AI生成ドキュメンテーションのためにオーダーメイドLLMを作成する
2人のエンジニア、1ヶ月、1,000ドル以下と、思っているより簡単です。
によって マシュー・ヘイズ, Hongyi Zhang, タオ・フェン, Zaheera Valani 、 Reynold Xin(レイノルド・シン) によ��る投稿
これは、大規模言語モデル(LLM)を使用して、Unityカタログのテーブルとカラムのドキュメントを自動的に生成するものです。私たちは、この機能がお客様から好評をいただいていることに身の引き締まる思いです。 現在、Databricksのテーブルメタデータ更新の80%以上がAI支援によるものです。
このブログポストでは、既製のSaaSベースのLLMを使用したハッカソンプロトタイピングから、より良く、より速く、より安いオーダーメイドのLLMの作成まで、この機能を開発した私たちの経験を紹介します。 この新しいモデルの開発には、2人のエンジニア、1ヶ月、1,000ドル未満の計算コストしかかかりませんでした(!)
私たちは、これらの学習がGenAIの幅広いユースケースに当てはまると考えているので、参考にしていただければ幸いです。 さらに重要なのは、オープンソースLLMの急速な進歩を利用できるようになったことです。
AIが作成した文書とは?
各データ・プラットフォームの中心には、データセット(多くの場合テーブル形式)の(潜在的に巨大な)コレクションがあります。 事実上、私たちが仕事をしたすべての組織において、テーブルの大半は文書化されていません。 文書がないために、人間がビジネス上の質問に答えるために必要なデータを発見することが難しくなったり、最近ではAIエージェントが質問に答えるために使用するデータセットを自動的に見つけることが難しくなるなど、多くの課題があります(私たちのプラットフォームではデータ・インテリジェンスと呼んでいる重要な機能)。
