Databricks Lakehouse Platform 上でのデータウェアハウスモデリング手法とその実装
レイクハウスでのデータボルトとスタースキーマの使用
によって ソーハム・バット 、 Deepak Sekar による投稿
レイクハウスは、データレイクとデータウェアハウスの最良の機能を組み合わせた新しいデータプラットフォームのパラダイムです。これは、多くのユースケースとデータプロダクトを収容できる大規模なエンタープライズレベルのデータプラットフォームとして設計されています。すべてのデータの単一の統合された�エンタープライズデータリポジトリとして機能します。
- データドメイン、
- リアルタイムストリーミングユースケース、
- データマート、
- 分散データウェアハウス、
- データサイエンスフィーチャーストアおよびデータサイエンスサンドボックス、および
- 部門ごとのセルフサービス分析サンドボックス。
ユースケースの多様性を考慮すると、レイクハウス上の異なるプロジェクトには、異なるデータ編成原則やモデリング手法が適用される場合があります。技術的には、Databricks Lakehouse Platformは、さまざまなデータモデリングスタイルをサポートできます。この記事では、レイクハウスのBronze/Silver/Goldデータ編成原則の実装と、さまざまなデータモデリング手法が各レイヤーにどのように適合するかを説明することを目的としています。
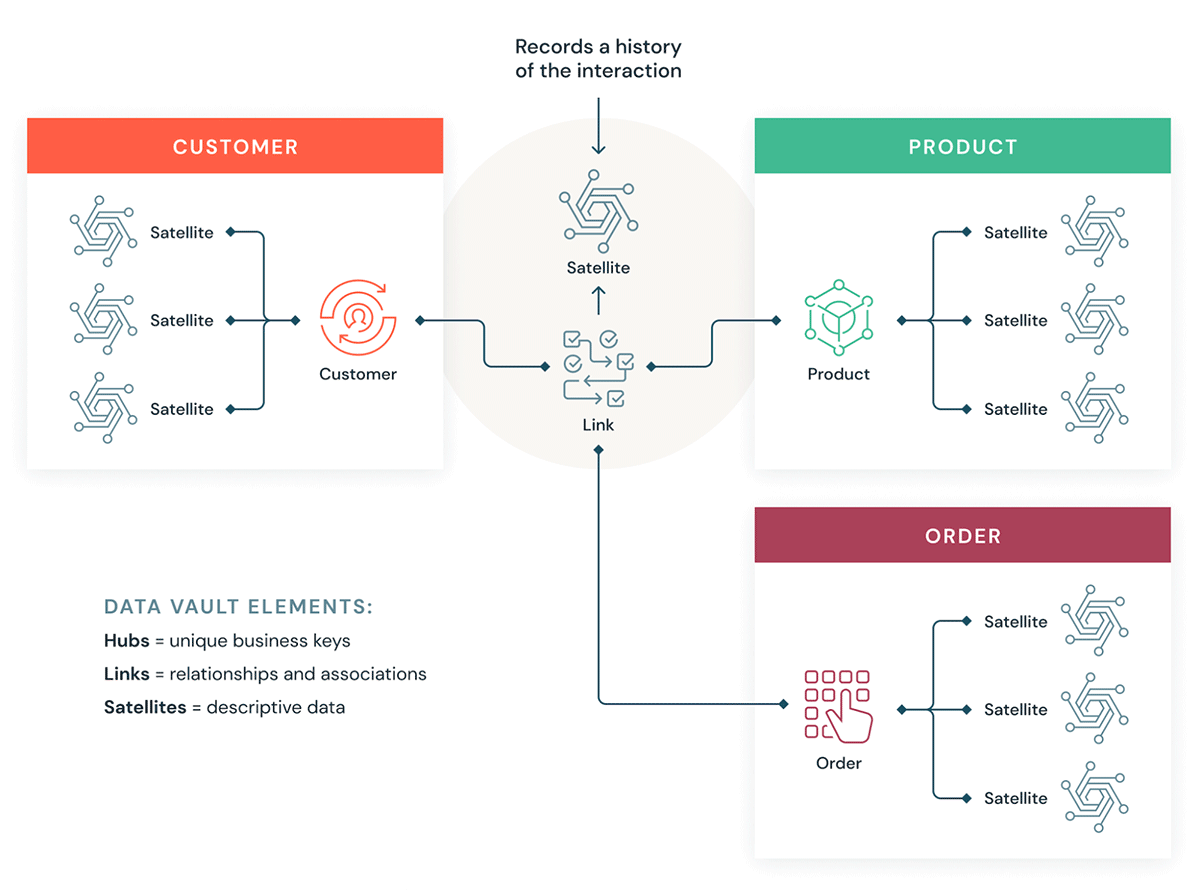
データボールトとは?
