Databricks AI Search パブリックプレビューのご紹介
によって アキル・グプタ, セルゲイ・ツァレフ 、 Eric Peter による投稿
昨日発表した RAG(Retrieval Augmented Generation)に続き、本日、Databricks AI Searchのパブリックプレビューを発表します。6月に開催されたData + AI Summitでは、限られたお客様を対象としたプライベートプレビューを発表しましたが、今回はすべてのお客様にご利用いただけるようになりました。Databricks AI Searchは、PDF、Officeドキュメント、Wikiなどの非構造化ドキュメントに対する類似検索を通じて、開発者がRAG(Retrieval Augmented Generation)や生成AIアプリケーションの精度を向上させることを可能にします。AI Search は Databricks Data Intelligence Platform の一部であり、RAG およびジェネレーティブ AI アプリケーションが Lakehouse に保存された独自データを高速かつ安全に使用し、正確なレスポンスを簡単に提供できるようにします。
Databricks AI Search は、高速で安全、かつ使いやすいように設計されています。
- 高速かつ低TCO - AI Searchは、他のプロバイダよりもレイテンシが最大5倍低く、低TCOで高いパフォーマンスを提供するように設計されています。
- シンプルで迅速な開発者エクスペリエンス - AI Searchは、1クリックであらゆるDelta Tableをベクターインデックス��に同期することが可能です。
- 統一されたガバナンス - AI Searchは、データインテリジェンスプラットフォームと同じUnity Catalogベースのセキュリティとデータガバナンスツールを使用します。
- サーバーレススケーリング - AI Searchのサーバーレスインフラストラクチャは、インスタンスやサーバータイプを設定することなく、ワークフローに合わせて自動的にスケールします。
ベクトル検索(AI Search)とは?
ベクトル検索は、情報検索やRAG(Retrieval Augmented Generation)アプリケーションで使用される手法で、クエリとの類似性に基づいて文書やレコードを検索します。ベクター検索は、「金曜日の夜に似合う青い靴」のような平易な言葉のクエリを入力し、関連する結果を返すことができる理由です。
