Apache Spark と Photon が SIGMOD アワードを受賞
によって Reynold Xin(レイノルド・シン) 、 Matei Zaharia による投稿
今週、データマネジメントコミュニティで最も影響力のあるエンジニアや研究者の多くが、2年間のバーチャル会議を経て、フィラデルフィアで開催されるACM SIGMODカンファレンスに直接集まっています。このイベントの一環として、以下の2つの賞が授与されたことを大変嬉しく思います。
- Apache SparkがSIGMOD Systems Awardを受賞しました
- Databricks Photonは最優秀インダストリーペーパー賞を受賞しました。
この機会に、これまでの背景とここに至った経緯についてご説明したいと思います。
ACM SIGMODとは何ですか?また、どのような賞がありますか?
ACM SIGMODは、Association of Computing Machinery’s Special Interest Group in the Management of Data(計算機学会のデータ管理に関する特別研究グループ)の略です。ええ、長い名前です。誰もが単にSIGMODと呼んでいます。カラムストアからクエリー最適化に至るまで、データベース分野で最も独創的なアイデアの多くがこの場で発表されてきたため、データベースの研究者やエンジニアにとって最も権威のあるカンファレンスです。
「SIGMODシステム賞」は、「その技術的貢献が大規模データマネジメントシステムの理論または実践に大きな影響を与えたシステム」1つに毎年授与されます。これらのシステムは、大規模な実世界のアプリケーションを持つだけでなく、将来のデータベースシステムの設計方法にも影響を与える傾向があります。過去の受賞者には、Postgres、SQLite、BerkeleyDB、Aurora などが含まれます。
最優秀業界論文賞は、実世界への影響、革新性、プレゼンテーションの質を組み合わせて、毎年1つの論文に授与されます。
Apache SparkのデータとAIの起源
10年ほど前、NetflixはNetflix Prizeというコンペティションを開始しました。その中で、同社は膨大なユーザーの映画評価データを匿名化し、ユーザーが映画をどのように評価するかを予測するアルゴリズムを考案するよう参加者に求めました。最高の機械学習モデルを構築したチームに、100万米ドルの賞金が授与されます。
UCバークレー校の博士課程の学生グループが、コンペに参加することを決めました。彼らが最初に直面した課題は、ツーリングが単純に十分ではなかったことでした。より良いモデルを構築するために、彼らは(学生のラップトップには収まらない)大量のデータをクリーンアップ、分析、処理するための高速で反復的な方法と、実験的な機械学習アルゴリズムを構成するのに十分な表現力を持つフレームワークを必要としていました。
エンタープライズデータの標準であったデータウェアハウスは、非構造化データを扱うことができず、表現力にも欠けていました。彼らはこの課題について、博士課程の学生であったMatei Zaharia氏と議論しました。彼らは共同で、RDDと呼ばれる革新的な分散データ構造を持つ、Sparkという新しい並列コンピューティングフレームワークを設計しました。Sparkを使用することで、ユーザーはデータ並列処理を迅速かつ簡潔に実行できるようになりました。
言い換えれば、コードを速く書けて、ランも速いということです。速く書けることが重要なのは、プログラムがより理解しやすくなり、より複雑なアルゴリズムを簡単に構成できるようになるからです。ランが速いということは、ユーザーがより速くフィードバックを得られ、増え続けるデータを使ってモデルを構築できることを意味します。

学生たちだけではなかったことが判明しました。当時は、業界におけるデータとAIアプリケーションの黎明期であり、誰もが同様の課題に直��面していました。多くの要望に応え、プロジェクトはApacheソフトウェア財団に移管され、巨大なコミュニティへと成長しました。
