Prescriptive Guidance for Implementing a Data Vault Model on the Databricks Lakehouse Platform
by Soham Bhatt, Tanveer Shaikh and Glenn Wiebe
There are many different data models that you can use when designing an analytical system, such as industry-specific domain models, Kimball, Inmon, and Data Vault methodologies. Depending on your unique requirements, you can use these different modeling techniques when designing a lakehouse. They all have their strengths, and each can be a good fit in different use cases.
Ultimately, a data model is nothing more than a construct defining different tables with one-to-one, one-to-many, and many-to-many relationships defined. Data platforms must provide best practices for physicalizing the data model, to help with easier information retrieval and better performance.
In a previous article, we covered Five Simple Steps for Implementing a Star Schema in Databricks With Delta Lake. In this article, we aim to explain what a Data Vault is, how to implement it within the Bronze/Silver/Gold layer and how to get the best performance of Data Vault with Databricks Lakehouse Platform.
Data Vault modeling, defined
The goal of Data Vault modeling is to adapt to fast-paced changing business requirements and support faster and agile development of data warehouses by design. A Data Vault is well suited to the lakehouse methodology since the data model is easily extensible and granular with its hub, link and satellite design so design and ETL changes are easily implemented.
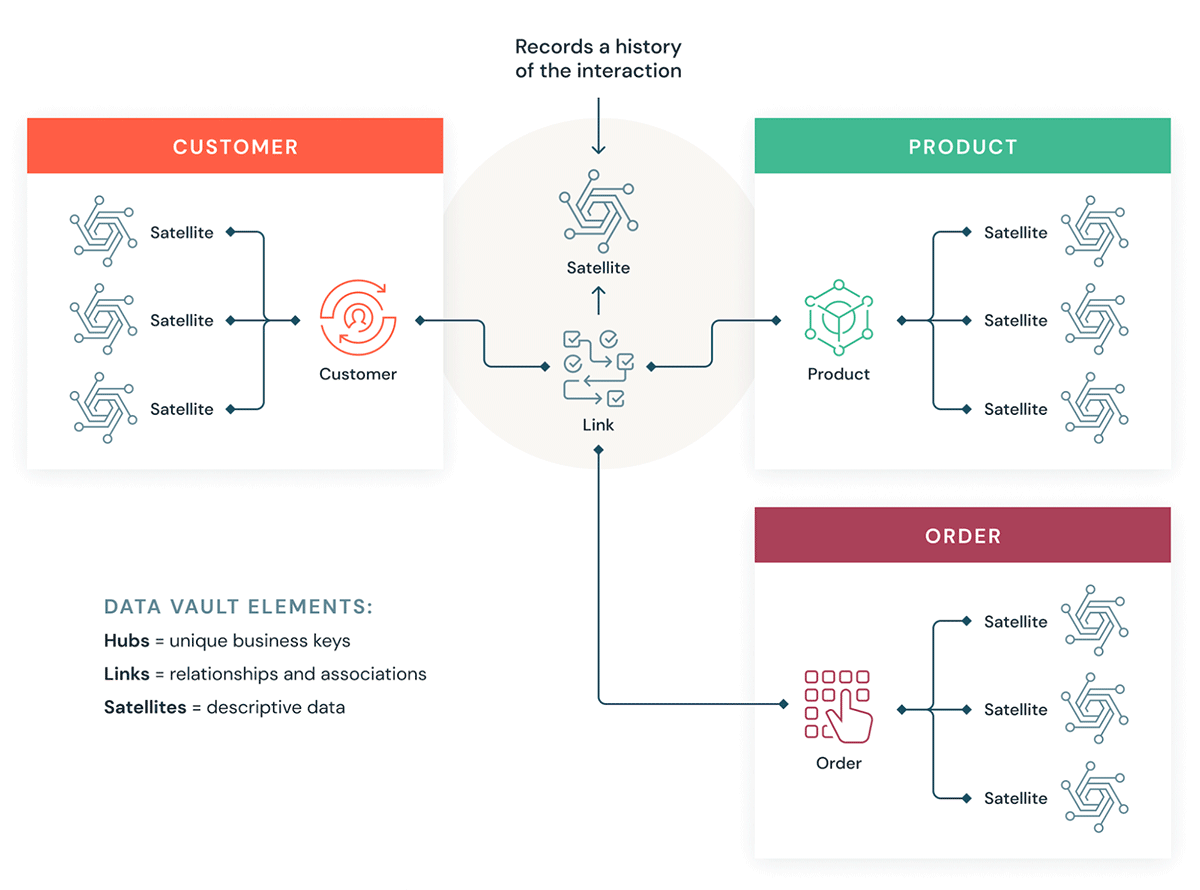
Let's understand a few building blocks for a Data Vault. In general, a Data Vault model has three types of entities:
- Hubs — A Hub represents a core business entity, like customers, products, orders, etc. Analysts will use the natural/business keys to get information about a Hub. The primary key of Hub tables is usually derived by a combination of business concept ID, load date, and other metadata information.
- Links — Links represent the relationship between Hub entities. It has only the join keys. It is like a Factless Fact table in the dimensional model. No attributes - just join keys.
- Satellites — Satellite tables have the attributes of the entities in the Hub or Links. They have descriptive information on core business entities. They are similar to a normalized version of a Dimension table. For example, a customer hub can have many satellite tables such as customer geographical attributes, , customer credit score, customer loyalty tiers, etc.
