実践におけるエージェント的推論:構造化データと非構造化データの理解
によって データブリックス AI 研究チーム による投稿
企業データは、サイロ化された状態ではほとんど役に立ちません。「過去 3 か月間で売上が減少した製品はどれか、また、さまざまな販売サイトの顧客レビューで指摘されている潜在的な関連問題は何か」といった質問に答えるには、データレイク、レビューデータ、製品情報管理システムなど、構造化データと非構造化データが混在するデータソース全体で推論を行う必要があります。このブログでは、Databricks Agent Bricks Supervisor Agent (SA) が、構造化データと非構造化データのハイブリッドに基づいた多段階の推論を通じて、これらの複雑で現実的なタスクにどのように役立つかを紹介します。
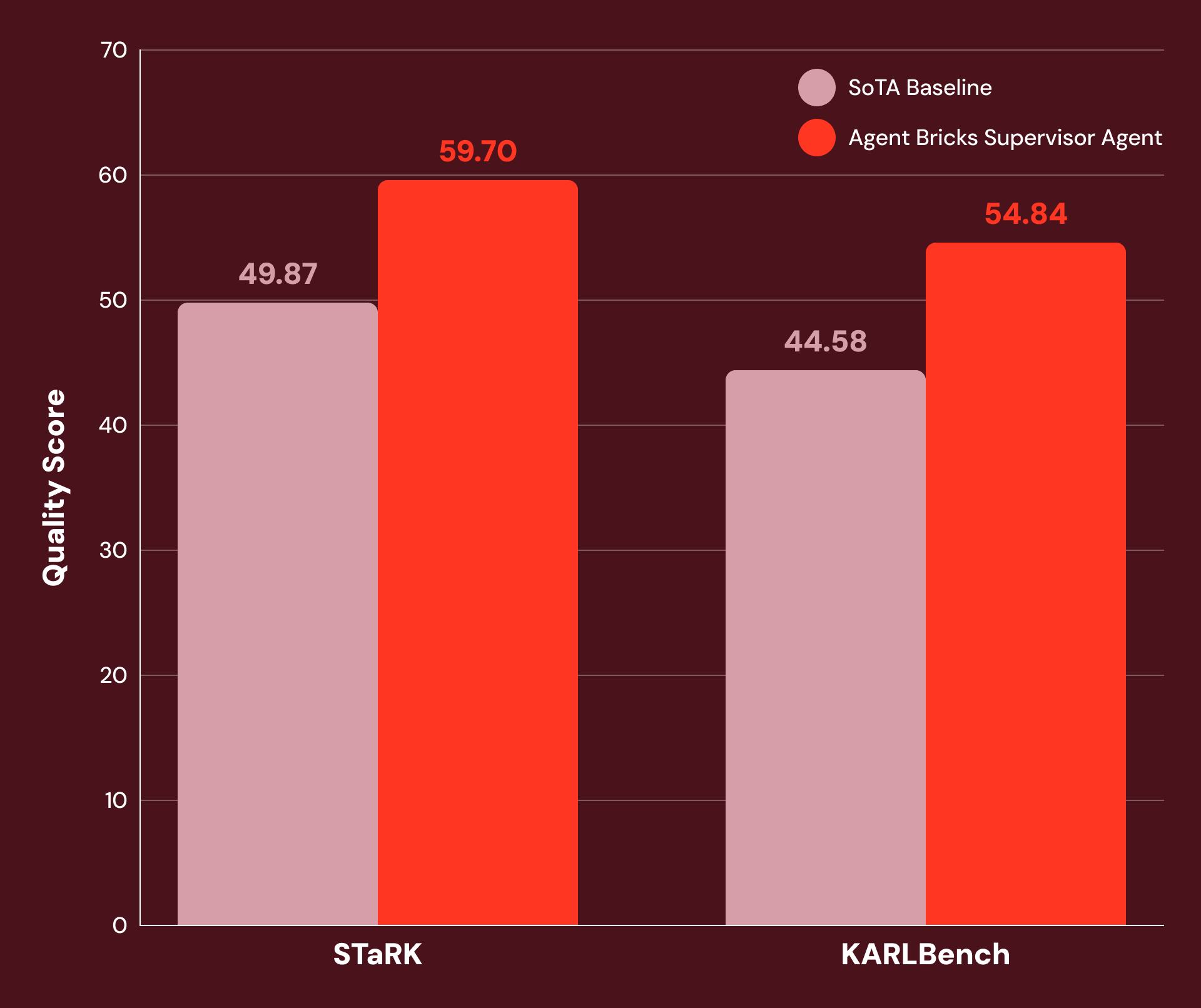
調整された指示と慎重なツール設定により、SAは幅広い知識集約型のエンタープライズタスクで高いパフォーマンスを発揮することがわかりました。図1は、SAがSoTAベースラインに対して以下の点で20%以上の改善を達成したことを示しています。
- STaRK: スタンフォード大学の研究者が公開した、3 つの半構造化検索タスクからなるスイート。
- KARLBench: Databricks が最近公開した、複雑なグラウンデッド推論のためのベンチマークスイート。