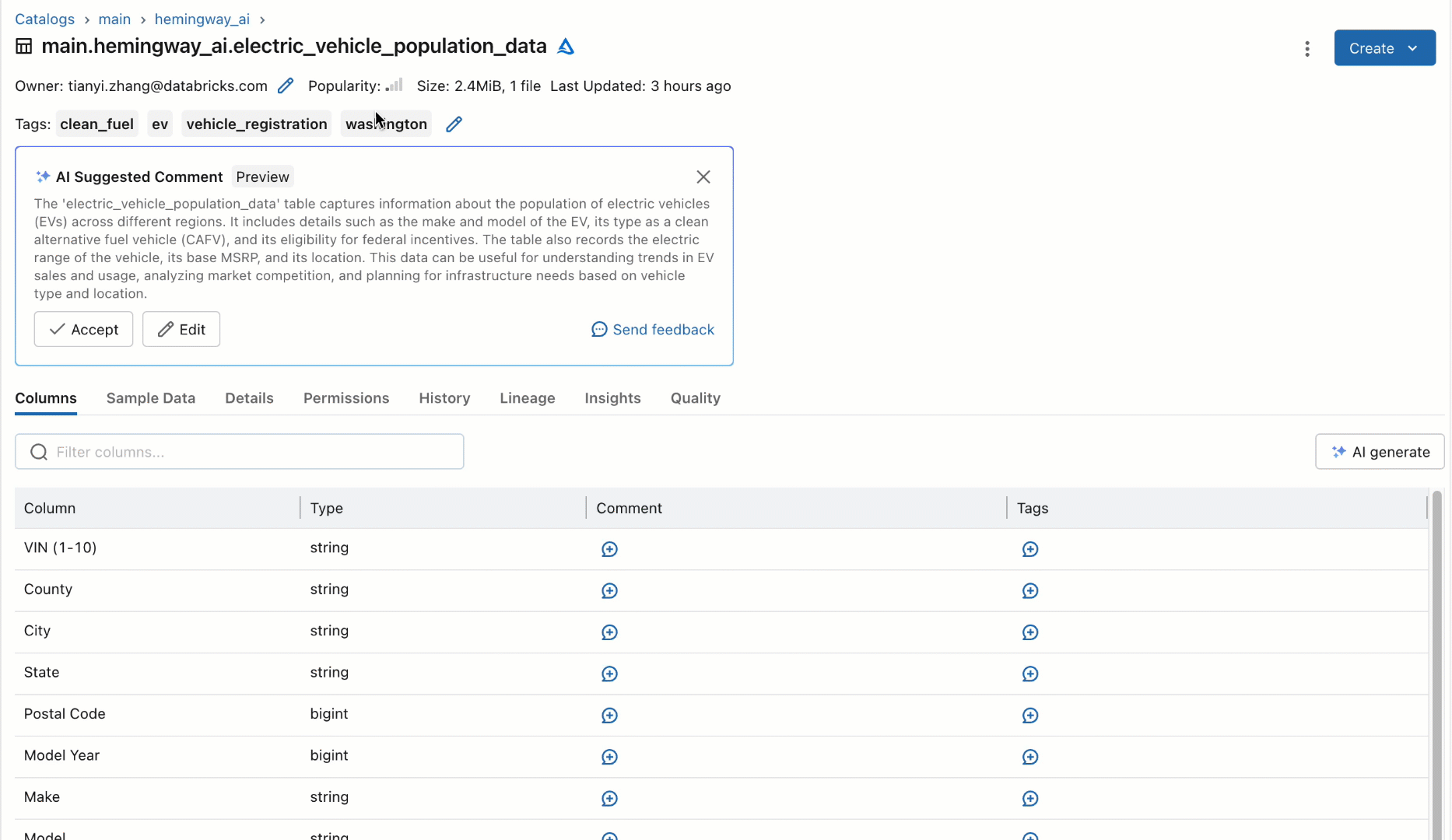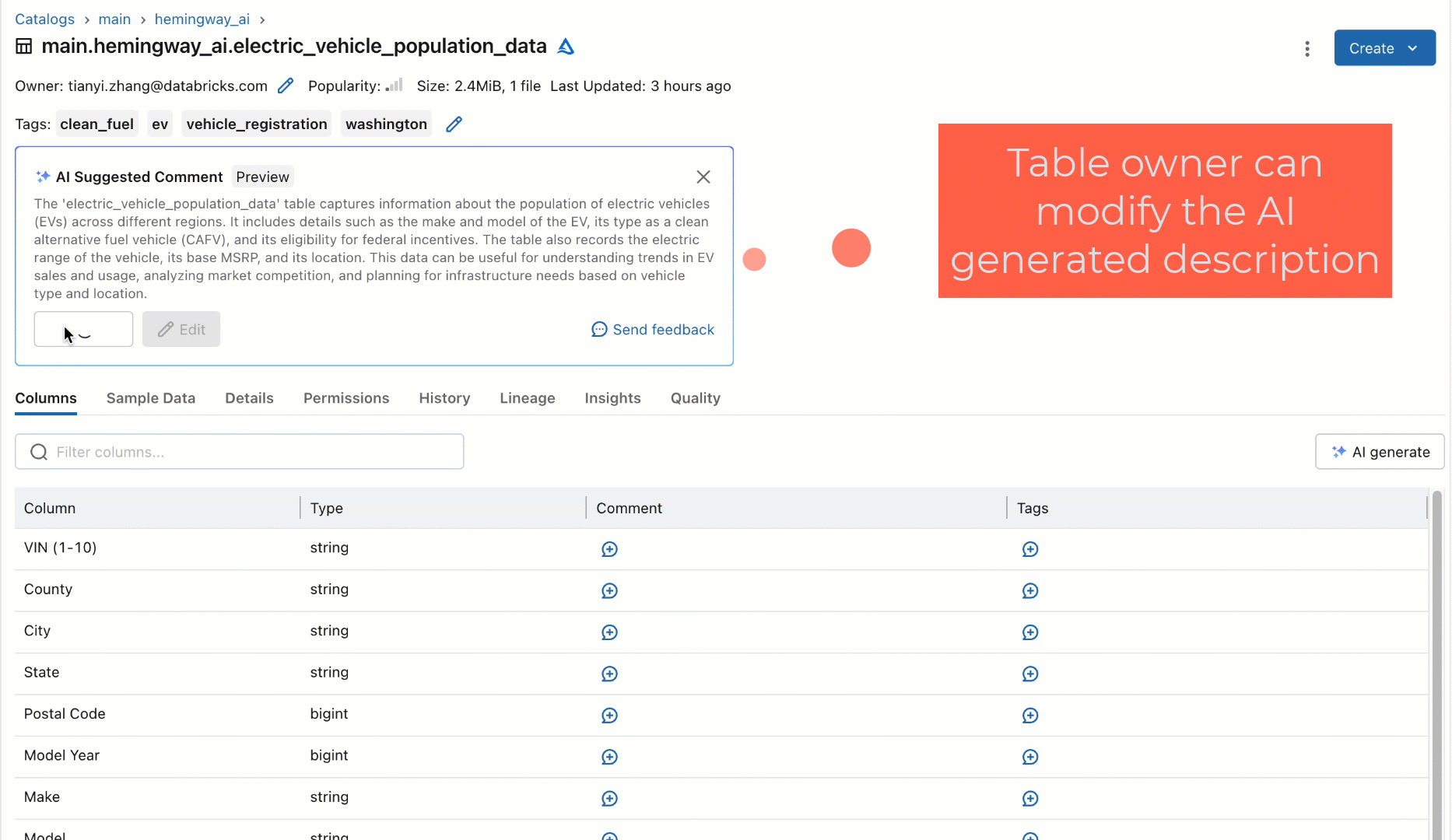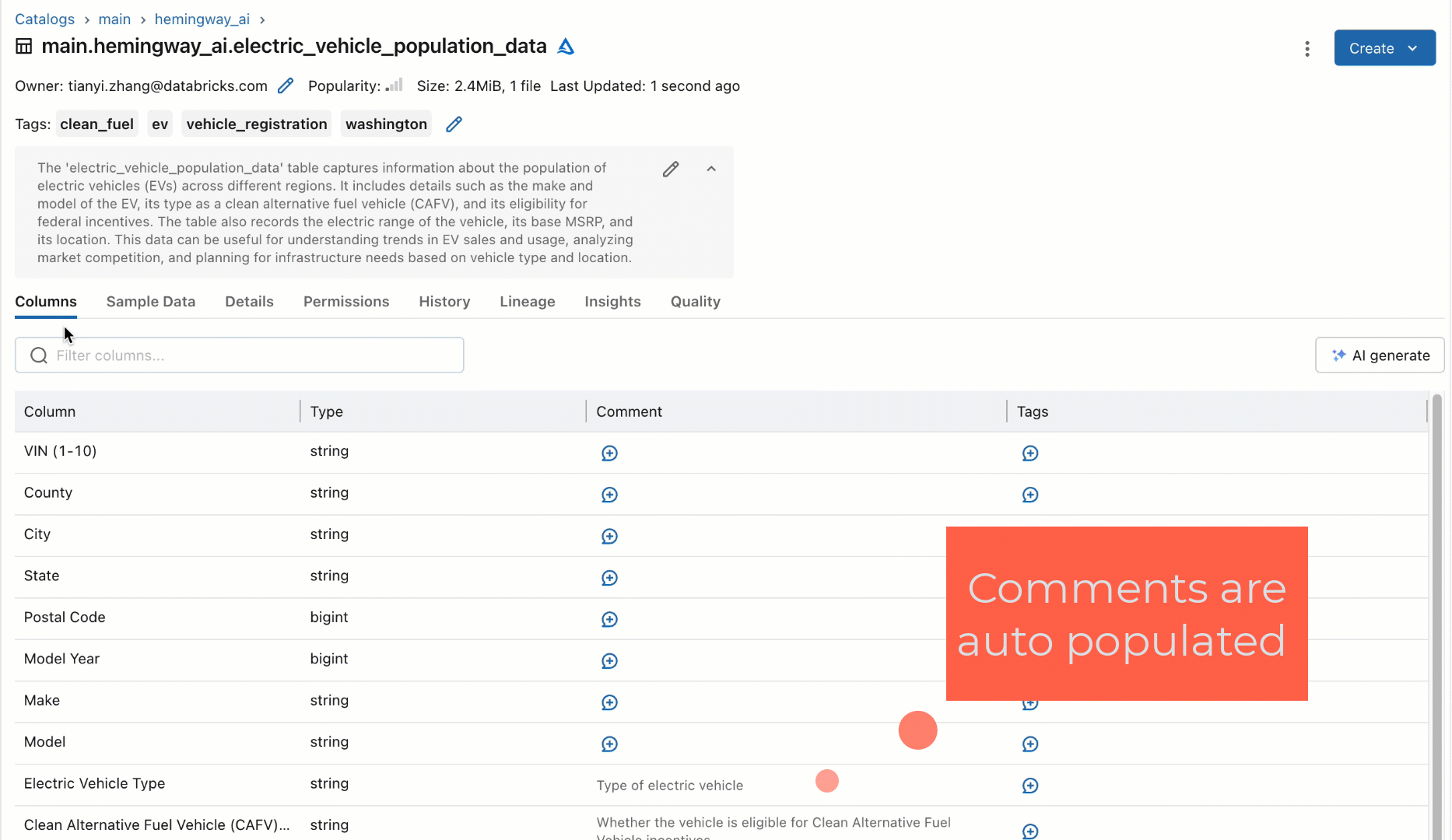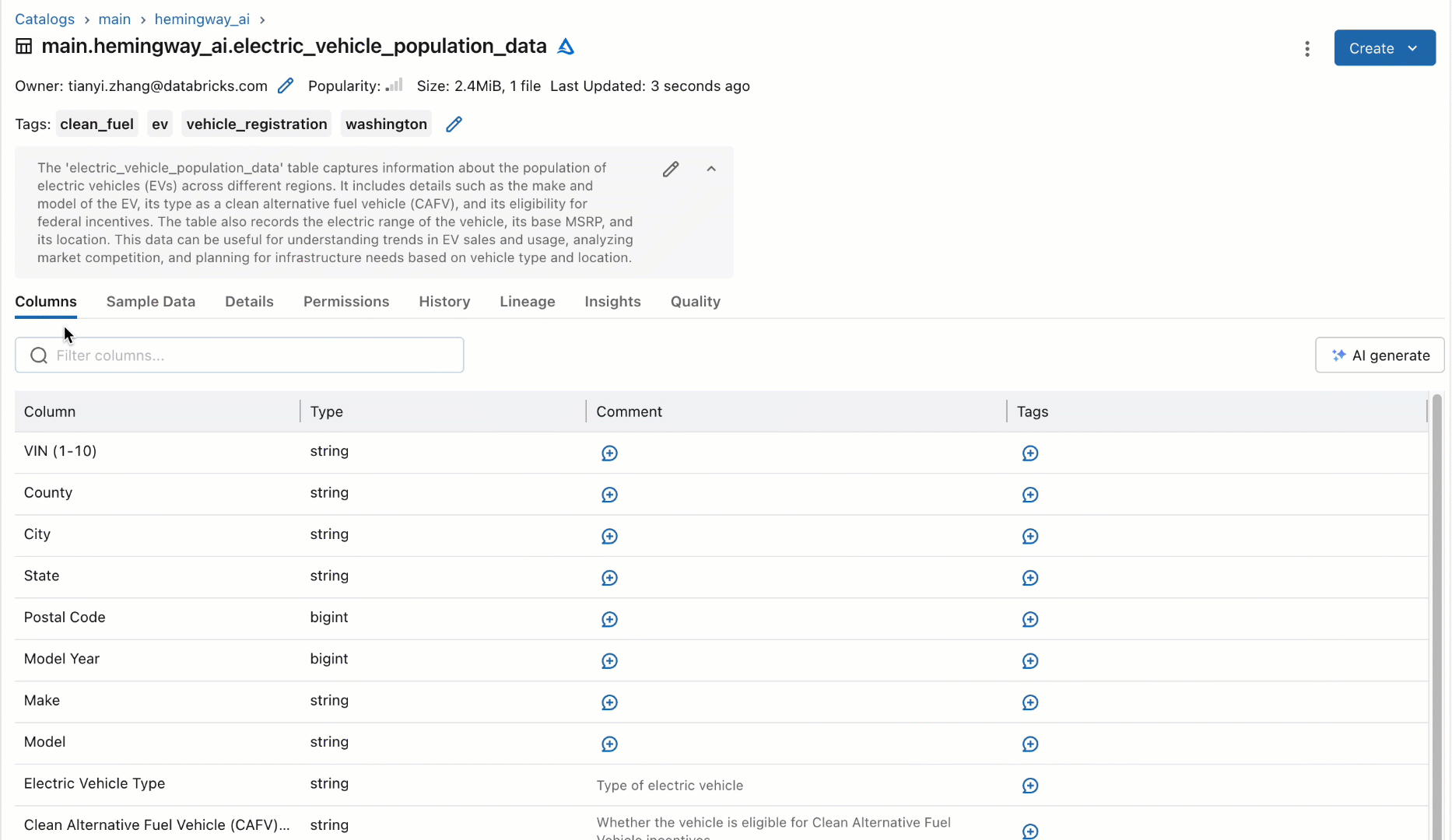
このようなデータセットのドキュメンテーションを人間に頼るのではなく、私たちは四半期に一度のハッカソンの一環として、既製のSaaSベースのLLMを使って、スキーマに基づいてテーブルとそのカラムのドキュメントを自動的に生成する新しいワークフローを試作しました。 この新しいワークフローは、以下のように、表や列の説明を自動的に提案し、ユーザーがその提案を個別に受け入れるか、一括して受け入れるか、より忠実なものに修正するかを選択できるようにするものです。 このプロトタイプを何人かのユーザーに見せたところ、即座に返ってきた質問は一様に "いつ手に入るの?"でした。
LLMの課題
この機能を全顧客に提供するために動き出したとき、私たちはモデルに関して3つの課題にぶつかりました:
- 品質:この機能が最終的に成功するかどうかは、生成されるドキュメントの品質にかかっています。 私たちは(どれくらいの頻度で受け入れられるかという意味で)質を測定することはできましたが、基本的なプロンプトを除けば、それを改善するために自由に使えるツ��マミは限られていました。 プライベート・プレビューの期間中、コードベースに変更を加えることなく、提案の質が低下していることに気づくこともありました。 我々の推測では、SaaSのLLMコントローラーがモデルのアップデートを行い、それが特定のタスクのパフォーマンスに影響を与えたのではないかと考えています。