One of the major advantages of using Data Vault methodology is that existing ETL jobs need significantly less refactoring when the data model changes. Data Vault is a "write-optimized" modeling style and supports agile development approaches and is a great fit for data lakes and lakehouse approach.
How Data Vault fits in a Lakehouse
Let's see how some of our customers are using Data Vault Modeling in a Databricks Lakehouse architecture:
Considerations for implementing a Data Vault Model in Databricks Lakehouse
- Data Vault modeling recommends using a hash of business keys as the primary keys. Databricks supports hash, md5, and SHA functions out of the box to support business keys.
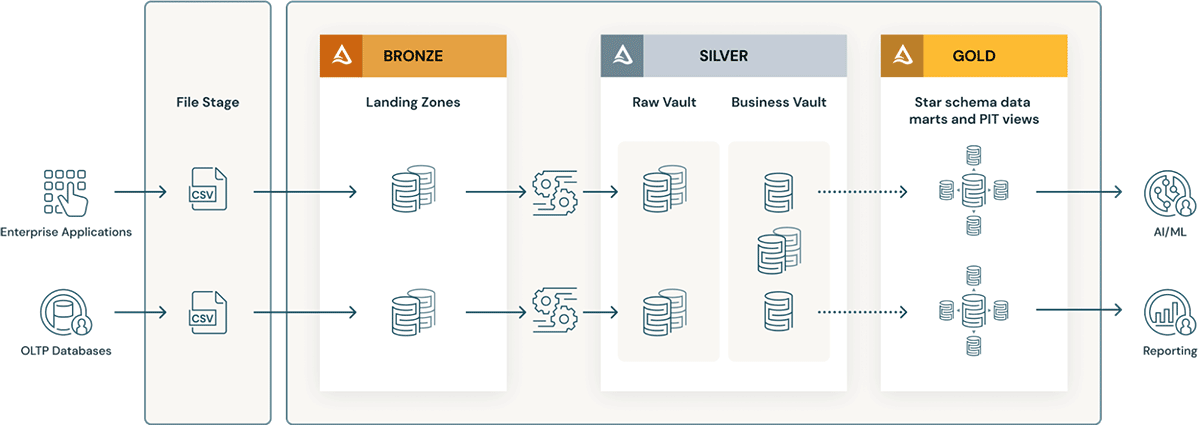
- Data Vault layers have the concept of a landing zone (and sometimes a staging zone). Both these physical layers naturally fit the Bronze layer of the data lakehouse. If the landing zone data arrives such as Avro, CSV, parquet, XML, JSON formats, it is converted to Delta-formatted tables in the staging zone, so that the subsequent ETL can be highly performant.
- Raw Vault is created from the landing or staging zone. Data is modeled as Hubs, Links and Satellite tables in the Raw Data Vault. Additional "business" ETL rules are not typically applied while loading the Raw Data Vault.
- All the ETL business rules, data quality rules, cleansing and conforming rules are applied between Raw and Business Vault. Business Vault tables can be organized by data domains - which serve as an enterprise "central repository" of standardized cleansed data. Data stewards and SMEs own the governance, data quality and business rules around their areas of the Business Vault.
- Query-helper tables such as Point-in-Time (PIT) and Bridge tables are created for the presentation layer on top of the business vault. The PIT tables will bolster query performance as some satellites and hubs are pre-joined and provide some WHERE conditions with "point in time" filtering. Bridge tables pre-joins hubs or entities to provide a flattened "dimensional table" like views for Entities. Delta Live Tables are exactly like Materialized Views and can be used to create Point-in-Time tables as well as Bridge tables in the Gold/Presentation layer on top of the Business Data Vault.
- As business processes change and adapt, the Data Vault model can be easily extended without massive refactoring like the dimensional models. Additional hubs (subject areas) can be easily added to links (pure join tables) and additional satellites (e.g. customer segmentations) can be added to a Hub (customer) with minimal changes.
- Also loading a dimensional model Data Warehouse in Gold layer becomes easier for the following reasons:
- Hubs make key management easier (natural keys from hubs can be converted to surrogate keys via Identity columns).
- Satellites make loading dimensions easier because they contain all the attributes.
- Links make loading fact tables quite straightforward because they contain all the relationships.
Tips to get best performance out of a Data Vault Model in Databricks Lakehouse
- Use Delta Formatted tables for Raw Vault, Business Vault and Gold layer tables.
- Make sure to use OPTIMIZE and Z-order indexes on all join keys of Hubs, Links and Satellites.
- Do not over partition the tables -especially the smaller satellites tables. Use Bloom filter indexing on Date columns, current flag columns and predicate columns that are typically filtered on to ensure best performance - especially if you need to create additional indices apart from Z-order.
- Delta Live Tables (Materialized Views) makes creating and managing PIT tables very easy.
- Reduce the
optimize.maxFileSizeto a lower number, such as 32-64MB vs. the default of 1 GB. By creating smaller files, you can benefit from file pruning and minimize the I/O retrieving the data you need to join. - Data Vault model has comparatively more joins, so use the latest version of DBR which ensures that the Adaptive Query Execution is ON by default so that the best Join strategy is automatically used. Use Join hints only if necessary. ( for advanced performance tuning).
Learn more about Data Vault modeling at Data Vault Alliance.
Get started on building your Data Vault in the Lakehouse
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.