Supervisor Agent は、学術検索 (STaRK-MAG で +21%) から生物医学的推論 (STaRK Prime で +38%)、財務分析 (FinanceBench で +23%) まで、経済的に価値のある幅広いタスクで大幅な向上を示しています。
エージェントのセットアップ
Agent Bricks Supervisor Agentは、エージェントとツールをオーケストレーションする宣言型のエージェントビルダーです。これは、マルチステップLLMワークフローを大規模に構築、評価、デプロイするための社内エージェントフレームワークであるaroll上に構築されています。1 arollとSAは、顧客が頻繁に遭遇する高度なエージェントユースケースのために特別に設計されました。
aroll は、簡単な構成変更で新しいツールやカスタム指示を追加でき、数千の並列会話と並列でのツール実行を処理し、さらにクエリーを改良して部分的な回答から復旧するための高度なエージェント オーケストレーションおよびコンテキスト管理技術を組み込んでいます。これらはすべて、今日のSoTAシングルターンシステムでは達成が困難です。
SA はこの柔軟なアーキテクチャ上に構築されているため、カスタムコードを記述する必要なく、最上位の指示の調整やエージェントの説明の改良など、簡単なユーザーキュレーションを通じてその品質を継続的に改善できます。
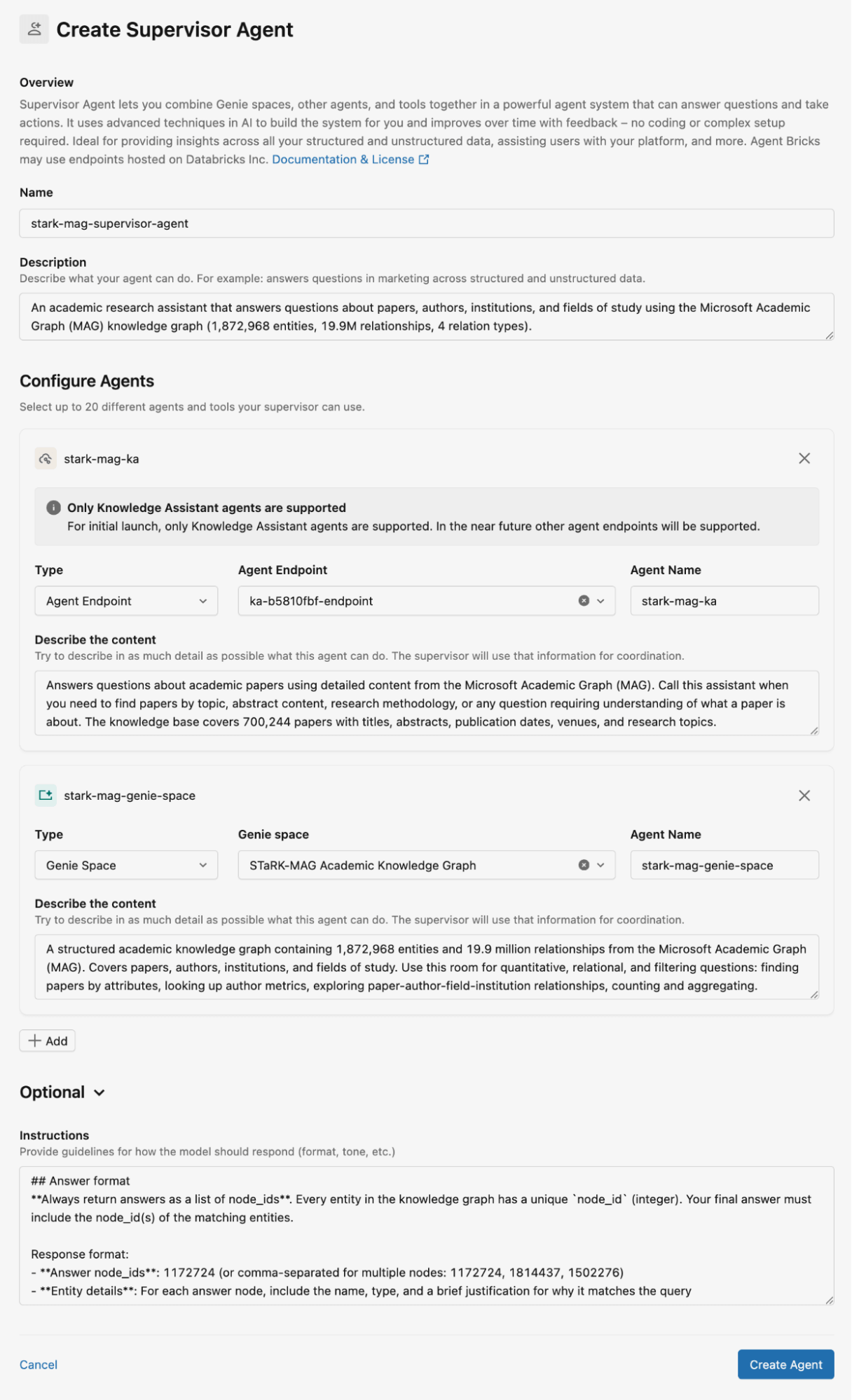
