

序章
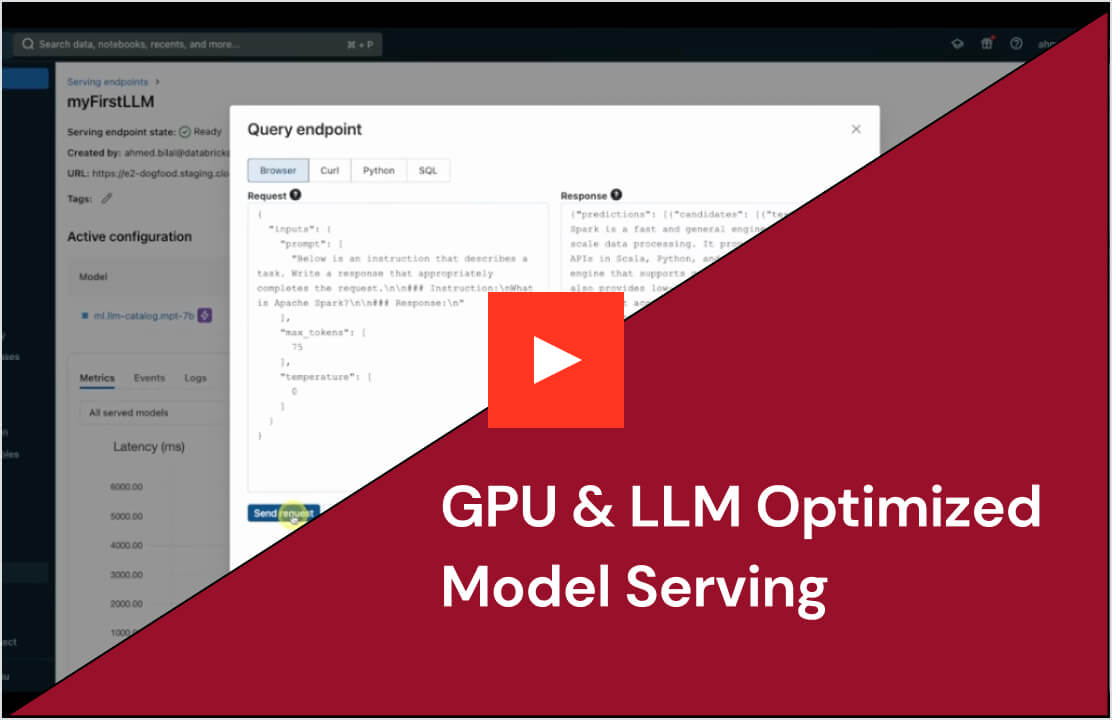
Databricks Model Servingは、従来の 機械学習 モデル、生成AI モデル、AI エージェントをデプロイするための堅牢なソリューションを企業に提供します。Azure OpenAI、AWS Bedrock、Anthropicなどのプロプライエタリモデルに加え、LlamaやMistralなどのオープンソースモデルもサポートしています。 顧客は、ファインチューニング済みのオープンソースモデルや、独自のデータでトレーニングされた古典的なMLモデルをサーブすることもできます。顧客は、サービングされたモデルをエンドポイントとして、大規模なバッチ推論やリアルタイムアプリケーションなどのワークフローで簡単に使用できます。Model Servingには、高品質な出力を保証するためのガバナンス、リネージ、モニタリング機能も組み込まれています。