Data Vaultは、KimballおよびInmonの方法と比較して、エンタープライズ規模の分析のためのデータウェアハウスを構築するために使用される、より最近のデータモデリングデザインパターンです。
Data Vaultは、データをハブ、リンク、サテライトの3つの異なるタイプに編成します。ハブはコアビジネスエンティティを表し、リンクはハブ間の関係を表し、サテライトはハブまたはリンクに関する属性を格納します。
Data Vaultは、スケーラビリティ、データ統合/ETL、および開発速度が重要なアジャイルデータウ��ェアハウス開発に焦点を当てています。ほとんどのお客様は、Databricksの編成パラダイムであるBronze、Silver、Goldレイヤーに対応する、ランディングゾーン、Vaultゾーン、およびデータマートゾーンを持っています。ハブ、リンク、サテライトテーブルのData Vaultモデリングスタイルは、通常、Databricks LakehouseのSilverレイヤーによく適合します。
Data Vaultモデリングの詳細については、Data Vault Allianceをご覧ください。
次元モデリングとは?
次元モデリングは、分析のためにデータウェアハウスを最適化するためのボトムアップアプローチです。次元モデルは、ビジネスデータをディメンション(時間や製品など)とファクト(金額や数量のトランザクションなど)に非正規化するために使用され、さまざまなサブジェクトエリアが共通ディメンションを介して接続され、さまざまなファクトテーブルにナビゲートします。
次元モデリングの最も一般的な形式はスター スキーマです。スター スキーマは、データを理解および分析しやすく、レポートを実行するのが非常に簡単で直感的な方法でデータを編成するために使用される多次元データモデルです。Kimballスタイルのスター スキーマまたは次元モデルは、データウェアハウスおよびデータマートのプレゼンテーションレイヤー、さらにはセマンティックおよびレポーティングレイヤーの事実上のゴールドスタンダードです。スター スキーマ設計は、大規模なデータセットのクエリに最適化されています。
