構造化ストリーミングにおける適応的なクエリの実行
Improving ForeachBatch Sink in Project Lightspeed
によって Steven Chen, MaryAnn Xue 、 Jungtaek Lim による投稿
Original: Adaptive Query Execution in Structured Streaming
翻訳: junichi.maruyama
Databricks Runtimeでは、Adaptive Query Execution (AQE) は、クエリ実行中にランタイム統計を使用してバッチクエリを継続的に再適正化するパフォーマンス機能です。Databricks Runtime 13.1以降、ForeachBatch Sinkを使用するリアルタイムストリーミングクエリも、Project Lightspeedの一環として、AQEを活用して動的再最適化を行います。
静的計画・統計による限界
Databricksでは、Structured Streamingが毎日ペタバイトのリアルタイムデータを扱っています。40%以上の顧客が使用しているForeachBatchストリーミングシンクでは、大量のデータに対して結合やDelta MERGEといった最もリソースを消費するオペレーションが組み込まれることが多い。その結果生じる多段階の実行計画は、AQEによって再最適化される可能性が最も高い。
ストリーミングクエリは、静的なクエリプランニングと推定統計量に依存しており、バッチクエリに見られるいくつかの既知の問題(物理戦略の決定ミスや、性能を低下させる歪んだデータ分布など)を引き起こしています。
動的最適化の応用
これらの課題を解決するために、ForeachBatch Sinkのマイクロバッチ実行中に収集された実行時統計情報を利用して、動的な最適化を行います。データの特性は異なるマイクロバッチ間で時間とともに変化する可能性があるため、適応的なクエリ再プランニングは各マイクロバッチで独立してトリガーされる予定です。
AQEの効果はステートレス演算子で分離され、ForeachBatch呼び出し可能関数内でマイクロバッチのDataFrameに適用されます。ForeachBatchを呼び出す前にストリーミングDataFrameに直接適用される演算子は、ステートフルである可能性があるため、AQEなしで別のクエリプランで実行されます。実行を分離することで、ステートフルな演算子に対するAQEの再分割を防ぎ、局所性を奪って正しさの問題を引き起こす可能性があります。
Photon対応クラスタでは、ステートレスクエリの各マイクロバッチは、バッチPhotonクエリと実質的に同じまとまったクエリプランで実行されます。この設計により、論理的および物理的な最適化を最も幅広く行うことができます。AQEは、ForeachBatch Sinkを使用するほとんどのステートレスPhoton対応クエリで効果を発揮します。
一般に、AQEは、ForeachBatch Sink内で変換を適用できる場合に最も効果的となります。以下のサンプルコードでは、2つの意味的に同じストリーミングクエリを示しています。2番目のクエリーは、結合がForeachBatch関数内に移動しているため、AQEカバレッジが向上する可能性があるため推奨されます。
AQEによるクエリプランの解釈
デルタテーブルにリアルタイムデータをアップサートするストリーミングデルタMERGEクエリの単純化した例を考えてみましょう:
マッチのスキャンは、Delta Mergeクエリで最もコストのかかる部分であることが多い。サンプルのマイクロバッチでマッチングプロセスを実行するクエリプランのSpark UIスニペットを検証してみましょう。
まず、AQE Plan Versionsには、実行中にプランがどのように進化したかを示すリンクが含まれています。AdaptiveSparkPlanルートノードは、少なくとも1つのシャッフルを含むため、このクエリプランにAQEが適用されたことを示します。
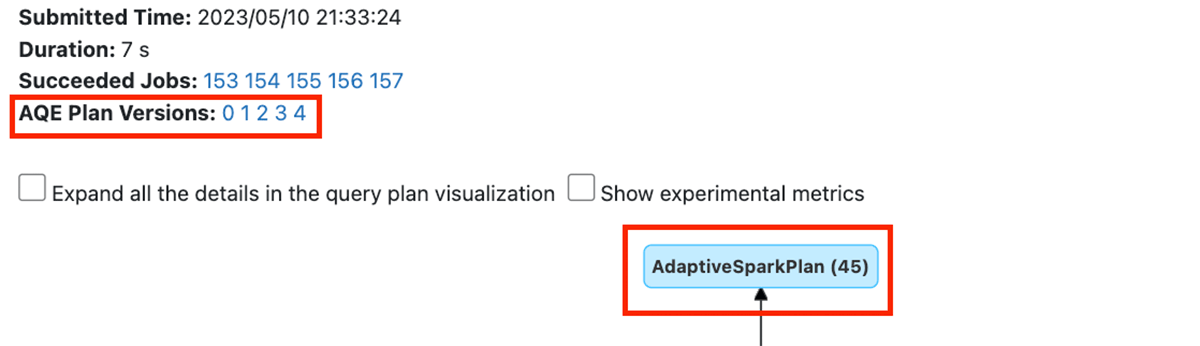
The snippet below shows that AQE applied dynamic coalescing of small partitions in this particular example.
