Databricks が DWH パフォーマンスの公式記録を更新
によって Reynold Xin(レイノルド・シン) 、 モスタファ・モクタル による投稿
Databricks は本日、「Databricks SQL」がデータウェアハウス(DWH)のベンチマークである TPC-DS の 100TB クラスで世界記録を更新したことを発表しました。Databricks SQL は、これまでの世界記録の 2.2 倍のパフォーマンスを達成。他の多くのベンチマーク達成ニュースとは異なり、この記録は TPC 評議会によって正式に認められています。
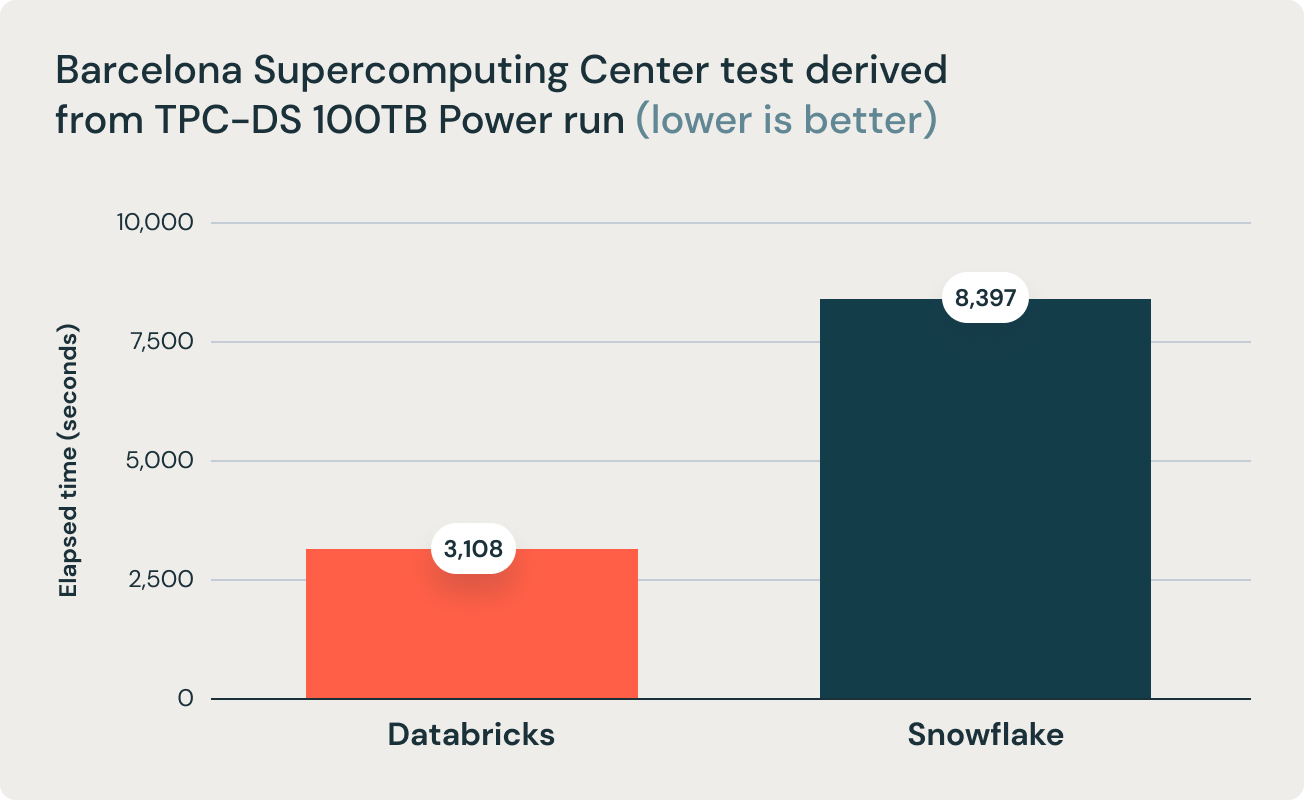
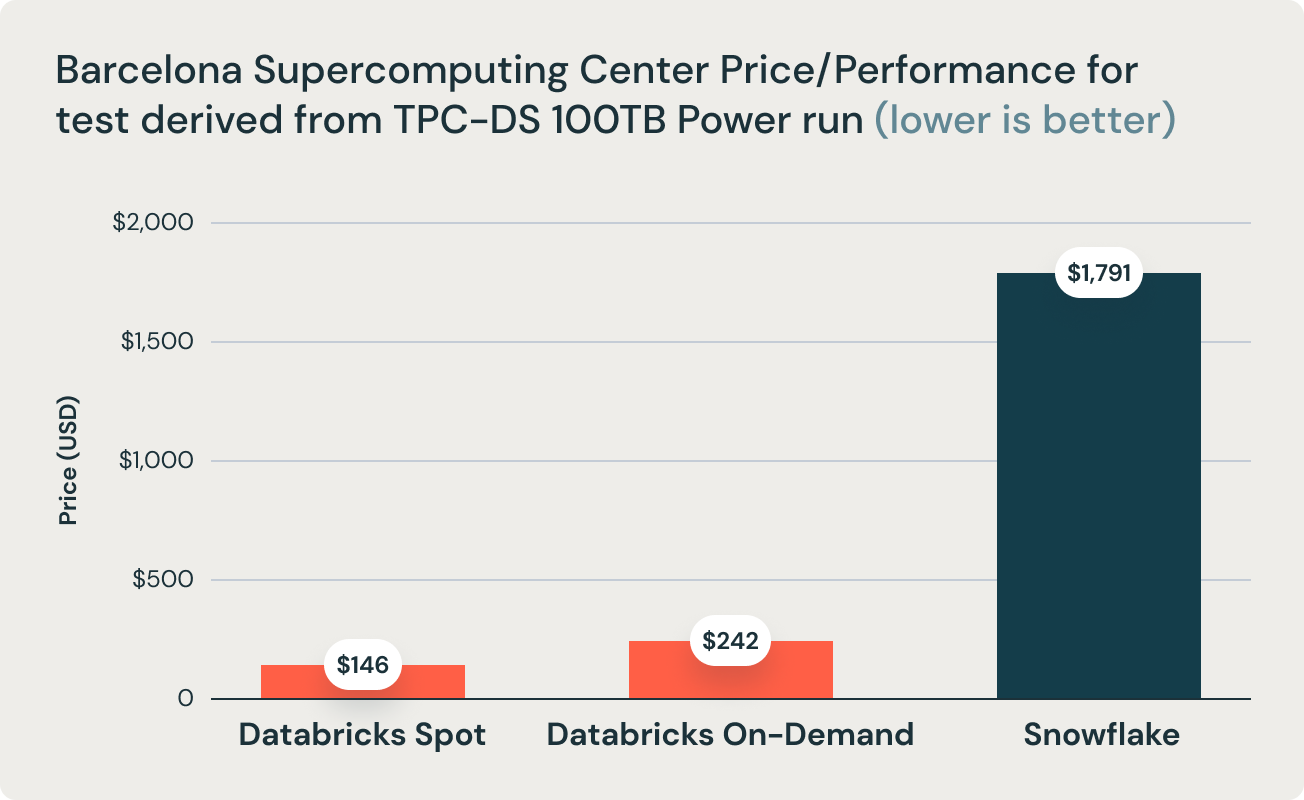
These results were corroborated by research from Barcelona Supercomputing Center, which frequently runs benchmarks that are derivative of TPC-DS on popular data warehouses. Their latest research benchmarked Databricks and Snowflake, and found that Databricks was 2.7x faster and 12x better in terms of price performance. This result validated the thesis that data warehouses such as Snowflake become prohibitively expensive as data size increases in production.
Databricks では、データレイクの上に本格的なデータウェアハウスのケイパビリティを直接実装する単一のアーキテクチャを急速に開発しました。データレイクハウスと呼ばれるこのアーキテクチャは、データウェアハウス、データレイク両方の優れた長所を提供します。2020 年 11 月に Databricks SQL をデータウェアハウスのケイパビリティのフルスイートとして発表して以来、レイクハウスを基盤にしたオープンなアーキテクチャが従来のデータウェアハウスのパフォーマンス、速度、コストを提供できるかどうかの疑問は未解決でした。しかし、今回の結果により、レイクハウスのアーキテクチャでそれが実現可能であることが証明されたことになります。
