Predictive I/O for Readsの一般提供開始を発表
Databricks Lakehouse uses ML to power faster and cheaper point queries
によって Shoumik Palkar, Justin Breese, シャント・ホヴセピアン, Kent Marten 、 シリエル・シメオネ による投稿
Original Blog : Announcing the General Availability of Predictive I/O for Reads
翻訳: junichi.maruyama
本日、Databricks SQL (DB SQL)向けのPredictive I/Oの一般提供を開始します:機械学習を利用した機能で、ポイントのルックアップをより速く、より安くすることができます。Predictive I/Oは、Databricksが大規模なAI/MLシステムを構築してきた長年の経験を活用し、追加のインデックスや高価なバックグラウンドサービスなしで、Lakehouseを最もスマートなデータウェアハウスにすることができます。実際、ポイント検索では、Predictive I/Oは、インデックスと最適化サービスのすべての利点を提供しますが、それらを維持するための複雑さとコストは必要ありません。Predictive I/Oは、DB SQL ProとServerlessではデフォルトでオンになっており、追加コストなしで機能します。
ポイントルックアップとは何か、なぜ高いのか?
選択的クエリやポイント・ルックアップは、BIやアナリティクスのユースケースでよく見られる、大きなデータセットから少量または単一の結果��を返そうとするものです。BIやアナリティクスのユースケースでよく見られるもので、「針の穴を通すような」クエリーと呼ばれることもありますが、こうしたクエリーをコストを抑えながら高速化することは困難です。
なぜなら、クラウドデータウェアハウス(CDW)でポイント検索を高速化するためには、インデックスを作成するか、追加の最適化サービスを使用しなければならないからです。さらに、これらのオプションはノブであり、各アプローチを有効にする前に、いつ、どのように使用するかを理解する必要があることを意味します。
インデックスが手間とコストがかかるのは、以下の理由から:
- どのカラムにインデックスを付けるかを考える必要がある
- インデックスを維持するために、再構築のタイミングを決定し、再構築のたびに費用を支払う必要がある
- このプロセスは、テーブルごとに、ユースケースごとに考える必要がある
- 書き込み増幅に注意する必要がある
- 使用パターンが変わった場合は、インデックスの再構築が必要
最適化サービスは高い:
- どのテーブルで有効にするかを決定する必要がある
- テーブルの変更に合わせてバックグラウンドでサービスを実行するための費用が必要
- 各テーブルごとにこのプロセスを考える必要がある
要約すると、CDWのインデックスとポイントルックアップの最適化サービスは高価である。必要なすべての考慮事項を考えると、これらのオプションは、調整するのに時間とお金がかかる複雑なノブである。もっと良い方法があるはずです。
Predictive I/Oのメリット
もし、データのコピーを作成する必要がなかったらどうでしょう?高価なインデックスや検索最適化サービスも必要ないとしたらどうでしょう?もし、システムがクエリに必要なデータを学習し、次に何が必要になるかを予測することができたら?もし、クエリがノブなしで単純に高速化されたらどうでしょう?
もしDatabricksが、DBAの悲しみの終わらないループを止め、シンプルさを取り戻すことを可能にするインテリジェントなシステムに置き換えることができたらどうでしょうか?ここで、Predictive I/Oがチャットに入るのです。Predictive I/Oのパフォーマンスがすぐに発揮される2つの例を見てみましょう。
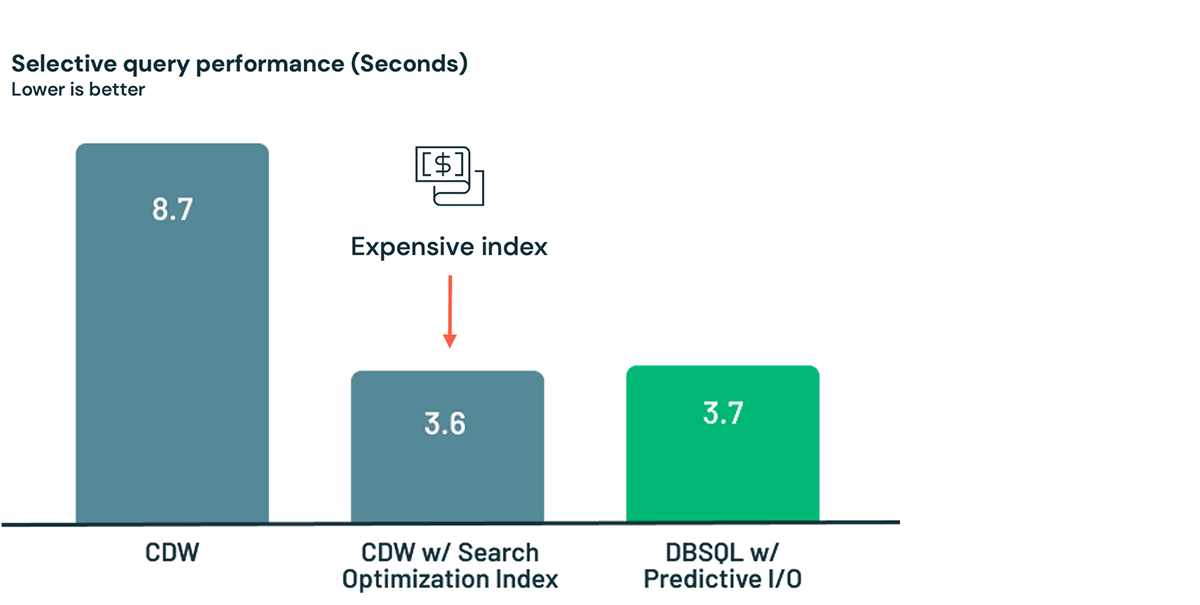
まず、Databricks SQL Serverlessのパフォーマンスを、Cloud Data Warehouse(CDW)のポイント検索と比較してみましょう。下のケースでは、CDWにデータセットをロードした後、クエリに8.7秒かかっています。もしこれが十分な速度でない場合は、高価な最適化サービスを利用すれば、3.6秒まで短縮することが可能です。しかし、忘れてはならないのは、このためにお金を払っていることです。テーブルが変わるたびに、最適化サービスはメンテナンス作業を行わなければならないのです。もっと簡単で安価な方法として、Predictive I/Oを使えば、Lakehouseのデータを3.7秒でロードしてクエリすることができます!
