Delta Live Tablesを使用して、複数のストリーミングプラットフォームから同時にデータを処理する
Easily manage and consume from diverse streaming platforms across multiple clouds through a single ETL pipeline.
によって Uday Satapathy, Dipankar Kushari 、 Akash Jaiswal による投稿
Original Blog : Processing data simultaneously from multiple streaming platforms using Delta Live Tables
翻訳: junichi.maruyama
今日の組織における大きな課題の1つは、ビジネスのスピードに合わせた意思決定を可能にすることです。ビジネスチームや自律的な意思決定システムは、意思決定や迅速な対応に必要なすべての情報を、ソースとなるイベントが発生すると同時に、リアルタイムまたはほぼリアルタイムで必要とすることが多い。このような情報は、ストリーム処理用語でイベントと呼ばれ、ソースからデスティネーションへ非同期でリレーされ、一般的にメッセージブローカーやメッセージバスを介して行われる。
組織が成長し、チームが他のチームに分岐するにつれ、メッセージブローカーの使用パターン、数、種類は増加します。合併や買収のシナリオでは、企業が新しいメッセージブローカーを継承することが多く、その場合、既存のデータエンジニアリング・プロセスと統合する必要があります。メッセージブローカー、そのプロデューサ、コンシューマ、データエンジニアリングパイプラインを一貫して管理することは、多くのテクノロジー、クラウドプラットフォーム、プログラミング言語の専門性を必要とするため、困難な場合があります。
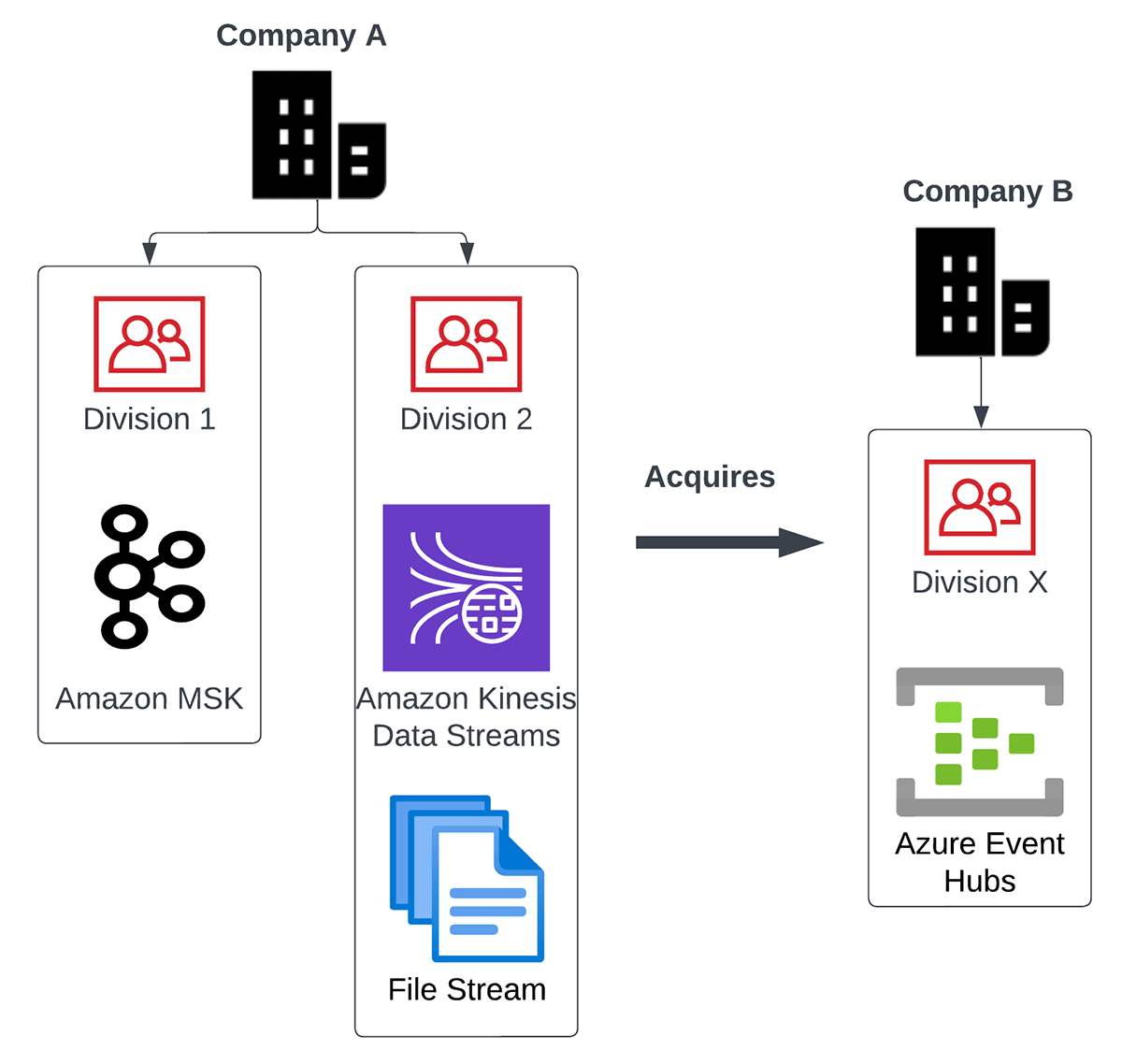
例えば、マルチストリームのユースケースを見てみましょう。世界的なコングロマリットで、次のような状況を想像してください。
- 同社には、Amazon Kinesis Data StreamsとAmazon Managed Service for Kafka(MSK)という2つのメッセージブローカーを使用する主要部門があります。
- またAzure Event Hubsを社内で使用している小規模な製品会社も買収しました。
- 彼らはまた、csvやjsonファイルの継続的なストリームという形で来るデータの主要なソースを持っています。
下の図は、上記のマルチストリームのユースケースを描いたものです:
このようなシナリオで、すべてのデータを処理する際の主な課題を紹介します:
- 多様なデータソースとその技術をどのように統合するのか?