技術大手は、製品体験を強化するために長年ベクトル検索を使用してきました。ジェネレーティブAIの出現により、これらの機能はついにすべての組織に民主化されました。
ベクトル検索の仕組みは以下の通りです:
埋め込み: ベクトル検索では、データとクエリは、生成AIモデルからの埋め込みと呼ばれる多次元空間のベクトルとして表現されます。
ベクトル検索を使って、大規模な単語コーパスから意味的に類似した単語を見つけたいという簡単な例を見てみましょう。コーパスに'dog'という単語をクエリすると、'puppy'のような単語が返されます。しかし、'car'と検索すれば、'van'のような単語を検索したいわけです。従�来の検索では、同義語や「類似語」のリストを管理する必要がありますが、これは生成や拡張が困難です。ベクトル検索を使うためには、代わりに生成AIモデルを使って、これらの単語をエンベッドと呼ばれるn次元空間のベクトルに変換します。これらのベクトルは、「dog」と「puppy」のような意味的に類似した単語は、「dog」と「car」のような単語よりもn次元空間において近いという性質を持ちます。
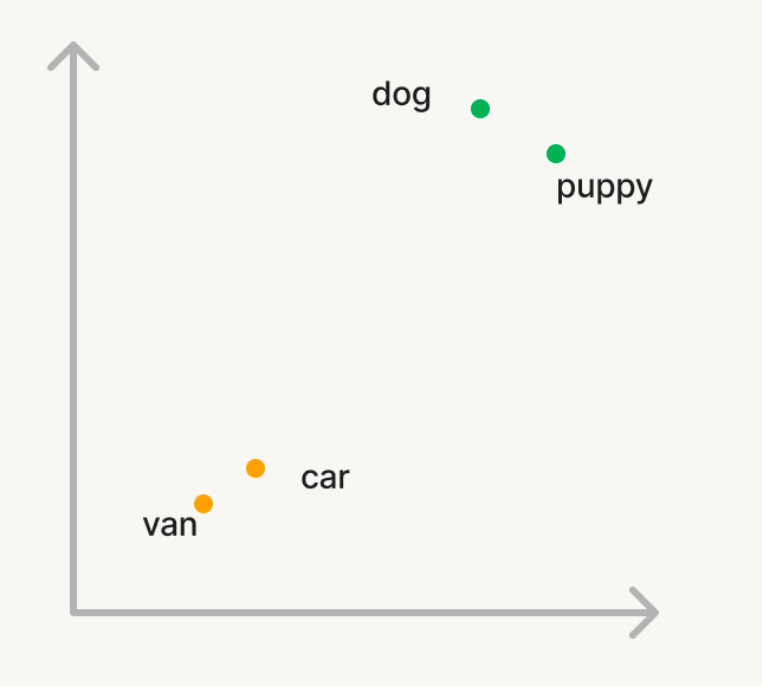
類似度の計算: クエリに関連する文書を見つけるために、クエリベクトルと各文書ベクトル間の類似度を計算し、n次元空間内でどれだけ近いかを測定します。これは通常、2つのベクトル間の角度の余弦を測定するコサイン類似度を使用して行われます。効率的な方法で類似ベクトルを見つけるために使用されるアルゴリズムはいくつかあり、HNSWベースのアルゴリズムは一貫してクラス最高のパフォーマンスです。
アプリケーション: ベクトル検索には多くのユースケースがあります:
- レコメンデーション - パーソナライズされた、コンテキストを意識したレコメンデーションをユーザーに提供します。
- RAG - RAGアプリケーションがユーザーの質問に答えるために、関連する非構造化ドキュメントを提供します。
- セマンティック検索 - プレーン・ランゲージの検索クエリを可能にし、関連性の高い結果を提供します。
- 文書クラスタリング - データ間の類似点と相違点を理解します。
なぜDatabricks AI Searchはお客様に愛されているのでしょうか?