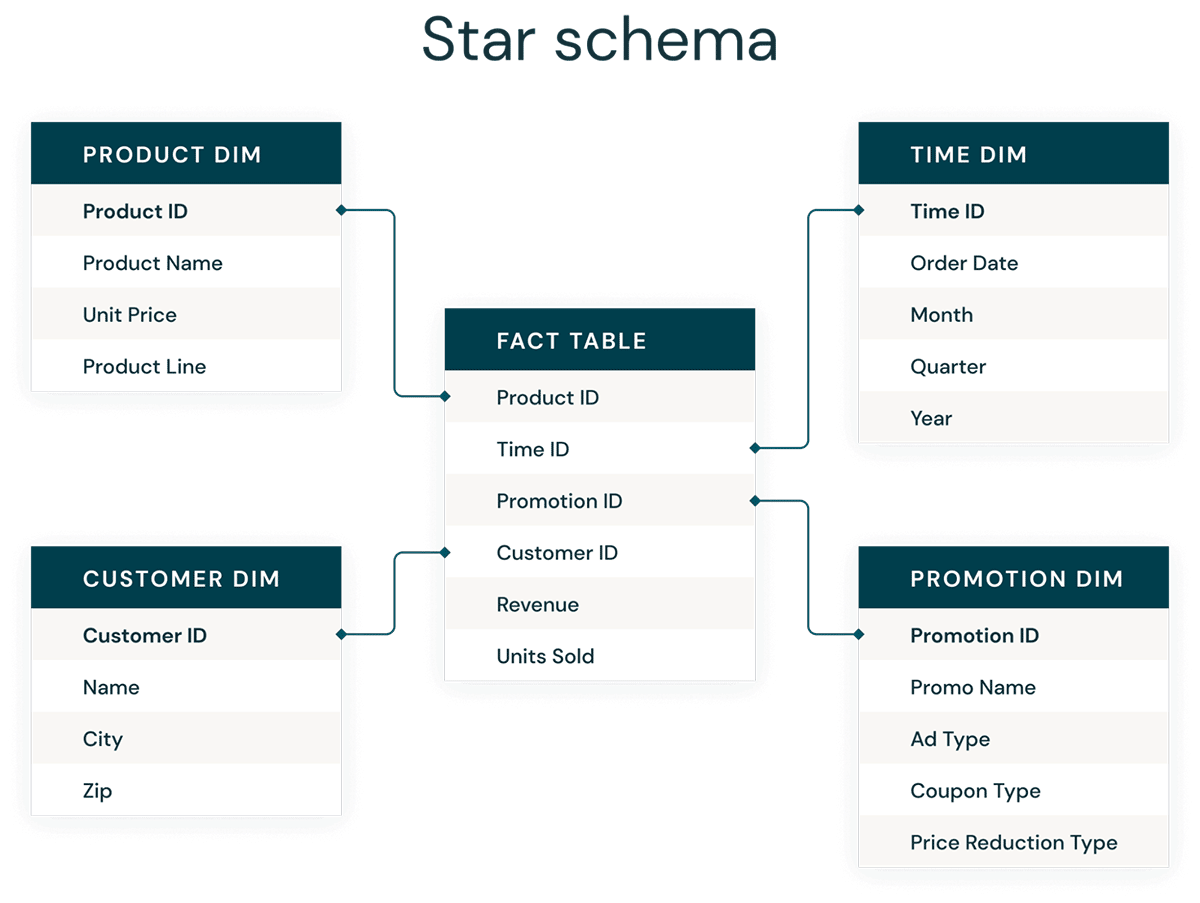
正規化されたData Vault(書き込み最適化)と非正規化された次元モデル(読み取り最適化)の両方のデータモデリングスタイルは、Databricks Lakehouseに場所があります。SilverレイヤーのData Vaultのハブとサテライトは、スター スキーマのディメンションをロードするために使用され、Data Vaultのリンクテーブルは、ディメンションモデルのファクトテーブルをロードするための主要な駆動テーブルになります。Kimball GroupのKimball Groupから次元モデリングの詳細をご覧ください。
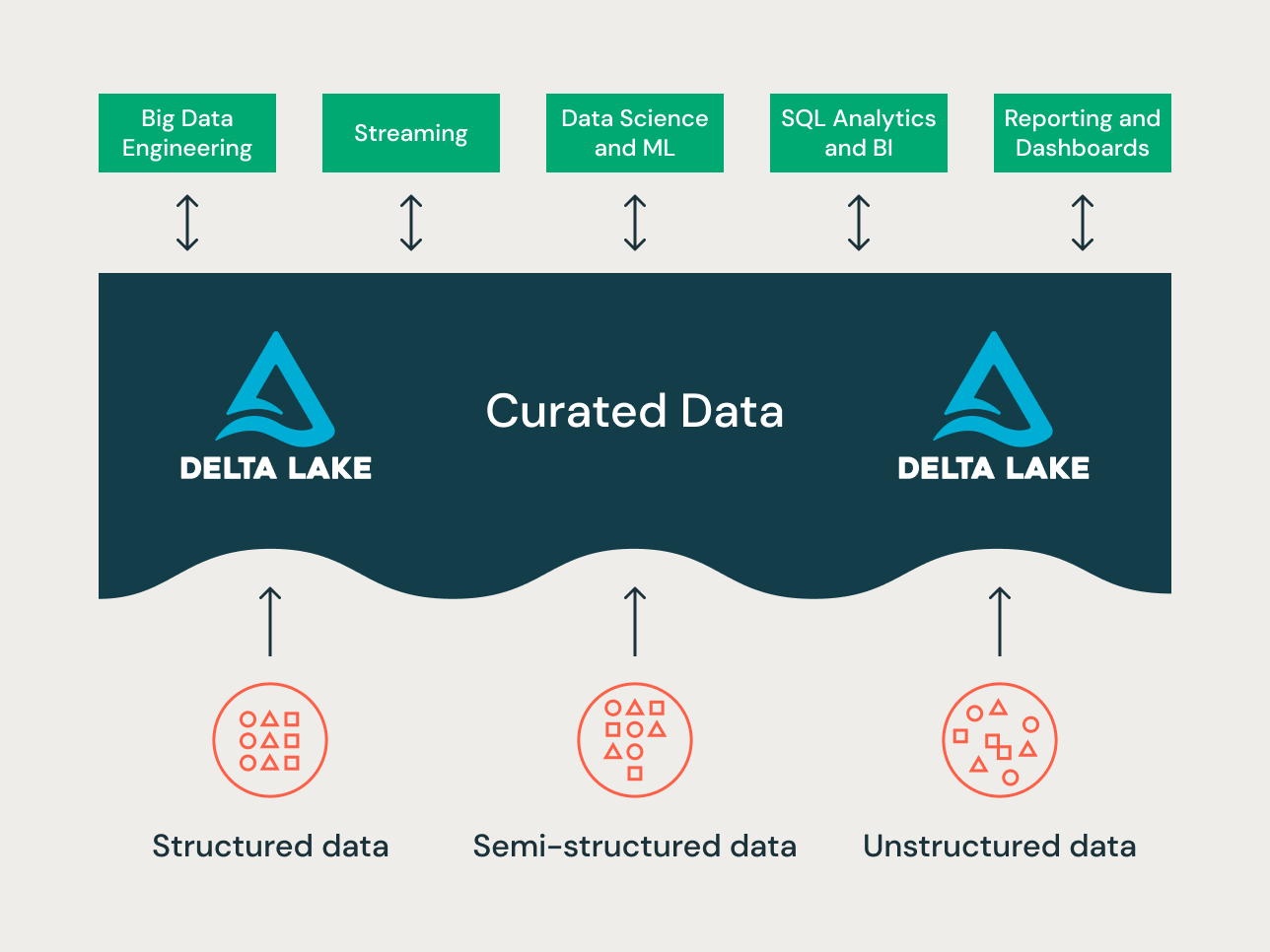
レイクハウスの各レイヤーにおけるデータ編成原則
最新のレイクハウスは、包括的なエンタープライズレベルのデータプラットフォームです。ETL、BI、データサイエンス、ストリーミングなど、さまざまなデータモデリングアプローチを必要とする可��能性のあるあらゆる種類のユースケースに対して、非常にスケーラブルでパフォーマンスが高くなります。典型的なレイクハウスがどのように編成されているかを見てみましょう。
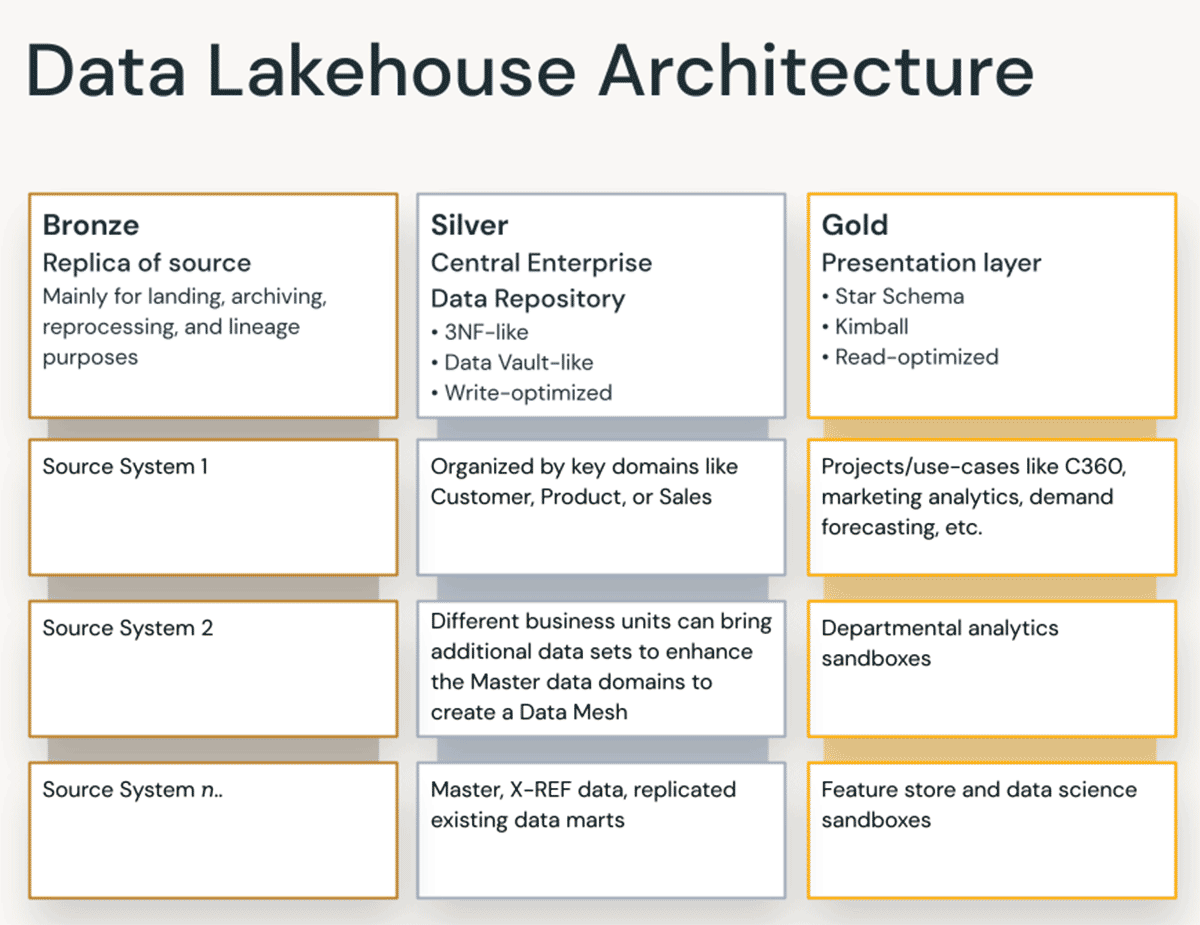
Bronzeレイヤー — ランディングゾーン
Bronzeレイヤーは、ソースシステムからすべてのデータを着陸させる場所です。このレイヤーのテーブル構造は、ロード日時、プロセスIDなどをキャプチャするためのオプションのメタデータ列を除き、ソースシステムテーブル構造「そのまま」に対応します。このレイヤーの焦点は、変更データキャプチャ(CDC)であり、ソースシステムからデータを再読み取りすることなく、ソースデータの履歴アーカイブ(コールドストレージ)、データリネージ、監査可能性、および必要に応じた再処理を提供できることです。