- パフォーマンス(スループット):SaaSのLLMプロバイダーには、限られたAPIクォータしか提供されていませんでした。 我々は何万もの組織と仕事をしており、一つの組織が何百万ものテーブルを持っていることも珍しくありません。 スループット・クォータに基づいてすべてのテーブルのドキュメントを作成するには時間がかかりすぎます。
- コスト:上記と関連して、この特定の機能を使用するために顧客に課金しない限り、費用対効果がありませんでした。
私たちは、LLMベースのアプリケーションを概念実証から本番稼動に移行させようとしているさまざまな顧客から同様の懸念を聞いており、これは私たちのような組織にとって代替案を検討する絶好の機会だと考えました。
私たちはSaaS型LLMのさまざまなバージョンで実験を行いましたが、どれも同じ課題を抱えていました。 これは今から思えば驚くべきことではありません。 SaaS型LLMは工学的には驚異的ですが、非常に一般的なモデルであり、テーブルの生成から人生の意味についての会話まで、あらゆるユースケースに対応する必要があります。 汎用性が高いということは、非常に多くのパラメーターを持つ必要があるということであり、答えを返す速度とコストが制限されます。 さまざまなユースケースに最適化されるように進化し続けるので、私たちが持っている狭いユースケースを後退させる可能性もあります。
オーダーメイドモデルの構築
前述の課題に対処するため、私たちは特注モデルの構築に着手しました。 人のエンジニアからなるチームが、より良く、より速く、より安い、カスタマイズされた小型のLLMを作るのに1ヶ月かかりました:
- 品質:我々の評価(下記参照)によれば、このモデルはSaaSモデルの廉価版よりもかなり優れており、高価版とほぼ同等です。