"Databricks の強力なソリューションを活用し、Lippert のカスタマーサポート業務を変革できることを嬉しく思います。私たちのような規模の企業にとって、ダイナミックなコールセンター環境を管理する上では、典型的にオペレーターの入れ替わりが激しい環境の中で、新しいオペレーターを素早く対応させるという大きな課題があります。Databricks は、この問題への解決の糸口を提供してくれます。ーAI Search を利用してオペレーターのアシストを設定することで、オペレーターが顧客からの問い合わせに対する回答を迅速に見つけられるようにするー製品マニュアル、YouTubeビデオ、サポート事例などのコンテンツをAI Searchに取り込むことで、Databricksはオペレーターが必要な知識をすぐに得られるようにしています。この革新的なアプローチはLippert社にとって画期的なもので、効率を高め、カスタマーサポート体験を向上させています。"-Chris Nishnick, Artificial Intelligence, Lippert
自動データ取り込み
ベクターデータベースが情報を格納する前に、データ取り込みパイプラインが必要です。このパイプラインでは、さまざまなソースからの未処理の生データをクリーニングし、処理(解析/チャンク)し、AIモデルを組み込んでから、データベースにベクターとして格納する必要があります。 別のデータ取り込みパイプラインを構築して維持するこのプロセスは、高価で時間がかかり、貴重なエンジニアリングリソースの時間を奪います。 Databricks AI SearchはDatabricks Data Intelligence Platformと完全に統合されており、新たなデータパイプラインを構築・維持することなく、自動的にデータを取り込み、そのデータを埋め込むことができます。
Delta Sync APIは、ソースデータとベクターインデックスを自動的に同期します。ソースデータが追加、更新、削除されると、対応するベクターインデックスが自動的に更新されます。AI Searchは、失敗を管理し、再試行を処理し、バッチサイズを最適化します。 これらの最適化により、エンベッディング・モデル・エンドポイントの利用率が向上するため、総所有コストが削減されます。
簡単な3ステップでベクトルインデックスを作成する例を見てみましょう。全てのAI Search機能は、REST API、Python SDK、またはDatabricks UIから利用可能です。
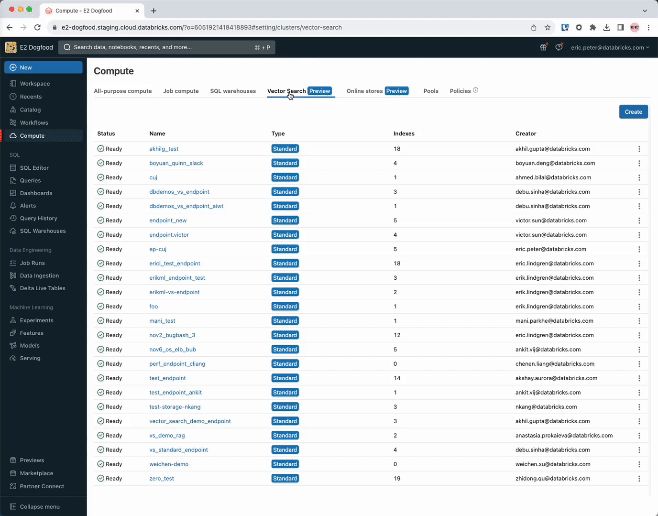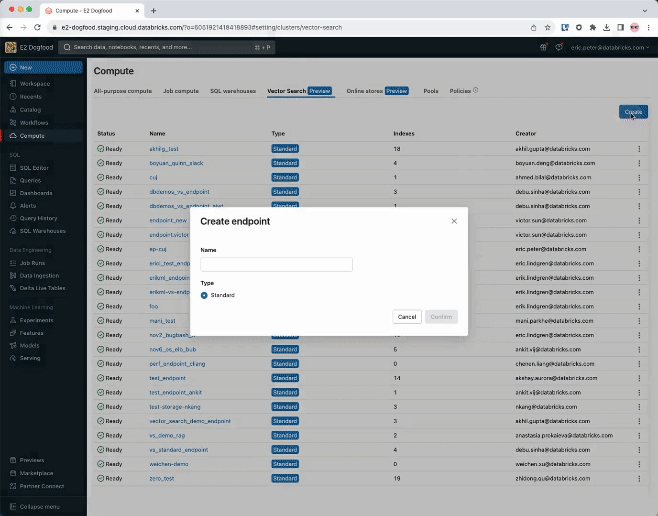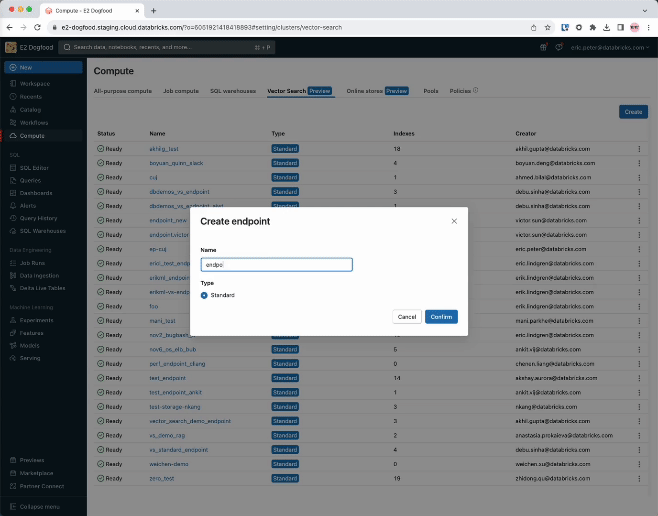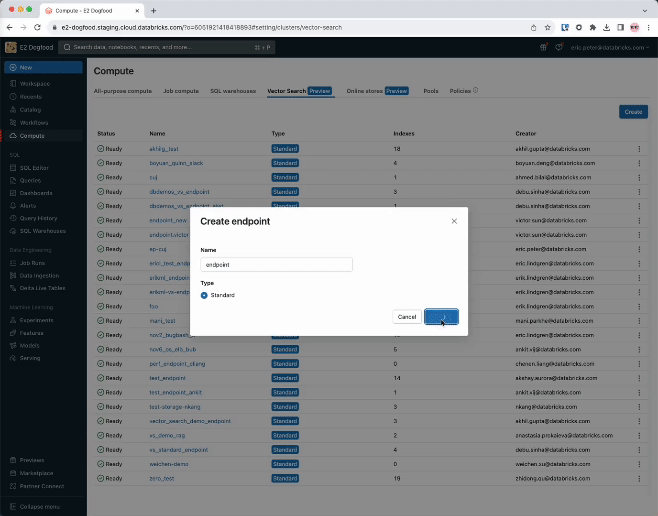
ステップ 1. UI または REST API/SDK を使用して、ベクトル・インデックスの作成とクエリに使用するベクトル検索エンドポイントを作成します。
