地理空間データプロダクトの構築
によって ミロシュ・コリック による投稿
このブログは古くなっています。Databricks Lakehouse内で地理空間データを保存および処理するための最新のアプローチについては、こちらのSpatial SQLに関するブログを参照してください。
地理空間データは、地図、地図作成、そして最近ではデジタルコンテンツの利用を通じて、何世紀にもわたってイノベーションを推進してきました。例えば、最古の地図はマンモスの牙に刻まれたものとして発見されており、紀元前約25000年に遡ります。これにより、地理空間データは社会が意思決定を行うために使用する最も古いデータソースの1つとなっていま�す。より最近の例として、空間分析の誕生とされるのは、1832年にシャルル・ピケが地理空間データを使用してパリのコレラ発生を分析したことです。その数十年後、1854年にはジョン・スノウがロンドンのコレラ発生に対して同じアプローチを取りました。これら2人の人物は、地理空間データを使って当時の最も困難な問題の1つを解決し、結果として数えきれない命を救いました。20世紀に話を移すと、地理情報システム(GIS)の概念は、1967年にカナダのオタワで林業・農村開発省によって初めて導入されました。
今日、私たちはクラウドコンピューティング業界の革命の真っただ中にいます。あらゆる組織がスーパーコンピューティング規模を利用でき、ストレージとコンピューティングの両方で事実上無限にスケーラブルです。プラットフォームのフェデレーションや相互運用性といった問題に対処するため、データコミュニティではデータメッシュやデータマーケットプレイスといった概念が登場しています。これらの概念を地理空間データ、空間分析、GISシステムにどのように適用できるでしょうか?データプロダクトの概念を採用し、地理空間データの設計をプロダクトとして捉えることで実現できます。
このブログでは、モダンで堅牢なスケーラブルな地理空間データプロダクトを設計する方法について、私たちの見解を提供します。Databricks Lakehouse Platformが、今日そして未来の最も困難な問題を解決するための最も貴重な資産の一つである地理空間プロダクトの可能性を最大限に引き出すためにどのように活用できるかについて議論します。
データプロダクトとは?そして、その設計方法とは?
「データプロダクト」の最も広範かつ簡潔な定義は、DJ Patil(初代米国首席データサイエンティスト)がData Jujitsu: The Art of Turning Data into Productの中で提唱した「データの利用を通じて最終目標を促進するプロダクト」です。この定義の複雑さ(Patil自身も認めているように)は、ダッシュボード、レポート、Excelスプレッドシート、さらにはメールで共有されるCSV抽出物など、考えられるプロダクトの広範な範囲を包含するために必要です。提供された例は、品質、堅牢性、ガバナンスの面で急速に劣化することにお気づきかもしれません。