- パフォーマンス(スループット):オーダーメイドのモデルはかなり小さいので、A10 GPUに収めることができ、水平スケーリングによって推論スループットを向上させることができます。 また、GPUが小型化されたことで、すべてのテーブルの記述をより高速に生成できるようになりました。
- コスト:モデルを微調整するたびにかかる費用は数ドルで、多くの実験を行ったため、全体として開発にかかった費用は1000ドル以下でした。 また、推論コストも10分の1になりました。
最初のステップは、これを応用機械学習の問題として扱うことでした。 「応用機械学習」というと難しく複雑に聞こえますが、私たちに必要なことはそれだけでした:
- 初期モデルをブートストラップするためのトレーニングデータセットを見つける。
- 本番に展開する前に、品質を測定できる評価メカニズムを特定する。
- モデルの訓練と選択を行う。
- 実際の使用状況のメトリクスを収集するこ�とで、モニターが本番環境でどの程度機能するかを監視できる。
- 品質、パフォーマンス、コストの3つの側面を継続的に改善するために、新しいモデルを反復し、展開する。
トレーニングデータ
この微調整タスクのために、2つの異なるデータソースを用いて初期トレーニングデータセットを作成しました:
- 北米産業分類システム(NAICS)コード。 連邦統計機関が米国企業経済に関する統計データを収集、分析、公表する目的で事業所を分類する際に使用する公開データセット
- Databricks社内のユースケース分類キュレーションデータセット。 これは、当社のソリューションアーキテクトが、ベストプラクティスのアーキテクチャを顧客に示すために作成した一連の内部データセット
次に、上記のユースケースを使用して CREATE TABLE ステートメントを合成し、多様なテーブルのセットを作成し、別の LLM を使用してテーブルの説明とカラムのコメントを含むサンプル応答を生成しました。 合計で〜3600のトレーニング例を作成しました。