- データエンジニアリング・システムを、拡張や保守が容易なように構築するにはどうすればよいか?それぞれの技術に特化した人材など、馬の骨を雇うのか?
- このようなテクノロジーの難問を解決する過程で、最終目標である「データの意味を理解し、意思決定を迅速に行う」ことを忘れないようにするには、どうすればよいのでしょうか。
- バッチ処理とストリーミング処理の両方のニーズを、同じデータ処理システムで実現するにはどうすればいいのでしょうか?
このブログでは、Delta Live Tables (DLT)を通して、これらの問題を簡単かつきれいに解決でき�る方法を紹介します。Databricks Lakehouse Platform上のDelta Live Tablesは、高品質のバッチおよびストリーミングデータパイプラインを簡単に作成、管理することができます。
マルチストリームの使用例
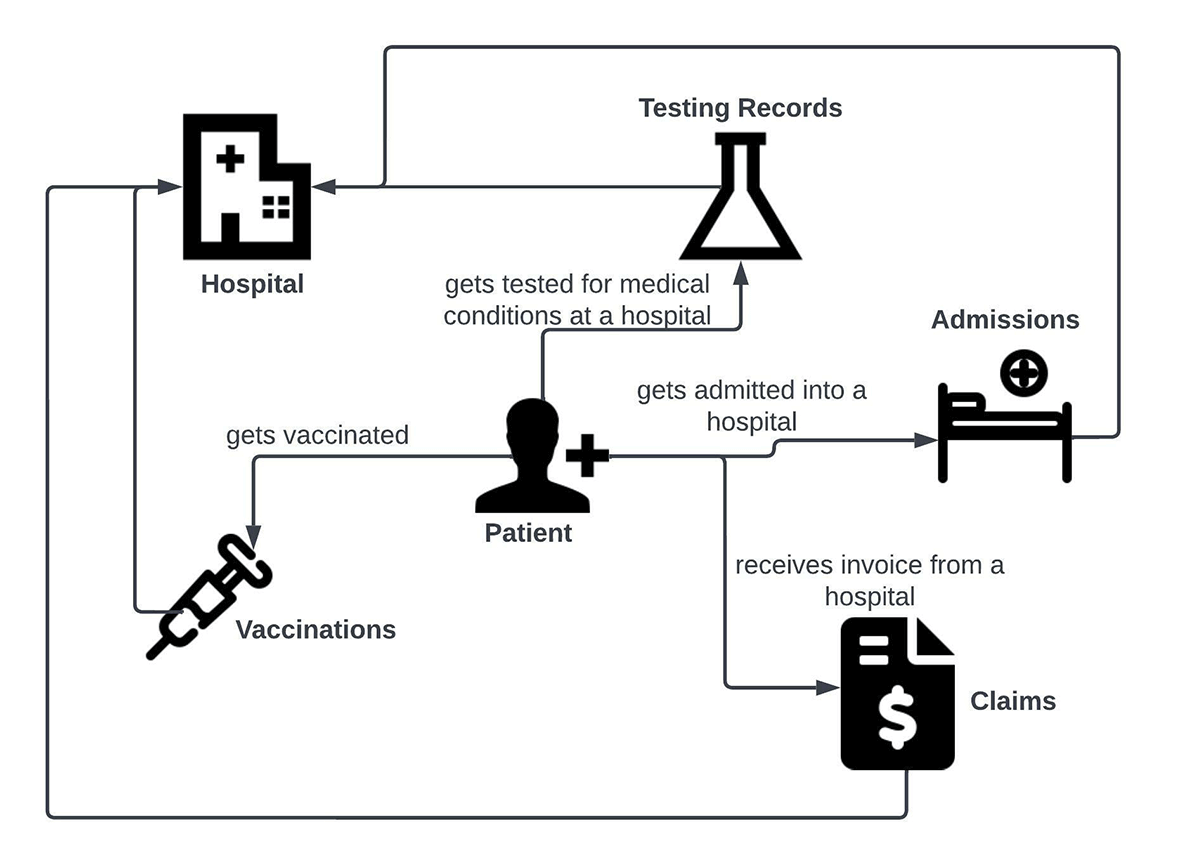
DLTによるマルチストリーム処理のシナリオを示すために、ヘルスケア領域のユースケースを想像してみましょう。ユースケースの中心は患者である。この患者は、別のエンティティ(hospital)と次のようなやり取りをします:
- 病院で病気に対する予防接種を受ける
- 病院で病気の検査を受ける
- 特定の病気で入院する。
- 治療費の請求は、クレーム処理によって行われます。
これらのやりとりは、以下のビジネスユースケースダイアグラムで表現することができます。
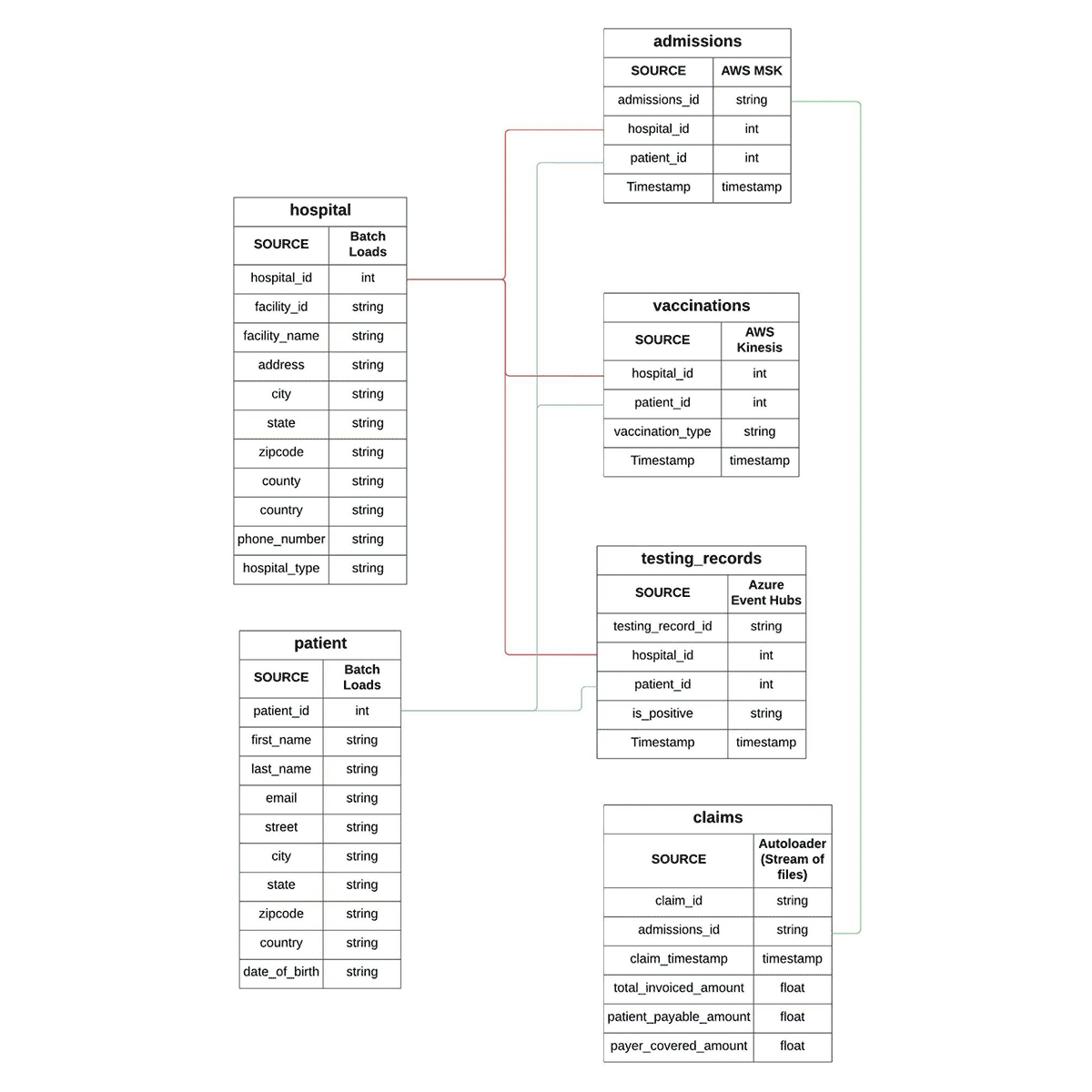
これらの相互作用に関与するエンティティは、以下のエンティティ関係(ER)図の形で表現することができます。この先、データ・ウェアハウス次元モデリングの辞書にある「ファクト」と「ディメンション」という用語を十分に使用することになります。ER図では、PatientとHospitalがディメンション・テーブルであり、Admissions、Vaccinations、Testing records、Claimsのデータはファクト・テーブルの形で表現されていることがわかります。
例えば、入学、予防接種、検査記録、請求のファクトデータが、異なるメッセージブローカーを通じて届くとします。このブログでは、業界で人気のあるApache Kafka (Amazon MSK), AWS Kinesis Data Streams, Azure Event Hubsを選択しました。ストリーム処理のシナリオを示す4つ目の方法は、一連のファイルをテーブル(この場合はDelta lake)にインクリメンタルに取り込むことです。この目的のためにDatabricks Autoloaderを選択しました。この情報により、患者のインタラクション図を関連するデータソースで更新できるようになりました:
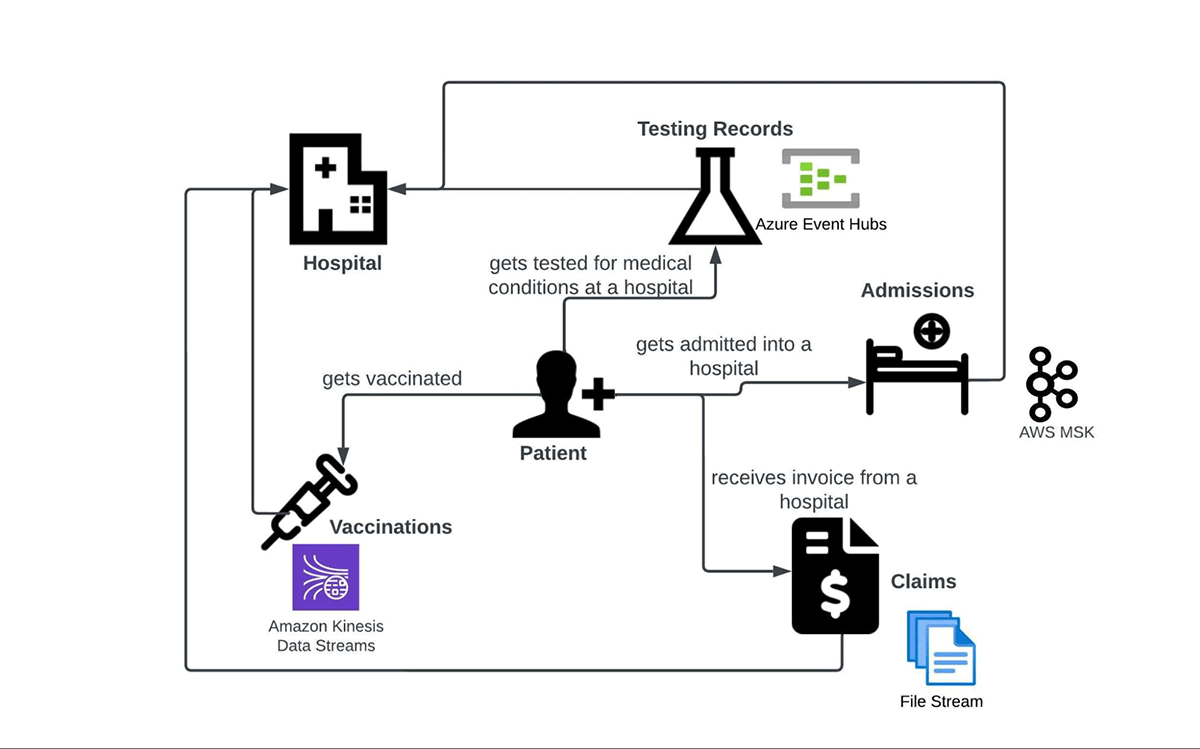
以下、表形式でまとめたデータソースを紹介します:
| Fact | Data source |
| Admissions | Amazon MSK (Apache Kafka) |
| Testing Records | Azure Event Hubs |
| Vaccinations | AWS Kinesis Data Streams |
| Claims | Incremental stream of files |
次のセクションでは、単一のDLTパイプラインが上記のストリーミングソースから同時にデータを取り込み、さらにそれに対してETLを実行する方法を示します。このブログではAWSのインフラを使ってリソースとパイプラインをセットアップしましたが、AzureやGCPなど他のパブリッククラウドでも同様にシナリオを構成できるはずです。
DLTによるマルチストリーム処理
下図は、一般的なDLTのパイプラインを表したものである。多様なソースからのストリーミングデータの取り込みと変換がこのブログの主題ですが、DLTにはさらに注目すべき機能があります。例えば、データ品質管理は、チームが特定の「期待値」をクリアしたデータのみを処理できるようにするための重要な機能です。チームは、誤ったデータに対して是正措置や予防措置を講じることができます。DLTのその他の利点として、管理されたチェックポイントと強化されたオートスケーリングがあります。これらの機能やその他の機能については、こちらの記事でご紹介しています: Delta Live Tables concepts
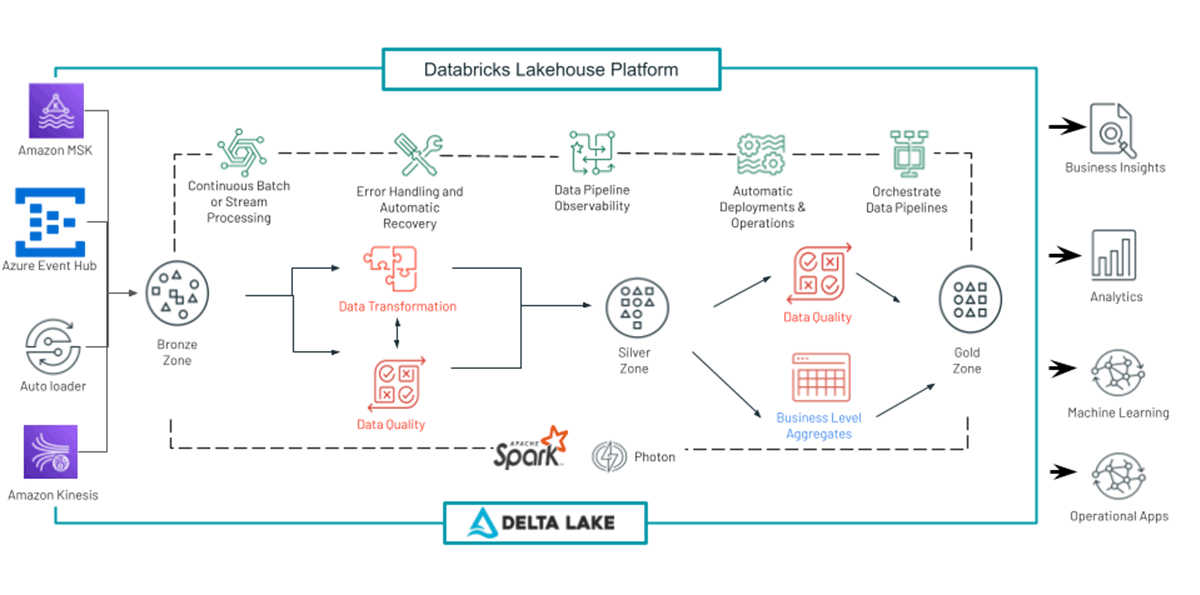
私たちのマルチストリーム処理DLTパイプライン(簡単のためにdlt_multistream_consumerと呼ぶことにします)は、以下のような操作を行います:
- メッセージブローカーからのストリーミングデータをデルタレイクテーブルの生レイヤーにロードする。
- メッセージペイロードから意味のあるファクト(ファクトテーブル)を生成するために、生データをパースしてスキーマを適用する。
- BIおよびアナリティクスチームが利用するための集計データセットを生成する。これは、様々なファクトテーブルとディメンションテーブルを結合し、生成されたレコードをスライス/ダイシングすることで行われます。
DLT Pipelineは、以下のモードで動作するように構成することができます:
- 連続:ライブクラスタは、データが到着するとすぐに連続的に処理します。これは、レイテンシーが最も重要なストリーミングシナリオに推奨されます。
