検索拡張生成(RAG)とは?
生成前に外部のナレッジベースから関連情報を検索することでLLMの回答を強化し、事実に基づいた出力を実現する技術
によって Databricks Staff による投稿
- 検索拡張生成(RAG)は、外部のデータソースから関連する文書をまず検索し、そのコンテキストをモデルに提供することで、大規模言語モデル(LLM)の回答を向上させるAIパターンです。
- RAGは、ハルシネーションを減らし、回答を最新の状態に保ち、基盤となるモデルを再学習させることなく、組織独自のコンテンツに合わせて出力をカスタマイズするのに役立ちます。
- 一般的なRAGのユースケースには、カスタマーサポートのチャットボット、社内ナレッジ検索、企業の文書から直接質問に答える拡張検索エクスペリエンスなどがあります。
検索拡張生成(RAG)とは?
検索拡張生成(RAG)は、大規模言語モデル(LLM)を外部の最新データソースと組み合わせることで強化する、ハイブリッドなAIフレームワークです。静的なトレーニングデータのみに依存するのではなく、RAGはクエリの実行時に関連するドキュメントを検索し、コンテキストとしてモデルに提供します。新しくコンテキストを考慮したデータを取り入れることで、AIはより正確で最新の、ドメインに特化した回答を生成できます。
RAGは、エンタープライズレベルのAIアプリケーションを構築するための標準的なアーキテクチャとして急速に普及しています。最近の調査によると、60%以上の組織が、信頼性の向上、ハルシネーション(根拠のない回答)の削減、および社内データを使用した出力のパーソナライズを目的として、AIを活用した検索ツールの開発に取り組んでいます。
ジェネレーティブAIがカスタマーサービス、社内のナレッジ管理、コンプライアンスなどの業務機能に拡大する中、一般的なAIと組織固有の知識とのギャップを埋めるRAGの能力は、信頼性の高い実用的な導入に不可欠な基盤となっています。
RAGの仕組み
RAGは、外部データソースから取得した、コンテキストを考慮したリアルタイムの情報を注入することで、言語モデルの出力を強化します。ユーザーがクエリを送信すると、システムはまず検索モデルを起動します。このモデ��ルは、ベクトルデータベースを使用して、意味的に類似したドキュメント、データベース、またはその他のソースを特定し、関連情報を「検索(リトリーブ)」します。特定された情報は、元の入力プロンプトと組み合わされてジェネレーティブAIモデルに送信され、AIモデルはその新しい情報を統合して回答を生成します。
これにより、LLMはトレーニングされたモデルだけに依存するのではなく、企業固有のデータや最新のデータに基づいた、より正確でコンテキストに応じた回答を生成できるようになります。
RAGパイプラインは通常、ドキュメントの準備とチャンク分割、ベクトルインデックス作成、検索、プロンプト拡張の4つのステップで構成されます。このプロセスフローにより、開発者はモデルを再トレーニングすることなくデータソースを更新できるため、RAGはカスタマーサポート、ナレッジベース、社内検索などの分野でLLMアプリケーションを構築するための、拡張性とコスト効率に優れたソリューションとなります。
検索拡張生成(RAG)アプローチはどのような課題を解決するのか?
課題1:LLMモデルは自社のデータを知らない
LLMはディープラーニングモデルを使用し、大規模なデータセットでトレーニングを行うことで、新しいコンテンツを理解、要約、生成します。ほとんどのLLMは広範な公開データでトレーニングされているため、1つのモデルで多くの種類のタスクや質問に対応できます。しかし、一度トレーニングされると、多くのLLMはトレーニング��データのカットオフポイント(基準時点)以降のデータにアクセスする能力を持ちません。そのため、LLMは静的なものとなり、トレーニングされていないデータについて質問された場合、誤った回答をしたり、古い情報を返したり、ハルシネーション(根拠のない回答)を起こしたりする可能性があります。
課題2:AIアプリケーションを効果的に機能させるには、カスタムデータを活用する必要がある
LLMが関連性の高い具体的な回答を提供するためには、組織はモデルに自社のドメインを理解させ、大まかで一般的な回答ではなく、自社のデータに基づいた回答を提供させる必要があります。たとえば、LLMを使用してカスタマーサポートボットを構築する場合、そのソリューションは顧客の質問に対して企業固有の回答を提供しなければなりません。また、社内のHRデータに関する従業員の質問に答える社内Q&Aボットを構築している企業もあります。モデルを再トレーニングすることなく、このようなソリューションを構築するにはどうすればよいでしょうか?
