異常検知でエネルギーロスを未然に防ぐ
によって Ashley Johnson 、 デビッド・ラドフォード による投稿
Original Blog : Anomaly Detection to Prevent Energy Loss
翻訳: junichi.maruyama
電力会社におけるエネルギー損�失は、主に不正と漏電の2つに分類されます。不正(またはエネルギー窃盗)は悪意があり、メーターの改ざん、隣家への盗聴、さらには住宅地での商用負荷(栽培ハウスなど)の実行など、さまざまな可能性があります。メーターの改ざんは、従来は担当者が手作業でチェックしていましたが、最近のコンピュータビジョンの進歩により、ライダーやドローンを使ってチェックを自動化することができます。
エネルギー漏れは、通常、配管の破損など物理的な漏れを指すことが多いですが、より顕著な問題を含んでいることもあります。例えば、ヒートポンプ式の住宅では、冬に窓を開けっ放しにしておくと、異常なエネルギー消費を引き起こすことがあります。消費者をコスト上昇から守り、エネルギーを節約するためには、このような状況に対応する必要がありますが、人間優先のアプローチでは、エネルギー損失を正確に特定することは困難です。本記事では、Databricksの機械学習手法を活用した科学的アプローチにより、すぐに使える分散コンピューティング、組み込みのオーケストレーション、エンドツーエンドのMLOpsで、この問題にスケールアップして取り組みます。
エネルギーロスを大規模に検出する
多くの電力会社がエネルギー損失を検出する取り組みで最初に直面する問題は、正確にラベル付けされたデータがないことである。顧客からの自己申告に依存するため、いくつかの問題が発生する。まず、消費者が漏電に全く気づかない場合があります。例えば、小さなガス漏れや、旅行中にドアが割れたままになっていたなど、ガスの臭いが十分に目立たない場合があります。第��二に、不正の場合、過剰な使用量を報告するインセンティブがないことである。天候や家の大きさなどを考慮して異常値を検証する必要があるため、単純な集計で盗難を見抜くのは難しい。さらに、すべての報告を調査するためのマンパワーが必要であり、その多くは誤報であるため、組織にとって負担となる。このようなハードルを乗り越えるために、電力会社はデータを活用し、機械学習による科学的アプローチでエネルギー損失を検出することができます。
エネルギー損失検出のための段階的アプローチ