今日、Sparkはデータ処理におけるデファクトスタンダードであり、その利用は拡大し続けています:
- 先月、PyPIとMaven Centralだけで4500万回ダウンロードされました。これは、ダウンロード数が前年比90%増であることを示しています。
- 少なくとも204の国と地域で利用されています。
- Stack Overflow の 2021 年開発者アンケートでは、最も高収入なテクノロジーとして第 1 位にランクインしています。
SIGMOD Systems Awardは、このプロジェクトが広く採用されたこと、そして、データとAIを統合パッケージとして捉えるという考え方を将来のシステム世代に与えた影響力を証明するものです。
Photon: 新しいワークロードとレイクハウス
Apache Sparkの人気が高まるにつれ、組織は大規模なデータ処理や機械学習だけでなく、さらに多くのことを望んでいることがわかりました。つまり、ビジネスの他の場面で使用しているのと同じデータセット上で、従来のインタラクティブなデータウェアハウジングアプリケーションを実行するし、複数のデータシステムを管理する必要をなくしたいと考えていたのです。これが、データウェアハウスとデータレイクシステムの利点を組み合わせ、大規模な処理とインタラクティブなSQLクエリーの両方を実行できる単一のデータストアであるレイクハウスシステムのコンセプトにつながりました。
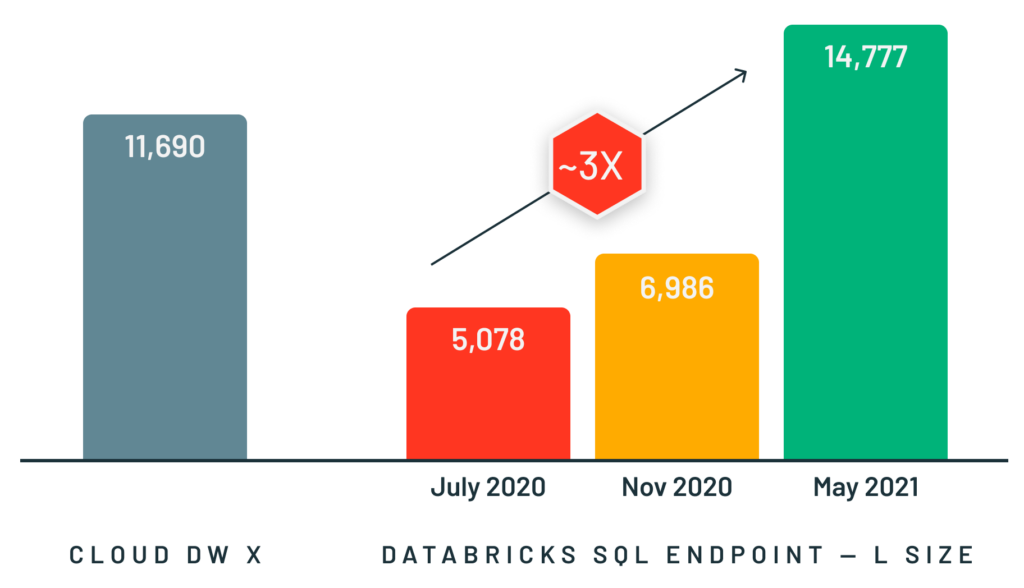
このようなユースケースをサポートするために、当社は Spark の既存のプログラミング インターフェースの背後で動作する、Spark および SQL ワークロード向けの高速な C++ ベクトル化実行エンジンである Photon を開発しました。Photonは、SQL、Python、Javaアプリケーションを含むSparkと同じAPIとワークロードをサポートしながら、Sparkよりもはるかに高速なインタラクティブクエリーと高い同時実行性を実現します。Photon を使用することで、昨年の大規模な TPC-DS データウェアハウス ベンチマークでの世界記録樹立から、小規模な同時実行クエリーでの 3 倍のパフォーマンス向上に至るまで、あらゆる規模のワークロードで大きな成果を上げています。
Photonの設計と実装は困難なものでした。そのエンジンは、(幅広いアプリケーションをサポートするために)Sparkの表現力と柔軟性を維持し、(パフォーマンスの低下を避けるために)決して速度を低下させず、ターゲットとするワークロードでは大幅に高速化する必要があったためです。さらに、すべてのデータが独自の形式でロード済みであることを前提とする従来のデータウェアハウスエンジンとは異なり、Photonはlakehouse環境で動作し、(インデックスやデータ統計の可用性など)取り込みプロセスに関する前提を最小限に抑えながら、Delta LakeやApache Parquetなどのオープンフォーマットのデータを処理する必要がありました。当社の SIGMOD 論文では、当社がこれらの課題にどのように取り組んだか、また Photon の実装に関する多くの技術的詳細について説明しています。
この研究が最優秀業界論文として認められたことを大変嬉しく思うとともに、このレイクハウスシステムという新しいモデルにおける課題について、データベースエンジニアや研究者の皆様に良いアイデアを提供できればと願っています。もちろん、これまで顧客がPhotonで成し遂げたことにも大変興奮しています — この新しいエンジンは、すでに当社のワークロードの大きな割合を占めるまでに成長しています。
SIGMODにご参加の方は、Databricksのブースにお立ち寄りいただき、ぜひお声がけください。データシステムの未来について、ぜひ一緒に語り合いましょう。お返しに、「最高のデータウェアハウスはlakehouseである」と書かれたTシャツをプレゼントします!

最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。