- Triggered(トリガー): 任意のスケジュールでクラスタが起動し、その時点で利用可能なデータを処理します。処理待ちのデータがなくなると(一定の時間持続する閾値)、クラスタはシャットダウンされます。このモードは、コスト削減とスループットがレイテンシーよりも優先される場合に推奨されます。
このブログでは、2つの理由から連続モードを使用し�ています。1つ目は、データをリアルタイムで取り込んで処理する「真の」ストリーム処理シナリオを実証するためです。2つ目は、このブログを公開している時点では、Apache Spark用のAmazon Kinesis Data Streamsコネクタは、トリガーモードのようなバッチモードの取り込みをサポートしていません(つまり、一度トリガーするか、今すぐ利用できます)。近々登場する予定ですが。
もう1つ強調したいのは、一般的に本番環境では、生データが取り込まれた後、多くの処理と充実化の段階を経るという点です。これらの段階は、データ分析、データの履歴および予測分析を含むビジネスユースケースのために、データを浄化、変換、集計します。私たちは、データがアーキテクチャの各層を流れる際に、データの構造と品質が徐々に改善されることを、メダリオンレイクハウス・アーキテクチャと呼んでいます。メダリオンアーキテクチャは主流のユースケースに対するベストプラクティスですが、このブログを簡単にするために、データ変換の部分を省略し、ビジネスユースケースをサポートするためのデータ分析の実行に移行することにします。
それでは、DLTを利用した多数のストリーミングシステムからDelta Lakeにストリーミングデータを一度に取り込み、そのデータを分析して意味のあるインサイトを生成する方法を見ていきましょう。
ストリームからのデータ取り込み
このセクションでは、複数のストリーミングプラットフォームからデータをインジェストする方法を紹介します。
Amazon MSKからのデータ取り込み
Amazon Managed Streaming for Apache Kafka(Amazon MSK)は、Apache Kafkaを使用してストリーミングデータを処理するアプリケーションの構築と実行を可能にするフルマネージドサービスです。Amazon MSKは、クラスタの作成、更新、削除といったコントロールプレーンの操作を提供します。
本ブログでは、以下のような構成のMSKクラスタを使用しています:
- Cluster type - Provisioned
- Total number of brokers - 2
- Apache Kafka version - 2.5.1
- Broker type - kafka.m5.large