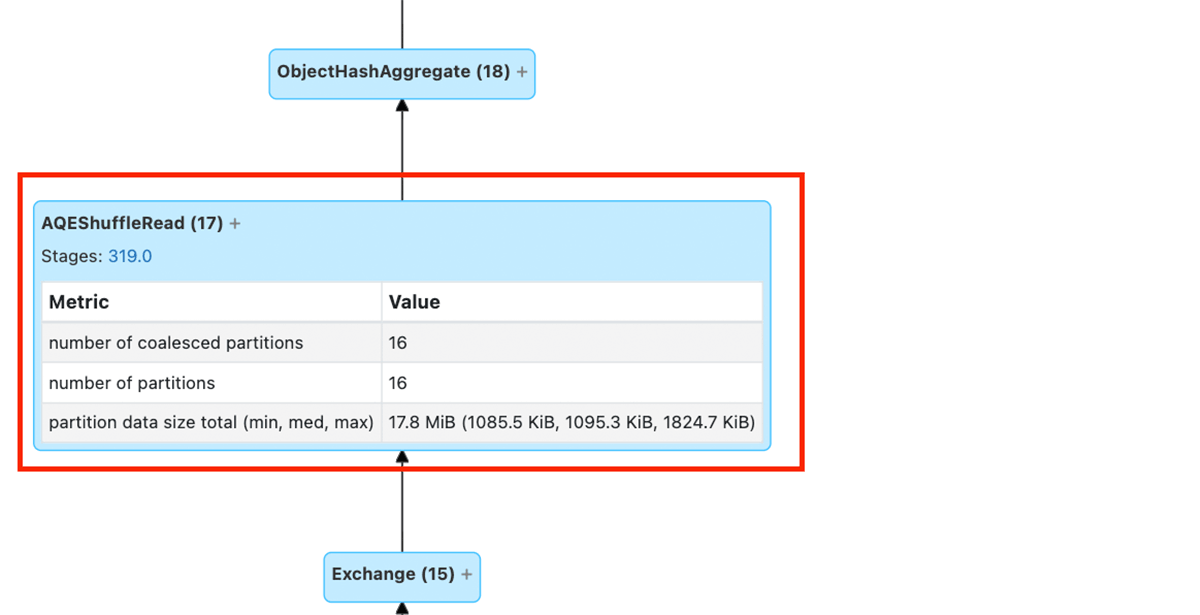
この例でプランのバージョンを比較すると、AQEがSortMergeJoinからBroadcastHashJoinに動的に切り替えて、結合を大幅に高速化できることもわかります。
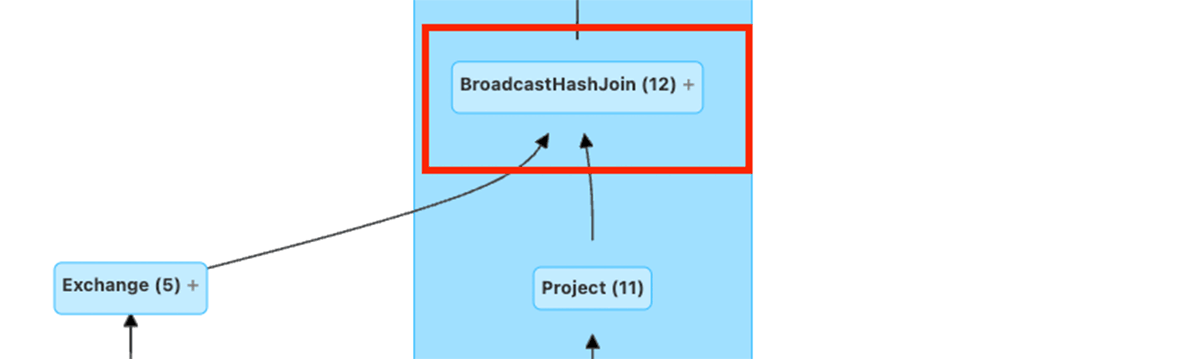
以下に示すように、クエリプランのリーフノードの1つはRDDスキャンで、ステートフルな演算子を含む可能性のあるストリーミングサブプランから、マテリアライズされたマイクロバッチデータを読み取ります。
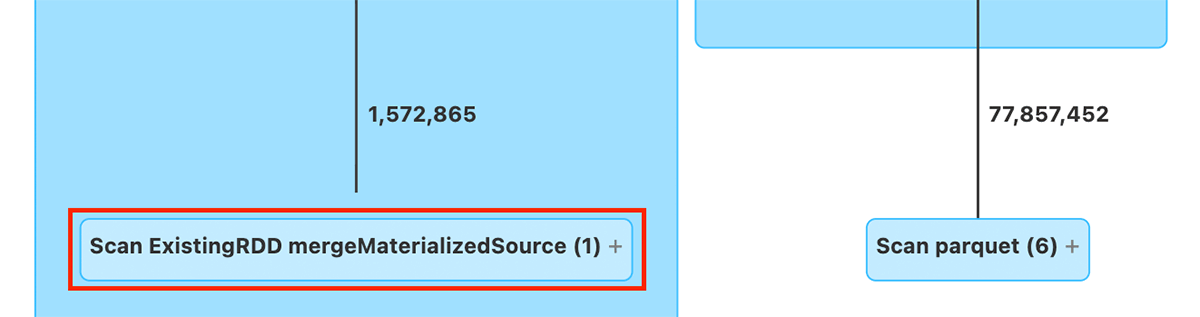
同じクエリーをRDD Scanで��はなくPhotonで実行した場合、実行計画にはデータストリームソースを含むすべてのダウンストリームオペレータが組み込まれます。
パフォーマンス結果
AQEを活用することで、高価な結合や集約によってボトルネックになっているステートレスベンチマーククエリは、通常1.2倍から2倍のスピードアップを経験し、特に静的計画が不十分だったクエリは16倍のスピードアップを経験しました。高速化したクエリでは、パーティションサイズの再最適化と動的結合ストラテジーの選択が確認されました。予想通り、AQEはステートフルなクエリや変換の少ないクエリのパフォーマンスには影響を与えませんでした。
