MLflow 2.3の紹介:LLMのネイティブサポートと新機能による強化
によって Ben Wilson, Harutaka Kawamura, リャン・チャン, Corey Zumar, Jin Zhang 、 Sunish Sheth による投稿
Introducing MLflow 2.3: Enhanced with Native LLM Support and New Features
翻訳: junichi.maruyama
MLflowは月間 1,300 万ダウンロードを超え、エンドツーエンドの MLOps の主要なプラットフォームとしての地位を確立しており、あらゆる規模のチームがバッチおよびリアルタイム推論用のモデルを追跡、共有、パッケージ化、およびデプロイできるようにしました。MLflowは、何千もの組織で日々採用され、多様な��プロダクション機械学習アプリケーションを推進しており、産業界と学界から500人以上の貢献者からなる活発なコミュニティによって活発に開発されています。
今日、私たちはこのオープンソースの機械学習プラットフォームの最新版であるMLflow 2.3を発表することができ、大規模言語モデル(LLM)の管理・導入能力を向上させる革新的な機能が満載されていることに興奮しています。この強化されたLLMサポートは、以下のような形で提供されます:
3つの新しいモデルフレーバー:Hugging Face Transformers、OpenAI関数、LangChain。
モデルファイルのマルチパートダウンロード・アップロードにより、クラウドサービスとの間でモデルのダウンロード・アップロード速度を大幅に向上。
Hugging Face transformers対応
"MLflowにおけるHugging Faceトランスフォーマーライブラリのネイティブサポートは、AIのための最大のコミュニティとオープンプラットフォームであるHugging Face Hubで利用できる17万以上の無料かつ一般公開された機械学習モデルとの連携を容易にします。" - Hugging Face プロダクトディレクター Jeff Boudier氏
新しい transformers フレーバーは、transformers パイプライン、モデル、および処理コンポーネントを MLflow トラッキング サービスにネイティ�ブに統合するものです。この新しいフレーバーでは、共通の MLflow トラッキング インターフェイスを介して、 Dollyを含む完全に構成されたトランスフォーマーpipeline またはベースモデルを保存または記録することができます。これらのログされた成果物は、コンポーネントのコレクション、パイプライン、またはpyfuncを介してネイティブにロードすることができます。
transformers フレーバーでコンポーネントやパイプラインを記録する場合、多くの検証が自動的に実行され、保存したパイプラインやモデルがデプロイ可能な推論と互換性があることを保証しています。検証に加えて、貴重なモデルカードデータが自動的に取得され、保存されたモデルやパイプラインアーティファクトに追加されます。これらのモデルやパイプラインの使い勝手を向上させるために、デプロイのプロセスを簡略化するモデルシグネチャ(signature)推論機能が搭載されています。
Hugging Face HubでホストされているDollyのようなオープンソースの大規模言語モデルとの統合は、次のように簡単です:
Hugging Faceトランスフォーマーと新しいMLflowの統合により、以下のようにpyfuncバージョンのモデルを軽量なチャットボットのインターフェイスとして使用することも可能です。
MLflowのトランスフォーマーは、signatureスキーマの自動検出とパイプライン固有の入力フォーマットの受け渡しをサポートしています。
トランスフォーマーパイプラインからロードされたpyfuncモデルの使用は、以下に示すように、基礎となるパイプラインのインターフェイスを維持することを目的としています:
トランスフォーマーパッケージがサポートする各パイプラインタイプについてメタデータが収集されます。それは正確な要件、コンポーネントのバージョン、および参照情報が、将来の参照と保存したモデルのサービングの両方に利用されるるためです。入力シグネチャが明示的に宣言されていない場合でも、ロギング中に提供された代表的な入力例に基づいてシグネチャが推論されます。
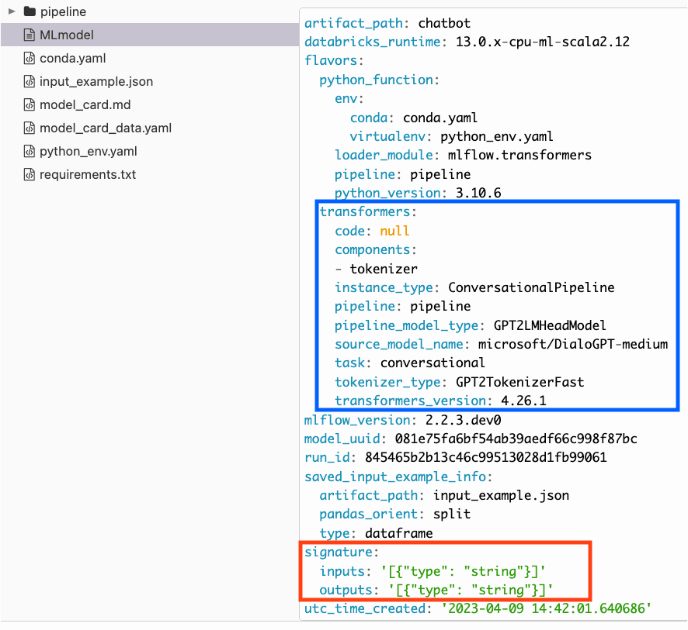
