Delta Live Tablesの新機能とパフォーマンス最適化を発表
DLTは、ETLワークロード専用に構築されたパフォーマンス最適化機能であるEnzymeを開発中であること、およびEnhanced Autoscalingを含むいくつかの新機能のローンチを発表しました。
によって ポール・ラッパス 、 Michael Armbrust による投稿
すべてのクラウドでDelta Live Tables (DLT) が利用可能になって以来(4月、発表)、開発を容易にする新機能の導入、自動インフラストラクチャ管理の強化、ETL処理を高速化するProject Enzymeという新しい最適化レイヤーの発表、そしていくつかのエンタープライズ機能とUXの改善を実現しました。
DLTにより、アナリストやデータエンジニアはSQLとPythonで本番稼働可能なストリーミングまたはバッチETLパイプラインを迅速に構築できます。DLTは、データ処理パイプラインを宣言的に定義することでETL開発を簡素化します。DLTはパイプラインの依存関係を理解し、運用上の複雑さのほとんどを自動化します。
Delta Live Tablesは、その誕生以来、世界中の主要企業で本番ETLユースケースを支えるまでに成長しました。DLTは、スタートアップからエンタープライズまで、ADP、Shell、H&R Block、Jumbo、Bread Finance、JLLを含む1,000社以上の企業で利用されています。
DLTを使用すると、エンジニアはパイプラインの運用・保守に集中するのではなく、データ提供に注力し、主要な機能を活用できます。継続的に到着するデータを効率的かつ容易にキャプチャするためのChange Data Capture (CDC)のサポートや、ストリーミン�グワークロードで優れたパフォーマンスを提供するEnhanced Auto Scalingのプレビュー版のリリースなど、いくつかのエンタープライズ機能とUXの改善を有効にしました。改善点について詳しく見ていきましょう。
開発を容易にする
ETLのエンドツーエンドのライフサイクル管理を容易にするためにUIを拡張しました。
UXの改善。 DLTパイプラインの管理、エラーの表示、豊富なパイプラインACLを持つチームメンバーへのアクセスを容易にするためにUIを拡張しました。また、データ品質メトリクスを一目で確認できるオブザーバビリティUIを追加し、UIから直接パイプラインをスケジュールしやすくしました。詳細はこちら。
パイプラインのスケジュールボタン。 DLTでは、ETLパイプラインを継続的またはトリガーモードで実行できます。継続的パイプラインはデータが到着すると新しいデータを処理し、データレイテンシが重要なシナリオで役立ちます。しかし、多くの顧客は、パイプラインの実行とコストをより厳密に制御するために、トリガーモードでDLTパイプラインを実行することを選択します。Databricks Jobsを使用してDLTパイプラインを定期的なスケジュールで簡単にトリガーできるように、DLT UIに「スケジュール」ボタンを追加しました。これにより、ユーザーはDLT UIを離れることなく数回のクリッ��クで定期的なスケジュールを設定できます。また、実行履歴を表示し、通知を設定するためにジョブの詳細にすばやく移動することもできます。詳細はこちら。
Change Data Capture (CDC)。 DLTを使用すると、データエンジニアは、SQLまたはPythonの新しい宣言的なAPPLY CHANGES INTO APIを使用して、CDCを簡単に実装できます。この新しい機能により、ETLパイプラインはソースデータの変更を簡単に検出し、レイクハウス全体のデータセットに適用できます。DLTは、CDCイベントを処理する際に、挿入、更新、または削除するレコードをフラグ付けしながら、Delta Lakeにデータ変更をインクリメンタルに処理します。詳細はこちら。
CDC Slowly Changing Dimensions—Type 2。 変更データ (CDC) を扱う場合、最新のデータを追跡するためにレコードを更新する必要があることがよくあります。SCD Type 2は、元のデータを保持するようにターゲットに更新を適用する方法です。たとえば、データベース内のユーザーエンティティが別の住所に移動した場合、そのユーザーの以前のすべての住所を保存できます。DLTは、変更の監査証跡を維持する必要がある組織向けにSCDタイプ2をサポートしています。SCD2は値の完全な履歴を保持します。属性の値が変更されると、現在のレコードは閉じられ、変更されたデータ値を持つ新しいレコードが作成され、こ�の新しいレコードが現在のレコードになります。詳細はこちら。