解決策:検索拡張は現在、業界の標準となっている
自社データを使用する簡単で一般的な方法は、LLMモデルにクエリを実行するプロンプトの一部としてデータを提供することです。これは、関連するデータを検索し、LLMの拡張コンテキストとして使用することから、検索拡張生成(RAG)と呼ばれます。トレーニングデータから得られた知識のみに依存するのではなく、RAGワークフローは関連情報を引き出し、静的なLLMをリアルタイムのデータ検索と接続します。
RAGアーキテクチャを使用すると、組織は任意のLLMモデルをデプロイし、少量のデータを提供するだけで、モデルのファインチューニングや事前トレーニングにかかるコストと時間をかけずに、自社に関連する結果を返すように拡張できます。
RAGのユースケースにはどのようなものがあるか?
RAGにはさまざまなユースケースがあります。最も一般的なものは以下の通りです:
Q&Aチャットボット:LLMをチャットボットに組み込むことで、企業のドキュメントやナレッジベースからより正確な回答を自動的に導き出すことができます。チャットボットは、カスタマーサポートやWebサイトのリードフォローアップを自動化し、質問への回答や問題の迅速な解決に活用されています。
たとえば、多国籍データブローカーであり消費者信用調査会社であるExperianは、社内および顧客向けのニーズに対応するチャットボットの構築を検討していました。同社はすぐに、既存のチャットボット技術では需要に合わせたスケールアップが困難であることに気づきました。Databricks Data Intelligence Platform上でGenAIチャットボット「Latte」を構築することにより、Experianはプロンプト処理とモデルの精度を向上させることができました。これにより、チームはさまざまなプロンプトを試行し、出力を微調整し、GenAI技術の進化に迅速に適応するための高い柔軟性を得ることができました。
- 検索拡張:LLMを検索エンジンに組み込み、LLMが生成した回答で検索結果を拡張することで、情報検索のクエリに対してより適切な回答を提供し、ユーザーが業務に必要な情報を容易に見つけられるようにします。
ナレッジエンジン:自社データ(HR、コンプライアンス文書など)に関する質問:企業のデータをLLMのコンテキストとして使用することで、従業員は福利厚生やポリシーに関するHR関連の質問、セキュリティやコンプライアンスに関する質問などに対して、簡単に回答を得ることができます。
この導入事例の1つが、東南アジアを代表する自動車グループであるCycle & Carriageです。同社はDatabricksを採用し、技術マニュアル、カスタマーサポートの書き起こし、業務プロセス文書などの独自ナレッジベースを活用するRAGチャットボットを開発しました。これにより、生産性と顧客エンゲージメントが向上しました。従業員は自然言語クエリを使用して情報を簡単に検索し、コンテキストに応じたリアルタイムの回答を得られるようになりました。
RAGのメリットとは?