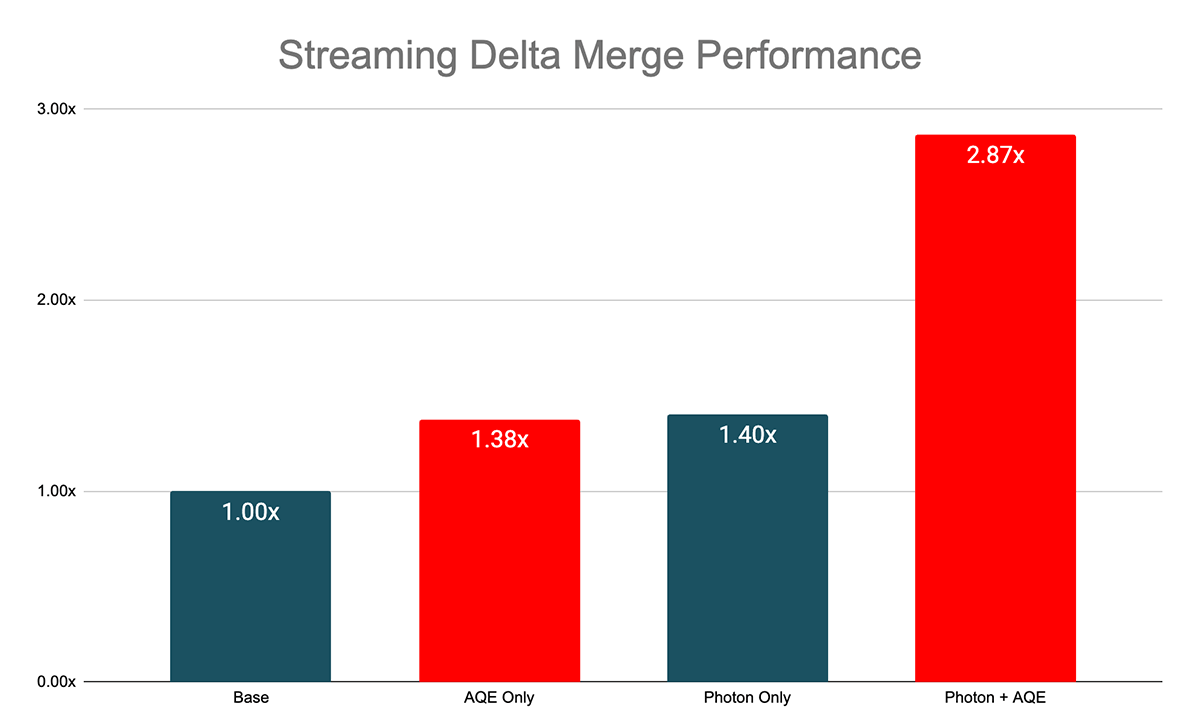
AQEと結合の再最適化によって可能になる追加の動的フィルターは、一般的なストリーミングのユースケースであるDelta MERGEで特に効果を発揮します。下図に示すように、内部ベンチマークでは、AQEを使用した場合は中央値で1.38倍、AQEとPhotonエンジンを併用した場合は2.87倍のスピードアップを示しました。
Looking Forward
ストリーミングにおけるAQEは、非PhotonクラスタのRuntime 13.1およびPhotonクラスタのRuntime 13.2でデフォルトで有効になる予定です。ForeachBatchのAQEにより、お客様は、バッチクエリで使用されるのと同じ動的最適化をストリーミングワークロードで利用できるようになりました。また、Adaptive Join FallbackやAQEによって実現され�るその他のAIを活用した機能など、今後のAQEの改良にご期待ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。