ファウンデーションモデル機能でGenAIアプリをより速く構築する方法
Databricks Model ServingによるあらゆるFoundationモデルへのアクセス、管理、監視
によって アーメッド・ビラル, アスファンディヤール・クレシ, マーガレット・チェン, 謝建偉, Sue Ann Hong(スー・アン・ホン), Vladimir Kolovski, ミンギュ・リー 、 Ankit Mathur による投稿
先週発表したRAG(Retrieval Augmented Generation)に続き、Model Servingのメジャーアップデートを発表できることを嬉しく思います。Databricks Model Servingは統一されたインターフェイスを提供するようになり、すべてのクラウドとプロバイダで基盤モデルの実験、カスタマイズ、プロダクション化が容易になりました。これは、組織固有のデータを安全に活用しながら、ユースケースに最適なモデルを使用して高品質のGenAIアプリを作成できることを意味します。
新しい統一インターフェースにより、Databricks上であろうと外部でホストされていようと、すべてのモデルを一箇所で管理し、単一のAPIでクエリすることができます。さらに、Llama2 や MPT モデルなどの一般的な大規模言語モデル (LLM) に Databricks 内から直接アクセスできる Foundation Model API をリリースします。これらのAPIには、トークンごとの支払いやスループットのプロビジョニングなど��、オンデマンドの価格オプションが用意されており、コストの削減と柔軟性の向上を実現しています。