RAGアプローチには、以下のような多くの主なメリットがあります:
- 最新かつ正確な回答の提供:RAGは、LLMの回答が静的で古いトレーニングデータのみに基づかないようにします。モデルは最新の外部データソースを使用して回答を提供します。
- 不正確な回答(ハルシネーション)の削減:LLMモデルの出力を関連する外部知識に基づかせることで、RAGは誤った情報や捏造された情報(ハルシネーションとも呼ばれます)を回答するリスクを軽減します。出力には元の情報源の引用を含めることができるため、人間による検証が可能です。
- ドメインに特化した関連性の高い回答の提供:RAGを使用することで、LLMは組織独自のデータやドメイン固有のデータに合わせて、コンテキストに応じた関連性の高い回答を提供できるようになります。
- 効率的かつ優れたコストパフォーマンス:ドメイン固有のデータでLLMをカスタマイズする他のアプローチと比較して、RAGはシンプルでコスト効率に優れています。組織はモデルをカスタマイズすることなくRAGを導入できます。これは、新しいデータでモデルを頻繁に更新する必要がある場合に特に有益です。
RAGを使用すべきなのはどのような場合で、モデルをファインチューニングすべきなのはどのような場合か?
RAGは簡単に始めることができ、一部のユースケースではそれだけで完全に十分な場合もあるため、最初に検討すべき最適なアプローチです。ファインチューニングは、LLMの動作を変更したい場合や、異なる「言語」を学習させたい場合など、別の状況で最も適しています。これらは相互に排性的なものではありません。将来的なステップとして、ドメイン言語や望ましい出力形式をよりよく理解するためにモデルをファインチュー��ニングし、同時に回答の品質と関連性を向上させるためにRAGを使用することも検討できます。
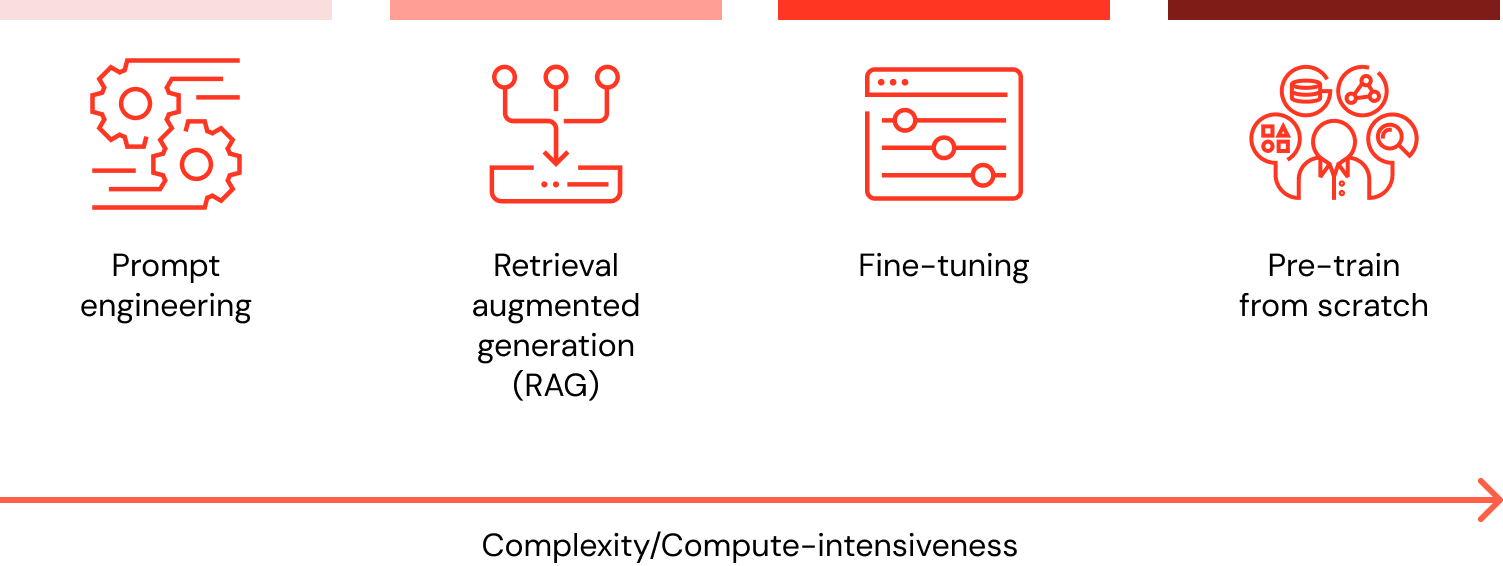
データを使用してLLMをカスタマイズしたい場合、どのような選択肢があり、どの方法が最適か(プロンプトエンジニアリング vs. RAG vs. ファインチューニング vs. 事前トレーニング)?
