

マネージド MLflow とは
Managed MLflow は、Databricks が開発した、より優れたモデルと生成 AI アプリを構築するためのオープンソースプラットフォームである MLflow の機能を拡張したもので、企業の信頼性、セキュリティ、スケーラビリティに重点を置いています。 MLflow の最新アップデートでは、大規模言語モデル(LLM)の管理およびデプロイ機能を強化する革新的な LLMOps 機能が導入されました。この拡張された LLM サポートは、業界標準の LLM ツールである OpenAI と Hugging Face Transformers、および MLflow デプロイメントサーバーとの新しい統合によって実現されます。 さらに、MLflow は LLM フレームワーク(LangChain など)と統合することで、チャットボット、文書要約、テキスト分類、センチメント分析など、さまざまなユースケースに対応する生成 AI アプリケーションを作成するためのモデル開発を簡素化することができます。
メリット
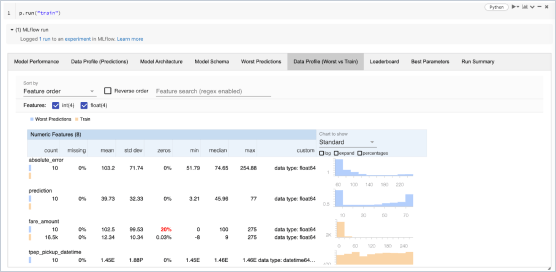
モデル開発
本番稼働可能なモデルのための標準化されたフレームワークにより、機械学習のライフサイクル管理を強化し、迅速化します。マネージド型の MLflow のレシピは、シームレスな ML プロジェクトのブートストラッ�プ、迅速なイテレーション、大規模なモデル展開を可能にします。チャットボット、文書要約、センチメント分析、分類などのアプリケーションを容易に作成できます。LangChain、Hugging Face、OpenAI とシームレスに統合された MLflow の LLM を使用して、生成 AI アプリケーション(チャットボット、文書要約など)を簡単に開発できます。
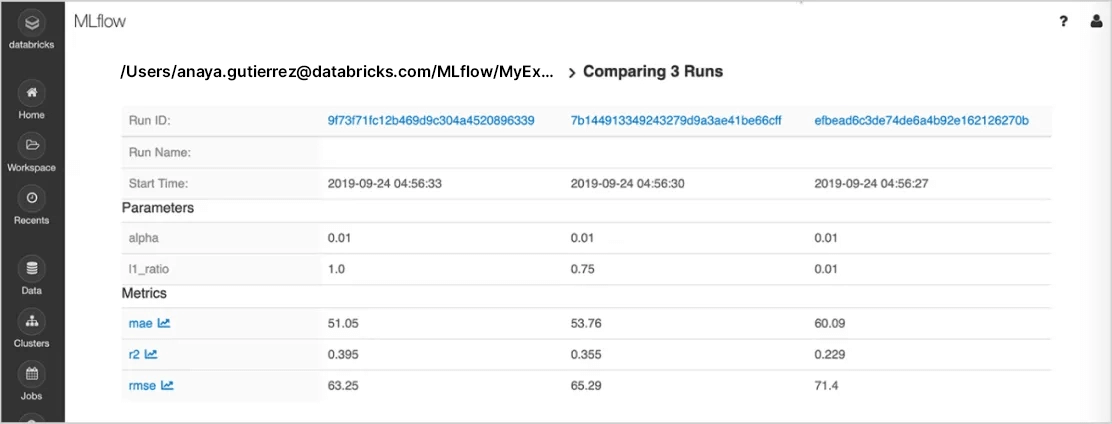
実験の追跡
機械学習ライブラリ、フレームワーク、言語を使って実験することができ、各実験のパラメータ、メトリック、コード、およびモデルを自動的に追跡します。Databricks ワークスペースとノートブックの組み込みの統合機能により、Databricks 上で MLflow を使用することで、対応する成果物やコードバージョンも含めた実験結果の安全な共有、管理、比較ができます。また、MLflow の評価機能により、生成 AI 実験の結果を評価し、品質を向上させることができます。