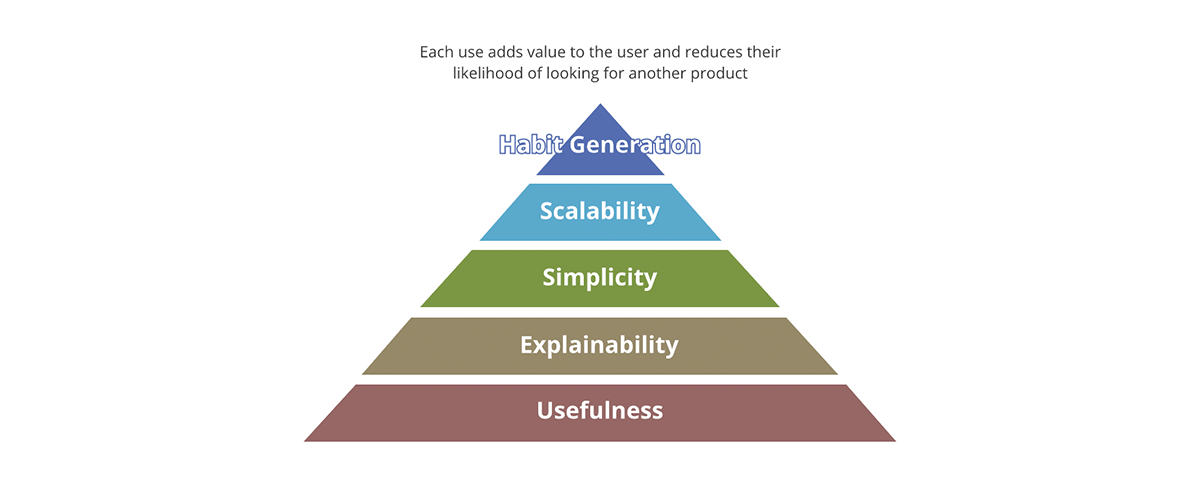
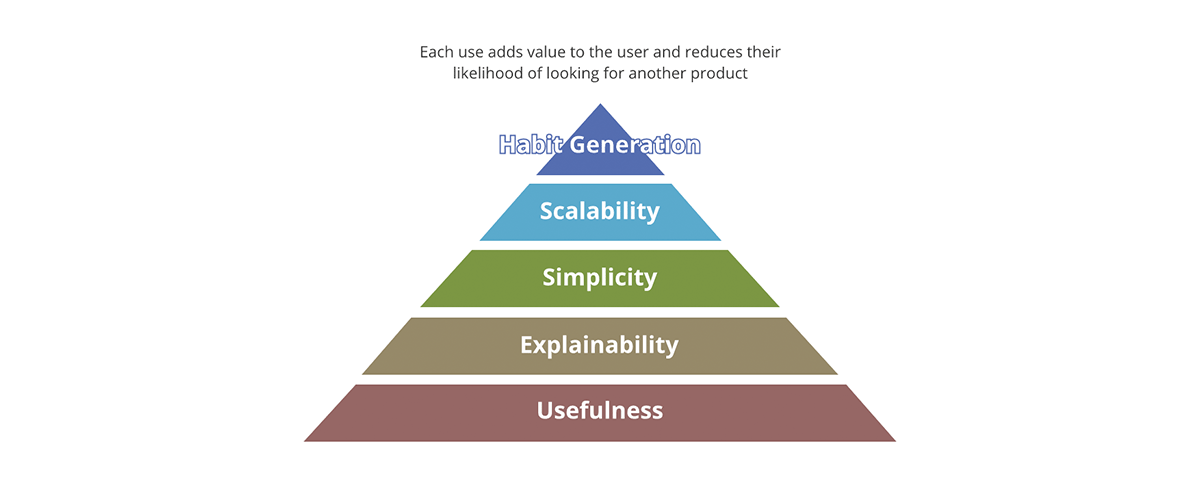
成功するプロダクトとそうでないプロダクトを区別する概念は何でしょうか?パッケージでしょうか��?コンテンツでしょうか?コンテンツの品質でしょうか?それとも市場でのプロダクトの採用率だけでしょうか?Forbesは、成功するプロダクトに不可欠な10の要素を定義しています。これを要約する良いフレームワークは、価値のピラミッドです。
{kind=link}
価値のピラミッドは、プロダクトの各側面に対する優先順位を示します。プロダクトについて尋ねるすべての価値に関する質問が同じ重みを持つわけではありません。出力が有用でなければ、他のどの側面も重要ではありません。その出力は真のプロダクトではなく、有用な結果のプールに対するデータ汚染物質となってしまいます。同様に、スケーラビリティはシンプルさと説明可能性が解決された後にのみ重要になります。
価値のピラミッドはデータプロダクトとどのように関連するのでしょうか?データプロダクトであるためには、各データ出力は以下の条件を満たす必要があります。
- 明確な有用性を持つべきです。社会が生み出すデータの量は、私たちが生み出すデータ汚染物質の量に匹敵します。これらは明確な価値と用途を欠き、それらをどうするかという戦略もほとんどない出力です。
- 説明可能であるべきです。AI/MLの出現により、データ駆動型の意思決定において説明可能性はさらに重要になっています。データは、それを記述するメタデータと同じくらい優れています。食品に例えるなら、味も重要ですが、より重要なのは食材の栄養価です。
- シンプルであるべきです。プロダクトの誤用の一例は、スプーンの代わりにフォークでシリアルを食べることです。さらに、シンプルさは不可欠ですが十分ではありません。シンプルさの先に、プロダクトは直感的であるべきです。可能な限り、データの意図された使用法と意図しない使用法の両方が明確であるべきです。
- スケーラブルであるべきです。データは、使用するにつれて増加する数少ないリソースの一つです。処理するデータが増えるほど、利用可能なデータも増えます。システムの入力と出力の両方が無限に増加し続ける場合、システムはコンピューティング能力、ストレージ容量、コンピューティング表現力の点でスケーラブルである必要があります。Databricksのようなクラウドデータプラットフォームは、これら3つの側面すべてに対応できる独自の立場にあります。