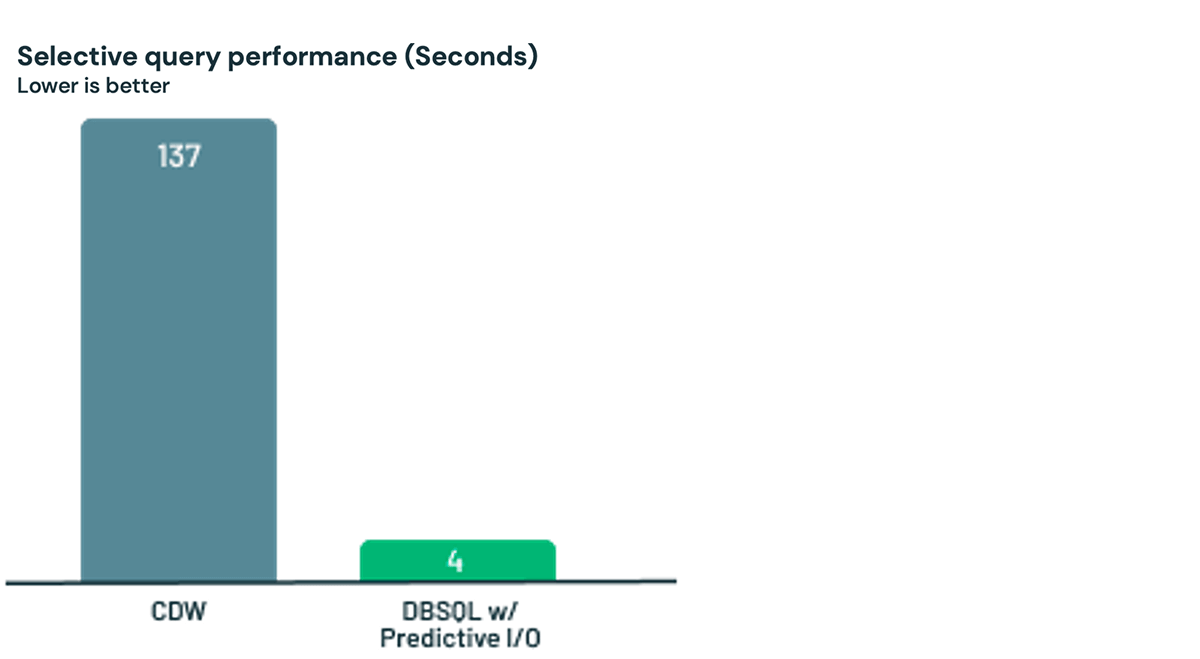
次に、Predictive I/Oの初期の顧客による実世界のワークロードを見てみましょう。データをDatabricksにロードし、選択的なクエリを実行するというシンプルなプロセスでした。Predictive I/Oは、このお客様のユースケースにおいて、CDWよりも35倍高速でした。ここでも、優れたパフォーマンスを発揮するために必要なノブはありません。
That sounds great! でもPredictive I/Oはどのように機能するのでしょうか?
Delta LakeとParquetテーブルに対して、Predictive I/Oは、ヒューリスティック、モデリング、ファイルプロパティに基づくスキャンパフォーマンスの予測など、さまざまな形態の機械学習と機械知能を使用して、さまざまな最適化をインテリジェントに有効または無効化します。全体的な目標はシンプルで、選択的なクエリのパフォーマンスを高速化し、お客様の時間とコストを削減することでした。
クエリの特性を利用して、クエリを最適に実行するためにどれだけの�リソースを割り当てる必要があるのかを決定します。
What's next?
Predictive I/Oは、お客様にとってパフォーマンス向上のマイルストーンとなるものです。分析において選択的なクエリがいかに一般的であるかを考えると、この分野でイノベーションを起こし続けることに興奮を覚えます。私たちのお客様がクラス最高のコストパフォーマンスを維持し、レイクハウスを最高のデータウェアハウスにするために、パフォーマンス機能の次の波が間もなくやってきますので、ご期待ください(ダジャレではありませんよ)。
既存のお客様であれば、今日からPredictive I/Oを使い始めることができます。Databricks SQL Serverless warehouse もしくは Databricks SQL Pro をセットアップするだけで、最高の体験ができ、データのクエリを開始できます。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。