自動インフラストラクチャ管理
Enhanced Autoscaling (プレビュー)。 ストリーミングワークロードのように変化し予測不可能なデータ量に対して最適なパフォーマンスを得るためにクラスターを手動でサイジングすることは困難であり、過剰プロビジョニングにつながる可能性があります。現在のクラスターオートスケーリングはストリーミングSLOを認識しておらず、処理がデータ到着率に追いついていない場合でも迅速にスケールアップしないか、負荷が低い場合にスケールダウンしない可能性があります。DLTは、ストリーミング用に特別に構築された強化されたオートスケーリングアルゴリズムを採用しています。DLTのEnhanced Autoscalingは、エンドツーエンドのレイテンシ全体を最小限に抑えながら、クラスターの利用率を最適化します。これは、取り込み待ちのデータを含むストリーミングワークロードの変動を検出し、必要なリソースの適切な量(ユーザー指定の制限まで)をプロビジョニングすることによって行われます。さらに、Enhanced Autoscalingは、利用率が低い場合はクラスターを正常にシャットダウンしますが、パイプラインに影響を与えないようにすべてのタスクの退避を保証します。その結果、Enhanced Autoscalingを使用するワークロードは、使用されるインフラストラクチャリソースが少なくなるため、コストを節約できます。詳細はこちら。
自動アップグレードとリリースチャネル。 Delta Live Tables (DLT) クラスターは、Databricks runtime (DBR) に基づいたDLTランタイムを使用します。Databricksは、約1〜2ヶ月ごとにDLTランタイムを自動的にアップグレードします。DLTは、エンドユーザーの介入なしにDLTランタイムを自動的にアップグレードし、アップグレード後にパイプラインの正常性を監視します。DLTランタイムのアップグレードによりDLTパイプラインが起動できないことを検出した場合、パイプラインを以前の既知の正常なバージョンにロールバックします。DLTチャネルを利用してDLTランタイムのプレビューバージョンをテストし、リグレッションがあった場合に自動的に通知を受けることで、initスクリプトやその他のDBRの動作に対する破壊的な変更について早期に警告を得ることができます。Databricksは、本番ワークロードにはCURRENTチャネルの使用を推奨しています。詳細はこちら。
ETLプロセスを高速化するために特別に設計された新しい最適化レイヤー、Enzymeを発表
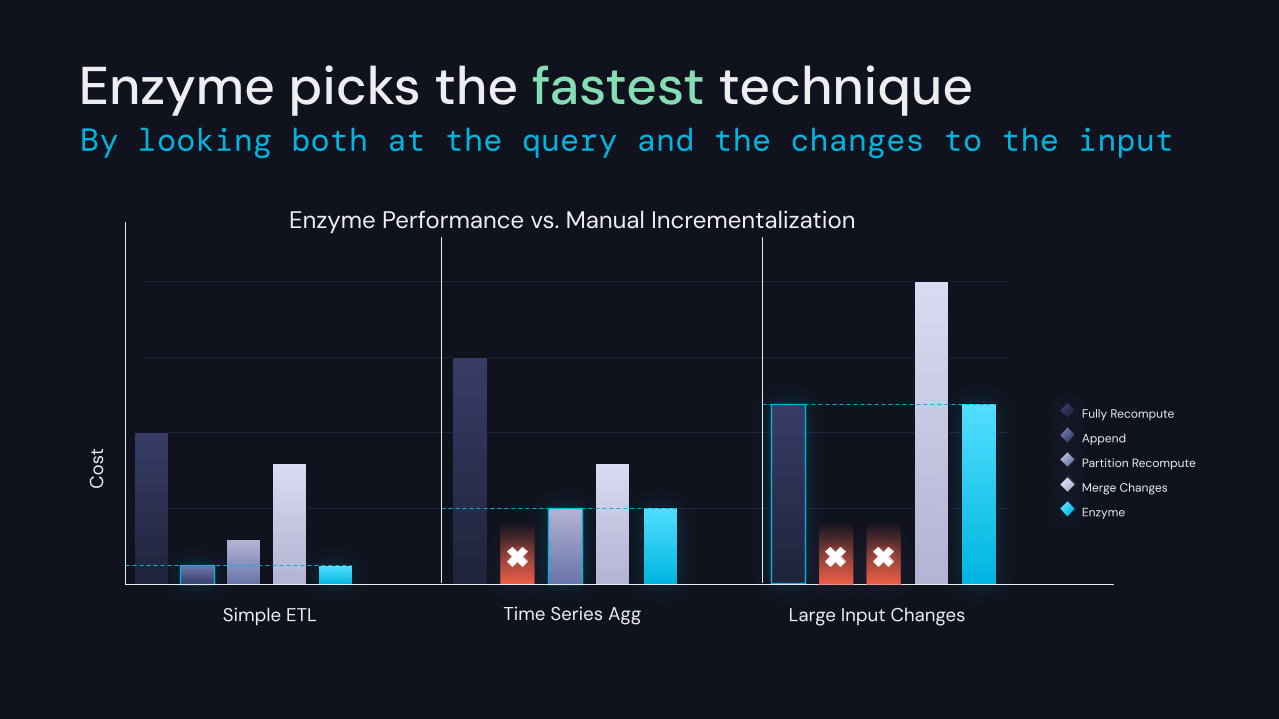
下流分析のために準備するためのデータの変換は、Databricksプラットフォーム上のほとんどの他のワークロードの前提条件です。SQLとDataFramesによりユーザーは比較的簡単に変換を表現できますが、入力データは常に変化します。これにより、ETLによって生成されたテーブルの再計算が必要になります。最初から結果を再計算するのは簡単ですが、多くの顧客が運用している規模ではコストがかかりすぎる場合がよくあります。
ETLの新しい最適化レイヤーであるProject Enzymeを開発していることを発表できることを嬉しく思います。Enzymeは、Deltaテーブルに格納された指定されたクエリの結果のマテリアライゼーションを効率的に最新の状態に保ちます。コストモデルを使用して、従来の具現化ビュー、delta-to-deltaストリーミング、および顧客が一般的に使用する手動ETLパターンで使用される技術を含む、さまざまな技術の中から選択します。
レイクハウス上のDelta Live Tablesを使い始める
データエンジニアとアナリストの両方にとってのDLTの使いやすさを発見するために、以下のデモをご覧ください。
Databricksのお客様は、開始ガイドに従ってください。このGAリリースに含まれるものについて詳しくは、リリースノートをお読みください。Databricksのお客様でない場合は、無料トライアルにサインアップしてください。詳細なDLTの価格については、こちらをご覧ください。
Data + AI Summit 2022の発表やアップデートについてチャットしているデータ愛好家の仲間たちがいるDatabricks Communityで会話に参加しましょう。学び、ネットワークを作り、祝いましょう。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。