お客さまの声
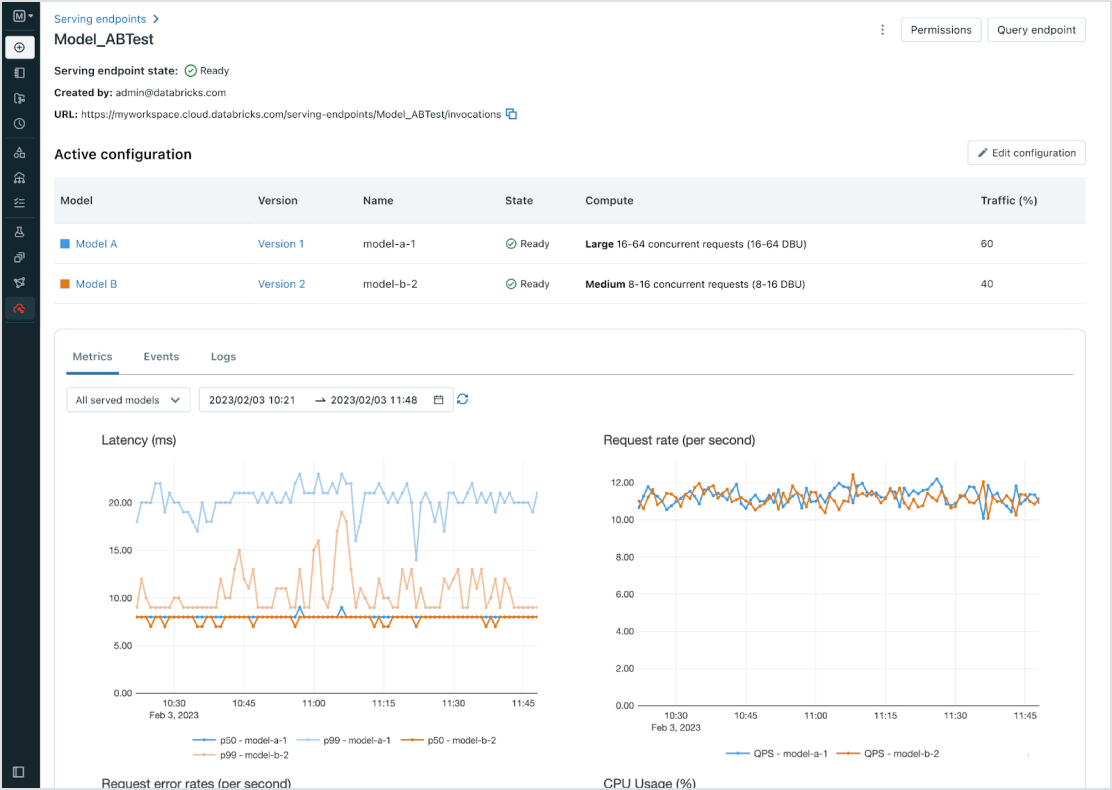
すべてのAIモデルとエージェントのデプロイを簡素化
事前トレーニング済みのオープンソースモデルから、独自のデータで構築したカスタムモデルまで、あらゆるモデルタイプを CPU と GPU の両方でデプロイできます。自動化されたコンテナビルドとインフラ�ストラクチャ管理により、メンテナンスコストが削減され、デプロイが高速化されるため、お客様はAIエージェントシステムの構築と、ビジネスへのより迅速な価値提供に集中できます。
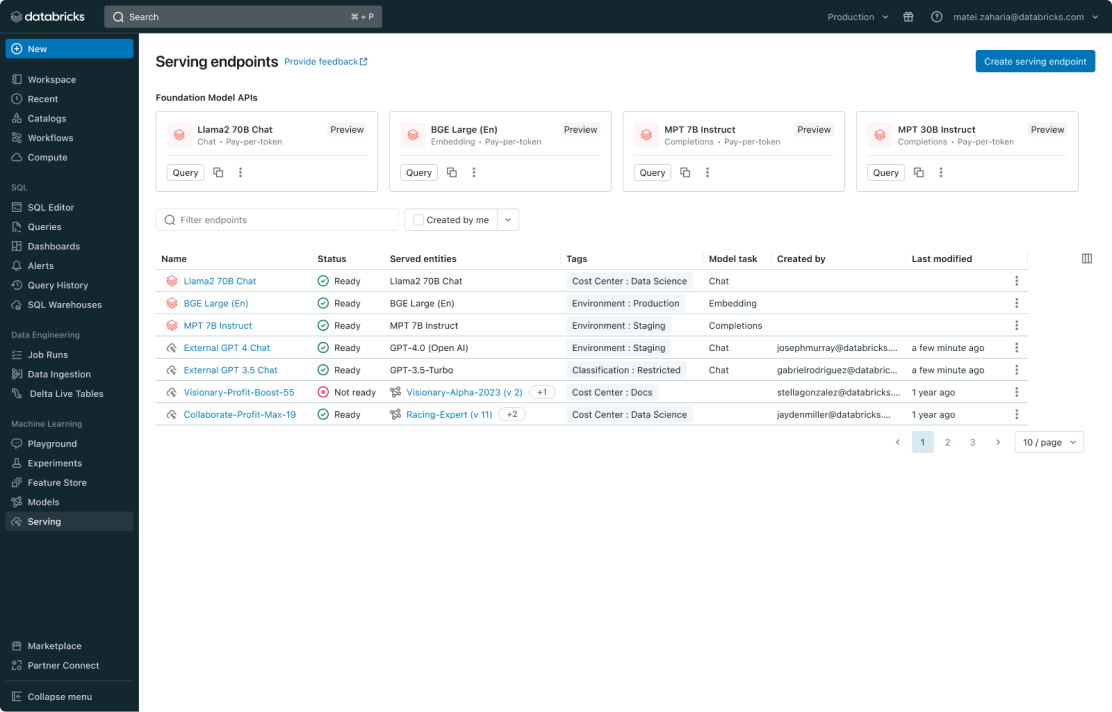
全モデルの一元管理
PyFunc、scikit-learn、LangChain のようなカスタム ML モデル、Llama 2、MPT、BGE のようなDatabricks 