組織のデータを使用してLLMアプリケーションをカスタマイズする際、考慮すべき4つのアーキテクチャパターンがあります。これらの手法は以下に概説されており、相互に排他的なものではありません。むしろ、それぞれの強みを活かすために組み合わせることも可能であり、そうすべきです。
| 手法 | 定義 | 主なユースケース | データ要件 | メリット | 考慮事項 |
|---|---|---|---|---|---|
プロンプトエンジニアリング | LLMの動作をガイドするための専用プロンプトの作成 | 迅速かつ即座のモデルガイダンス | なし | 高速、費用対効果が高い、トレーニング不要 | ファインチューニングよりもコントロール性が低い |
検索拡張生成(RAG) | LLMと外部知識検索の組み合わせ | 動的なデータセットと外部知識 | 外部の知識ベースまたはデータベース(例:ベクトルデータベース) | 動的に更新されるコンテキスト、精度の向上 | プロンプト長と推論計算量の増加 |
ファインチューニング | 事前学習済みLLMを特定のデータセットやドメインに適応させる | ドメインまたはタスクの専門化 | 数千件のドメイン固有または指示のサンプル | きめ細かなコントロール、高度な専門化 | ラベル付きデータが必要、計算コストがかかる |
事前学習 | LLMをゼロからトレーニングする | 独自のタスクまたはドメイン固有の企業 | 大規模なデータセット(数十億〜数兆トークン) | 最大限のコントロール、特定のニーズに合わせたカスタマイズ | 極めてリソース集約的 |

どの手法を選択するかにかかわらず、適切に構造化されモジュール化された方法でソリューションを構築することで、組織は反復と適応の準備を整えることができます。このアプローチなどの詳細については、The Big Book of MLOpsをご覧ください。
RAG実装における一般的な課題
RAGを大規模に実装すると、技術的および運用上の課題がいくつか生じます。
- 検索の品質。 最も強力なLLMであっても、無関係な文書や低品質な文書を検索してしまうと、不適切な回答を生成する可能性があります。したがって、埋め込みモデル、類似度メトリクス、ランキング戦略を慎重に選択することを含む、効果的な検索パイプラインを開発することが極めて重要です。
- コンテキストウィンドウの制限。 世界中のすべてのドキュメントをすぐに利用できるため、モデルにコンテンツを注入しすぎて、ソースが切り捨てられたり、回答が薄まったりするリスクがあります。チャンキング戦略では、意味的な一貫性とトークン効率のバランスを考慮する必要があります。
- データの鮮度。 RAGのメリットは、最新の情報を抽出できる点にあります。しかし、定期的な取り込みジョブや自動更新を行わないと、ドキュメントのインデックスはすぐに古くなってしまいます。データの鮮度を保つことで、ハルシネーションや古い回答を避けることができます。
- レイテンシー。 大規模なデータセットや外部APIを扱う場合、レイテンシーが検索、ランキング、生成の妨げになることがあります。
- RAGの評価。 RAGのハイブリッドな性質上、従来のAI評価モデルでは不十分です。出力の精度を評価するには、回答の品質を評価するための人間の判断、関連性スコアリング、グラウンデッドネス(根拠性)チェックを組み合わせる必要があります。
RAGアプリケーションのリファレンスアーキテクチャとは何ですか?