- 習慣を生成すべきです。データ領域では、小売プロダクトの場合のような顧客維持には関心がありません。しかし、ベストプラクティスに適用すれば、習慣生成の価値は明らかです。システムとデータ出力はベストプラクティスを示し、それを促進すべきです—データとシステムを意図された方法で使用する方が、そうでない場合よりも簡単であるべきです。
地理空間データは、前述のすべての側面に準拠すべきであり、あらゆるデータプロダクトも同様です。この高い要求に加えて、地理空間データにはいくつかの特定のニーズがあります。
地理空間データ標準
地理空間データ標準は、地理データが一貫性のある信頼できる方法で収集、整理、共有されることを保証するために使用されます。これらの標準には、データフォーマット、座標系、地図投影法、メタデータなどのガイドラインが含まれます。標準に準拠することで、異なる組織間でのデータ共有が容易になり、より大きなコラボレーションと地理情報への幅広いアクセスが可能になります。
The 地理空間委員会(英国政府)は、地理空間データに適用されるデータ標準の中央リポジトリとして英国地理空間データ標準登録簿を定義しています。さらに、この登録簿の使命は次のとおりです。
- 「英国の地理空間データが、より一貫性があり、整合性が取れており、幅広いシステムで利用可能であることを保証する。」 — これらの概念は、説明可能性、有用性、習慣生成(おそらく価値のピラミッドの他の側面も)の重要性を強調するものです。
- 「英国の地理空間コミュニティが、関連する標準および標準化団体との関与を深めることを支援する。」 — コミュニティ内での習慣生成は、標準の堅牢で重要な設計と同じくらい重要です。採用されなければ、標準は無意味です。
- 「政府の他の部門内で地理空間データ標準の理解と利用を促進する。」 — 価値のピラミッドは標準にも適用されます。遵守の容易さ(有用性/シンプルさ)、標準の目的(説明可能性/有用性)、採用(習慣生成)といった概念は、標準の価値生成にとって不可欠です。
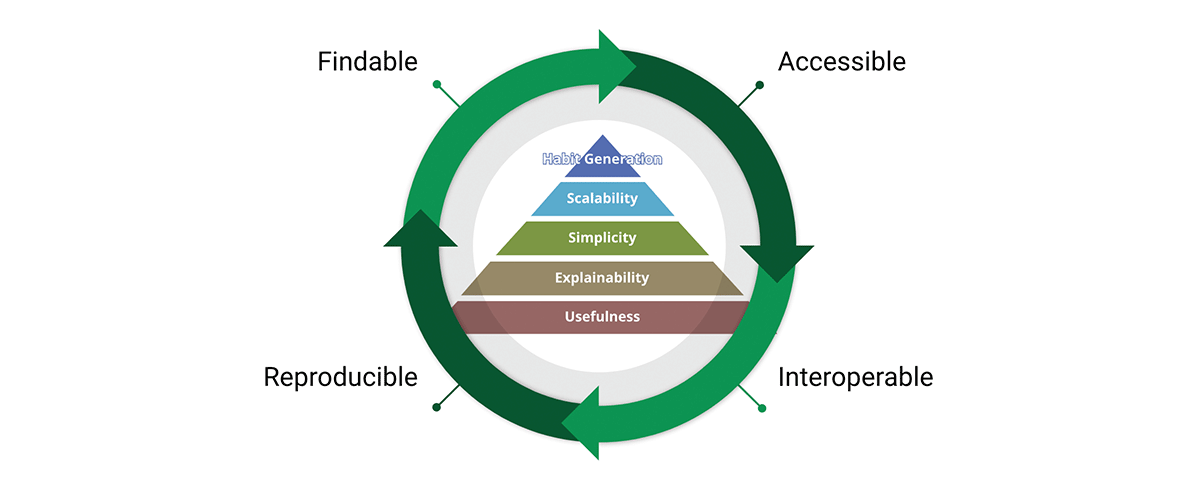
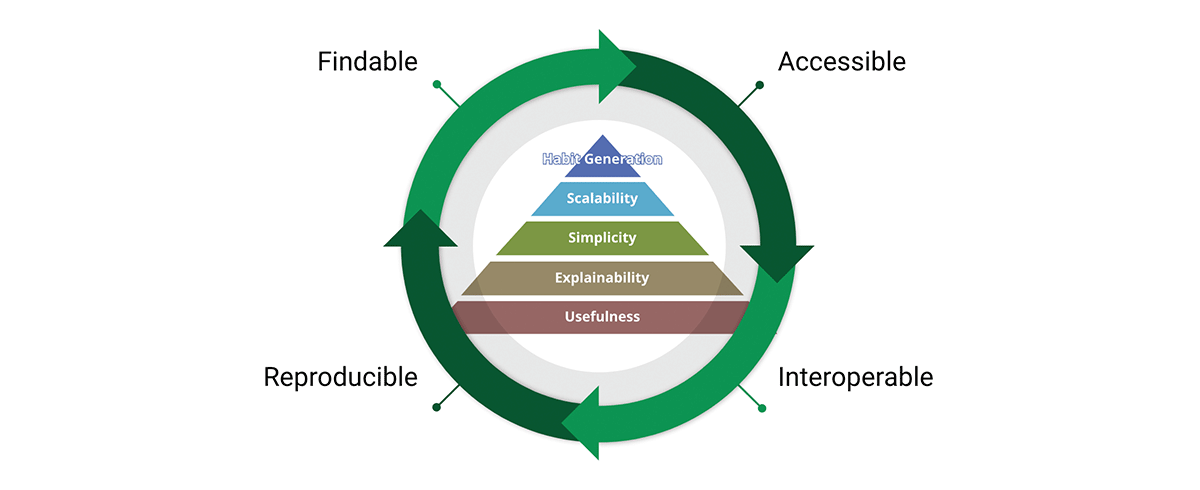
データ標準の使命を達成するための重要なツールは、FAIRデータ原則です。
- Findable(見つけやすい) - データを(再)利用する最初のステップは、それらを見つけることです。メタデータとデータは、人間とコンピューターの両方にとって見つけやすいものであるべきです。機械可読なメタデータは、データセットとサービスの自動発見に不可欠です。
- Accessible(アクセスしやすい) - ユーザーが必要なデータを見つけたら、認証や認可を含め、どのようにアクセスできるかを知る必要があります。
- 相互運用可能 - データは通常、他のデータと統合する必要があります。さらに、データは分析、保存、処理のためのアプリケーションやワークフローと相互運用できる必要があります。