ほとんどの場合、BronzeレイヤーのデータをDelta形式で保持することは良い考えです。これにより、ETLのためにBronzeレイヤーから後続の読み取りが効率的になり、CDCの変更を書き込むためにBronzeで更新を実行できるようになります。JSONまたはXML形式でデータが到着する場合、ソースデータ形式のまま着陸させ、Delta形式に変更してステージングする顧客も見られます。そのため、論理的なBronzeレイヤーを物理的なランディング��ゾーンとステージングゾーンにマニフェストする顧客も見られます。
ランディングゾーンにソースデータ形式のまま生データを保存することは、インジェストツールがDeltaをネイティブシンクとしてサポートしていない場合や、ソースシステムがオブジェクトストアに直接データをダンプする場合に、一貫性を保つのにも役立ちます。このパターンは、ソースが生のファイルのランディングゾーンにデータを着陸させ、その後Databricks AutoLoaderがデータをDelta形式のステージングレイヤーに変換する、オートローダーインジェストフレームワークともよく一致します。
Silverレイヤー — エンタープライズセントラルリポジトリ
LakehouseのSilverレイヤーでは、Bronzeレイヤーからのデータが一致、マージ、統合、クリーニング(「必要十分」)され、Silverレイヤーがすべての主要なビジネスエンティティ、概念、およびトランザクションの「エンタープライズビュー」を提供できるようにします。これは、エンタープライズオペレーショナルデータストア(ODS)またはセントラルリポジトリ、あるいはデータメッシュのデータドメイン(例:マスター顧客、製品、重複しないトランザクション、クロスリファレンステーブル)に似ています。