
エージェントの乱立を管理。自信を持ってエージェントを構築。
エンタープライズAIエージェントの開発、管理、ガバナンスを統合します。あなたのデータを理解するエージェント
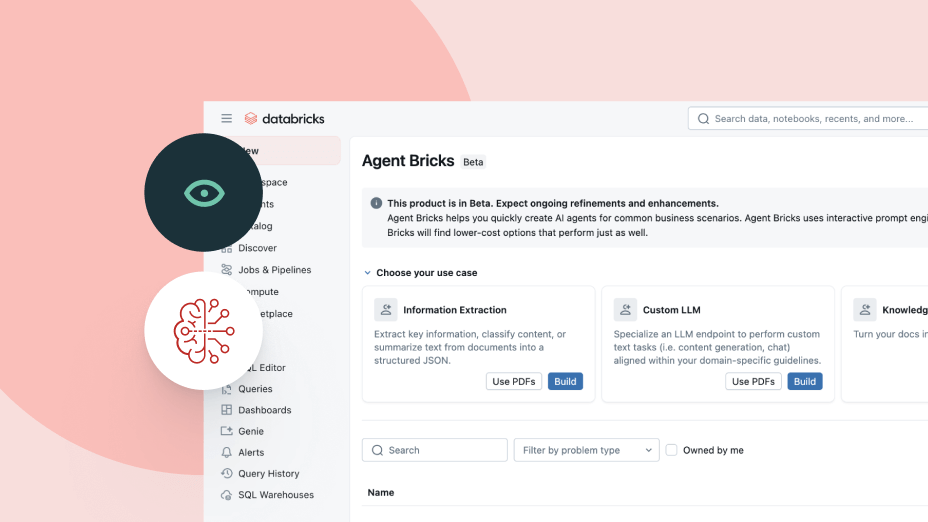
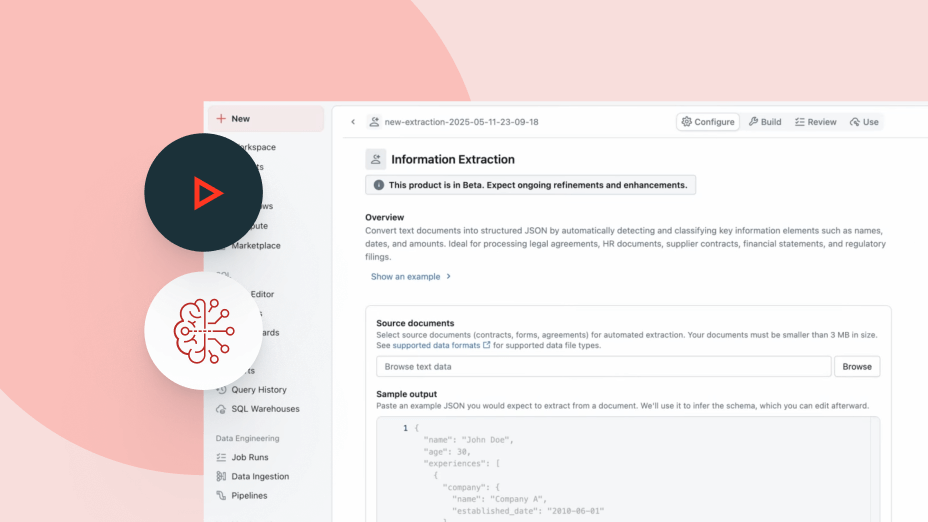
Agent Bricksは、スキーマ、ビジネス定義、カスタムセマンティクスといったエンタープライズコンテキストを利用して、使用するツールやテーブル、データの正しい結合方法、そして正確で一貫性のある回答の生成方法について、よりスマートな意思決定を行います。
オープン&マルチAI