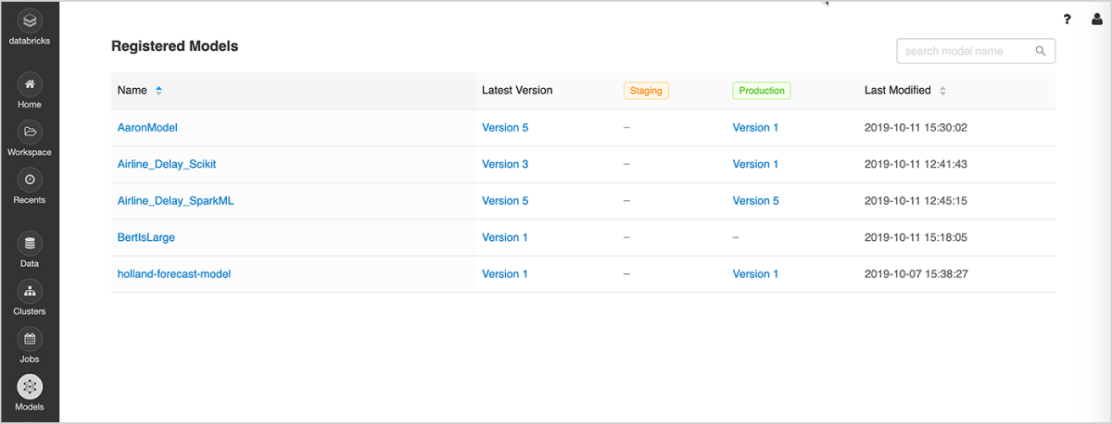
モデル管理
一元的な場所を使用して、機械学習モデルの検出と共有、実験からオンラインでのテストと実稼働への移行に関する共同作業、承認とガバナンスのワークフローと CI/CD パイプラインとの統合、機械学習のデプロイとそのパフォーマンスを監視します。MLflowモデルレジストリを使用することで、専門知識と知識の共有を容易にし、管理を維持できます。
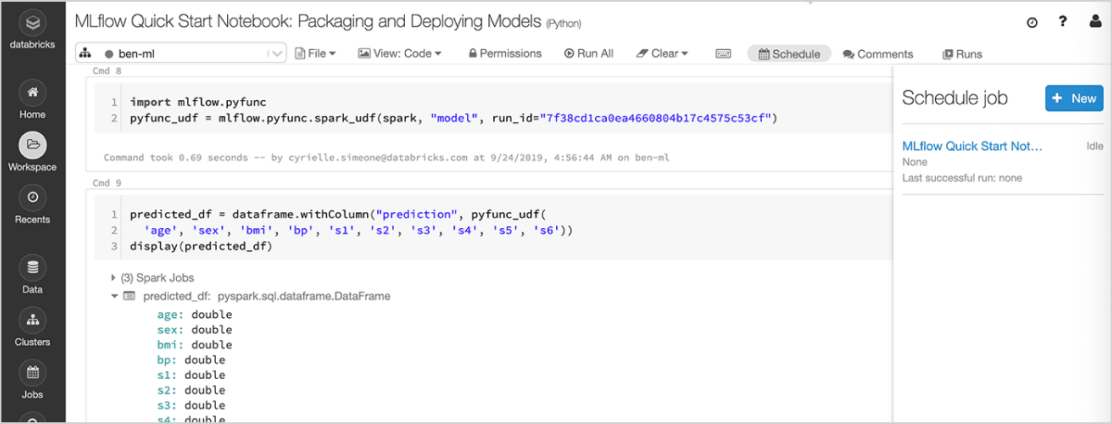
モデルのデプロイ
本番モデルは、Apache Spark™ でバッチ推論を実行するために、または Docker コンテナ、Azure ML、Amazon SageMaker に統合されている組み込み機能を使用する REST API として、迅速にデプロイできます。Databricks 上のマネージド型の MLflow では、Databricks Jobs Scheduler や自動管理クラスターを利用して本番モデルを運用および監視し、ビジネスニーズに応じてスケーリングすることができます。
MLflow の最新のアップグレードは、生成 AI アプリケーションをデプロイするためにシームレスにパッケージ化します。 Databricks のモデルサービング を使用することで、チャットボットやドキュメントの要約、感情分析、分類などの生成 AI アプリケーションを大規模に展開できるようになりました。
Features
Tracing
Capture inputs, outputs, and step-by-step execution—including prompts, retrievals, and tool calls—with MLflow’s open-source, OpenTelemetry-compatible tracing. Automatically instrument popular GenAI libraries or ingest traces directly. Debug and iterate faster with interactive timeline views, side-by-side comparisons, and zero vendor lock-in.