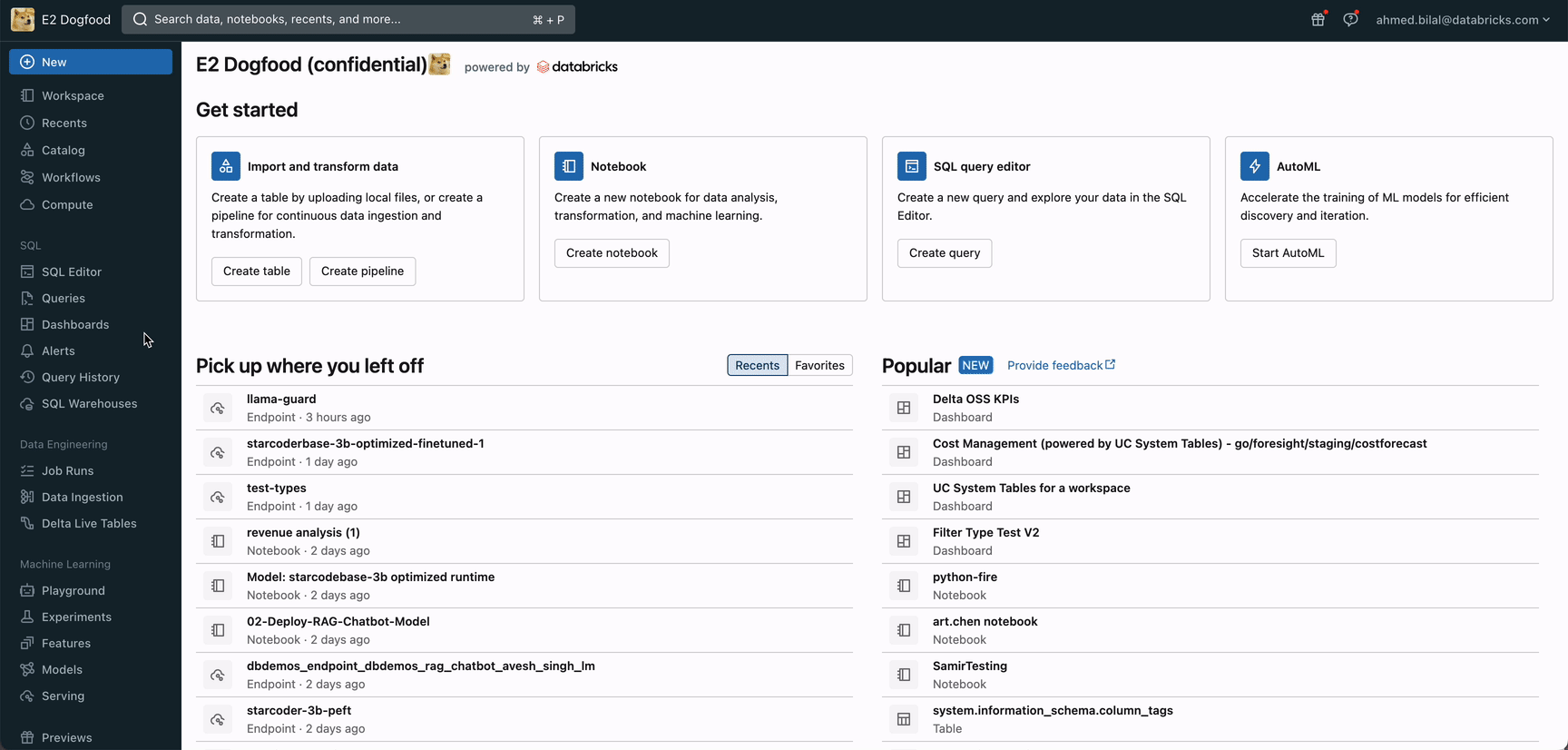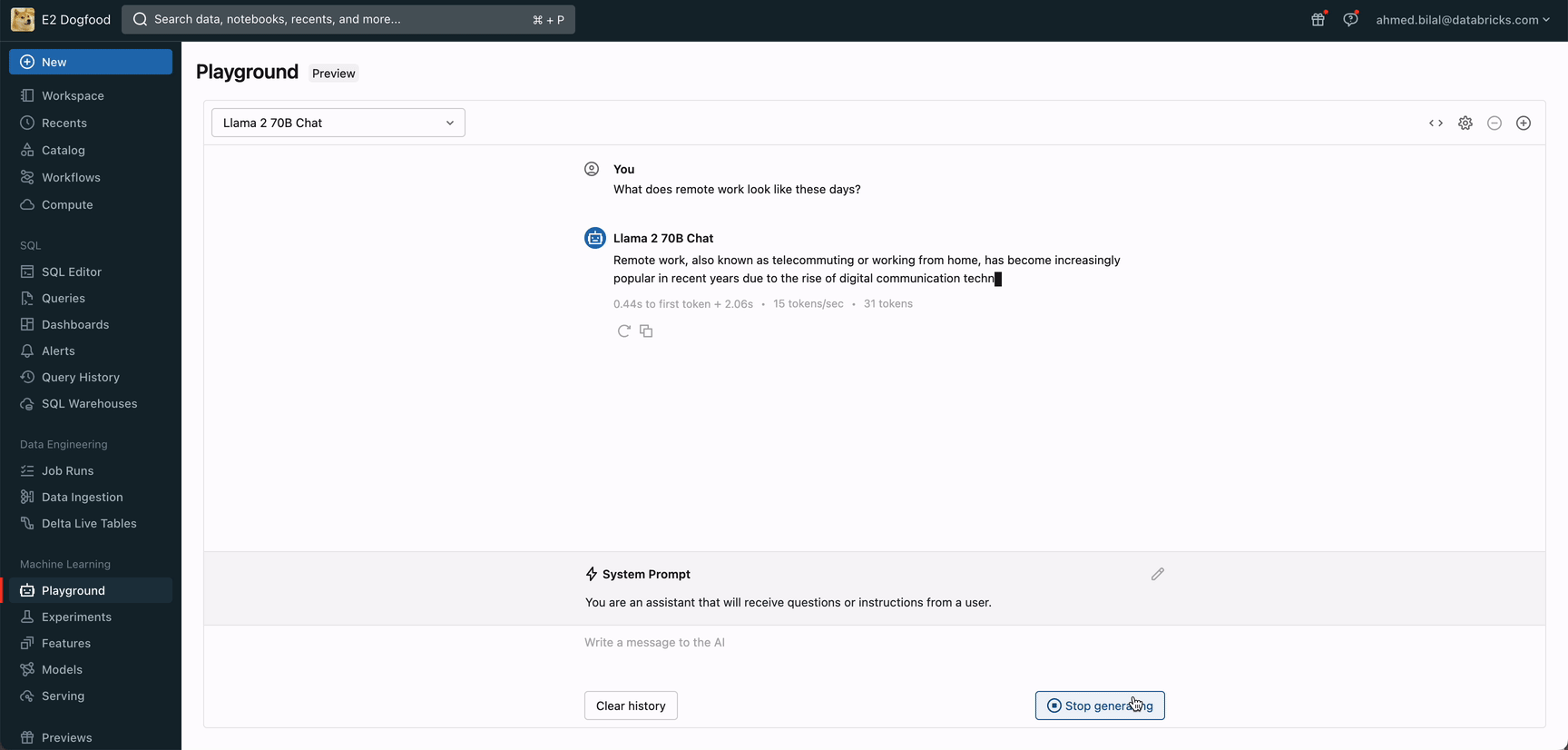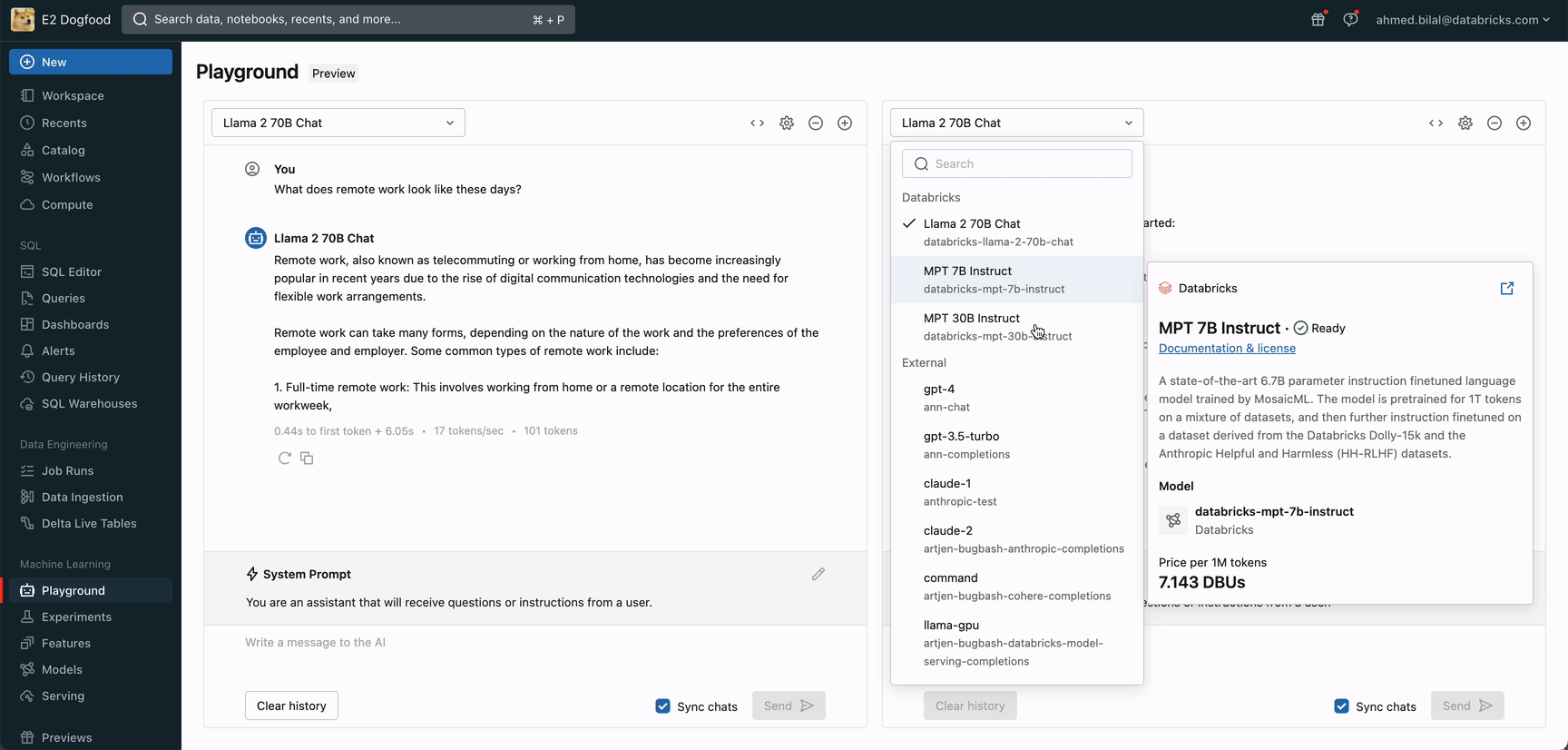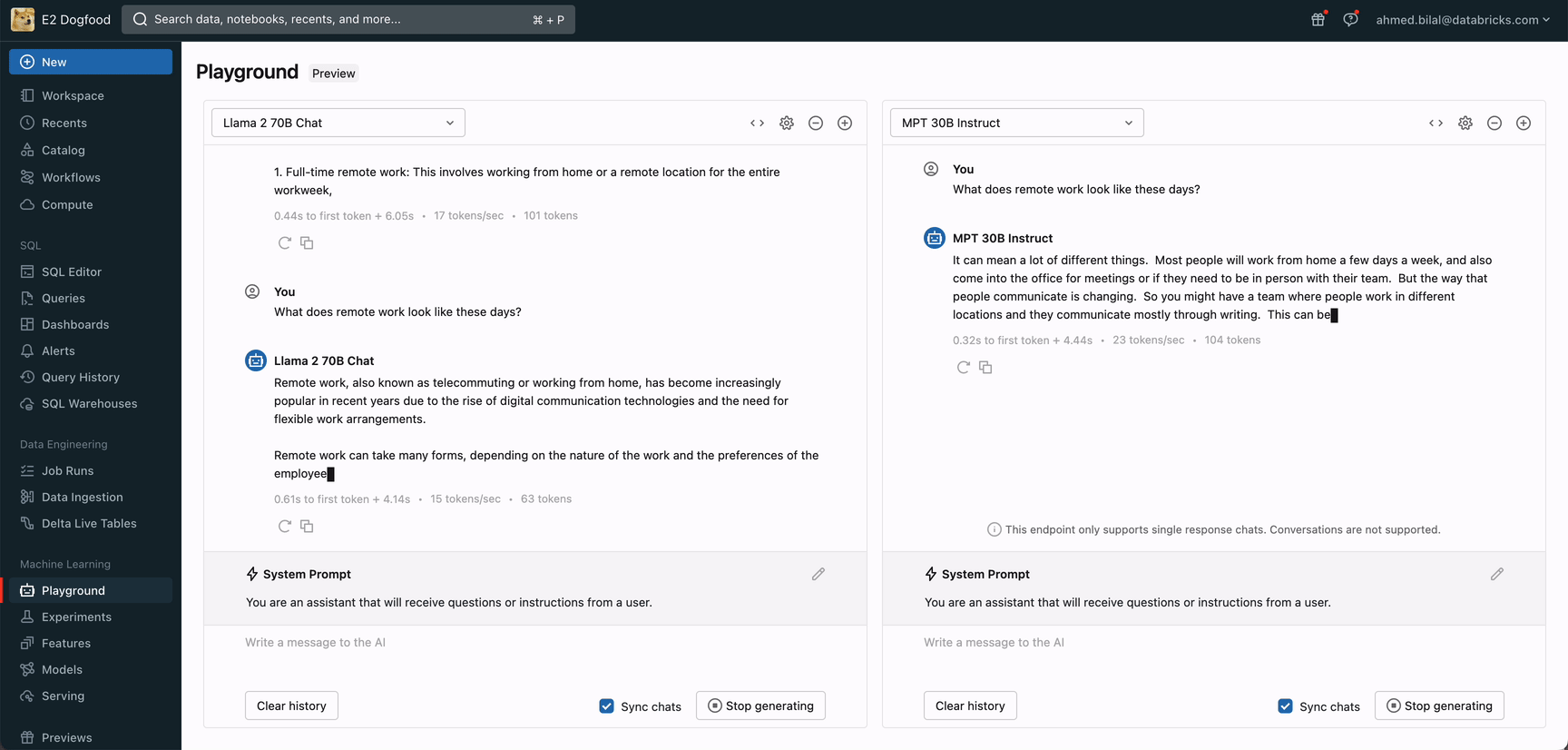
今すぐGenAIアプリを作り始めよう Databricks AI Playgroundにアクセスして、ワークスペースから直接、生成AIモデルを素早く試すことができます。
ファウンデーション・モデルの構築における課題
ソフトウェアはあらゆる産業に革命をもたらしましたが、AIは近い将来、既存のソフトウェアをよりインテリジェントなものに変えていくと考えています。その影響は大きく、カスタマーサポートから医療、教育まで、あらゆる分野に影響を及ぼします。私たちのお客様の多くは、すでにAIを製品に統合し始めていますが、本格的な生産への成長には、まだいくつかの課題があります:
- モデル間での実験: モデル間の実験:各ユースケースは、複数のオープンおよびプロプライエタリな選択肢の中から最適なモデルを特定するための実験を必要とします。企業は、異なるモデル・プロバイダの認証情報、レート制限、権限、クエリ構文を管理することを含め、モデル間で迅速に実験を行う必要があります。
- エンタープライズ・コンテキストの欠如: ファウンデーションモデルは幅広い知識を持っていますが、内部的な知識やドメインの専門知識が不足しています。そのまま使用すると、固有のビジネス要件を完全に満たすことができません。