このブログ記事では、記録達成の結果報告に加え、私たちがどのようにしてこのレベルのパフォーマンスを達成したか、また、そのために注力してきた取り組みについてもご紹介します。
TPC-DS の世界記録
Databricks SQL は、32,941,245 QphDS @ 100TB を達成しました。これは、Alibaba のカスタム構築のシステムが出した前回の世界記録 14,861,137 QphDS @ 100TB の 2.2 倍のパフォーマンスです。(Alibaba には、世界最大の e コマースプラットフォームを支える優れたシステムがありました)Databricks SQL は、これまでの記録を大幅に更新したのみならず、ディスカウントなしの公示価格に基づいて比較した場合、システムの総コストの 10% 削減も同時に達成しています。
QphDS という単位だけでは何を意味するのかわかりにくいかもしれません(私たちも数式を見ないと何のことかわかりません)。QphDS は、TPC-DS の主要指標であり、(1) データセットのロード、 (2) 一連のクエリの処理(パワーテスト)、(3) 複数の同時実行のクエリストリームの処理(スループットテスト)、(4) データの挿入/削除を行うデータメンテナンス機能の実行、を含むワークロードの組み合わせによるパフォーマンスを表します。
The aforementioned conclusion is further supported by the research team at Barcelona Supercomputing Center (BSC) that recently ran a different benchmark derived from TPC-DS comparing Databricks SQL and Snowflake, and found that Databricks SQL was 2.7x faster than a similarly sized Snowflake setup.