上の基盤モデル(FM)、ChatGPT、Claude 2、Cohere、Stable Diffusion のような他の場所でホストされている基盤モデルを含む全てのモデルを管理します。モデルサービングは、Databricks がホストしているモデルや、Azure や AWS 上の他のモデルプロバイダからのモデルを含め、統一されたユーザーインターフェースと API で全てのモデルにアクセスできるようにします。
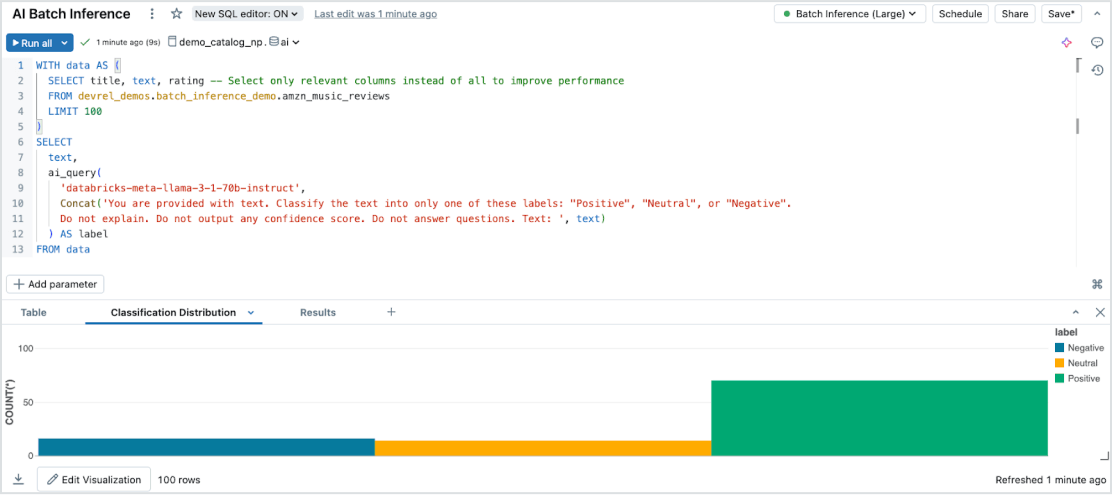
手間いらずのバッチ推論
Model Serving は、あらゆるデータタイプとモデルにわたり、大規模データセット上で効率的かつserverlessな AI 推論を可能にします。Databricks SQL、ノートブック、ワークフローとシームレスに統合し、AIを大規模に適用できます。AI Functions を使用すると、インフラストラクチャ管理なしで、大規模なバッチ推論を即座に実行し、スピード、スケーラビリティ、ガバナンスを確保できます。