- Number of availability zones - 2
- EBS storage volume per broker - 300 GiB
- Encryption between clients and brokers:
- TLS encryption - Enabled
- Plaintext - Enabled
AWS環境での認証のために、DLTクラスタにインスタンスプロファイルをアタッチしています。これは、役割定義で設定された適切な読み取り/書き込み権限を持つIAMロールを参照しています。
パイプラインdlt_multistream_consumerは、MSKトピックadmissionからHospital Admissionデータセットをmsk_admissions_tbl_rawというデルタレイクテーブルにインジェストしています。Admissions ファクトの kafka ペイロード(文字列として表現されるバイナリ)は次のようになります:
インジェストにはpythonノートで以下のコードを使い、DLTパイプラインのdlt_multistream_consumerにアタッチしています。
パイプライン dlt_multistream_consumer が開始されると、目的のデータベース/スキーマ内に msk_admissions_tbl_raw テーブルを作成し、そのテーブルに入場トピックから読み込んだデータを入力します。その後、そのトピックに新しいデータが書き込まれると、さらにデータを取り込みます。
Kafkaトピックから取り込まれる4つのフィールドに加えて、msk_event_timestamp(Kafkaが生成するイベントタイムスタンプから派生)列をmsk_admissions_tbl_rawテーブルに追加しています。メッセージは、バイナリ形式でKafkaペイロードのフィールド値で受信されます。下流のプロセスで解析できるように、文字列に変換する必要があります。
Amazon Kinesisからのインジェスト
Amazon Kinesis Data Streamsは、リアルタイムのストリーミングデータを簡単に収集、処理、分析することができます。データは、機械学習、分析、その他のアプリケーションのためのビデオ、オーディオ、アプリケーションログ、ウェブサイトのクリックストリーム、およびIoTテレメトリデータである可能性があります。当ブログでは、以下の構成でKinesisデータストリームを使用しました:
- Data Stream Name: test_vaccination_data
- Capacity Mode: On Demand
- Write Capacity: 200 MiB/second or 200,000 records/second (Default Maximum)