図 2 は、STaRK-MAG データセット用に Supervisor Agent をどのように設定したかを示しています。このブログでは、リレーショナルナレッジベースを格納するために Genie spaces を、検索用に非構造化ドキュメントを格納するために Knowledge Assistant を使用します。すべての Knowledge Assistant と Genie spaces の詳細な説明、およびエージェントの応答に関する指示を提供します。
ハイブリッド推論:構造化と非構造化の融合
構造化データと非構造化データのハイブリッドに基づくグラウンデッド推論を評価するために、3 つのドメインを含む STaRK ベンチマークを使用します。
- Amazon: 製品属性 (構造化) とレビュー (非構造化)
- MAG:引用ネットワーク(構造化)と学術論文(非構造化)
- Prime: 生物医学的エンティティ (構造化) と文献 (非構造化)
例えば、「Find me a paper written by a co-author with 115 papers and is about the Rydberg atom」(115本の論文を持つ共著者が執筆したリュードベリ原子に関する論文を探して)というクエリでは、システムは構造化フィルタリング(「co-author with 115 papers」)と非構造化理解(「about the Rydberg atom」)を組み合わせる必要があります。最良の公開ベースラインは、LLMベースのリランカーを用いたベクトル類似性検索を使用しています。これは強力なシングルターンアプローチですが、データタイプをまたいでクエリーを分解することはできません。公平な比較を確保するため、我々はこのベースラインを現在のSoTA基盤モデルで再実行し、大幅に強力なベースラインを用意しました。