- モデルの運用: 品質、デバッグ��、および安全性のために、リクエストとモデルの応答を一貫して監視する必要があります。モデル間のインターフェイスが異なるため、それらを管理および統合することが難しい。
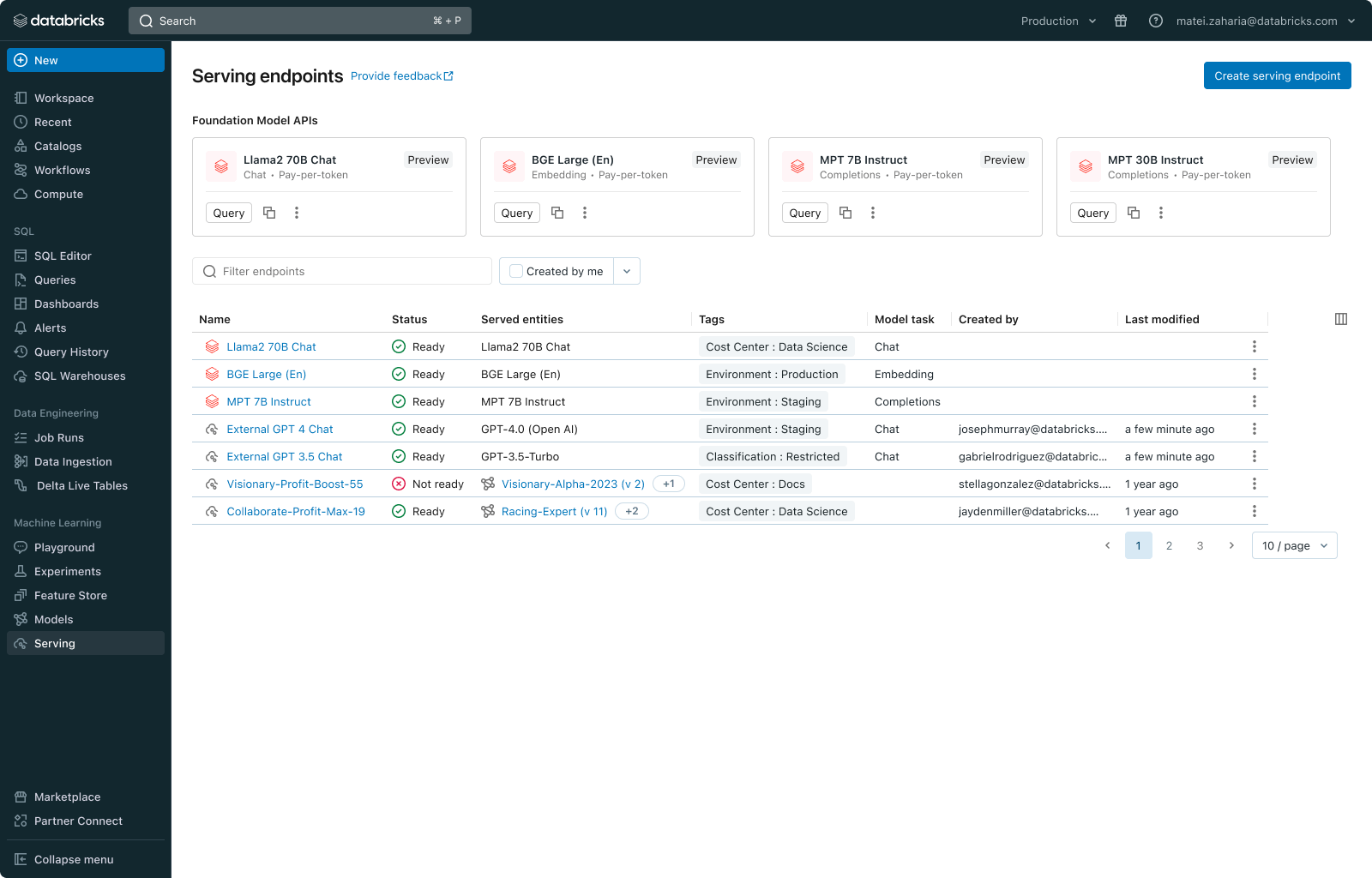
Databricks Model Serving:あらゆるファウンデーションモデルに対応する統合サービング
Databricks Model Servingは、大規模な言語モデルやビジョンアプリケーションを含む幅広いユースケースで、すでに数百社の企業で実運用されています。最新のアップデートにより、あらゆるFoundationモデルのクエリ、管理、および監視が大幅に簡素化されました。
"Databricks Model Servingを利用することで、ジェネレーティブAIを当社のプロセスに統合し、カスタマーエクスペリエンスを向上させ、業務効率を高めることができます。Model Servingにより、データとモデルを完全に制御しながらLLMモデルを展開することができます。"
- Ben Dias, Director of Data Science and Analytics at easyJet
ファウンデーション・モデルにアクセスする
Databricks Model Servingは、完全なカスタムモデル、Databricksが管理するモデル、サードパーティのFoundation Modelなど、あらゆるFoundation Modelをサポートします。この柔軟性により、適切な作業に適切なモデルを選択することができ、利用可能なモデルの範囲における将来の進歩に先んじることができます。このビジョンを実現するために、本日 2 つの新機能を紹介します:
- Foundation Model API:ファウンデーションモデルAPIは、Databricks上の一般的なファウンデーションモデルへの即時アクセスを提供します。これらのAPIは、Databricksのセキュリティ境界内でデータの安全性を確保しながら、基盤モデルのホスティングとデプロイの手間を完全に取り除きます。基礎モデルAPIはトークン単位で利用できるため、運用コストを大幅に削減できます。また、きめ細かいモデルやパフォーマンス保証が必要なワークロードの場合は、Provisioned Throughput(旧称Optimized LLM Serving)に切り替えることもできます。APIは現在、チャット(llama-2-70b-chat)、補完(mpt-30B-instruct & mpt-7B-instruct)、エンベッディング・モデル(bge-large-en-v1.5)など、さまざまなモデルをサポートしています。今後、提供モデルを拡大していく予定です。
- 外部モデル: 外部モデル(旧AI Gateway)では、Azure OpenAI GPTモデル、Anthropic Claudeモデル、AWS Bedrockモデルなど、Databricksの外部でホストされているモデルにアクセスするためのエンドポイントを追加することができます。一度追加すると、これらのモデルはDatabricks内から管理することができます。
さらに、データおよびAI資産のためのオープンマーケットプレイスであるDatabricks Marketplaceに、厳選されたファウンデーション(基盤)モデルのリストを追加しました。