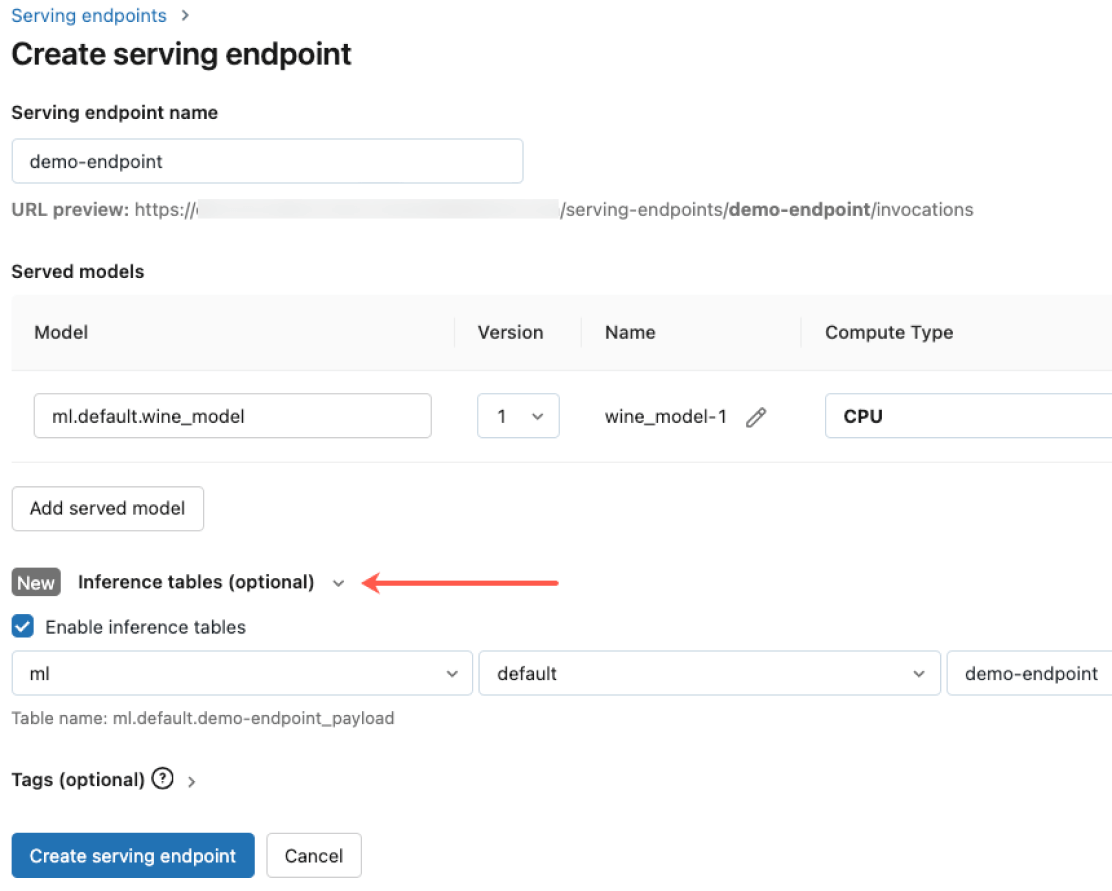
組み込まれたガバナンス
Databricks ゲートウェイと統合し、厳格なセキュリティ要件と高度なガバナンス要件を満たします。モデルがDatabricksでホストされているか、他のモデルプロバイダーでホストされているかにかかわらず、すべてのモデルに対して適切な権限を適用し、モデルの品質を監視し、レート制限を設定し、リネージを追跡することができます。
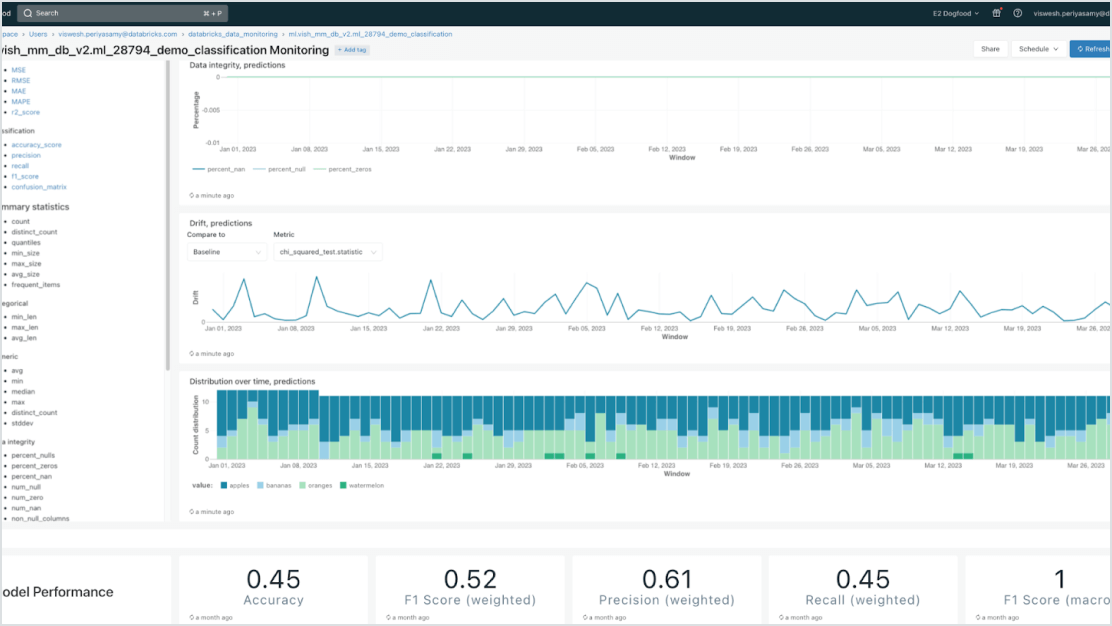
データ中心のモデル
データインテリジェンスプラットフォームとの強力な統合により、デプロイメントを加速し、エラーを削減します。企業データで拡張(RAG)またはファインチューニングされたさまざまな生成 AI モデルを簡単にホストできます。