- Read Capacity: 400 MiB/second (Default)
スループットを向上させるために、Databricks Runtime KinesisコネクタのAmazon Kinesis enhanced fan-out (EFO)機能を本番シナリオで使用することができます。
今回のユースケースでは、test_vaccination_dataストリームが、患者のワクチン接種の事実(イベント)を運びます。以下は、ペイロードのサンプルです:
KinesisデータストリームからLake houseのLanding zoneにデータを消費するためのDLTコードは以下の通りです:
パイプラインdlt_multistream_consumerは、Kinesisデータストリームで利用可能なデータをターゲットテーブルkinesis_vaccination_tbl_rawに入力し、データの再読み込みを回避するためにチェックポイントを実行する。メッセージはバイナリ形式でKinesisペイロードのフィールドデータで受信されます。下流のプロセスで解析できるように、文字列に変換する必要があります。
Azure Event Hubsからのインジェスト
Azure Event Hubsは、Microsoftが提供する一般的なストリーミングプラットフォームです。Event Hubsは、AMQP、HTTPS、Apache Kafkaなど、読み書きのための複数のプロトコルをサポートしています。このブログでは、DLTパイプラインdlt_multistream_consumerは、Event HubsのKafkaサーフェスを使用してメッセージを消費しています。私たちは、Event Hubsのネームスペースに2 Throughput Unitの標準価格帯を使用しています。
Azureのドキュメントでは、名前空間はイベントハブ(Kafkaでいうところのトピック)の管理コンテナであると説明されています。私たちの関心のあるイベントハブ(別名トピック)はtesting_records_streamで、患者の臨床検査結果に関連するイベントを運びます。各メッセージは以下のような感じです:
testing_records_streamイベントハブからメッセージを消費するDLTコードは、Amazon MSKのインジェストパターンとよく似ています(どちらもKafkaプロトコルを使っていますね)
DLTパイプラインは、イベントハブからテストレコードメッセージをインクリメンタルに読み込み、新しい行としてeventhubs_testing_records_tbl_raw delta lake tableに追加する。メッセージは、Kafka-surfaceのペイロードのフィールド値でバイナリ形式で受信されます。下流のプロセスが解析できるように、これらは文字列に変換する必要があります。
