DatabricksおよびApache Spark™上でのRayオートスケーリングのサポートを発表
Databricks Auto Scalingの活用によるRayワークロードのオートスケール
によって Weichen Xu, Puneet Jain 、 Ben Wilson による投稿
Rayはオープンソースの統合コンピュートフレームワークで、分散環境におけるAIとPythonワークロードのスケーリングを簡素化します。 Databricks上でのRayの実行サポートを導入して以来、予測や深層強化学習からLLMの微調整に至るまで、数多くのお客様が機械学習のユースケースの導入に成功しています。
Rayバージョン2.8.0のリリースに伴い、Ray on Databricksのオートスケーリングサポートが追加されました。 オートスケーリングは、変動する需要に対してリソースを動的に調整することができるため、不可欠です。 処理のニーズは時間と共に大きく変化する可能性があるため、オートスケーリングにより、最適なパフォーマンスとコスト効率を保証し、手動介入を必要とせずに計算能力と費用のバランスを維持するのに役立ちます。
Databricks上のRayオートスケーリングは、必要に応じてワーカーノードを追加または削除することができ、Sparkフレームワークを活用して分散コンピューティング環境におけるスケーラビリティ、コスト効率、応答性を向上させます。 この統合されたアプローチは、複雑な権限、クラウドの初期化スクリプト、ログの設定を定義する必要がないため、OSSオートスケールを実装する代替案よりもはるかにシンプルです。 完全に管理され、本番稼動可能な統合オートスケーリングソリューションにより、Rayワークロードの複雑さとコストを大幅に削減することができます。
オートスケールを有効にしてDatabricks上にRayクラスタを作成する
Rayの最新バージョンをインストールするだけで開始できます。
次のステップでは、`ray.util.spark.setup_ray_cluster() `関数を使用して、これから開始するRayクラスタの設定を行います。 オートスケール機能を利用するには、Rayクラスタが使用できるワーカーノードの最大数を指定し、割り当てられたコンピュートリソースを定義し、オートスケールフラグをTrueに設定します。 さらに、Databricksクラスタが自動スケーリングを有効にして起動されていることを確認することが重要です。 詳しくはドキュメントをご覧ください。
これら��のパラメータを設定した後、Rayクラスタを初期化すると、オートスケーリングはDatabricksのオートスケーリングと全く同じように機能します。 以下は、オートスケール機能を持つRayクラスタのセットアップ例です。
この機能は、Databricks Runtimeバージョン14.0以上を実行しているDatabricksクラスタと互換性があります。