- 再利用可能 - FAIRの究極の目標は、データの再利用を最適化することです。これを達成するために、メタデータとデータは、異なる設定で複製および/または結合できるように、適切に記述されるべきです。
私たちは、FAIR原則が信頼できるスケーラブルなデータ製品の設計にとって極めて重要であるという信念を共有しています。公平に言えば、FAIRは常識に基づいています。では、なぜそれが私たちの検討事項にとって重要なのでしょうか? "私がFAIRに見るのは、それ自体は新しいものではありませんが、データ改善への全体的なアプローチの必要性を、分かりやすい方法で明確に表現している点が優れています。このコミュニケーションの容易さこそが、FAIRがデータ改善の包括的な概念として、地理空間コミュニティだけでなく、ますます広く利用されている理由です。" - データ改善へのFAIRな追い風。
このアプローチをさらに支援するため、連邦地理データ委員会は、2021年から2024年までの期間をカバーし、2020年11月に承認された国家空間データインフラ(NSDI)戦略計画を策定しました。NSDIの目標は本質的にFAIR原則であり、共通の標準に従って組織間を流れるデータ製品、そしてデータサプライチェーンの各段階で新しい価値と機会を解き放つデータ循環経済を促進するシステムを設計するという同じメッセージを伝えています。これらの原則が異なる管轄区域に浸透し、さまざまな規制当局で採用されているという事実は、このアプローチの堅牢性と健全性の証です。

{kind=link}
FAIRの概念は、データ製品の設計と非常によく調和しています。実際、FAIRは製品価値ピラミッド全体を横断し、価値サイクルを形成します。価値ピラミッドとFAIR原則の両方を採用することで、私たちは内部と外部の両方の視点を持つデータ製品を設計します。これにより、データの蓄積ではなく、データの再利用が促進されます。
{kind=link}
地理空間データと地理空間データ製品にとって、FAIR原則が重要なのはなぜでしょうか? FAIRは地理空間データを超越しており、実際にはデータそのものを超越しています。それは、優れた設計のためのシンプルでありながら一貫性のある指針システムであり、その優れた設計は地理空間データや地理空間システムを含むあらゆるものに適用できます。
グリッドインデックスシステム
従来のGISソリューションでは、空間演算のパフォーマンスは通常、ツリー構造(KDツリー、ボールツリー、クアッドツリーなど)を構築することで実現されます。ツリーアプローチの問題点は、最終的にスケーラビリティの原則を破ってしまうことです。データが大きすぎてツリーを構築するために処理できなくなり、ツリー構築に必要な計算が長すぎて目的を達成できなくなるのです。これはデータのアクセシビリティにも悪影響を及ぼします。ツリーを構築できなければ完全なデータにアクセスできず、結果を再現することもできません。このような場合、グリッドインデックスシステムが解決策を提供します。