TPC-DS とは
TPC-DS は、トランザクション処理性能評議会(TPC)によって定義されるデータウェアハウスのベンチマークです。TPC は、1980 年代後半にデータベースコミュニティによって設立された非営利団体で、リアルワールドのシナリオを模倣したベンチマークの作成に注力しています。そのため、TPC は、データベースシステムの性能を客観的に測定する目的で使用されています。また、TPC はデータベースの領域にも大きな影響を与え、Oracle、Microsoft、IBM などの確立されたベンダーによる 10 年に及ぶ「ベンチマーク戦争」が、この領域の発展を推進してきました。
TPC-DS の “DS” は、意思決定支援(Decision Support)を意味します。極めてシンプルな集計から複雑なパターンマイニングまで、さまざまな複雑さを持つ 99 のクエリが含まれています。これは、複雑さが増す分析を反映した 2000 年代半ばからスタートした比較的新たな取り組みのベンチマークです。TPC-DS は、この 10 年間でデータウェアハウスのベンチマークの事実上の標準となり、ほぼ全てのベンダーで採用されています。
しかし、その複雑さから、多くのデータウェアハウスシステムは(たとえ老舗ベンダーが構築したものでも)、自社のシステムが優れた性能を示すように公式のベンチマークが調整されてきました。(一般的な調整として、ロールアップなどの特定の SQL 機能の削除や、データ分散の変更による歪みの除去などがあります。)TPC-DS に関するインターネットのページは 400 万件以上もあるにもかかわらず、公式な TPC-DS ベンチマークの件数が少ないのはこのためです。また、これが、多くのベンダーが独自のベンチマークを使用して調整し、自社の製品を他社の製品より優れているように見せる「からくり」です。
どのように達成したか
前述したとおり、Databricks SQL がデータウェアハウスの SQL パフォーマンスを上回る可能性があるかどうかの疑問は未解決でした。その疑問の理由は、次の 4 点に��まとめることができます。
- データウェアハウスは、独自のデータフォーマットを活用しているため、迅速に進化させることができます。一方で、レイクハウスをベースにした Databricks は、Apache Parquet や Delta Lake などのオープンフォーマットに依存しているため、迅速な変更ができません。結果的に、エンタープライズデータウェアハウス(EDW)には、固有のメリットがあることになります。
- 優れた SQL パフォーマンスには、MPP(大規模並列処理)アーキテクチャが必要です。Databricks と Apache Spark は、MPP ではありません。
- 従来のスループットとレイテンシのトレードオフは、システムがスループット重視の大規模なクエリ、またはレイテンシ重視の小規模なクエリのいずれかに対して優れていることを意味しており、両方を実現していません。Databricks は、大規模なクエリを重視していたので、小規模なクエリでの高いパフォーマンスは発揮していませんでした。
- 仮に実現可能だとしても、データウェアハウスのシステム構築には 10 年以上かかるというのがこれまでの常識であり、そんなに迅速に進展できるすべはありません。
ここからは、この問題について1つずつ議論していきます。
独自のフォーマットとオープンフォーマット
レイクハウスアーキテクチャの主要な考え方の1つは、オープンなストレージフォーマットです。「オープン」であることは、ベンダーロックインを回避し、ベンダーに依存しないエコシステムのツールの開発を可能に�します。オープンフォーマットの大きなメリットは標準化です。この標準化により、エンタープライズデータの多くがオープンなデータレイクに格納されることになり、Apache Parquet がデータ格納のデファクトスタンダードとなりました。データウェアハウスと同様の性能グレードをオープンフォーマットにもたらすことで、データの移動を最小限にし、BI と AI のワークロードのデータアーキテクチャをシンプルにすることが目的です。
オープンであることに対するよくある反論は、「オープンフォーマットは変更が困難で改善が難しい」というものです。この反論は理論的にはあっていますが、実際には正確ではありません。理由は次のとおりです。
第一に、オープンフォーマットも進化できることは間違いありません。大容量のデータストレージでよく使用されるオープンフォーマットの Parquet は、継続的な改善がなされています。私たちが Delta Lake を導入した主要な理由の 1 つに、Parquet レイヤーでは実現できない追加のケイパビリティを導入することが挙げられます。Delta Lake は、Parquet に追加のインデックス機能と統計機能をもたらしました。