Spark上でRayクラスタを構成するために利用可能なパラメータの詳細については、setup_ray_clusterドキュメントを参照してください。 Rayクラスタが初期化されると、RayヘッドノードがRayダッシュボードに表示されます。
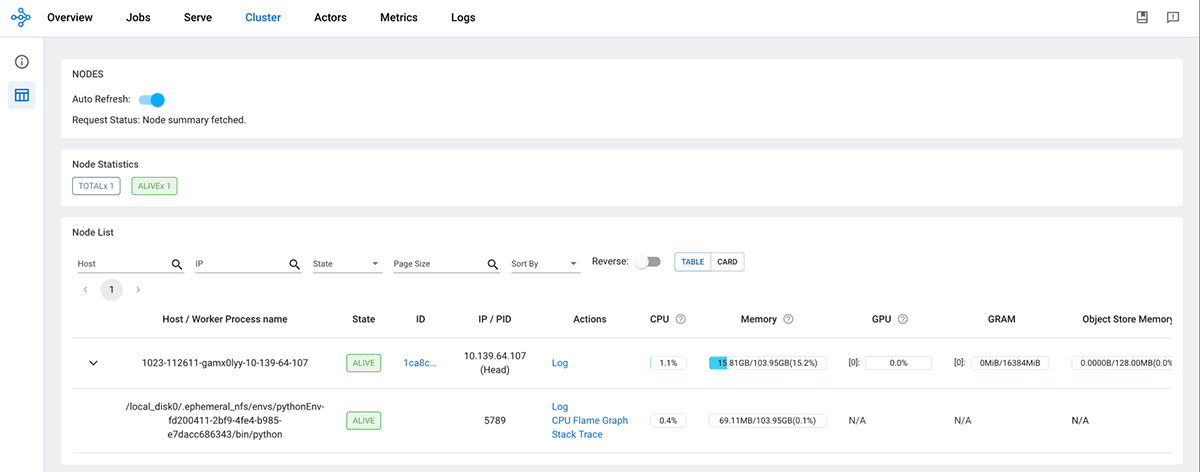
ジョブがRayクラスタにサブミットされると、Ray Autoscaler APIは必要なCPUとGPUコンピュート要件のタスクをサブミットしてSparkクラスタにリソースを要求します。 Sparkスケジューラは、現在のクラスタリソースがタスクの計算要求を満たすことができない場合にワーカーノードをスケールアップします。タスクが完了し、保留中の追加タスクがない場合にはクラスタをスケールダウンします。 autoscale_upscaling_speedと autoscale_idle_timeout_minutesパラメータを調整することで、スケールアップとスケールダウンの速度を制御できま��す。 これらの制御パラメータの詳細については、マニュアルを参照してください。 処理が完了すると、Rayは割り当てられたリソースをすべてSparkクラスタに戻し、他のタスクやダウンスケーリングのために使用することで、リソースの効率的な利用を保証します。
オートスケーリングプロセスを示すために、ハイパーパラメータチューニングの例を見てみましょう。 この例では、CIFAR10データセットでPyTorchモデルを学習します。コードはRayのドキュメントを参考にしました。
チューニングしたいPyTorchモデルを定義することから始めます。
データローダーを独自の関数でラップし、グローバルデータディレクトリを渡します。 こうすることで、異なる試験間でデータディレクトリを共有することができます。
次に、コンフィグを取り込み、トーチモデルのトレーニングループを1回実行する関数を定義します。 各トライアルが終了すると、重みをチェックポイントし、`train, report` APIを使用して評価された損失を報告します。 モデルの損失特性を改善しない効果のない試行をスケジューラが停止できるようにするためです。
次に、設定ファイルで指定された合計エポック数だけ実行される学習ループを定義します:
- トレーニングループ - 学習データセットを繰り返し、最適なパラメータに収束させようとします。
- 検証/テストループ - テストデータセットを繰り返し、モデルのパフォーマンスが向上しているかどうかをチェックします。
最後に、まずチェックポイントを保存し、いくつかのメトリクスをRay Tuneに報告します。 具体的には、検証の損失と精度をRay Tuneに送り返します。 Ray Tuneは、これらのメトリクスを使用して、どのハイパーパラメータ構成が最良の結果につながるかを決定します。