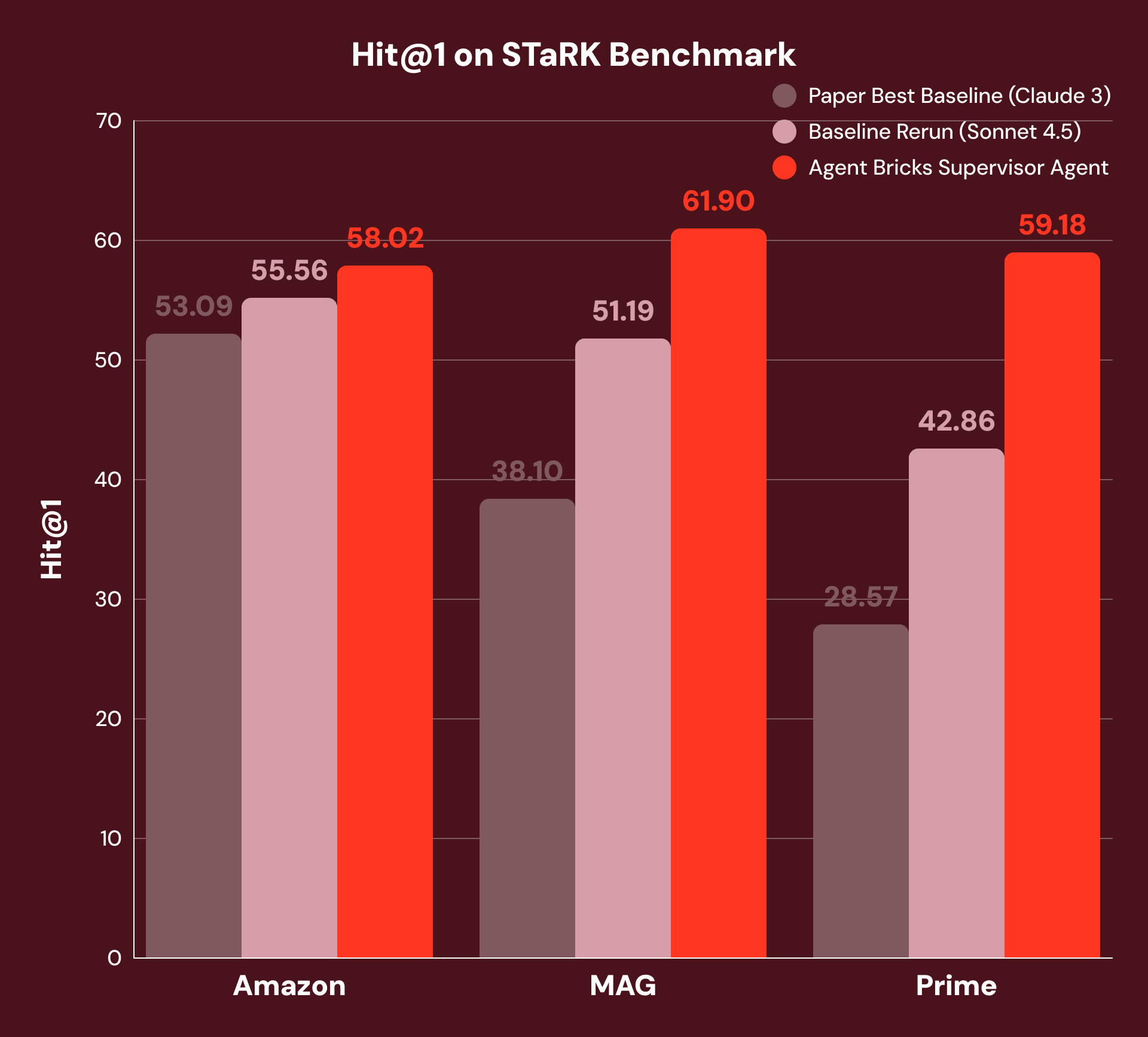
我々のアプローチでは、SAは各質問を分解し、サブ質問を適切なツールにルーティングし、複数の推論ステップにわたって結果を統合します。図3が示すように、これにより、Amazonで+4%、MAGで+21%、Primeで+38%のHit@1を達成し、元のベースラインの最良のものと、現在のSoTA基盤モデルで再実行した我々のベースラインの両方を上回りました。最も大きな改善が見られたのはMAGとPrimeで、そこでは回答に構造化データと非構造化データの最も緊密な統合が必要とされます。
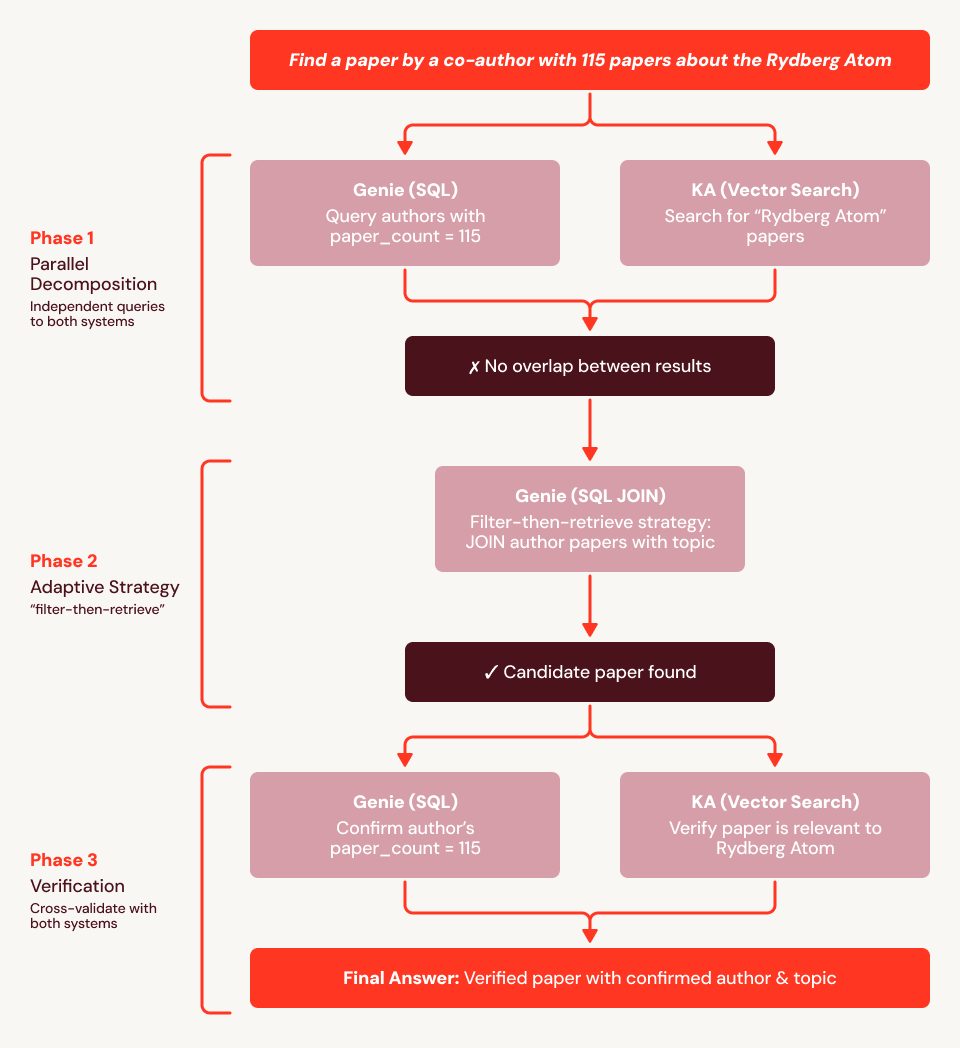
上記の質問例(「論文を115本執筆した共著者が書いた、リュードベリ原子に関する論文を探してください」)を使用すると、埋め込みが構造的制約(「共著者の論文がちょうど115本である」)をエンコードできないため、ベースラインは失敗することがわかります。図4に、SAの実行トレースを示します。まず、Genieを使用して論文数が115本の著者759人すべてを検索し、Knowledge Assistantを使用してリュードベリ論文を取得します。その後、2つのセットを相互参照します。重複が見つからない場合、SAは適応します。