このエンタープライズビューは、さまざまなソースからのデータを統合し、アドホックレポート、高度な分析、およびMLのためのセルフサービス分析を可能にします。また、部門のアナリスト、データエンジニア、データサイエンティストが、Goldレイヤーのエン�タープライズおよび部門データプロジェクトを通じてビジネス上の問題を解決するためのデータプロジェクトや分析を作成するためのソースとしても機能します。
Lakehouseデータエンジニアリングパラダイムでは、従来のExtract-Transform-Load(ETL)ではなく、通常、Extract-Load-Transform(ELT)方法論が採用されています。ELTアプローチは、Silverレイヤーにロードする際に、最小限または「必要十分」な変換とデータクリーニングルールのみが適用されることを意味します。すべての「エンタープライズレベル」のルールは、Goldレイヤーで適用されるプロジェクト固有の変換ルールとは対照的に、Silverレイヤーで適用されます。Lakehouseでのデータの取り込みと配信の速度と俊敏性がここで優先されます。
データモデリングの観点からは、Silverレイヤーはより3NF(3rd Normal Form)のようなデータモデルを持っています。Data Vaultのような書き込みパフォーマンスの高いデータアーキテクチャとデータモデルをこのレイヤーで使用できます。Data Vault方法論を使用する場合、生のData VaultとビジネスVaultの両方がレイクの論理的なSilverレイヤーに適合し、Point-In-Time(PIT)プレゼンテーションビューまたはマテリアライズドビューがGoldレイヤーで提示されます。
Goldレイヤー — プレゼンテーションレイヤー
