Databricks Model Servingを使用したプライベートLLMのデプロイ
によって アーメッド・ビラル, Ankit Mathur, Kasey Uhlenhuth 、 Joshua Hartman による投稿
翻訳:Saki Kitaoka. - Original Blog Link
Databricks Model ServingのGPUおよびLLM最適化サポートのパブリックプレビューを発表できることを嬉しく思います!この発表により、LLMやVisionモデルを含む、あらゆるタイプのオープンソースまたは独自のカスタムAIモデルをLakehouseプラットフォーム上にデプロイできるようになります。Databricks Model Servingは、LLM Serving用にモデルを自動的に最適化し、設定なしでクラス最高のパフォーマンスを提供します。
Databricks Model Servingは、統合データおよびAIプラットフォーム上で開発された初のサーバーレスGPUサービング製品です。これにより、データの取り込みから微調整、モデルのデプロイ、モニタリングに至るまで、GenAIアプリケーションの構築とデプロイをすべて単一のプラットフォーム上で行うことができます。
Azure上のユーザーは、Model ServingのGPUおよびLLM最適化サポートを有効にするために、サインアップフォームに記入する必要があります。
Databricks Model ServingによるジェネレーティブAIアプリケーションの構築
"Databricks Model Servingを利用することで、ジェネレーティブAIを当社のプロセスに統合し、カスタマーエクスペリエンスを向上させ、業務効率を高めることができます。Model Servingのおかげで、データとモデルを完全にコントロールしながらLLMモデルを展開することができます" - easyJet、データサイエンス&アナリティクス担当ディレクター、ベン・ディアス氏 - Learn more
インフラ管理を心配することなくAIモデルを安全にホスト
Databricks Model Servingは、複雑なインフラストラクチャを理解する必要なく、あらゆるAIモデルをデプロイするための単一のソリューションを提供します。つまり、自然言語モデル、視覚モデル、音声モデル、表形式モデル、カスタムモデルなど、どのように学習させたかに関係なく、ゼロから構築したものでも、オープンソースから調達したものでも、独自のデータで微調整したものでも、あらゆるモデルをデプロイできます。MLflowでモデルを記録するだけで、CUDAのようなGPUライブラリを備えたプロダクションレディのコンテナを自動的に準備し、サーバーレスGPUにデプロイします。MLflowのフルマネージドサービスは、インスタンスの管理、バージョンの互換性の維持、パッチの適用といった面倒な作業をすべて代行します。このサービスは、トラフィックパターンに合わせてインスタンスを自動的にスケールし、レイテンシパフォーマンスを最適化しながらインフラコストを節約します。
"Databricks Model Servingは、有意義なセマンティック検索アプリケーションからメディアトレンドの予測まで、多様なユースケースにインテリジェンスを注入する当社の能力を加速しています。CUDAとGPUサーバーのスケーリングの複雑な仕組みを抽象化し簡素化することで、Databricksは私たちの本当の専門分野、つまりインフラの手間や負担をかけずにコンデナストのすべてのアプリケーションでAIを活用することに集中できるようになりました" - Condé Nast社シニアMLエンジニア、ベン・ホール氏
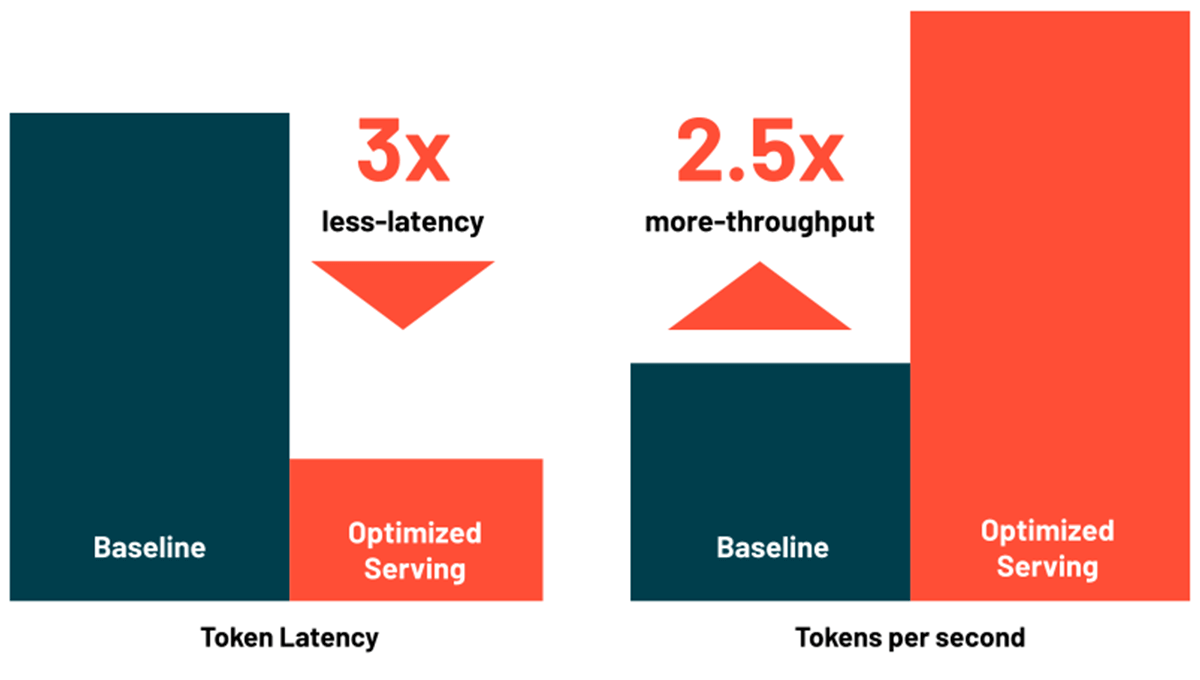
最適化されたLLMサービングでレイテンシーとコストを削減