第二に、Databricks のシステムは、オブジェクトストアからローカル NVMe SSD にデータをロードする際に、自動的に Delta Lake と Parquet の未加工のデータを効率的なフォーマットにトランスコードすることです。これにより、その後の最適化が可能になります。
��すなわち、データウェアハウスで使用される独自のフォーマットと比較しても、ほとんどのデータウェアハウスのワークロードにおける Delta Lake と Parquet は、すでに十分な最適化を提供していることになります。このようなワークロードでは、データスキャンの高速化ではなく、クエリ処理の高速化が最適化の機会になります。実際のところ、TPC-DS では、最適化された内部フォーマットでキャッシュされたクエリデータは、S3 のコールドデータのクエリよりもわずか 10% しか高速ではありません。(これは、ベンチマークテストを行ったデータウェアハウスと Databricks の両方で同じ結果でした。)
MPP アーキテクチャ
よくある誤解に「データウェアハウスは SQL パフォーマンスに優れた MPP アーキテクチャを採用しているが Databricks はそうではない」というものがあります。MPP アーキテクチャとは、単一のクエリを複数のノードで処理する機能のことです。これはまさに、Databricks SQL のアーキテクチャです。ベースは Apache Spark ではなく、むしろ Photon です。エンジンを完全に書き換え、C++ でゼロから構築したもので、最新の SIMD ハードウェアに対応し、高負荷な並列クエリ処理を行います。すなわち、Photon は MPP エンジンなのです。
スループットとレイテンシのトレードオフ
スループットとレイテンシの優先度の選択は、コンピューターシステムにおいて以前からあるトレードオフです。システムは、高スループットと低レイテンシを同時に達成できないという意味です。スループットを優先した設計にする場合(例:デー��タのバッチ処理)、レイテンシを犠牲にしなければなりません。これは、データシステムにおいて、大規模なクエリと小規模なクエリを効率的に同時処理できないことを意味します。
私たちは、このトレードオフを否定するつもりはありません。実際、技術設計文書の中でよく議論になります。しかし、Databricks や一般的なウェアハウスを含め、現在の最先端のシステムでは、スループットおよびレイテンシの両方の面で、大きな進化を遂げています。
その結果、スループットとレイテンシを両方とも同時に改善できる新たな設計、実装を考案することは十分可能です。これがまさに、この 2 年間で Databricks が実現したほぼ全ての主要技術の構築方法です。Photon、Delta Lake、その他の最先端技術により、大小規模のクエリのパフォーマンスを改善し、新たな記録を更新できました。
時間と集中
これまでの常識では、データベースのシステムが成熟するまでには少なくとも 10 年は必要であると考えられてきました。Databricks が最近(SQL ワークロードをサポートするために)レイクハウスに注力していることを考えても、SQL のパフォーマンスを高めるには、さらなる投資が必要なことは明らかです。にもかかわらず、私たちが予想以上のスピードでこれを実現できた理由は以下のとおりです。
まず第一に、この投資は 1、2年の間に始まったものではありません。Databricks では、創業当初から、さまざまな基盤技術に投資し、Databricks 上の AI ワークロードにもメリットのある SQL ワークロードをサポートしてきました。これには、完全なコストベースのクエリオプティマイザや、ネイティブにベクトル化された実行エンジン、ウィンドウ関数などのさまざまなケイパビリティが含まれます。Databricks のワークフローの大部分は、SQL にマッピングされる SparkのDataFrame API によって実行されるため、これらのコンポーネントは、数年にわたりテストされ、最適化されてきたものです。SQL ワークロードを特に重要視してきたわけではありません。最近のレイクハウスの位置付けの変更は、お客様のシンプルなデータアーキテクチャのニーズに応えたものです。
第二の理由は、SaaS モデルによるソフトウェア開発サイクルの加速です。これまで、多くのベンダーには年次のリリースサイクルがあり、お客様がそのソフトウェアをインストールして導入するまでに数年のサイクルがありました。SaaS では、エンジニアリングチームが新たなデザインを考案、実装し、数日で一部のお客様にソフトウェアをリリース可能です。この開発サイクルの短縮により、チームは迅速にフィードバックを取得し、イノベーションの高速化を実現することができました。