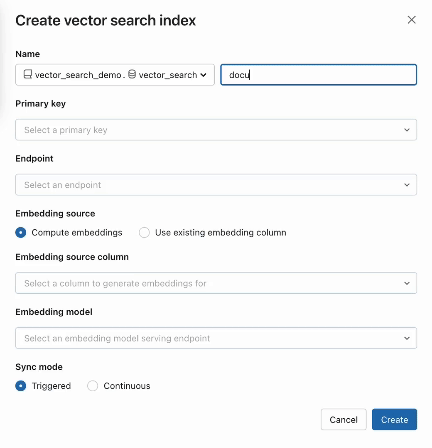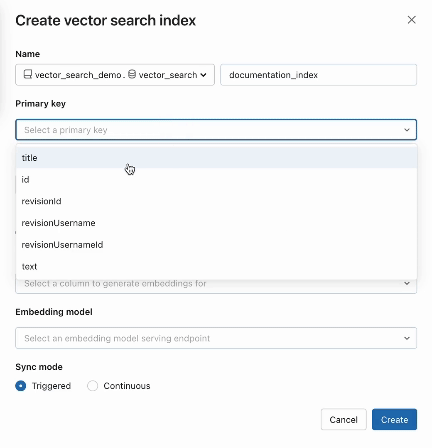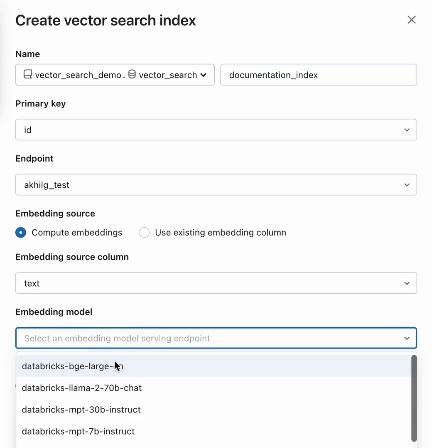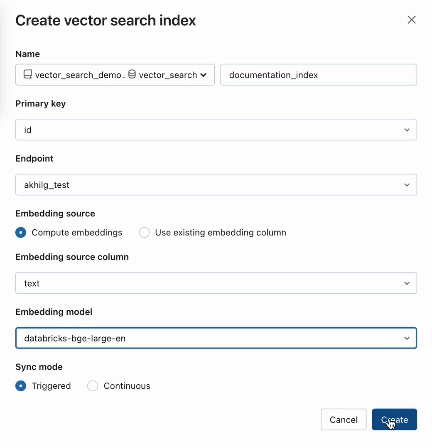
ステップ2. ソースデータでデルタテーブルを作成した後、埋め込むデルタテーブルのカラムを選択し、データの埋め込みを生成するために使用されるModel Servingエンドポイントを選択します。
埋め込みモ�デルには、以下のようなものがあります:
- ファインチューニングしたモデル
- 既製のオープンソースモデル(E5、BGE、InstructorXLなど)
- API経由で利用可能な独自の埋め込みモデル(OpenAI、Cohere、Anthropicなど)
AI Searchは、Delta Tableでエンベッディングを管理したり、REST APIを使用してデータ取り込みパイプラインを作成したいお客様のために、高度なモードも提供しています。 例については、AI Searchのドキュメントをご覧ください。
ステップ3. インデックスの準備ができたら、クエリを作成して、クエリに関連するベクトルを見つけることができます。これらの結果は、RAG(Retrieval Augmented Generation)アプリケーションに送信できます。
"この製品は使いやすく、数時間で稼働させることができました。全てのデータは既にDeltaにあるので、AI Searchとdelta syncの統合された管理エクスペリエンスは素晴らしいです。"—- Alex Dalla Piazza (EQT Corporation)“
一元化されたガバナンス
企業組織は、ユーザーがGenerative AIモデルを使用して、アクセスすべきでない機密データを提供できないように、データに対する厳格なセキュリティとアクセス制御を必要とします。しかし、現在のVectorデータベースは、強固なセキュリティとアクセス制御を備えていないか、データ・プラットフォームとは別のセキュリティ・ポリシーを構築して維持する必要があります。複数のセキュリティとガバナンスのセットを持つことは、コストと複雑さを増し、確実に維持するためにエラーが発生しやすくなります。