上記のように、自己申告データに依存することは、一貫性のない不正確な結果を招き、電力会社が正確な監視モデルを構築することを妨げる。その代わりに、「報告して調査する」という消極的なアプローチではなく、積極的なデータファーストのアプローチを取るべきである。このようなデータファーストのアプローチは、教師なし、教師あり、メンテナンスの3つのフェーズに分けることができる。教師なしアプローチから始めると、訓練データなしで異常を検出することにより、ラベル付きデータセットを生成するポインテッドベリフィケーションが可能になる。次に、教師なしステップの出力を、ラベル付きデータを使用して汎用的で堅牢なモデルを構築する教師ありトレーニングステップに供給することができます。ガスや電気の使用パターンは、消費と盗難のパターンによって変化するため、教師ありモデルは時間の経過とともに精度が低下していきます。これに対処するため、教師なしモデルは、教師ありモデルに対するチェックとして実行し続ける。これを説明するために、1時�間ごとの検針と気象データを組み合わせた電気メーターのデータセットを利用して、エネルギー損失検出を行うための大まかな枠組みを構築します。


教師なしフェーズ
この最初の段階は、潜在的な損失を調査・検証するためのガイドとして機能し、ランダムな検査よりも正確であるべきです。ここでの主な目標は、監視フェーズに正確な情報を提供することであり、短期的な目標は、このラベル付きデータを取得するための運用オーバーヘッドを削減することである。理想的には、住宅のサイズ、階数、築年数、家電製品情報など、できるだけ多様性のある母集団のサブセットからこの演習を開始する必要があります。これらの要素は、この段階では特徴として使用されないが、次の段階でより堅牢な教師ありモデルを構築する際に重要となる。
教師なしアプローチでは、メーターレベルで異常を特定するために、さまざまな技術を組み合わせて使用します。単一のアルゴリズムに依存するのではなく、アンサンブル(またはモデルの集合体)を使用してコンセンサスを開発することがより強力になる可能性があります。単純な統計から深層学習アルゴリズムまで、異常の特定に有用なモデルや方程式があらかじめ数多く�存在します。この演習では、The Isolation forest、ローカル外れ値、およびZスコア測定の3つの方法が選択されました。
zスコアの式は非常に単純で、計算も極めて軽量です。ある値からすべての値の平均を引き、それを標準偏差で割るというシンプルなものです。この場合、値はビルの1つの検針票を表し、平均はそのビルのすべての検針票の平均となり、標準偏差も同様である。
z = ( x - μ ) / σ
もしスコアが3以上であれば、それは異常とみなされます。これは、値を素早く確認するための精度の高い方法ですが、この方法だけでは、天候や時間帯など他の要因を考慮することはできません。
The Isolation forest (iForest)モデルは、異常なポイントが最短のトラバーサルパスを持つThe Isolation forestのアンサンブルを構築します。