"DatabricksのFoundation Model APIを利用することで、ボタンを押すだけで最先端のオープンモデルをクエリできるようになりました。このプラットフォーム上で複数のモデルを使用していますが、これまでのところ、安定性と信頼性、そして問題が発生したときにいつでも受けられるサポートに感銘を受けています"
- Sidd Seethepalli, CTO & Founder, Vellum
"DatabricksのFoundation Model API製品は、セットアップが非常に簡単で、すぐに使用できるため、RAGワークフローが簡単になりました。私たちはこの製品のパフォーマンス、スループット、価格設定に興奮しています。IT'のおかげでどれだけ時間を節約できたか、とても気に入っています"
- Ben Hills, CEO, HeyIris.AI
統一されたインターフェイスによるクエリーモデル
Databricks Model Servingは、Foundationモデルを簡単にクエリできるOpenAI互換の統一APIとSDKを提供します。また、AI Functionsを通じてSQLからモデルに直接クエリを実行することもでき、分析ワークフローへのAIの統合を簡素化します。標準的なインターフェイスにより、実験と比較が容易になります。例えば、DatabricksのAI生成ドキュメントで実証されているように、専有モデルから始めて、より低いレイテンシーとコストのために微調整されたオープンモデルに切り替えることができます。
全モデルの管理と監視