Databricks AI Searchは、Unity Catalogとの統合によって可能になったData Intelligence Platformの残りの部分を保護するのと同じセキュリティ制御とデータガバナンスを活用します。ベクターインデックスは、Unityカタログ内のエンティティとして保存され、同じ統一インターフェースを活用してデータに対するポリシーを定義し、エンベッディングをきめ細かく制御します。
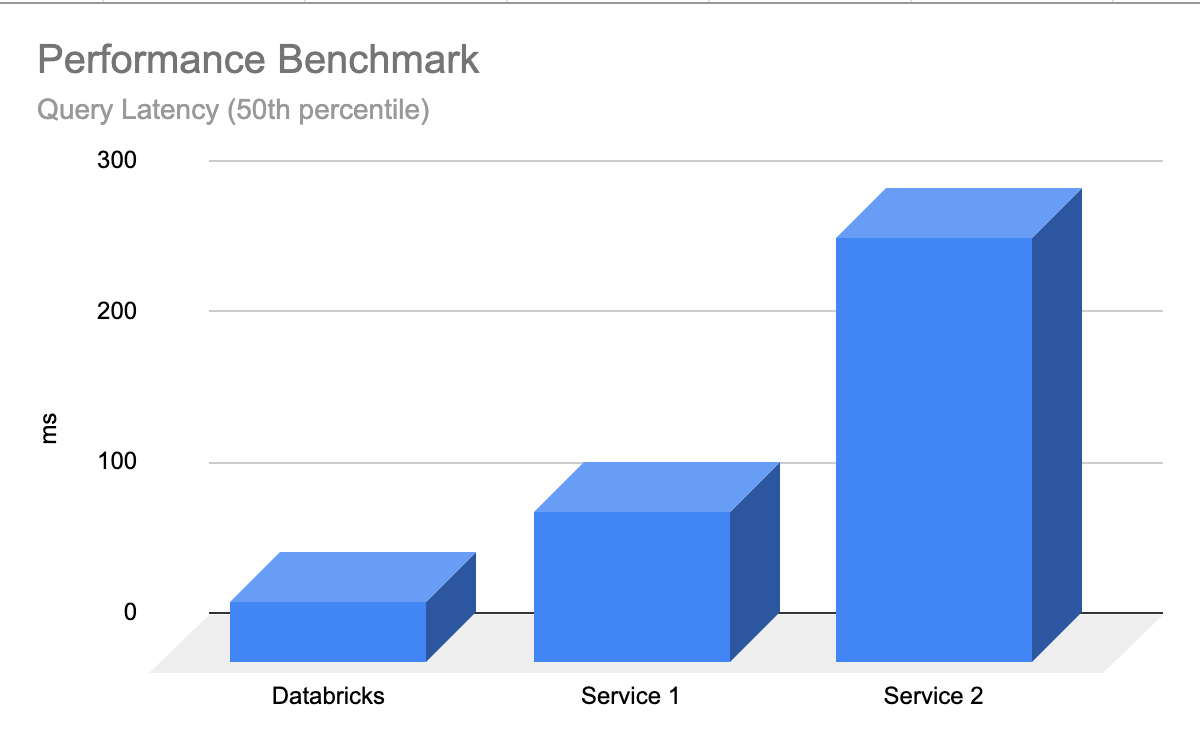
高速クエリ・パフォーマンス
市場が成熟しているため、多くのベクターデータベースは少量のデータによる概念実証(POC)では良い結果を示しています。しかし、本番環境で使用するには、パフォーマンスやスケーラビリティが不十分なことがよくあります。すぐに使えるパフォーマンスが低いため、ユーザーは検索インデックス�のチューニングや拡張方法を考えなければなりません。ワークロードを理解し、どのようなコンピュートインスタンスを選択し、どのような構成を使用するかについて難しい選択を迫られます。
Databricks AI Searchは、LLMが最小限のレイテンシで適切な結果を迅速に返すので、データベースのチューニングやスケーリングに必要な作業はゼロです。AI Searchは、フィルタリングの有無にかかわらず、クエリが非常に高速になるように設計されています。他の主要なベクトルデータベースと比較して、最大5倍のパフォーマンスを発揮します。 設定も簡単で、想定されるワークロードのサイズ(例:1秒あたりのクエリ数)、必要なレイテンシ、想定されるエンベッディングの数をお知らせいただくだけで、あとは私たちにお任せください。 インスタンスタイプ、RAM/CPU、ベクターデータベースの内部構造を理解する必要はありません。
何千ものお客様がすでにDatabricks上で実行しているAIワークロードをサポートするために、私たちはDatabricks AI Searchのカスタマイズに多くの労力を費やしました。この最適化には、セマンティック検索に最適なハードウェアをベンチマークして特定すること、基礎となる検索アルゴリズムとネットワークオーバーヘッドを最適化すること、スケールで最高のパフォーマンスを提供することなどが含まれます。
次のステップ
私たちのドキュメントを読み、具体的にAI Searchインデックスを作成することから始めましょう。
AI Searchの価格についてもっと読む
独自のRAGアプリケーションのデプロイを開始する(デモ)
Databricks Generative AIWebセミナーに申し込む
今週初めに発表された概要を 読む
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。