Autoloaderによるファイルの取り込み
Auto Loaderは、業界で最も強力で堅牢なデータファイルインジェストツールの1つです。新しいデータファイルがクラウドストレージに到着すると、追加設定をすることなく、段階的かつ効率的に処理します。現在、JSON、CSV、PARQUET、AVRO、ORC、TEXT、BINARYFILEのファイル形式を取り込むことができます。
Auto Loaderでは、コンシューマーはcloudFilesと呼ばれるStructured Streamingソースを設定することができます。設定オプションには、クラウドストレージのファイルパス、ファイルフィルタリングパターン、Azure Queue Storage、AWS SQS、AWS SNSなどのキューに対するファイル到着イベントオプションなどがあります。DLTパイプ�ラインは、これらのオプションを使用して、到着した新しいファイルを自動的に取り込み、そのディレクトリにある既存のファイルも処理するオプションがあります。Auto Loaderは、DLTパイプラインにおけるPythonとSQLの両方をサポートしています。クライアントはAuto Loaderを使用して、何十億ものファイルを処理し、データの移行やテーブルの埋め戻しを行ったことがあります。Auto Loaderは、1時間あたり数百万ファイルのほぼリアルタイムのインジェストをサポートするように拡張されています。
このブログでは、Auto Loaderを使用して、以下のサンプルで患者請求データを取り込みました:
dlt_multistream_consumerパイプラインでは、以下のコードのように、患者クレームのjsonファイルがソースロケーションに到着すると、Auto Loaderを介してインジェストされます:
インジェストされたデータを分析し、ビジネスインサイトを生み出す
前述したように、このブログでは、Amazon MSK、Amazon Kinesis Data Streams、Azure Event Hubs、Databricks Auto Loaderという4つの異なるソースから患者データセットをすでにインジェストしています。簡潔にするために、データ変換部分はスキーマの強制のみに限定し、ビジネスユースケースをサポートするために、これらのデータセットに対してデータ分析を実行するために前進しています。
このブログでは、2つのビジネス分析のユースケースを作成しました。これは、ユーザーがDLTによって作成されたデルタレイクのテーブルを使用して、ビジネスの疑問に答えるためにデータ分析を実行する方法を示すため�のものです。