グリッドインデックスシステムは、地理空間データのスケーラビリティの側面を念頭に置いて最初から構築されています。ツリーを構築するのではなく、関心領域をカバーする一連のグリッドを定義します。H3(Uberが先駆者)の場合、グリッドは地球全体をカバーし、ローカルグリッドインデックスシステム(例:英国国家グリッド)の場合、特定の関心領域のみをカバーすることがあります。これらのグリッドは、一意の識別子を持つセルで構成されています。位置とグリッド��内のセルとの間には数学的な関係があります。これにより、グリッドインデックスシステムは非常にスケーラブルで本質的に並列処理が可能です。
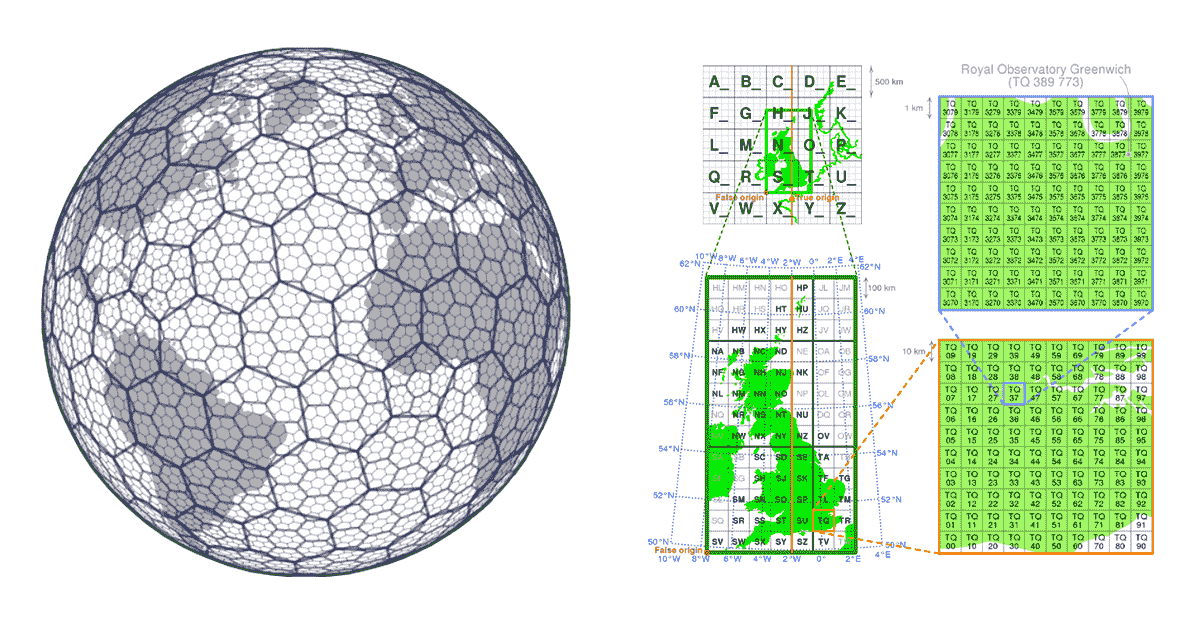
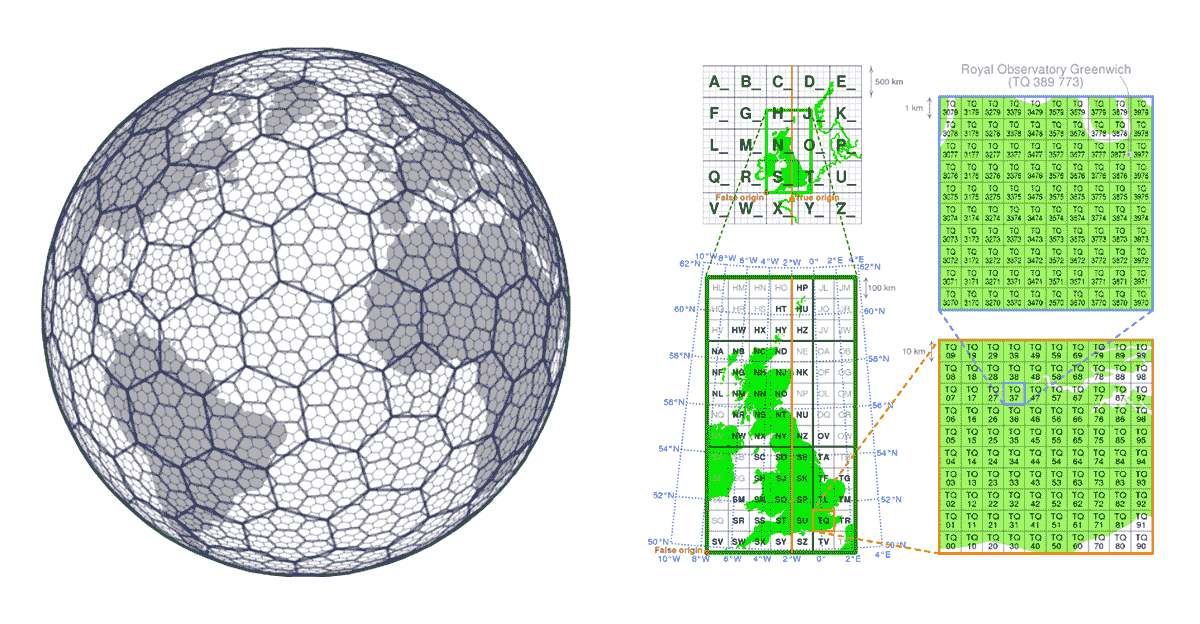{kind=link}
図4:グリッドインデックスシステム(H3、英国国家グリッド)">
グリッドインデックスシステムのもう一つの重要な側面は、オープンソースであることです。これにより、インデックス値はデータ生産者と消費者双方によって普遍的に活用できます。データは、データサプライチェーンを通じたその過程のどの段階でも、グリッドインデックス情報で強化できます。これにより、グリッドインデックスシステムはコミュニティ主導のデータ標準の一例となります。コミュニティ主導のデータ標準は、本質的に強制を必要とせず、価値ピラミッドの習慣形成の側面に完全に準拠し、FAIRの相互運用性とアクセシビリティの原則に有意義に対処します。
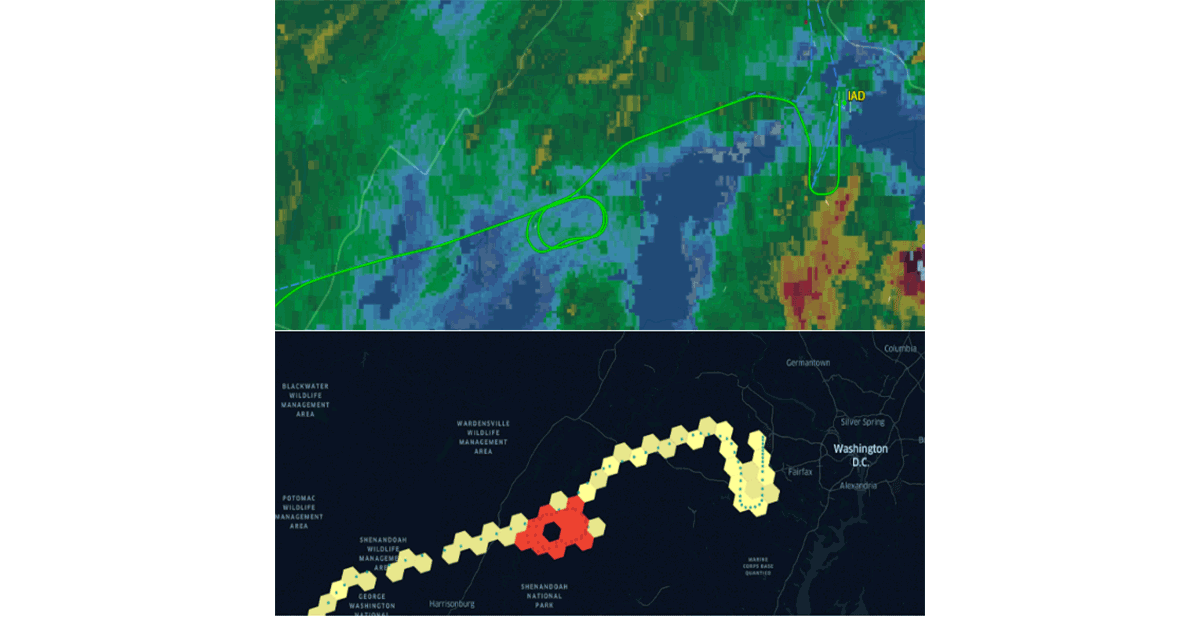
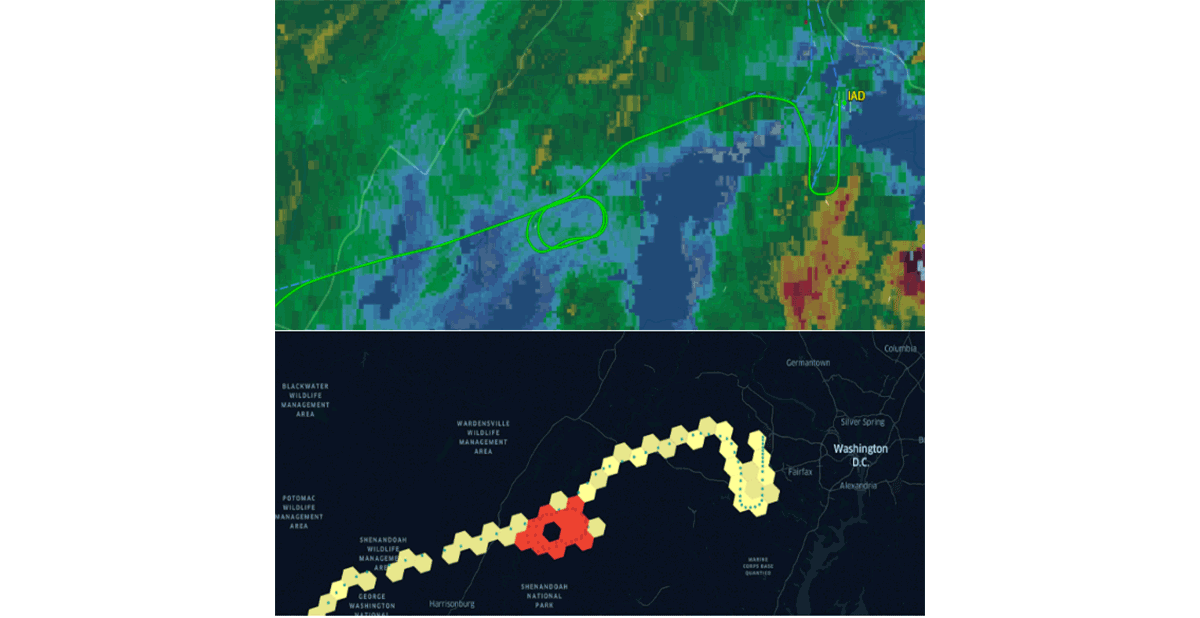{kind=link}
Databricksは最近、同じ価値提案に沿って、H3グリッドインデックスシステムのネイティブサポートを発表しました。コミュニティ主導の共通業界標準を採用することが、習慣形成と相互運用性を適切に推進する唯一の方法です。この主張を強化するため、CARTO、ESRI、Googleなどの組織は、スケーラブルなGISシステム設計のためのグリッドインデックスシステムの利用を推進してきました。さらに、Databricks LabsプロジェクトのMosaicは、英国政府で広く使用されている標準グリッドインデックスシステムとして英国国家グリッドをサポートしています。グリッドインデックスシステムは、地理空間データ処理のスケーラビリティと、複雑な問題(例:図5 - H3を使用した飛行待機パターン)に対するソリューションを適切に設計するために重要です。
地理空間データの多様性