さらにMLflow トランスフォーマーのフレーバーは、モデルやパイプラインの保存やロギング時に、Hugging Face Hub からモデルカードの状態を自動的に引き出します。この機能により、一般的な参照と監査の両方の目的で、基礎となるモデル情報の状態をポイントインタイムで参照することができます。

transformers フレーバーの追加により、非常に広く使用され人気のあるパッケージは、現在MLflowでファーストクラスのサポートを得ています。MLflowで再トレーニングされ、ログに記録されたパイプラインは、簡単にHugging Face Repository,に戻すことができ、他の人が複雑なテキストベースの問題を解決するための新しいモデルアーキテクチャを使用し利益を得ることができます。
関数ベースの味付けでOpenAI APIをサポート
OpenAI Python libraryは、Python言語で書かれたアプリケーションから、OpenAI APIへの便利なアクセスを提供します。このライブラリには、OpenAI APIリソースに対応する定義済みのクラスが含まれています。これらの提供されたクラスを使用することで、OpenAI APIの幅広いモデルバージョンとエンドポイントからの接続、データの受け渡し、および応答の取得を動的に初期化します。
MLflow OpenAIフレーバーは以下をサポートします:
- シグネチャスキーマの自動検出
- APIリクエストの並列化により、推論を高速化
- レートリミットエラーなどの一時的なエラーに対して�、APIリクエストを自動的にリトライする
以下は `openai.ChatCompletion` モデルをロギングし、推論のためにロードバックする例です:
MLflow 2.3では、カスタムモデルのロギングを容易にするために、モデルとしての関数のロギングと型アノテーションからのシグネチャの自動検出をサポートしています。以下は、OpenAIのチャットコンプリートモデルをロギングする例です。
MLflowでOpenAIのフレーバーを利用することで、MLflowのトラッキングとデプロイ機能を活用しながら、OpenAIがホストする事前学習済みモデルをフル活用することができます。
OpenAI APIキーは環境変数で管理し、実行パラメータやタグとしてログに記録しないことを忘れないでください。Databricksでは、 Databricks Secret Management を経由して、以下のようにキー名「openai_api_key」を持つ希望のスコープにAPIキーを追加することができます。MLflowは、OpenAI風味のモデルがエンドポイントで提供される際に、Databricks Secretストアからシークレットキーを自動的にフェッチします。
シークレットスコープ名は、環境変数 MLFLOW_OPENAI_SECRET_SCOPE で指定することができます。
LangChain サポート
MLflowのLangChainフレーバーは、質問応答システムやチャットボットなど、LLMベースのアプリケーションの構築とデプロイのプロセスを簡素化します。LangChainの高度な機能を、MLflowの合理化された開発およびデプロイメントサポートで活用できるようになりました。
ここでは、LangChainのネイティブフレーバーとしてLLMChain(英仏翻訳)を記録し、Sparkを使って英文のバッチ翻訳を実行する例を紹介します:
Spark UDFで分散バッチ推論を行うためにLangChainモデルをロードします:
これはLangChainフレーバーの初期リリースであり、モデルのロギングがLLMChainに限定されていることに注意してください。エージェントロギングやその他のロギング機能は現在進行中で、今後のMLflowリリースで追加される予定です。
MLflow 2.3を使ってみよう
本日、MLflow 2.3 をお試しください!アップグレードしてLLMをサポートする新機能を使用するには、以下のコマンドを使用してPython MLflow libraryをインストールするだけです:
MLflow 2.3 の新機能と改良点の完全なリストは、リリースの変更履歴を参照してください。MLflow を使い始める方法、および MLflow 2.3 で導入された LLM ベースの新機能の完全なドキュメントについては、MLflow ドキュメントを参照してください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。