Generative AI Evaluation
Evaluate GenAI agents using LLM-as-a-judge and human feedback—right in the MLflow UI. Build datasets from production traces, compare outputs across versions, and assess quality with prebuilt or custom metrics like hallucination or relevance. Incorporate expert feedback via web UIs or app APIs to align with human judgment and continuously improve results.
Prompt Registry and Agent Versioning
Version prompts, agents, and application code in one place with MLflow. Link traces, evaluations, and performance data to specific versions for full lifecycle lineage. Reuse and compare prompts across workflows, manage agent versions with associated metrics and parameters, and integrate with Git and CI/CD to accelerate governed iteration.
Generative AI Monitoring and Alerting
Monitor GenAI quality in real time with MLflow’s dashboards, trace explorers, and automated alerts. Track issues like PII leakage, latency spikes, or unhelpful responses using LLM-judge evaluations and custom metrics. Configure online evaluations and act quickly—before users are affected.
Features
Experiment Tracking
Automatically track parameters, metrics, artifacts, and models from any ML or deep learning framework. MLflow gives you a complete audit trail and supports deep comparisons across architectures, checkpoints, and training workflows—at scale.
Model evaluation for ML and DL
Automatically log built-in and custom metrics for tasks like classification or regression. Compare results against baselines, log artifacts like ROC curves, and validate models on new datasets—before they reach production.
Effortless Model Management & Governance
Discover, share, and manage models centrally with the MLflow Model Registry—integrated with Unity Catalog for end-to-end governance. Track deployment status and collaborate across teams with full visibility into model performance across environments
Deployment at Scale
Deploy models with a reproducible packaging format that includes all code, dependencies, and weights. Serve them as REST APIs or run high-throughput batch inference with ai_query—optimized for both CPU and GPU via Databricks Model Serving.
最新の機能の詳細については、Azure Databricks と AWS の製品ニュースをご覧ください。
MLflow の機能比較
Open Source MLflow | Managed MLflow on Databricks | |
|---|---|---|
実験の追跡 | ||
MLflow 追跡 API | ||
MLflow 追跡サーバー | 自己ホスト型 | フルマネージド型 |
ノートブックの統合 | ||
ワークフロー連携 | ||
再現可能なプロジェクト | ||
MLflow プロジェクト | ||
モデル管理 | ||
Git と Conda の統合 | ||
プロジェクト実行のためのスケーラブルなクラウド/クラスター | ||
MLflow Model Registry | ||
モデルのバージョン管理 | ||
柔軟なデプロイ | ||
ACL ベースのステージ遷移 | ||
CI/CD ワークフローの統合 | ||
セキュリティと管理 | ||
組み込みのバッチ推論 | ||
MLflow モデル | ||
組み込みのストリーミング分析 | ||
高可用性 | ||
自動更新 | ||
ロールベースのアクセス制御 | ||
セキュリティと管理 | ||
ロールベースのアクセス制御 | ||
ロールベースのアクセス制御 | ||
ロールベースのアクセス制御 | ||
ロールベースのアクセス制御 | ||
セキュリティと管理 | ||
ロールベースのアクセス制御 | ||
ロールベースのアクセス制御 | ||
ロールベースのアクセス制御 | ||
ロールベースのアクセス制御 | ||
セキュリティと管理 | ||
ロールベースのアクセス制御 | ||
ロールベースのアクセス制御 | ||
ロールベースのアクセス制御 |
リソース
ブログ
動画
チュートリアル
Web セミナー
Web セミナー
Web セミナー
Frequently Asked Questions
Ready to get started?