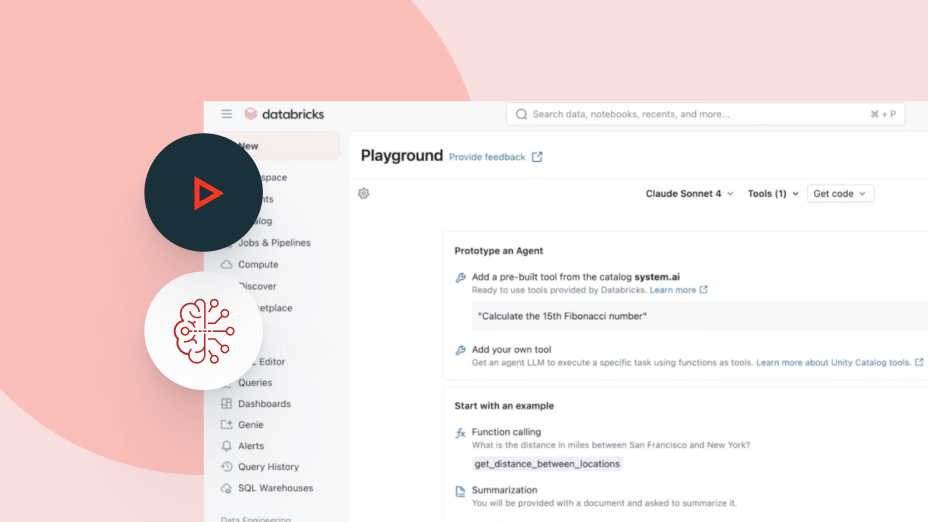
OpenAI、Anthropic、Googleからオープンソースまで、あらゆる主要なAIモデルに単一のプラットフォームを通じてアクセスできます。Agent Bricksを使用すると、スタックを再設計することなく、モデルを即座に切り替えてコスト、品質、パフォーマンスを最適化できます。
ガバナンスを統合
Databricksだけが、データからAIモデルまでのフルスタックを単一の記録システムで管理します。明確な所有権とエンドツーエンドの権限ですべてのエージェント、MCPサーバー、モデル、ツールを追跡し、エージェントが許可された範囲を超えてアクセスできないようにします。