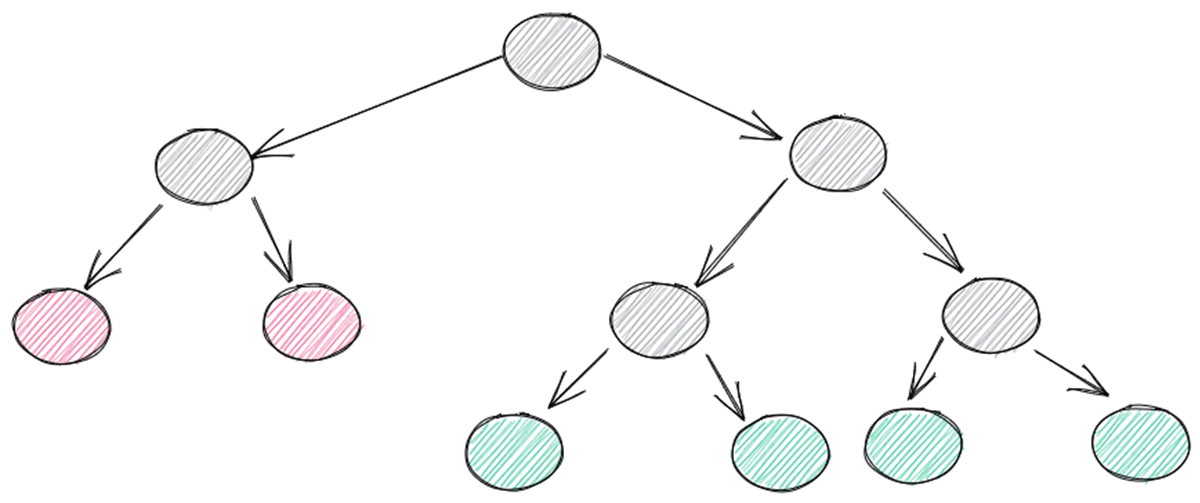
このアプローチの利点は、多次元データを使用できることで、予測精度を高めることができることです。この追加されたオーバーヘッドは、単純なZスコアの約2倍の実行時間に相当します。ハイパーパラメーターは非常に少ないので、チューニングは最小限に抑えられます。
ローカル・アウトライア・ファクター(LOF)モデルは、ローカル・クラスターの密度(またはポイント間の距離)を、その近隣のクラスターの密度と比較して、アウトライアを判定するものである。
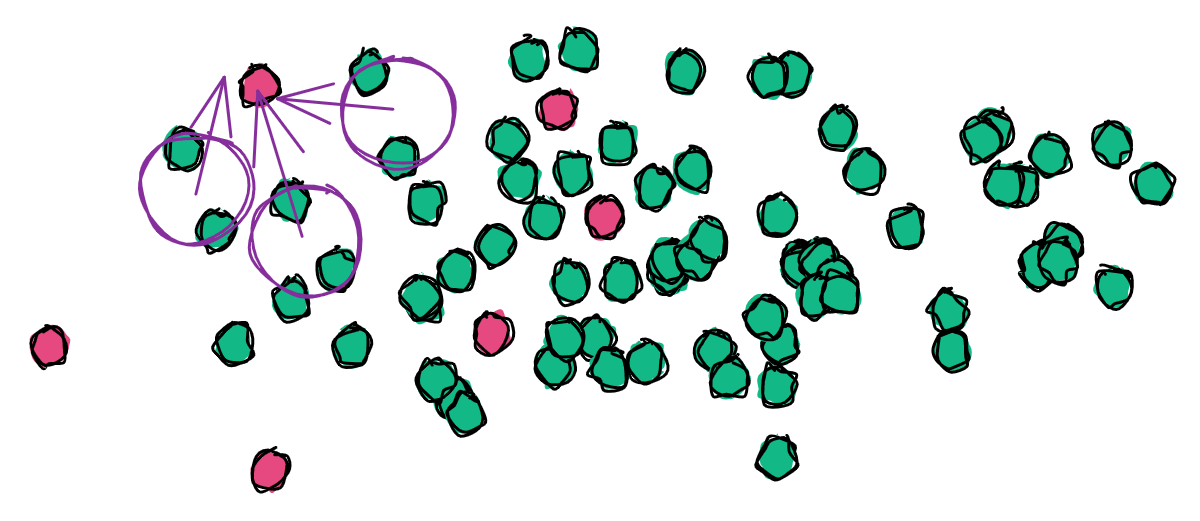
LOFはiForestとほぼ同じ計算量ですが、グローバルな異常ではなく、局所的な異常の検出においてより堅牢です。
これらのアルゴリズムの実装は、z-scoreの場合は組み込みのSQL関数、scikit-learnの場合はpandas UDFを使用して、クラスタ上でスケールします。各モデルは、居住者の習慣などの未知の変数を考慮するため、個々のメーターレベルで適用されます。
Z-score は、上記で紹介した数式を使用し、スコアが 3 より大きい場合、レコードを異常としてマークします。
iForestとLOFは、多次元モデルであるため、どちらも同じ入力を使用します。いくつかの主要な特徴を使用することで、最良の結果を得ることができます。この例では、構造的な特徴は、与えられたメーターに対して静的なものであるため、無視されています。その代わりに、気温に焦点が当てられています。
これはグループ化され、分散処理のためにpandas UDFに渡されます。どのモデルが使われたかを示すためと、一意のアンサンブル識別子を保存するために、いくつかのメタデータカラムが結果に追加されます。
その後、Databricks Workflowsを使用して3つのモデルを並列に実行することができます。タスク値は、コンセンサスがワークフローの同じ実行からデータを照会できるように、共有アンサンブル識別子を生成するために使用されます。コンセンサスステップ��では、3つのモデルに対して単純な多数決を行い、異常か否かを判断します。
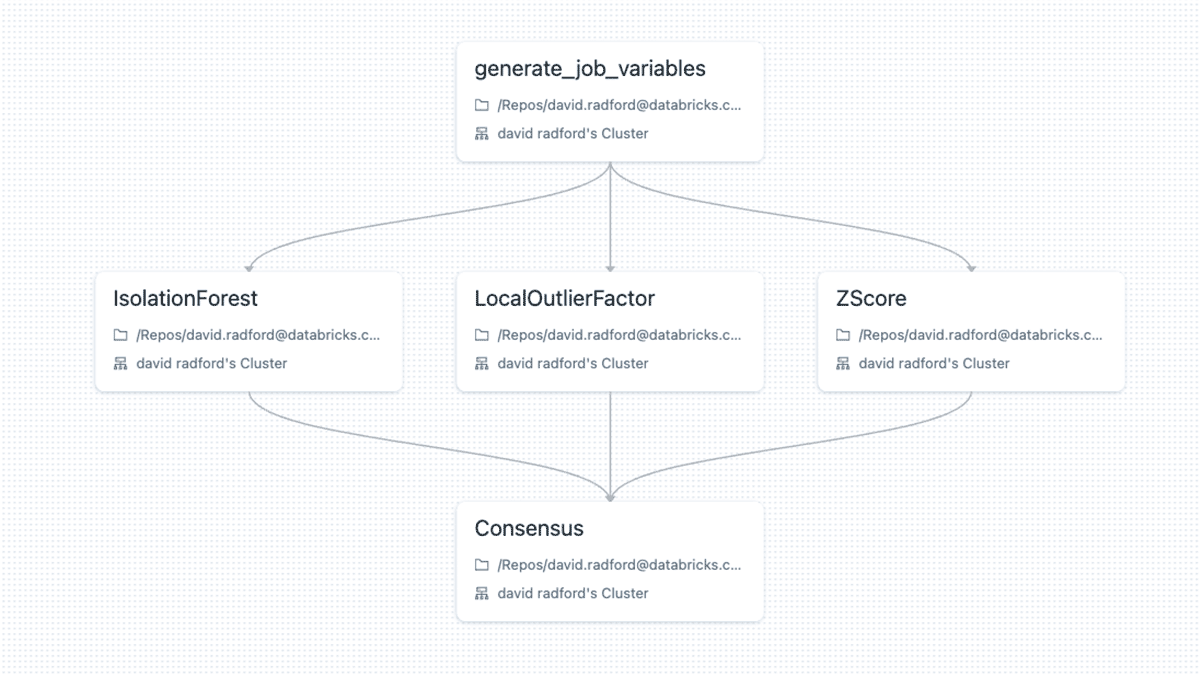
モデルは1日(あるいは1時間)間隔で実行し、潜在的なエネルギー損失を特定します。それは出来るだけ問題がなくなったり、顧客が忘れたり(例:先週、窓を開けっ放したか覚えていない)する前に検証する必要があります。すべての異常を調査し、正常値のランダム(あるいはセミランダム)セットも日常的に検査して、異常が抜け落ちていないことを確認すべきです。数ヶ月の繰り返しが行われた後、適切にラベル付けされたデータを教師ありモデルに送り込み、トレーニングを行うことができます。