特定のニーズやデータのニュアンスに応じて、検索拡張生成システムを実装する方法は数多くあります。以下は、プロセスの基本的な理解を提供するために、一般的に採用されているワークフローの1つです。
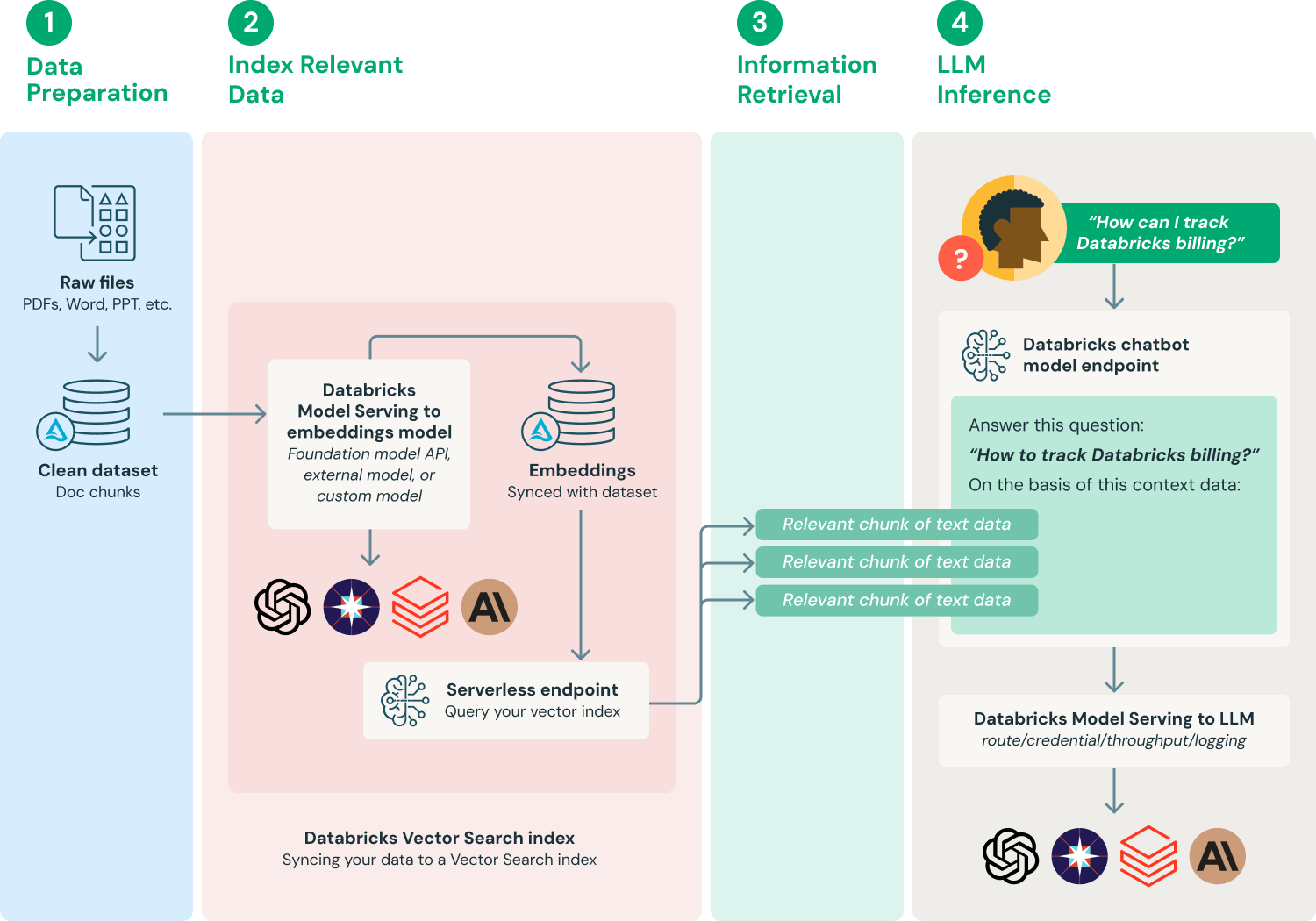
- データの準備: ドキュメントデータはメタデータとともに収集され、初期の前処理(例:PII(個人特定情報)の処理(検出、フィルタリング、黒塗り、置換))が行われます。RAGアプリケーションで使用するには、選択し�た埋め込みモデルや、これらのドキュメントをコンテキストとして使用するダウンストリームのLLMアプリケーションに基づいて、ドキュメントを適切な長さにチャンク化する必要があります。
- 関連データのインデックス作成: ドキュメントの埋め込みを生成し、このデータでAI Searchインデックスを設定します。
- 関連データの検索: ユーザーのクエリに関連するデータの一部を検索します。その後、そのテキストデータはLLMに使用されるプロンプトの一部として提供されます。
- LLMアプリケーションの構築: プロンプト拡張のコンポーネントとLLMへのクエリをエンドポイントにラップします。このエンドポイントは、シンプルなREST APIを介して、Q&Aチャットボットなどのアプリケーションに公開できます。
Databricksは、RAGアーキテクチャのいくつかの重要なアーキテクチャ要素も推奨しています。
- ベクトルデータベース: 一部の(すべてではありませんが)LLMアプリケーションは、高速な類似性検索のためにベクトルデータベースを使用します。これは、LLMクエリでコンテキストやドメイン知識を提供するために最もよく使用されます。デプロイされた言語モデルが最新の情報にアクセスできるように、定期的なベク��トルデータベースの更新をジョブとしてスケジュールできます。ベクトルデータベースから検索してLLMコンテキストに情報を注入するロジックは、MLflowのLangChainまたはPyFuncモデルフレーバーを使用して、MLflowに記録されたモデルアーティファクトにパッケージ化できることに注意してください。