Goldレイヤーでは、次元モデリング/Kimball方法論に従って、複数のデータマートまたはウェアハウスを構築できます。前述のように、Goldレイヤーはレポート用であり、Silverレイヤーと比較して結合が少なく、より非正規化された読み取り最適化データモデルを使用します。データサイエンティスト��がフィーチャーエンジニアリングのためにアルゴリズムに供給するためにそのようにしたい場合、Goldレイヤーのテーブルは完全に非正規化されることもあります。
ETLとデータ品質ルールは、「プロジェクト固有」のものが、SilverレイヤーからGoldレイヤーへのデータ変換時に適用されます。データウェアハウス、データマート、または顧客分析、製品/品質分析、在庫分析、顧客セグメンテーション、製品レコメンデーション、マーケティング/セールス分析などのデータプロダクトのような最終的なプレゼンテーションレイヤーが、このレイヤーで提供されます。KimballスタイルのスタースキーマベースのデータモデルやInmonスタイルのデータマートは、LakehouseのこのGoldレイヤーに適合します。セルフサービス分析のためのData Science Laboratoriesや部門別サンドボックスもGoldレイヤーに含まれます。
レイクハウスのデータ編成パラダイム
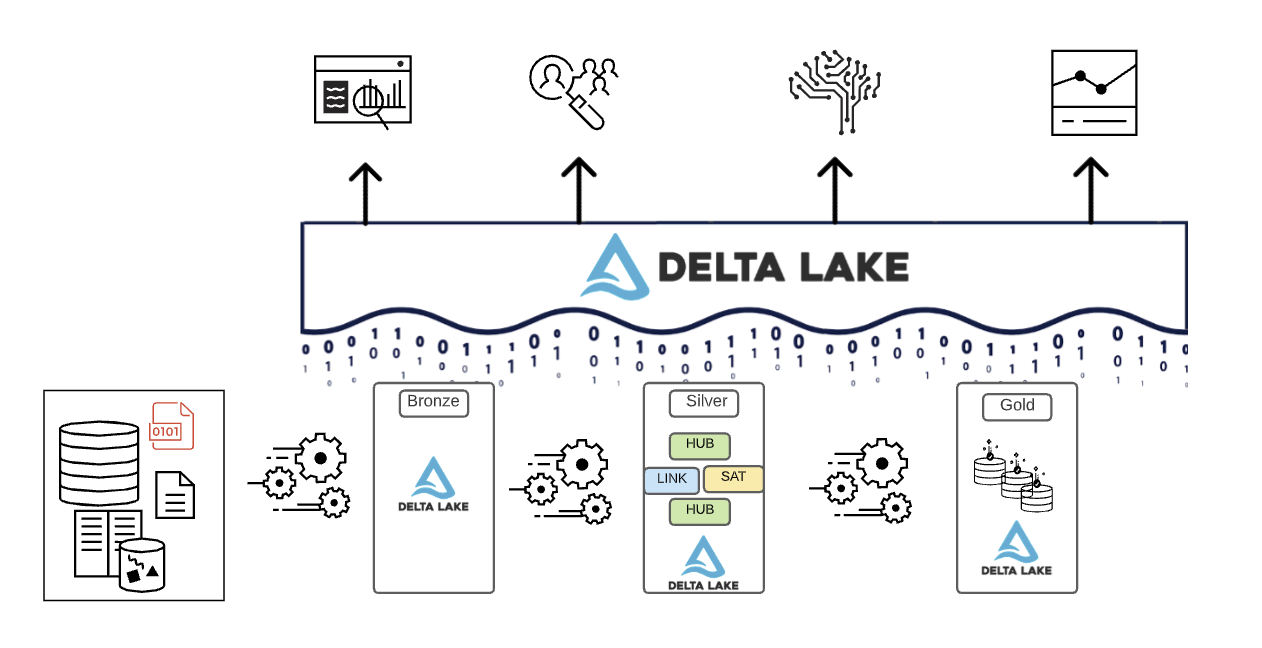
要約すると、データはレイクハウスのさまざまなレイヤーを通過するにつれてキュレーションされます。
- Bronzeレイヤーは、ソースシステムのデータモデルを使用します。データが生の形式で取り込まれる場合、このレイヤー内でDelta Lake形式に変換されます。
- Silverレイヤーは、さまざまなソースからのデータを初めて統合し、エンタープライズビューを作成するために適合させます。通常、3NF(正規化第3正�規形)ライクまたはData Vaultライクな、より正規化された書き込み最適化データモデルを使用します。