論文数が115本の著者のリストと、タイトルまたはアブストラクトに「Rydberg」を含むすべての論文に対してSQL JOINを発行し、構造化データから直接回答を導き出します。次に、Knowledge Assistant を呼び出して関連性を検証し、Genie を呼び出して著者の論文数を確認して、正しい論文を正常に返します。
知識集約型タスクにおけるエージェントの利点
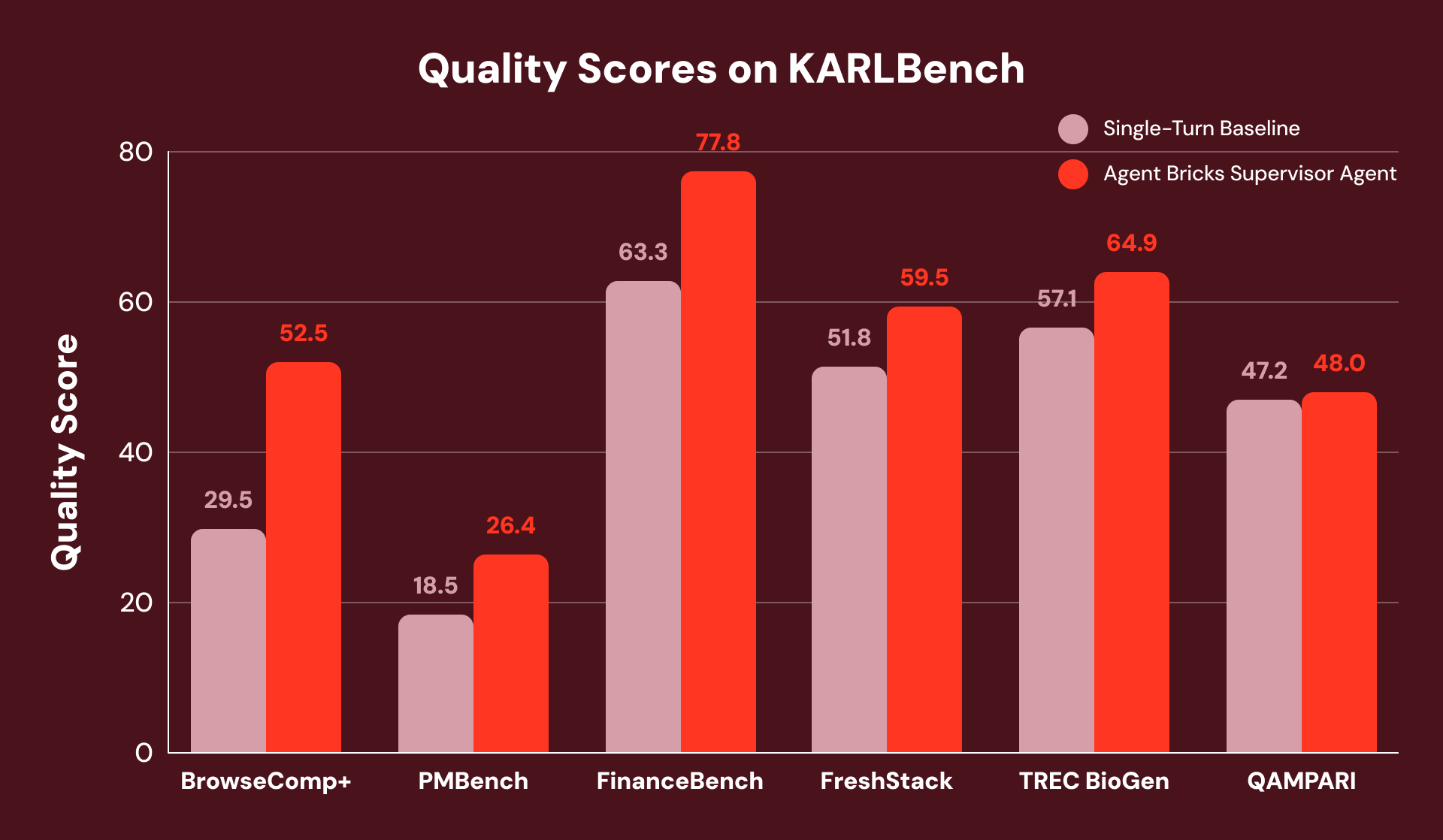
構造化データが不要な状況でAgent Bricks SAのパフォーマンスを(STaRKの最良の公開ベースラインに類似した)強力なシングルターンベースラインと比較するために、我々はKARLBenchを使用して評価しました。KARLBenchは、様々な検索能力と推論能力をまとめてストレステストする、グラウンデッド推論ベンチマークスイートです。
- BrowseComp+: 消去法�によるエンティティ検索
- TREC BioGen: 生物医学文献の統合
- FinanceBench: 財務書類に関する数値的推論
- QAMPARI:網羅的なエンティティリコール
- FreshStack:ドキュメントに基づく技術的なトラブルシューティング
- PMBench: Databricks の社内エンタープライズ文書の理解
全体として、Supervisor Agentは6つすべてのベンチマークで一貫した向上を達成しており、網羅的な分析または自己修正のいずれかを必要とするタスクで最大の改善が見られました。FinanceBenchでは、ギャップを検出してクエリーを再定式化することにより、初期の不完全な検索から回復し、全体で+23%の改善をもたらしました。