トップチームはAGENT BRICKSで成功を収めています
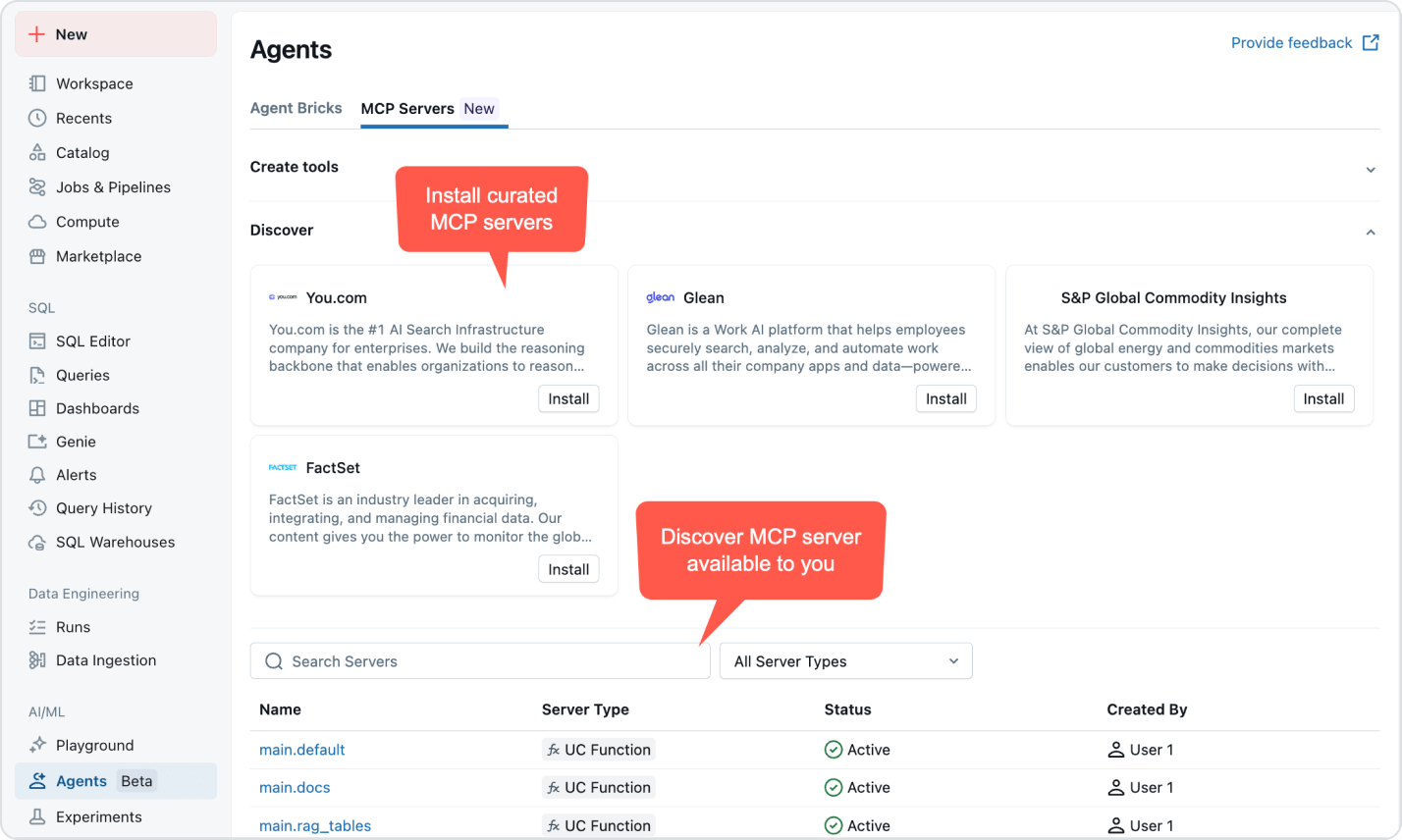
エージェントの構築、統制、拡��張に必要なすべて
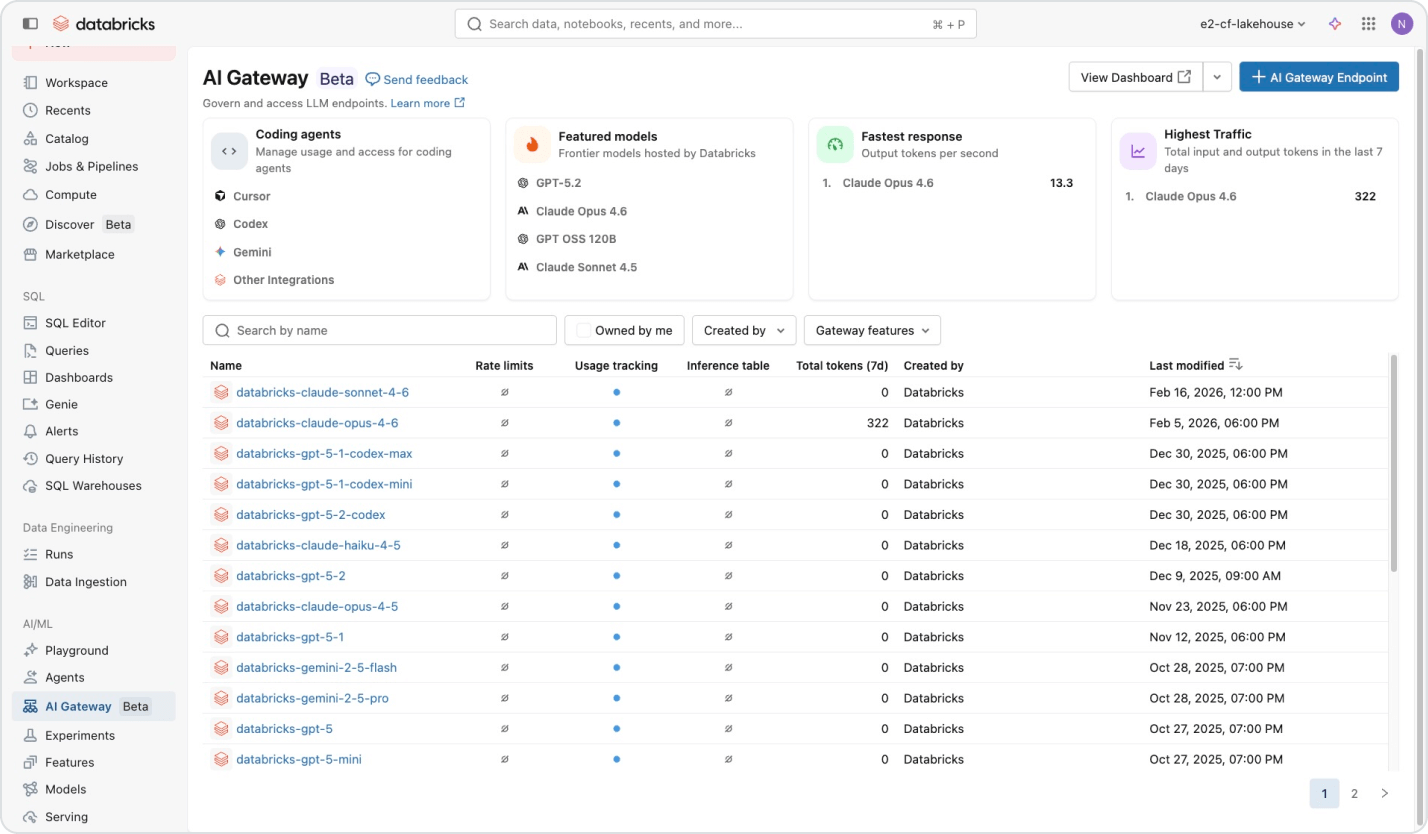
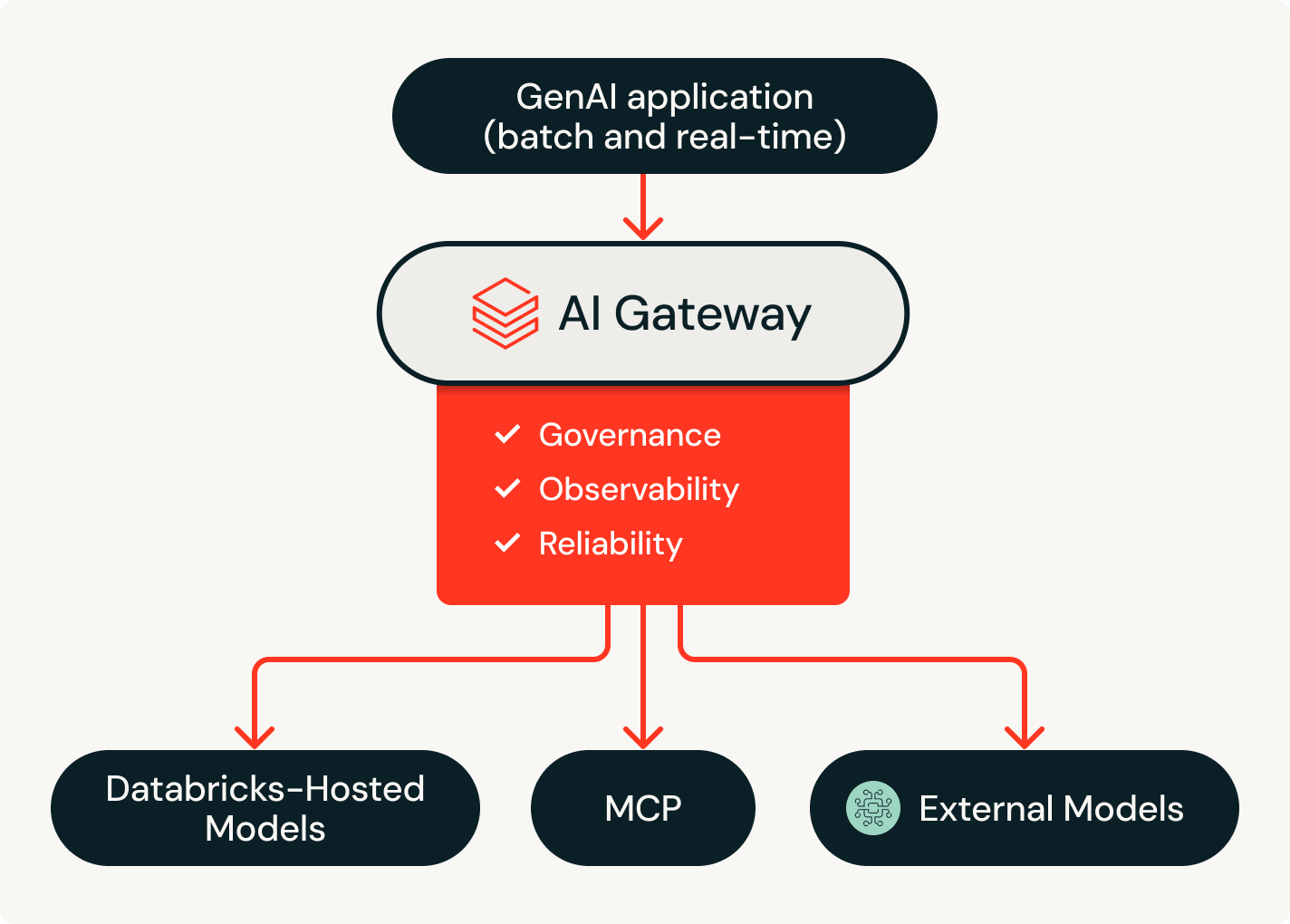
単一の契約で、ロックインされることなく、あらゆるモデルにアクセス
単一のプラットフォームから、OpenAI、Anthropic、Google、Meta などの AI モデルにアクセスできます。