レイクハウス探訪 - Databricksの全貌に迫る
によって Takaaki Yayoi による投稿
本稿では、Databricksレイクハウスの構成要素を紐解き、それぞれが担う役割や提供機能にディープダイブする。
レイクハウスとは
こちらの記事でも触れているように、レイクハウスはこれまでのデータプラットフォームの課題を解決するために、データウェアハウスとデータレイクの長所を組み合わせた新たなデータプラットフォームである。以下の図に示しているように、レイクハウスではテーブルなどの構造化データ、ログやJSONのような半構造化データ、さらには、画像・音声・テキストのような非構造化データすべてを格納することができ、データウェアハウスを活用して行われていたBIや、データレイクの主なユースケースであるデータサイエンスや機械学習の取り組みなどをすべて一つのプラットフォームで実施することできる。

以降では、Databricksでこのような機能をどのように実現し��ているのかを説明していく。
レイクハウスのアーキテクチャ
ハイレベルなレイクハウスのアーキテクチャ図を以下に示す。一番上にあるグリーンの箱は、ユースケースあるいはペルソナである。このように、データ×AIという取り組みにおいて、考えつくであろうすべてのユースケースをカバーしているのがレイクハウスの特徴の一つである。
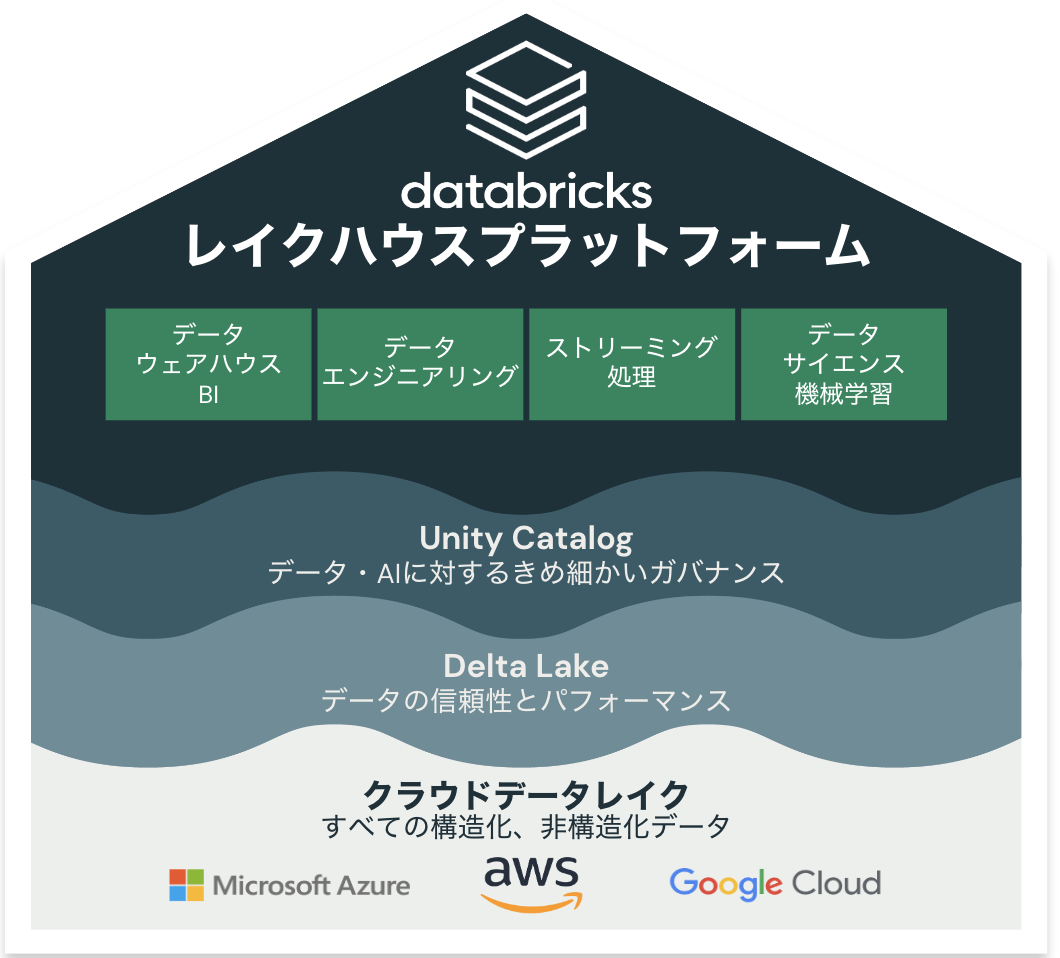
そして、レイクハウスにおいては、データをオープンなデータレイクに格納することでデータの種類やサイズを問わずそのままの状態で保持することが可能である。これによってベンダーロックインを回避できることに加え、将来的に取り組むであろうユースケースに備えて柔軟にデータを蓄積することが可能となる。
しかし、データレイクには上述の長所がある一方で、以前の記事でも触れたようにデータ品質やパフォーマンスの課題がある。どのようなデータを格納できたとしても、そのままではゴミだらけになってしまう。このため、従来のデータレイクはデータスワンプ(沼)と揶揄されることもあった。
レイクハウスでは、この課題を解決するための様々な仕組みが導入されている。これが上の図のUnity CatalogやDelta Lakeであるが、詳細は次節で説明する。
レイクハウスの構成要素
Databricksのレイクハウスプラットフォームは、いくつかのコンポーネントを軸としてデータ×AIの取り組みを効率的に進めるためのマネージドサービスを提供している。ここでは、データレイクをベースとした各種分析ワークロードで活用するコンポーネントにフォーカスして説明する。より包括的な説明についてはDatabricksのサイトを参照願いたい。
レイクハウスにおいてはデータはデータレイクに格納されるのは上述の通りである。そして、データレイクにおけるデータ品質やパフォーマンスの課題を解決するのがDelta LakeとUnity Catalogである。Delta LakeはDatabricksレイクハウスアーキテクチャの鍵となるコンポーネントである。Delta LakeはParquetをベースとしたオープンソースのストレージレイヤーソフトウェアであり、堅牢性、パフォーマンス、バージョン管理、トランザクション保証のような高度な機能を提供している。これによって、データレイクにデータを格納しつつも、データウェアハウスのような堅牢性やパフォーマンスを達成することが可能となる。そして、Unity Catalogはレイクハウスにガバナンスをもたらすソリューションであり、レイクハウスで管理されるファイル、データベース、テーブルなどのデータ資産のメタデータ、セキュリティの一元管理を可能にしている。この他、Unity Catalogではデータリネージ(データの依存関係)を自動でキャプチャする機能やデータ資産を検索する機能、社内外でデータをセキュアに共有する機能を備えており、レイクハウスにおけるデータ活用を促進する助けとなるものである。