教師ありフェーズ
前節では、教師なしアプローチを用いて、1日に数回の潜在的な漏水や盗難を検出するという付加的な利点を持つ異常を正確にラベル付けすることができました。教師ありの段階では、この新たにラベル付けされたデータを、家のサイズ、階数、家の年齢、家電製品情報などの特徴と組み合わせて、取り込まれた異常を積極的に検出できる汎用モデルを構築します。数年分の過去の公共料金の使用状況を詳細なレベルで記録するなど、より大量のデータを扱う場合、標準的なML技術ではパフォーマンスが低下する可能性があります。そのような場合、Spark MLライブラリはSparkの分散処理を活用する。Spark MLは、Spark上のMLをスケーラブルかつ容易にする、高レベルのDataframeベースのAPIを提供する機械学習ライブラリ��である。多くの一般的なアルゴリズムやユーティリティが含まれており、MLワークフローをPipelineに変換する機能もあります-これについては、もう少し詳しく説明します。今のところ、目標は、単純なロジスティック回帰モデルを使用して、ラベル付きデータのベースラインモデルを作成することだけです。
まず、ラベル付きデータセットをSpark SQLを使用してDeltaテーブルからデータフレームにロードします。
異常レコードの比率が著しくアンバランスであるように見えるため、PySparkを使用して、多数派のクラスのサンプルを取り、少数派(異常)全体のDataFrameに結合することによって、バランスのとれたデータセットを作成します。
不要なカラムを削除した後、新しいリバランスされたDataFrameはtrainとtestのデータセットに分割されます。この時点で、scikit-learnのパイプラインの概念と同様に、Pipelines APIを使用してSparkMLでパイプラインを構築することができます。パイプラインは、順番に実行されるステージのシーケンスで構成され、各ステージで入力DataFrameを変換する。
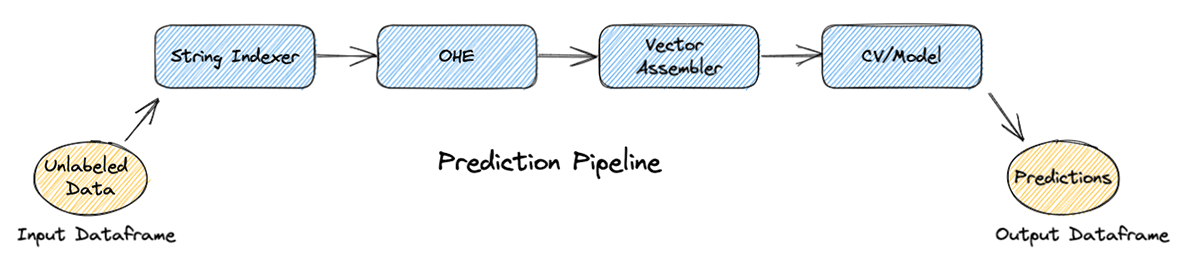
訓練ステップでは、パイプラインは、カテゴリ変数を扱うための文字列インデクサーとワンホットエンコーダー、すべての特徴からなる必要な単一の配列列を作成するためのベクトルアセンブラ、およびクロスバリデーションの4段階で構成されます。この時��点から、パイプラインはトレーニングデータセットに適合させることができます。
その後、テストデータセットを新しいモデルのパイプラインに通すことで、精度を把握することができます。