次に、与えられたハイパーパラメータに対してオプティマイザが選択する探索空間を指定することで、チューニング作業を開始するための主要コンポーネントを定義します。
探索空間の定義
以下の設定は、ハイパーパラメータとその検索選択範囲を辞書として表現しています。 指定されたパラメータタイプごとに、適切なセレクタアルゴリズム(定義されるパラメータの性質に応じて、sample_from、loguniform、choiceなど)を使用します。
各試行で、Ray Tuneはこれらの探索空間からパラメーターの組み合わせをランダムにサンプリングします。 上で定義したコンフィグの範囲内で各�パラメータの値を選択した後、グループの中で最もパフォーマンスの高いモデルを見つけるために、複数のモデルを並行して訓練します。 うまく機能していないパラメータ選択の反復を短絡させるために、ASHASchedulerを使用します。このASHASchedulerは、効果のないトライアルを早期に終了させます。
APIを調整する
最後に、Tuner APIを呼び出して実行を開始します。 トレーニング開始メソッドを呼び出す際に、トライアルごとにRay Tuneに使用を許可するリソース、チェックポイントのデフォルトの保存場所、反復最適化中に最適化するターゲットメトリックを定義する追加設定オプションを渡します。 Ray Tuneで使用可能な各種パラメーターの詳細については、こちらをご参照ください。
このコードを特定のリソース制約を宣言して実行するとどうなるかを確認するため、cpus_per_trial = 3、gpu = 0、total_epochs = 20を使用して、CPUのみで実行をトリガーしてみましょう。
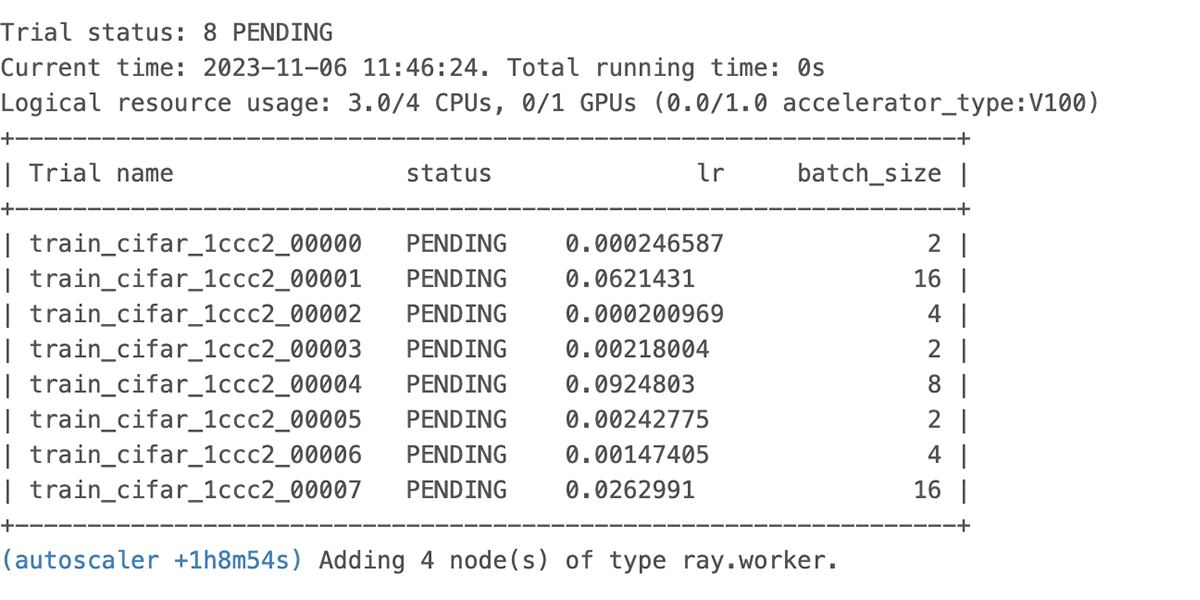
上図のようにオートスケーラーがリソースのリクエストを開始し、下図のように保留中のリソースがUIに記録されるのがわかります。
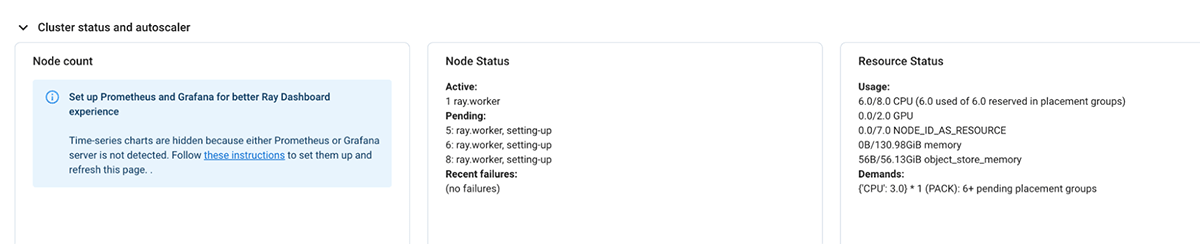
Rayクラスタによるリソースの現在の需要を満たすことができない場合、同様にdatabricksクラスタのオートスケーリングを開始します。

最後に、ジョブの出力が終了すると、いくつかの悪い試行が早期に終了され、計算量の節約につながったことがわかります。
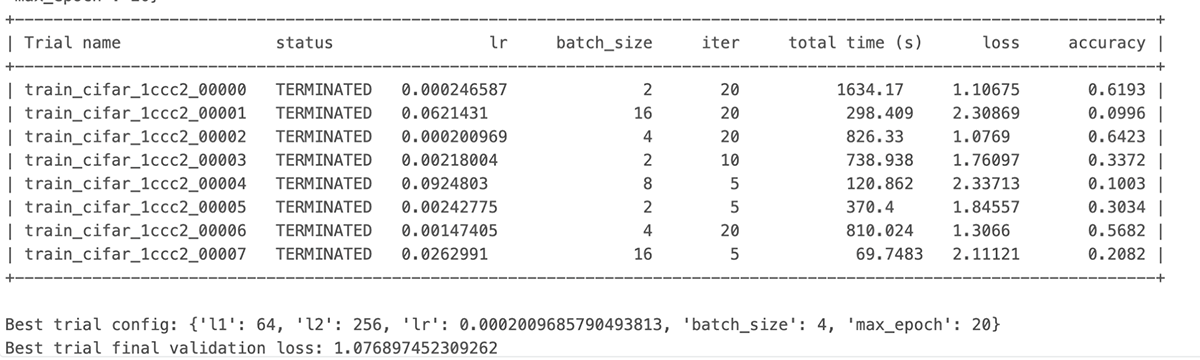
GPUリソースを使用しても、コードを変更することなく、同じ処理を実行できます。 ノートブックをクローンして、あなたの環境で自由に実行してください:
次の記事
Rayワークロードの自動スケーリングをサポートすることで、RayとDatabricksの統合をさらに強化し、ダイナミックなワークロードのスケーリングを支援します。 この統合のロードマップは、さらにエキサイティングな展開をお約束します。 続報にご期待ください!
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。