インテリジェントなルーティングと自動fallbackに��より、プロバイダーがダウンした場合でもエージェントは稼働し続けます。Unity Catalog は、ユーザーまたはチームごとにきめ細かい権限とレート制限を適用するため、コントロールを失うことなくモデルへのアクセスを拡張できます。
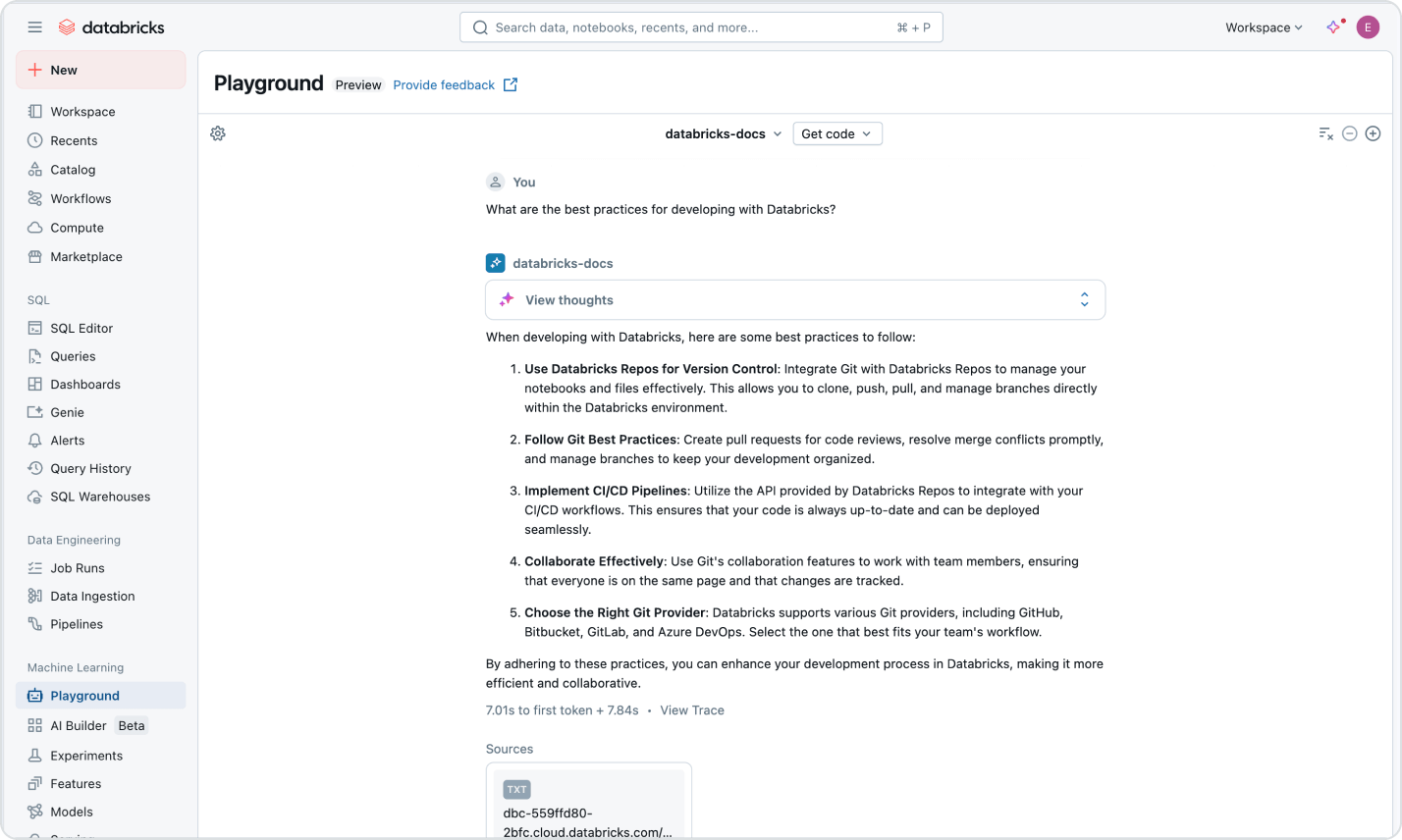



使用量に応じた価格設定で、支出を抑制
使用した製品に対する秒単位での課金となります。さらに詳しく
Databricksデータインテリジェンスプラットフォームが、お客様のチームのあらゆるデータおよびAIワークロードをどのように強化するか、詳細をご覧ください。
Genie
自然言語で質問するだけで、データから知見を取得できます。

Databricks Apps
カスタムエージェントを、Databricks上で安全なユーザー向けAIアプリケーションに変換します。Serverlessインフラストラクチャと組み込みのスケーリング機能により、ガバナンスの効いたデータとモデル上で完全なエクスペリエンスを構築できます。

モデルの提供
組み込みのオブザーバビリティ、スケール、エンタープライズコントロールにより、本番運用であらゆるAIモデルやエージェントのデプロイとガバナンスを実現します。

ベクトル検索
ソースデータを継続的に同期する高性能ベクトルデータベースで、リアルタイムAIアプリケーションを強化します。

Unity Catalog
Unity Catalog を利用することで、構造化データ/非構造化データ/ML モデル/ノートブック/ダッシュボード/ファイルを主要なクラウドやプラットフォームでシー��ムレスに管理できます。

人工知能(AI)
エンドツーエンドのAIエージェントシステムのための、Databricks AIツールの全スイートをご覧ください。

Databricks データ・インテリジェンス・プラットフォーム
Databricksで利用可能なすべてのツールを探索し、組織全体でデータとAIをシームレスに統合しましょう。