たとえば、BrowseComp+ の質問には、それぞれ 5~10 個の連動する制約があります。例: 「ロシアのクラブを去り (2015~2020 年)、ヨーロッパに帰化し (2010~2016 年)、身長が 1.95~2.06m の選手を見つけてください。」COVID の影響で延期されたオリンピックでのブロック成功率は?」シングルターンのベースラインは、選手を正しく特定する 1 つの広範なクエリーを発行しますが、詳細な統計ドキュメントを提示できず、質問に失敗します。
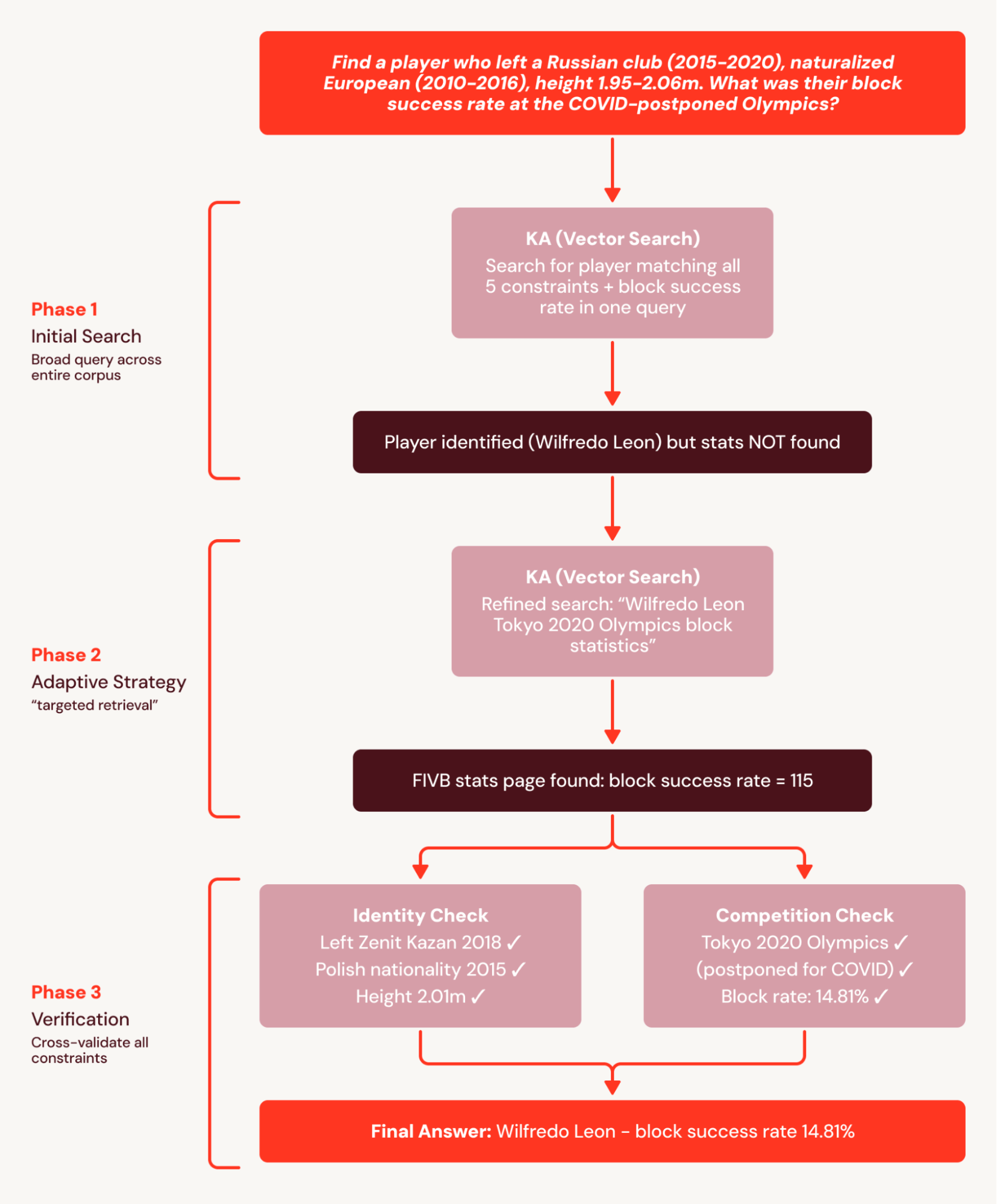
SA はこのタスクを連携した検索プランに分割し、そのプランを検索可能なサブセットに分解します。これにより、統計が後続の検索で取得されるために見つからないという、シングルターンのベースラインにおける失敗を回避します。その結果、SA は +78% の相対的な改善を達成します。
PMBenchの別の例では、「what are the guardrail types customers are using」(顧客が使用しているガードレールのタイプは何か)という質問の1つがあり、網羅的な回答を得るためには、10以上の顧客会話ドキュメントにわたる26個のナゲット(定義はKARLのレポートを参照)が必要です。