地理空間データ標準は、データ形式の標準化に関して多大な努力を払っており、その形式は相互運用性と再現性に関して最も重要な考慮事項の一つです。さらに、データの読み取りが複雑である場合、どうしてシンプルさについて語れるでしょうか? 残念ながら、地理空間データ形式は通常複雑であり、データはオープンソースとベンダー固有の形式を含む多数の形式で生成される可能性があります。ベクターデータのみを考慮すると、データはWKT、WKB、GeoJSON、web CSV、CSV、Shape File、GeoPackageなど、多くの形式で提供されることが予想されます。一方、ラスターデータを考慮する場合、GeoTiff、netCDF、GRIB、GeoDatabaseなど、任意の数の形式でデータが提供されることが予想されます。形式の包括的なリストについては、このブログを参照してください。
地理空間データドメインは非常に多様であり、長年にわたり、それが対処してきたユースケースを中心に有機的に成長してきました。このような多様なエコシステムの統合は、非常に大きな課題です。Open Geospatial Consortium (OGC) による、Apache Parquet とその地理空間スキーマ仕様であるGeoParquet への標準化に向けた最近の取り組みは、正しい方向への一歩です。シンプルさは、優れたスケーラブルで堅牢な製品を設計する上での重要な側面の1つです。統合はシンプルさにつながり、エコシステムにおける摩擦の主な原因の1つであるデータ取り込みに対処します。GeoParquetへの標準化は、FAIRデータと価値ピラミッドのあらゆる側面に対処する多くの価値をもたらします。
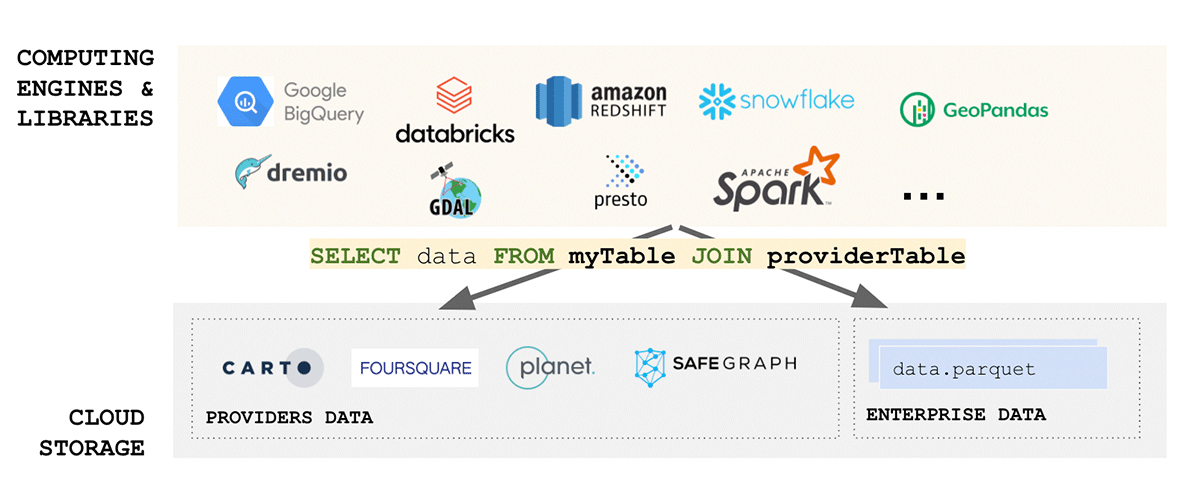
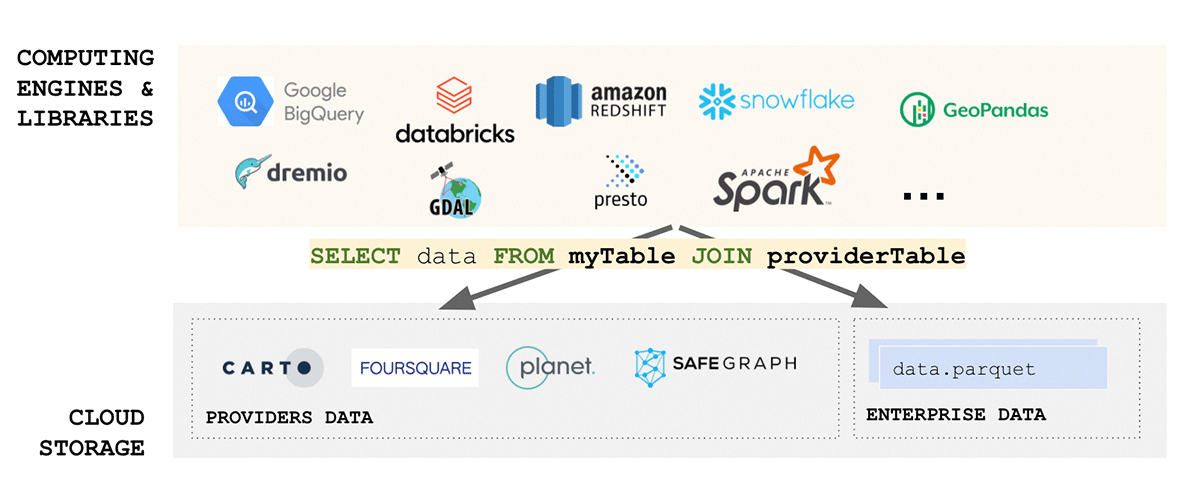{kind=link}
Figure 6: Geoparquet as a geospatial standard data format">
なぜ、すでに複雑なエコシステムに別のフォーマットを導入するのでしょうか?GeoParquetは新しいフォーマットではありません。これは、業界やコミュニティで広く採用され使用されているApache Parquetフォーマットのスキーマ仕様です。ベースフォーマットとしてのParquetは、バイナリ列をサポートし、任意のデータペイロードの保存を可能にします。同時に、このフォーマット��は、データペイロードとともにメタデータを保存できる構造化データ列もサポートしています。これにより、相互運用性と再現性を促進する選択肢となります。最後に、Delta Lake フォーマットはParquetの上に構築されており、ACID特性をもたらします。フォーマットのACID特性は、再現性と信頼できる出力のために不可欠です。