Databricks Model Servingには、大規模な言語モデルを効率的に提供するための最適化が含まれており、レイテンシーとコストを最大3~5倍削減します。最適化されたLLM Servingの使用は非常に簡単です。モデルをOSSまたは微調整された重みとともに提供するだけで、あとはDatabricksがモデルを最適化されたパフォーマンスで提供します。これにより、お客様はモデル最適化のための低レベルライブラリを書く代わりに、LLMをアプリケーションに統合することに集中することができます。Databricks Model Servingは、MPTとLlama2クラスのモデルを自動的に最適化します。
Lakehouse AIインテグレーションでデプロイを加速
LLMをプロダクション化する場合、単にモデルをデプロイするだけではありません。検索拡張世代(RAG)、パラメータ効率的ファインチューニング(PEFT)、標準ファインチューニングなどのテクニックを使ってモデルを補完する必要もあります。さらに、LLMの品質を評価し、モデルの性能と安全性を継続的に監視する必要があります。その結果、チームは異種のツールの統合に多大な時間を費やすことになり、運用の複雑性が増し、メンテナンスのオーバーヘッドが発生します。
Databricks Model Servingは、統一されたデータおよびAIプラットフォーム上に構築されているため、データの取り込みから微調整、デプロイメント、モニタリングに至るまで、LLMOps全体を単一のプラットフォーム上で管理できます。Model Servingは、Lakehouse内のさまざまなLLMサービスと統合されています:
- Fine-tuning: Lakehouse上でお客様独自のデータを使って基礎モデルを直接微調整することにより、精度と差別化を向上させます。
- ベクトル検索のインテグレーション: 検索拡張世代とセマンティック検索のユースケースのためにベクトル検索を統合し、シームレスに実行します。プレビューのお申し込みはこちらから。
- 組み込みのLLM管理: Databricks AI Gatewayと統合され、すべてのLLMコールの中央APIレイヤーとして使用できます。
- MLflow: MLflowのPromptLabを介してLLMを評価、比較、管理します。
- 品質と診断: リクエストとレスポンスを Delta テーブルに自動的に取り込み、モデルを監視およびデバッグします。さらにLabelboxとのパートナーシップにより、このデータをラベルと組み合わせてトレーニングデータセットを生成できます。
- 統一されたガバナンス: Unity Catalogで、Model Servingで消費および生成されたものを含む、すべてのデータとAIアセットを管理およびガバナンスできます。
LLMサービングに信頼性とセキュリティを導入
Databricks Model Servingは、データ、モデル、およびデプロイメント構成を完全に制御しながら、スケールの大きな推論を可能にする専用コンピュートリソースを提供します。選択したクラウド領域で専用の容量を確保することで、低オーバーヘッドのレイテンシー、予測可能なパフォーマンス、SLAに裏付けされた保証が得られます。さらに、お客様のワークロードは多層的なセキュリティによって保護され、最も機密性の高いタスクでも安全で信頼性の高い環境を確保します。また、規制の厳しい業界特��有のコンプライアンス・ニーズに対応するため、複数の管理体制を導入しています。詳細については、このページをご覧になるか、Databricksのアカウントチームまでお問い合わせください。
GPUとLLMのサービングを始めましょう
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。