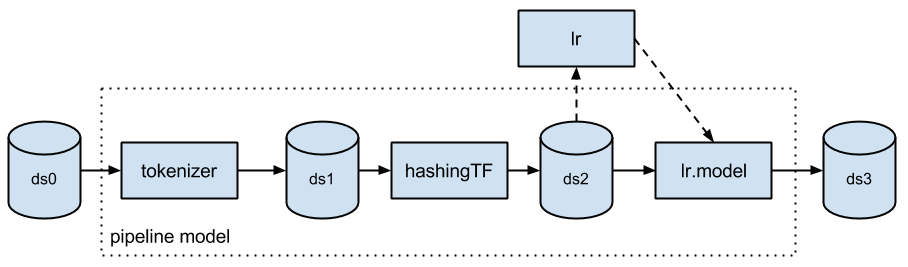 機械学習パイプラインとは、"spark.ml" パッケージ下にあるMLlibのための高レベルAPIです。パイプラインには、一連のステージがあり、基本的なパイプラインのステージタイプは、トランスフォーマーとエスティメーターの2��つです。トランスフォーマーは、データセットを入力として受け取り、出力として拡張データセットを生成します。例えば、トークナイザは、テキストのデータセットをトークン化した単語のデータセットに変換するトランスフォーマーです。エスティメーターは、入力データセットを変換するトランスフォーマーであるモデルを生成するには、最初に入力データセットに適合させる必要があります。例えば、ロジスティック回帰は、ラベルと特徴量でデータセットをトレーニングし、ロジスティック回帰モデルを生成するエスティメーターです。
機械学習パイプラインとは、"spark.ml" パッケージ下にあるMLlibのための高レベルAPIです。パイプラインには、一連のステージがあり、基本的なパイプラインのステージタイプは、トランスフォーマーとエスティメーターの2��つです。トランスフォーマーは、データセットを入力として受け取り、出力として拡張データセットを生成します。例えば、トークナイザは、テキストのデータセットをトークン化した単語のデータセットに変換するトランスフォーマーです。エスティメーターは、入力データセットを変換するトランスフォーマーであるモデルを生成するには、最初に入力データセットに適合させる必要があります。例えば、ロジスティック回帰は、ラベルと特徴量でデータセットをトレーニングし、ロジスティック回帰モデルを生成するエスティメーターです。
FAQ
機械学習パイプラインとは何ですか?
複数の前処理や学習工程を統合し、一貫したMLワークフローを構築する仕組みです。
Sparkのパイプラインの特徴は?
spark.mlパッケージで提供され、トランスフォーマーとエスティメーターを組み合わせて効率的に処理できます。
なぜ大規模データに有効ですか?
分散処理を前提とするため、複雑な工程を自動化しつつ拡張性のあるMLモデル構築を実現できるからです。
エンタープライズ向けエージェントAIプレイブック

最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。