さらに、Deltaはスケーラブルなデータ共有ソリューションであるDelta Sharingで使用されるフォーマットです。Delta Sharingは、Databricksを使用して任意のパブリッククラウド間でエンタープライズ規模のデータ共有を可能にします(プライベートクラウド向けのDIYオプションは、オープンソースの構成要素を使用して利用可能です)。Delta Sharingは、データを他のサードパーティに公開するためのカスタム構築されたRest APIsの必要性を完全に抽象化します。Deltaに保存されたデータ資産(GeoParquetスキーマを使用)は、自動的にデータ製品となり、管理された統制された方法で外部の関係者に公開できます。Delta Sharingは、セキュリティのベストプラクティスを念頭に置いてゼロから構築されています。
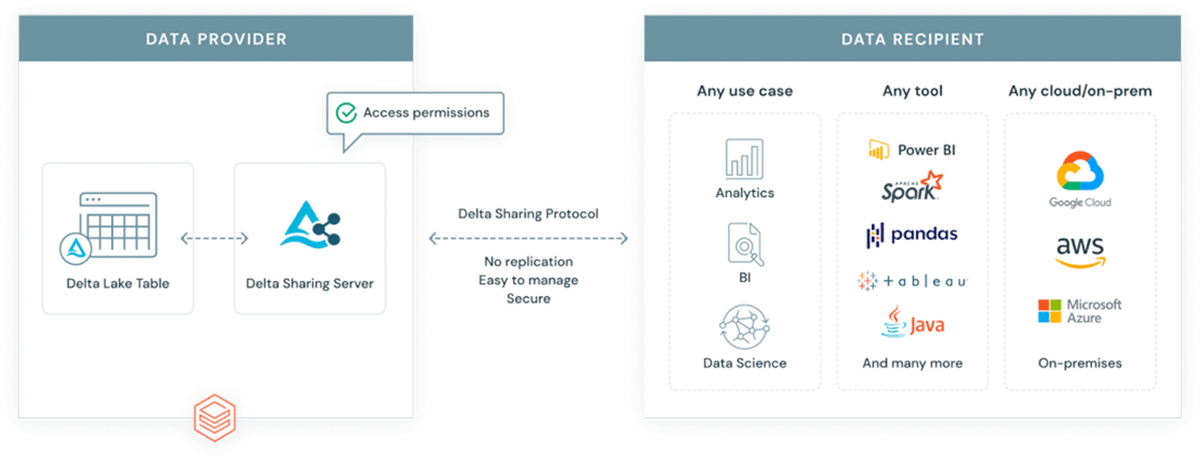
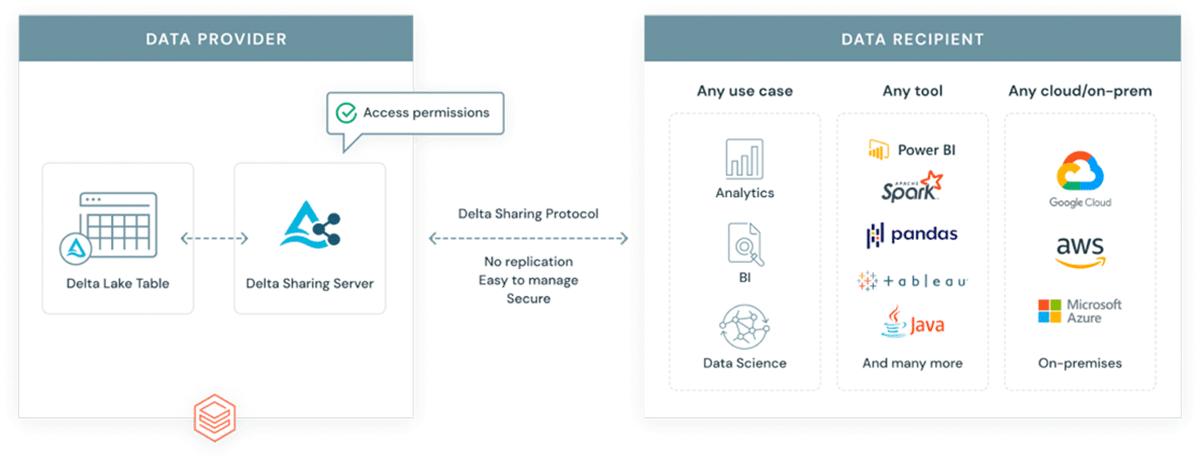{kind=link}
Figure 7: Delta sharing simplifying data access in the ecosystem">
循環型データエコノミー
サステナビリティの領域から概念を借りると、循環型データエコノミーとは、データの価値を最大化しつつ、不必要な計算時間、信頼できない洞察、データ汚染物質に基づく偏った行動などの無駄や負の影響を最小限に抑える方法でデータが収集、共有、使用されるシステムとして定義できます。この考慮事項における重要な概念は再利用性であり、「車輪の再発明」をいかに最小限に抑えるかです。世の中には、同じ領域、同じ概念を表す無数のデータ資産が存在し、特定のユースケースにより良く適合させるためにわずかな変更が加えられているだけです。これは実際の最適化によるものなのか、それとも既存の資産を再利用するよりも新しいコピーを作成する方が簡単だったためなのか?あるいは、既存のデータ資産を見つけるのが難しすぎたのか、あるいはデータアクセスパターンを定義するのが複雑すぎたのか?
データ資産の重複は、FAIRの考慮事項とデータ価値ピラミッドの考慮事項の両方において多くの負の側面を持っています。同じ領域と同じ概念を表す多く��の異種で類似した(しかし異なる)データ資産が存在すると、データドメインのシンプルさの考慮事項を損なう可能性があります。つまり、実際に信頼できるデータ資産を特定することが困難になります。また、習慣の生成に対しても非常に負の影響を与える可能性があります。多くのニッチなコミュニティが出現し、より広範なエコシステムのベストプラクティスを無視して独自の標準を確立したり、さらに悪いことに、まったく標準化しないこともあります。