この強力な機能のトレーニングには、顧客データは一切使用していません。
ブートストラップ・モデル評価
機能ローンチ後、ユーザーが提案を受け入れる率などの生産指標を通じて、モデルの品質を測定することができます。 しかし、ローンチにこぎつける前に、SaaS型LLMと比較してモデルの質を評価する方法が必要でした。
偏りのない方法でこれを行うため、単純な二重盲検評価の枠組みを設�定し、4人の従業員に、62の未見の表セットを使用して、比較したい2つのモデルから生成された表記述を評価してもらいました。 そして、我々のフレームワークは、各行が入力を示し、両方の出力をランダムな順序で示すシートを生成しました。 評価者はより良いサンプルに投票します(あるいは同点にする)。 このフレームワークは、異なる評価者の投票を処理して報告書を作成し、各評価者の同意の度合いもまとめています。
これまでの経験に基づけば、数十から数百のデータポイントの評価データセットを持つことは、最初のマイルストーンとして十分であり、他のユースケースにも一般化できます。
モデルの選択と微調整
モデル選択にあたっては、以下の基準を考慮しました:
- ライセンスが商業利用をサポートしているかどうか
- テキスト生成モデルのパフォーマンス(品質)
- モデルのスピード
これらの基準に基づき、MPT-7BとLlama2-7Bが有力候補となりました。MPT-30BやLlama-2-13Bといった大型モデルも検討しました。 最終的にMPT-7Bを選んだのは、品質と推論性能の組み合わせが最も優れていたからです:
- このタスクでは、MPT-7BとLlama-2-7Bのファインチューニングモデルの間に、品質に明らかな差はなかった。