- MLflow LLM DeploymentsまたはModel Serving: サードパーティのLLM APIを使用するLLMベースのアプリケーションでは、外部モデルに対するMLflow LLM DeploymentsまたはModel Servingのサポートを、OpenAIやAnthropicなどのベンダーからのリクエストをルーティングするための標準化されたインターフェースとして使用できます。エンタープライズグレード of APIゲートウェイを提供するだけでなく、MLflow LLM DeploymentsまたはModel ServingはAPIキー管理を一元化し、コスト管理を強制する機能を提供します。
- Model Serving: サードパーティAPIを使用したRAGの場合、主要なアーキテクチャの変更点の1つは、LLMパイプラインがModel Servingエンドポイントから社内また��はサードパーティのLLM APIへの外部API呼び出しを行うことです。これにより、複雑さ、潜在的なレイテンシー、および資格情報管理の別のレイヤーが追加されることに注意する必要があります。対照的に、ファインチューニングされたモデルの例では、モデルとそのモデル環境がデプロイされます。
リソース
- Databricksブログ記事
- Databricksデモ
- Databricks eブック — The Big Book of MLOps
RAGを使用しているDatabricksのお客様
JetBlue
JetBlueは、Databricksを基盤とし、企業データで補完されたオープンソースの生成AIモデルを使用するチャットボット「BlueBot」を導入しました。このチャットボットは、JetBlueのすべてのチームが利用でき、ロールに基づいて制御されたデータにアクセスできます。たとえば、財務チームはSAPのデータや規制当局への提出書類を閲覧できますが、運用��チームはメンテナンス情報のみを閲覧できます。
こちらの記事もご覧ください。
Chevron Phillips
Chevron Phillips Chemicalは、文書処理の自動化を含む生成AIの取り組みをサポートするためにDatabricksを使用しています。
Thrivent Financial
Thrivent Financialは、検索の向上、より適切に要約されアクセスしやすいインサイトの生成、そしてエンジニアリングの生産性向上のために生成AIの活用を検討しています。
検索拡張生成(RAG)に関する詳細情報はどこで入手できますか?