新しい Databricks Model Serving の UI とアーキテクチャにより、外部でホストされたものを含むすべてのモデルエンドポイントを一箇所で管理できるようになりました。これには、パーミッションの管理、使用制限の追跡、あらゆる種類のモデルの品質の監視が含まれます。例えば、管理者は外部モデルを設定し、チームやアプリケーションにアクセスを許可することで、認証情報を公開することなく、標準的なインターフェイスを介してモデルを照会することができます。このアプローチは、必要なガードレールを提供しながら、組織内で強力なSaaSやオープンLLMへのアクセスを民主化します。
"Databricks Model Serving は、Databricks 上または Databricks 外でホストされているモデルを含む、複数の SaaS モデルおよびオープンモデルへのセキュアなアクセスと管理を容易にすることで、当社の AI 主導プロジェクトを加速しています。一元化されたアプローチにより、セキュリティとコスト管理が簡素化され、当社のデータチームはイノベーションにより集中し、管理オーバーヘッドを削減することができます"
- Greg Rokita, AVP, Technology at Edmunds.com
個人データを使ってモデルを安全にカスタマイズ
データインテリジェンスプラットフォーム上に構築されたDatabricks Model Servingでは、検索拡張生成(RAG)、パラメータ効率的ファインチューニング(PEFT)、標準ファインチューニングなどのテクニックを使用して、基盤モデルのパワーを簡単に拡張することができます。独自のデータで基盤モデルを微調整し、Model Serving上で簡単に展開することができます。新しくリリースされたDatabricks AI Searchは、Model Servingとシームレスに統合され、最新かつコンテキストに関連した応答を生成することができます。
"Databricks Model Serving を使用することで、Stardog Voicebox 用に微調整された GenAI モデルを迅速にデプロイすることができました。Databricks Model Servingが提供する使いやすさ、柔軟なデプロイメントオプション、LLM最適化により、我々のデプロイメントプロセスは加速され、我々のチームはインフラストラクチャを管理するよりも、イノベーションに専念できるようになりました"
- Evren Sirin, CTO and Co-founder at Stardog
Databricks AI Playgroundで今すぐ始めよう
今すぐAIプレイグラウンドにアクセスして、強力な基礎モデルとの対話をすぐに始めましょう。AIプレイグラウンドでは、システムプロンプトや推論パラメータなどの設定をプロンプトや比較、調整することができます。
さらに詳しい情報はこちら:
- Foundation Model APIとExternal ModelsDocumentation �を参照してください。
- Databricks マーケットプレイスで基盤モデルを使用する。
- Databricks Generative AI Webセミナーに申し込む。
- Databricks Model Servingのウェブページに移動する。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。