- 7Bの小型モデルは、微調整を経て、すでに品質の水準を満たしていた。 SaaSモデルの廉価版よりかなり良く、高価版とほぼ同等だった。
- このタスクに大型モデルを使用することで、増大するサービングコストを正当化できるような、測定可能なメリットはまだ観察されていない。
- 小型モデルのレイテンシーは、同等の品質を提供しながら、大型モデルよりも大幅に改善された。
- より小型のモデルは快適にフィットし、より入手しやすいA10 GPUを使ってサービスを提供することができる。 その数が多ければ多いほど、タスクの推論スループットは高くなる。
3,600の例でモデルを微調整するのにかかった時間は、合計でわずか15分ほどでした!!
我々はMPT-7Bをモデルに選びましたが、LLMの状況は急速に変化しており、今日のベストモデルが明日のベストモデルとは限らないと考えています。 そのため、私たちはこれを反復的かつ継続的なプロセスと考え、評価を効率的かつ迅速に行えるツールの使用に重点を置いています。
生産パイプラインの主要なアーキテクチャ・コンポーネント
私たちは、Databricks Data Intelligence Platformの以下の主要コンポーネントに依存することで、これを迅速に構築することができました:
- Databricks LLMの微調整。 これは、我々のタスクのためにモデルを微調整するための非常にシンプルなインフラを提供する。 JSON形式のトレーニングデータを用意し、CLIコマンド1行でLLMを微調整することができた。
- Unityカタログ:プロダクションで使用するモデルはUnity Catalog(UC)に登録され、データだけでなくモデルにも必要なガバナンスを提供する。 エンド・ツー・エンドのリネージ機能により、UCはモデルから学習させたデータセットまでのトレーサビリティも提供してくれる。