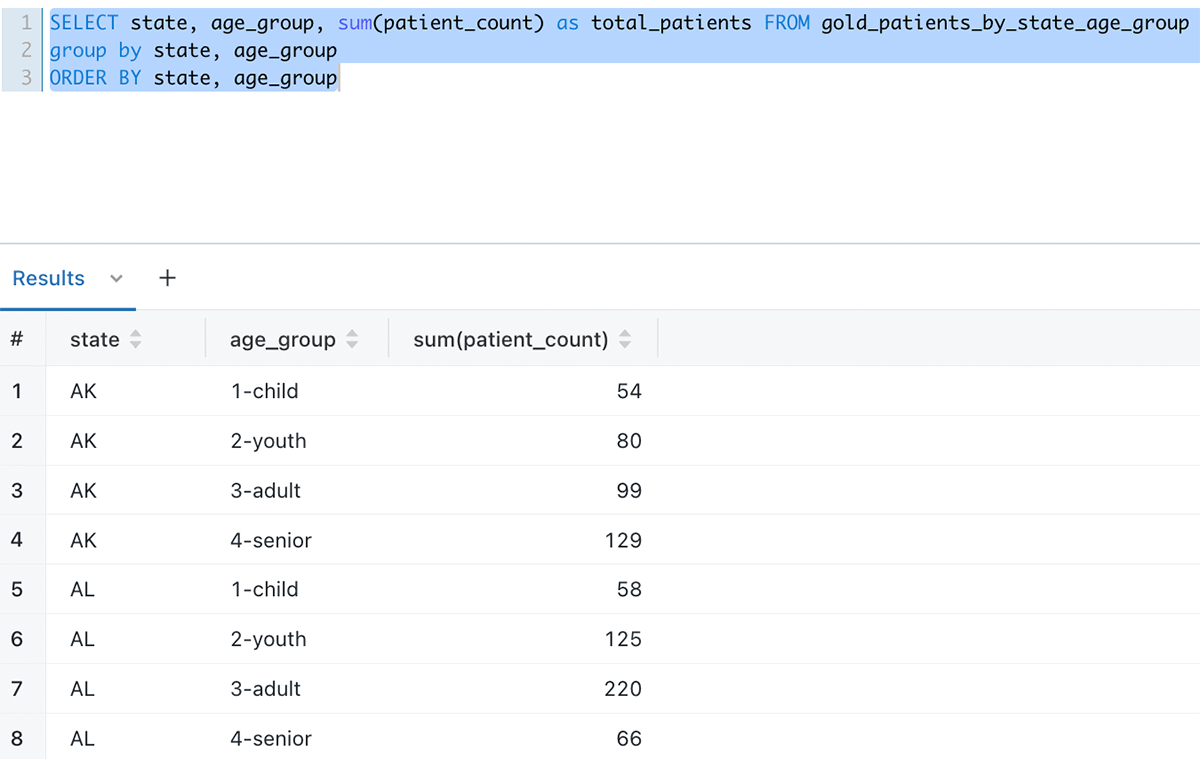
Covidワクチン接種後にCovid陽性となった患者数(州・年齢層別)
gold_patients_by_state_age_group テーブルは、DLT を介したデータ取り込みによって入力されたテーブルを結合することによって DLT で作成されます。新しいデータがインジェストレイヤーに到着すると、継続的なDLTパイプラインがそのデータをインジェストレイヤーに取り込み、データ分析のためにこのgold_patients_by_state_age_groupテーブルを更新します。--
以下は、Databricks SQLクエリエディタでクエリした場合のデータの見え方です:
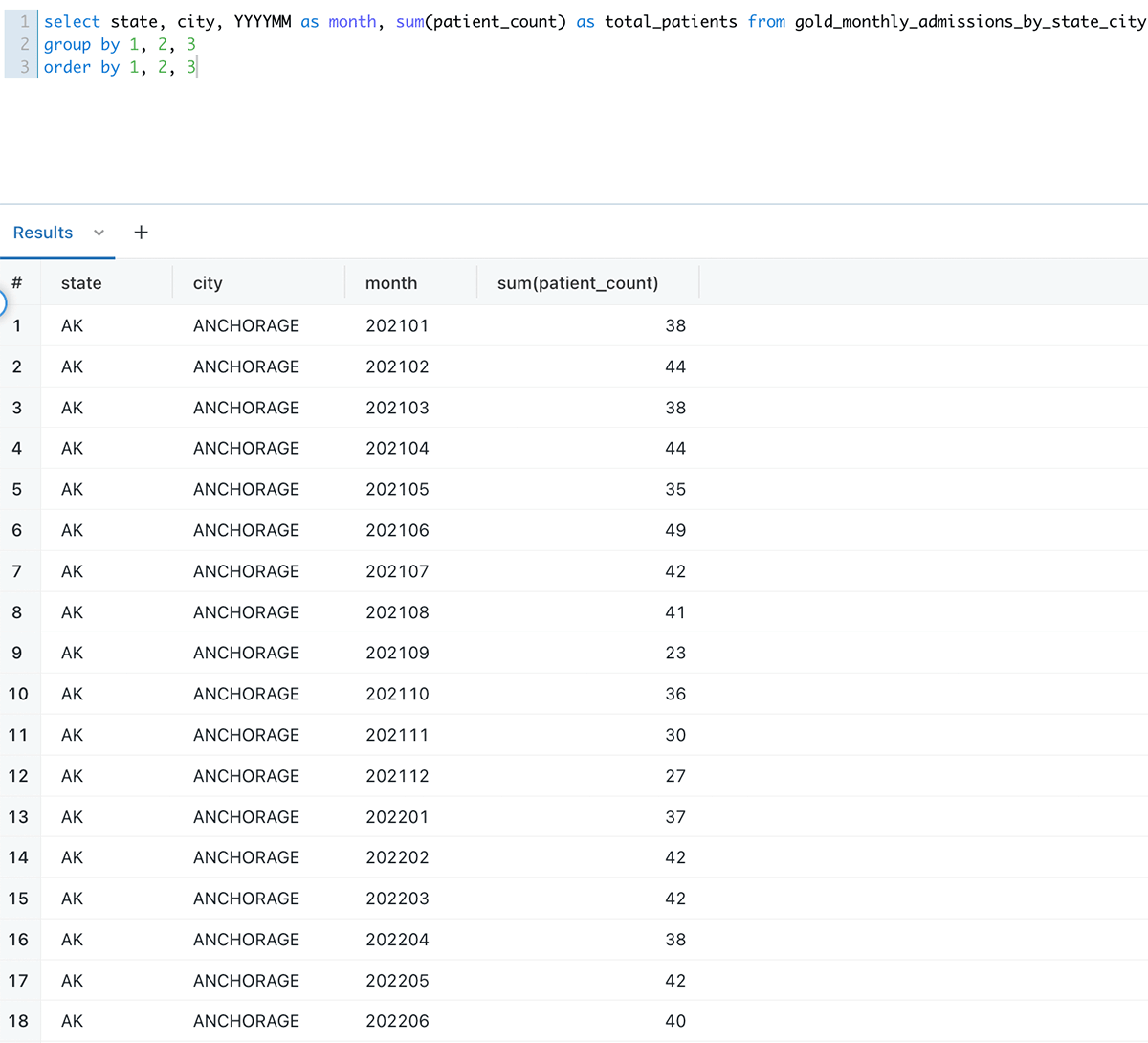
都市・州ごとの月別入学者数
月ごとの都市および州ごとの入場者数は、gold_monthly_admissions_by_state_cityテーブルを照会することでサポートされる別のユースケースです。
以下は、Databricks SQLクエリエディタでクエリした場合のデータの見え方です:
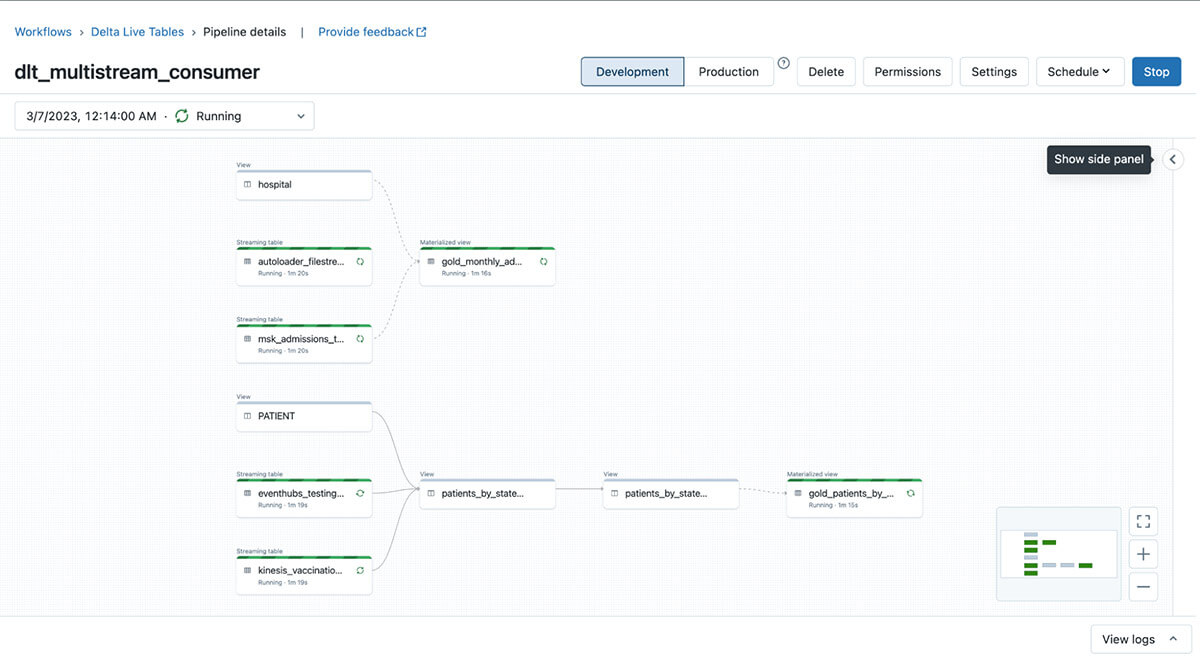
DLTパイプラインのEnd to Endビュー
DLTの主な特徴の1つは、パイプラインの一部として含まれるコードアーティファクト間のテーブルレベルの依存関係をすべてクロールし、それを系統グラフの形で表示する機能です。このグラフは「ライブ」です。ETL処理が進むにつれて、成功した処理は緑色で、失敗した処理は赤色で表示されます。継続的に実行されているDLTデータパイプラインのスクリーンショットを以下に示します:
まとめ
このブログでは、Databricks Delta Live Tableを使用して、複数のクラウドにまたがる多様なストリーミングプラットフォームから、単一のデータパイプラインを使用してデータを取り込み、消費する方法を紹介しました。ETLプロセスは、データが到着するとすぐに、連続的に行われます。変換によって生成されたデータは、データ分析を実行してビジネスの疑問に対する答えを得るために継続的に利用できます。このようなソリューションは、全体的な技術アーキテクチャを大幅に簡素化し、保守と拡張を容易にします。DatabricksはDLTに定期的に新機能を導入しており、ETLワークロードのために顧客の間で広く採用されています。Delta Live Tablesを今すぐお試しください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の��投稿を受信トレイにお届けします。