第三に、Databricks には、リーダーシップのキャパシティと資本の両面で、この課題に注力する能力があったことです。これまでの新たなデータウェアハウスシステムの構築は、スタートアップ企業もしくは大企業の中の新たなチームによって行われてきました。Databricks のような、資金力(35 億ドルを超える資金調達)があり、データウェアハウスシステム構築に必要な人材を揃えることができるデータベースのスタートアップ企業は他にありませんでした。大企業の中での新たな取り組みは、他の取り組みと同様に扱われます。経営陣から注目されることもないでしょう。
私たちは当初、データウェアハウスの構築ではなく、一般的に技術的な問題を多く抱えるデータサイエンスや AI などの関連のビジネス領域に注力していました。最初の目的の成功により、これまでにない最もアグレッシブな SQL チームの構築に資金を投入できるようになり、短期間で広範囲なデータウェアハウスの経験を持つチームメンバーを集約しました。これは、他の企業では 10 年ほど必要とすることです。このチームのメンバーには、Amazon Redshift、GoogleのBigQuery、F1(Google 社内のデータウェアハウスシステム)、Procella(Youtube 社内のデータウェアハウスシステム)、Oracle、IBM DB2、Microsoft SQL Server など、成功したデータシステムのリードエンジニアやデザイナーもいます。
優れた SQL パフォーマンスは一朝一夕には実現しません。Databricks では、恵まれた環境もありましたが、数年前からこの課題に取り組んでいました。
実績による実証
このベンチマークテストの結果は、Databricks のお客様によって実証されています。世界中の 5,000 社以上の企業が、Databricks のレイクハウスプラットフォームを活用して世界中の難題の解決に挑んでいます。以下に導入事例をいくつかご紹介します。
- Bread Finance:Bread 社は、財務レポート、不正検知、信用リスク、損害の査定、フルファネルの推薦エンジンなど、ビッグデータのユースケースを持つ、テクノロジードリブンなペイメントプラットフォームを提供しています。Databricks のレイクハウスプラットフォームを活用して、データの取り込みをこれまでの 1 日 1 回のバッチジョブから、ほぼリアルタイムのインジェストに移行し、データ処理時間を 90% 削減しています。さらに、このデータプラットフォームは、わずか 1.5 倍のコスト増で、データ規模を 140 倍にスケーリングできます。
- シェル(Shell):Databricks のレイクハウスプラットフォームにより、数百人もいるデータアナリストが、標準な BI ツールを利用して、ペタバイト規模のデータセットに迅速なクエリを実行できるようになりました。これは、シェル社にとって革新となりました。
- リジェネロン(Regeneron):データセット全体に対して行うクエリの実行時間が 30 分から 3 秒に短縮し、 600 倍高速化されました。計算生物学者による迅速な知見の抽出が可能になり、創薬標的同定を加速しています。
まとめ
レイクハウスアーキテクチャの上に構築された Databricks SQL は、市場において最も高速なデータウェアハウスであり、優れた価格性能を提供します。これにより、他のシステムにデータをエクスポートしなくても、新たなデータがインジェストされると同時にあらゆるデータに対して、低レイテンシで優れたパフォーマンスを得ることができるようになりました。
これは、ワールドクラスのデータウェアハウス性能をデータレイクにもたらすという、レイクハウスのビジョンを証明するものです。もちろん、Databricksが構築したのは、単なるデータウェアハウスではありません。レイクハウスのアーキテクチャは、ウェアハウス機能に加えて、データサイエンス、機械学習のあらゆるデータワークロ�ードをサポートする機能を備えています。
しかし、これが私たちのゴールではありません。私たちの市場最強のチームは、さらなるパフォーマンスのブレークスルーを実現すべく、注力しています。また、パフォーマンスだけでなく、使いやすさやガバナンスに関する数多くの改善にも取り組んでいます。今後の更新にご期待ください。
The TPC does not audit or validate results of benchmarks derived from the TPC-DS and does not consider results of derived benchmarks to be comparable to published TPC-DS results.
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。