- デルタ共有:デルタ・シェアリングを使って、世界中にあるすべてのプロダクション・リージョンにモデルを配布し、より速くサービスを提供できるようにした。
- Databricksの 最適化されたLLMサービング:モデルがUCに登録されると、新しい最適化されたLLMサービングを使用してサービングすることができます。このサービングは、従来のLLMサービングと比較して、スループットとレイテンシの面で大幅な性能向上を実現する。
まとめ
十分に文書化されたデータを持つことは、すべてのデータ・ユーザーにとって重要であり、AIベースのデータ・プラットフォーム(私たちはデータ・インテリジェンスと呼んでいる)を強化するために、その重要性は日に日に増しています。 私たちは、このGenAIの新機能のプロトタイピングのためにSaaSのLLMを使い始めましたが、品質、パフォーマンス、コストの問題にぶつかりました。 私たちは、同じタスクをより高い品質でこなし、しかもスケールアウトでより高いスループットと10倍のコスト削減を実現する特注モデルを構築しました。 何が必要だったかを振り返ってみます:
- エンジニア2名
- 1か月
- トレーニングや実験に必要なコンピュート費用は1000ドル以下
- MPT-7B、3600の合成例題を15分以内に微調整
- 4人の人間評価者、62の初期評価例を持つ
この経験は、特定のタスクのために特注のLLMを開発し、配備することがいかに容易�であるかを示しています。 このモデルは現在、Amazon Web ServicesとGoogle CloudのDatabricks上で稼働しており、プラットフォーム上のほとんどのデータアノテーションに使用されています。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。