RAGに関する詳細情報については、以下をはじめとする多くのリソースが用意されています。
ブログ
- Databricksを使用した高品質なRAGアプリケーションの構築
- Databricks AI Search パブリックプレビュー
- リアルタイムの構造化データによるRAGア�プリケーションの回答品質の向上
- 新しい基盤モデル機能による生成AIアプリの迅速な構築
- RAGアプリケーションのLLM評価におけるベストプラクティス
- MLflow AI GatewayとLlama 2を使用した生成AIアプリの構築(独自データを用いた検索拡張生成(RAG)による精度の向上)
Eブック
デモ
デモのスケジュールや、LLMおよび検索拡張生成(RAG)プロジェクトに関するご相談は、Databricksにお問い合わせください。
エンタープライズ向けエージェントAIプレイブック

RAGテクノロジーの未来
RAGは、単なる応急処置的な回避策から、エンタープライズAIアーキテクチャの基盤コンポーネントへと急速に進化しています。LLMの機能が向上するにつれて、RAGの役割は変化しています。単に知識の隙間を埋めるものから、構造化され、モジュール化された、よりインテリジェントなシステムへと移行しつつあります。
RAGの発展の方向性の1つは、RAGをツール、構造化データベース、ファンクションコーリングエージェントと組み合わせるハイブリッドアーキテクチャです。これらのシステムでは、RAGが非構造化データに基づくグラウンディング(根拠付け)を提供する一方、構造化データやAPIがより正確なタスクを処理します。こうしたマルチモーダルアーキテクチャにより、企業はより信頼性の高いエンドツーエンドの自動化を実現できます。
もう1つの大きな進展は、レトリバーとジェネレーターの共同トレーニングです。これは、RAGのレトリバーとジェネレーターを共同でトレーニングし、お互いの回答品質を最適化するモデルです。これにより、手動でのプロンプトエンジニアリングやファインチューニングの必要性が減り、適応学習、ハルシネーションの抑制、レトリバーとジェネレーターの全体的なパフォーマンス向上などにつながる可能性があります。
LLMアーキテクチャが成熟するにつれて、RAGはよりシームレスでコンテキストに応じたものになるでしょう。有限のメモリや情報の蓄積を超えて、これらの新しいシステムは、リアルタイムのデータフロー、複数ドキュメントにまたがる推論、永続メモリを処理できるようになり、知識豊富で信頼できるアシスタントになります。
よくある質問(FAQ)
検索拡張生成(RAG)とは何ですか?
RAGは、関連するドキュメントを検索してプロンプトに挿入することでLLMを強化するAIアーキテクチャです。これにより、モデルの再トレーニングに時間をかけることなく、より正確で最新の、ドメインに特化した回答が可能になります。
ファインチューニングではなく、RAGを使用すべきなのはどのような場合ですか?
ファインチューニングのコストや複雑さ��を伴わずに、動的なデータを取り入れたい場合はRAGを使用します。正確でタイムリーな情報が必要とされるユースケースに最適です。
RAGはLLMのハルシネーションを抑制しますか?
はい。検索された最新のコンテンツにモデルの回答をグラウンディング(根拠付け)することで、RAGはハルシネーションの可能性を低減します。これは、医療、法務、エンタープライズサポートなど、高い正確性が求められるドメインで特に有効です。
RAGにはどのようなデータが必要ですか?
RAGは、検索可能な形式で保存された非構造化テキストデータ(PDF、電子メール、社内文書など)を使用します。これらは通常、ベクトルデータベースに保存され、関連性を維持するためにインデックスを作成し、定期的に更新する必要があります。
RAGシステムはどのように評価しますか?
RAGシステムは、関連性スコアリング、グラウンディング(根拠性)チェック、人間による評価、およびタスク固有のパフォーマンス指標を組み合わせて評価されます。しかし、これまで見てきたように、レトリバーとジェネレーターの共同トレーニングの可能性により、モデルがお互いから学習し、トレーニングし合うことで、定期的な評価が容易になる可能性があります。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。