この基本的なLogisticRegression estimatorでは、結果的にメトリクスを計算することができます。
クロスバリデーションで使用する推定値を変更するだけで、異なる学習アルゴリズムを評価することができます。3つの異なる推定量(LogisticRegression、RandomForestClassifier、GBTClassifier)をテストした結果、GBTClassifierの方が若干精度が高いと判断されました。

非常に基本的なコードで、チューニングやカスタマイズをほとんど行っていない割には悪くはないでしょう。モデルの精度を向上させ、信頼性の高いMLパイプラインを製品化するために、特徴選択の強化、ハイパーパラメータのチューニング、説明可能な詳細の追加などの追加ステップを追加することができます。
メンテナンスレイヤ
時間が経てば、天候の変化、家電製品のアップグレード、家の所有権、不正行為など、監修モデルが見たことのないエネルギー損失の原因となる新しいシナリオや状況が発生します。このことを念頭に置いて、ハイブリッド・アプローチを実施する必要があります。高精度の教師ありモデルは、教師なしアンサンブルと並行して、既知のシナリオを予測するために使用することができます。教師なしアンサンブルから得られる確信度の高い予測は、教師ありの判断を上書きし、エッジ(または未見)シナリオから潜在的な異常を昇格させるために使用することができます。検証の結果、教師ありモデルの再トレーニングと拡張のために、結果をシステムにフィードバックすることができます。Databricksに組み込まれたオーケストレーション機能を使用することで、このソリューションは、リアルタイムの異常予測だけでなく、教師なしモデルによるオフラインチェックにも効果的に展開することが可能です。
まとめ
エネルギー損失の防止は、大規模な異常の検出能力を必要とする困難な問題である。従来は、非常に小さく、しばしば不正確に報告されるデータセットを補完するために、大規模な現場での調査が必要であったため、この問題に取り組むのは非常に困難でした。教師なし手法を用いた科学的なアプローチで調査を行うことで、初期トレーニングデータセットの開発に必要な工数が大幅に削減され、母集団にカスタムフィットする、より正確な教師ありモデルの開発への参入障壁が低くなります。Databricksは、このようなアンサンブルモデルのオーケストレーションと分散型モデルトレーニングに必要な機能を内蔵しており、データ入力サイズに関する従来の制限を取り除き、機械学習のライフサイクルをすべてスケールアップして実現することができます。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。