シングルターンベースラインは、1つの質問ですべてのガードレールカテゴリを横断して検索できないため、顧客の言及を1つしか見つけられません。SAは各ガードレールカテゴリ(「PII detection」、「hallucination」、「toxicity」、「prompt injection」)を個別に検索し、その過程で段階的により多くの顧客の言及を表面化させます。
学んだこと
エクスペリメント全体の結果から、いくつかの重要なポイントが示唆されます。
- 適切なツールとデータ表現へのアクセスが与えられれば、グラウンデッド推論エージェントは構造化データと非構造化データのハイブリッド検索から恩恵を受けることができます。
- 高品質な検索シナリオでは、たとえ再ランキングの段階で SoTA モデルが使用される場合でも、異種データセット上にカスタム RAG パイプラインを構築することは避けるべきです。各ステップでエージェントが適切なデータソースを選択し、その有用性を考察する多段階の推論は、パフォーマンスを向上させるために不可欠です。
- Databricks Supervisor Agent によって実装されたもののような、エージェント構築への宣言的アプローチは、使いやすさと品質の間の良好なトレードオフを提供します。
我々は、Databricks Supervisor Agentを使用して、3つのSTaRKドメインすべてとKARLBenchの6つの非構造化データセット用のエージェントを構築します。これら9つのタスクで異なるのは指示とツールだけで、これらの多様なデータセットを処理するためにカスタムコードは不要でした。したがって、新しいエンタープライズタスクのために高パフォーマンスなエージェントを構築することは、新しいシステムをゼロから構築するのではなく、主に正確な指示を作成し、適切なツールを備え付けることの問題です。
Agent Bricks Supervisor Agent はすべての顧客にご利用いただけます。Agent Bricks SA の使用は、エージェントを作成して、既存のエージェント、ツール、MCP サーバーに接続するだけで簡単に起動できます。Supervisor Agent が本番運用のワークフローにどのように適合するかを確認するには、ドキュメントをご覧ください。
著者: Xinglin Zhao、Arnav Singhvi、Mark Rizkallah、Jonathan Li、Jacob Portes、Elise Gonzales、Sabhya Chhabria、Kevin Wang、Yu Gong、Moonsoo Lee、Michael Bendersky、Matei Zaharia。
1aroll が合成データ生成、スケーラブルな RL トレーニング、エージェントタスクのためのオンライン推論にどのように使用されるかの詳細については、当社の最近の出版物「KARL: Knowledge Agents via Reinforcement Learning」をご参照ください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。