循環型データエコノミーでは、データは新しい製品やサービスを作成したり、既存のものを改善したりするために使用できる貴重なリソースとして扱われます。このアプローチは、データを使い捨ての商品として扱うのではなく、データの再利用とリサイクルを促進します。ここでも、サステナビリティのアナロジーを文字通りの意味で使用しています。私たちは、これが問題に取り組む正しい方法であると主張します。データ汚染物質は、組織にとって内部的にも外部的にも現実の課題です。The Guardianの記事によると、収集されたデータの1%未満しか実際に分析されていません。データ重複が多すぎ、データの大部分はアクセスが困難であり、実際の価値を引き出すのは煩雑すぎます。循環型データエコノミーは、ベストプラクティスと既存のデータ資産の再利用を促進し、より広範なデータエコシステム全体で一貫した解釈と洞察を可能にします。
{kind=link}
Figure 8: Databricks marketplace">
相互運用性はFAIRデータ原則の重要な要素であり、相互運用性から循環性の問題が浮上します。データ利用とデータ再利用を最大化するエコシステムをどのように設計できるでしょうか?ここでも、FAIRと価値ピラミッドが答えを握っています。データの見つけやすさは、データの再利用とデータ汚染の解決の鍵となります。容易に発見できるデータ資産があれば、わずかな変更を加えるだけで同じデータ資産が複数の場所で再作成されるのを避けることができ、代わりに、簡単に結合して再利用できるデータを持つ一貫したデータエコシステムを構築できます。Databricksは最近、Databricks Marketplaceを発表しました。このマーケットプレイスの背後にあるアイデアは、DJ Patelによるデータ製品の元の定義と一致しています。このマーケットプレイスは、データセット、ノートブック、ダッシュボード、機械学習モデルの共有をサポートします。このようなマーケットプレイスの重要な構成要素は、Delta Sharingの概念です。これは、地理空間データを含むあらゆるデータを共有するためのスケーラブルで柔軟かつ堅牢なチャネルです。
Marketplaceに存在するスケーラブルなデータ製品を設計することは非常に重要です。各データ製品の付加価値を最大化するためには、FAIR原則と製品価値ピラミッドを強く考慮する必要があります。これらの指針となる原則がなければ、現在のシステムにすでに存在する問題を増やすだけです。各データ製品は、独自の課題を解決し、それをシンプルで再現性があり、堅牢な方法で解決する必要があります。
Databricks Lakehouse Platformがデータ製品からの価値創出までの時間をどのように短縮できるかについては、eBook「データ共有への新しいアプローチ」で詳しく読むことができます。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。