このように、データ品質が担保され、ガバナンスが行き届いたデータレイク(我々はこれをキュレーテッドデータレイクと呼んでいる)を活用することで、様々なペルソナがレイクハウスを活用できるようになる。
そして、データサイエンティスト、データエンジニア、ビジネスアナリストのようなペルソナがレイクハウスを活用する際に重要になる側面が「セルフサービス」である。従来型のオンプレミスのプラットフォームを活用する際には、データ活用部門とIT部門との連携が不可欠であり、計算リソースや必要なソフトウェアを確保するだけで数ヶ月のリードタイムを要してしまうということはよくある話である。
Databricksレイクハウスの設計思想の一つに「データ×AIの民主化」というものがある。これは、スキルセットや習熟度に関係なく様々な人々がデータやAIを活用できるべきであるというものであり、Databricksレイクハウスではそのための機能も数多く提供している。
まず、これらのペルソナはブラウザ経由でDatabricksワークスペースにアクセスして各種の作業を行う。ワークスペースではノートブック��を活用することで、データエンジニアリング、機械学習、BIなどを統一的なインタフェースを通じて実施することができ、生産性高く作業を進めることができる。各ペルソナがどのように連携してレイクハウスを活用するのかについては、こちらの記事を参照願いたい。

また、各種作業で取り扱うデータ量、求められる処理時間や処理内容に応じて、必要なソフトウェアが事前インストールされている計算資源であるDatabricksクラスターをセルフサービスで簡単に設定・起動することができる。また、DatabricksレイクハウスではマネージドサービスのMLflowがインテグレーションされているので、ノートブックでトレーニングした機械学習モデルを容易にトラッキング・管理することが可能となっている。
このように、レイクハウスを活用することで多くの人々が自分が行いたいことに自由かつ迅速に取り込めることができるのであるが、そこにはコスト管理やアクセス管理など管理の側面にも注意を払わなくてはならない。Databricksレイクハウスでは、アクセスコントロールやクラスター作成ポリシーの定義、コスト監視や監査ログなどプラットフォーム全体にセキュリティやガバナンスを行き渡らせるための機能も数多く提供している。これによって、企業においては自由度やスピードとセキュリティ・ガバナンスのトレードオフを考慮しながら最適な運用を行うことが可能となっている。
まとめ
本稿では主要な構成要素にフォーカスしてレイクハウスを説明したが、Databricksはこれ以外にも数多くの機能を提供しているので、興味がある方はこちらを参照願いたい。
Databricksレイクハウスを活用し、以下のようなリファレンスアーキテクチャを構築することで、データの種類、流入形態を問わないキュレーテッドデータレイクを構築し、メダリオンアーキテクチャを実装することで、データサイエンス、データエンジニアリング、BIすべてのユースケースで最新かつ高品質なデータを活用できるようになるのがレイクハウスの大きなメリットである。

最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。