- Goldレイヤーは、Silverレイヤーよりも非正規化またはフラット化されたデータモデルを持つプレゼンテーションレイヤーであり、通常はKimballスタイルのディメンショナルモデルまたはスタースキーマを使用します。Goldレイヤーには、エンタープライズ全体でのセルフサービス分析とデータサイエンスを可能にするための部門別およびデータサイエンスサンドボックスも格納されます。これらのサンドボックスとそれら自身の個別のコンピューティングクラスターを提供することで、ビジネスチームがレイクハウス外に独自のデータコピーを作成するのを防ぎます。
このレイクハウスのデータ編成アプローチは、データサイロを打破し、チームを統合し、適切なガバナンスを備えた単一のプラットフォームでETL、ストリーミング、BI、AIを実行できるようにすることを目的としています。中央データチームは、組織内のイノベーションの推進者となり、新しいセルフサービスユーザーのオンボーディングをスピードアップし、多くのデータプロジェクトを並行して開発できるようにするべきです。データモデリングプロセスがボトルネックになるのではなく。Databricks Unity Catalogは、レイクハウスでの検索と検出、ガバナンス、およびリネージを提供し、良好なデータガバナンスのペースを保証します。
Databricks SQLでData Vaultとスタースキーマデータウェアハウスを構築しましょう。
さらに読む:
- DatabricksとDelta Lakeでスタースキーマを実装するための5つの簡単なステップ
- Databricks LakehouseプラットフォームでData Vaultモデルを実装するための推奨事項
- ディメンショナルモデリングのベストプラクティスとモダンレイクハウスでの実装
- 代理キーを生成するためのID列がレイクハウスで利用可能になりました!
- Databricks LakehouseでEDWディメンショナルモデルをリアルタイムでロード
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。