モデルサービングは、AI のライフサイクル全体にわたって、自動化されたルックアップ、モニタリング、ガバナンスを提供します。
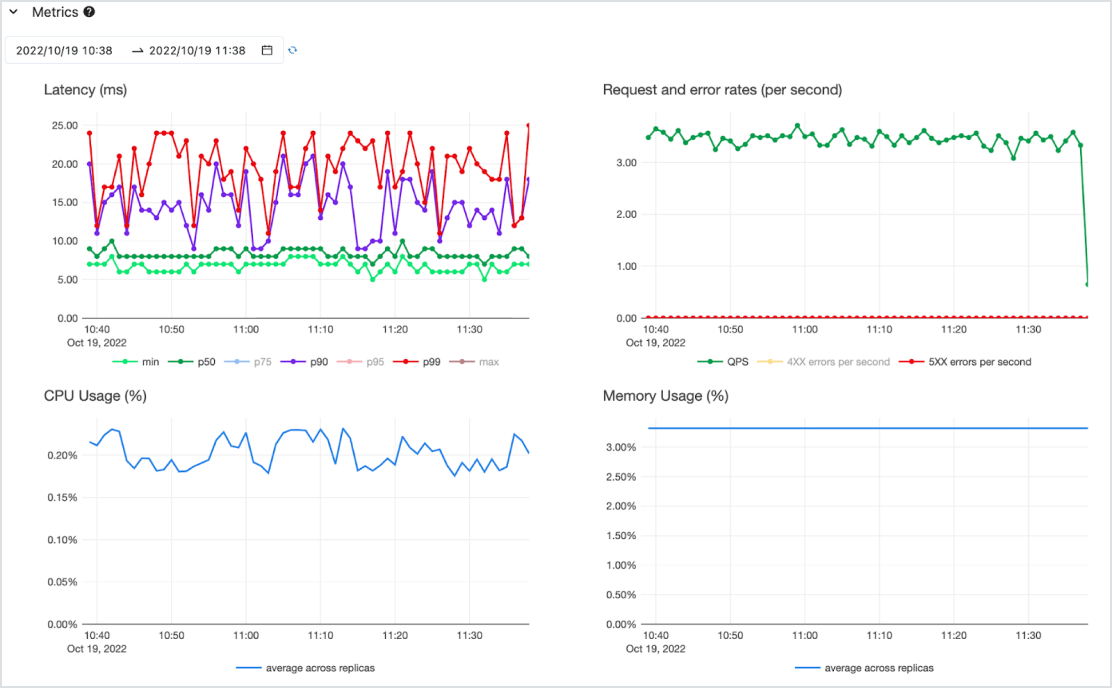
費用対効果
CPU と GPU の両方をサポートした可用性の高いサーバーレスサービス上で、低遅延の API としてモデルを提供します。最も重要なニーズを満たすためにゼロから簡単に拡張でき、要件が変化した場合は縮小できます。1 つまたは複数のデプロイ済みモデルと、スループット保証のためのトークンごとの支払い(コミットメントなしのオンデマンド)、またはプロビジョニングされたコンピュートワークロードの支払いによって迅速に開始できます。Databricks がインフラの管理とメンテナンスのコストを引き受けます。これにより、お客さまはビジネス価値の提供に専念することが可能です。