Apache Spark™ 3.5におけるArrowに最適化されたPython UDF
によって Xinrong Meng, Hyukjin Kwon, 植品拓也 、 アラン・フォルティング による投稿
Apache Spark™では、Pythonのユーザー定義関数(UDF)は最も人気のある機能の1つです。 ユーザーは、独自のデータ処理ニーズに合わせてカスタムコードを作成することができる。 しかし、シリアライズとデシリアライズのためにcloudpickleに依存している現在のPython UDFは、特に大きなデータの入出力を扱うときに、パフォーマンスのボトルネックに遭遇する。
Apache Spark 3.5とDatabricks Runtime 14.0では、Arrowに最適化されたPython UDFを導入し、パフォーマンスを大幅に改善しました。 この最適化の核となるのが、標準化された言語横断的なカラム型インメモリデータ表現であるApache Arrowである。 Arrowを利用することで、これらのUDFは、従来の遅いデータ(デ)シリアライゼーションの方法をバイパスし、JVMとPythonプロセス間の迅速なデータ交換をもたらします。 Apache Arrowの豊富な型システムにより、これらの最適化されたUDFは、より一貫性のある標準化された型強制の処理方法を提供します。
Python UDFのアロー最適化はオプションであり、ユーザーは"functions.udf" の"useArrow"booleanパラメータを使用することで、個々のUDFに対してアロー最適化を有効にするかどうかを制御することができます。 例を以下に示す:
また、Sparkの設定により、SparkSession全体のすべてのUDFに対してArrow最適化を�有効にすることができます:"spark.sql.execution.pythonUDF.arrow.enabled" 、 以下の通りである:
より速い(デ)シリアライゼーション
Apache Arrowは、異なるシステムやプログラミング言語間で効率的なデータ交換を提供するカラム型インメモリーデータフォーマットである。 行全体をオブジェクトとしてシリアライズするPickleとは異なり、Arrowは列指向のフォーマットでデータを格納するため、より優れた圧縮性とメモリ局所性を実現し、分析ワークロードに適している。
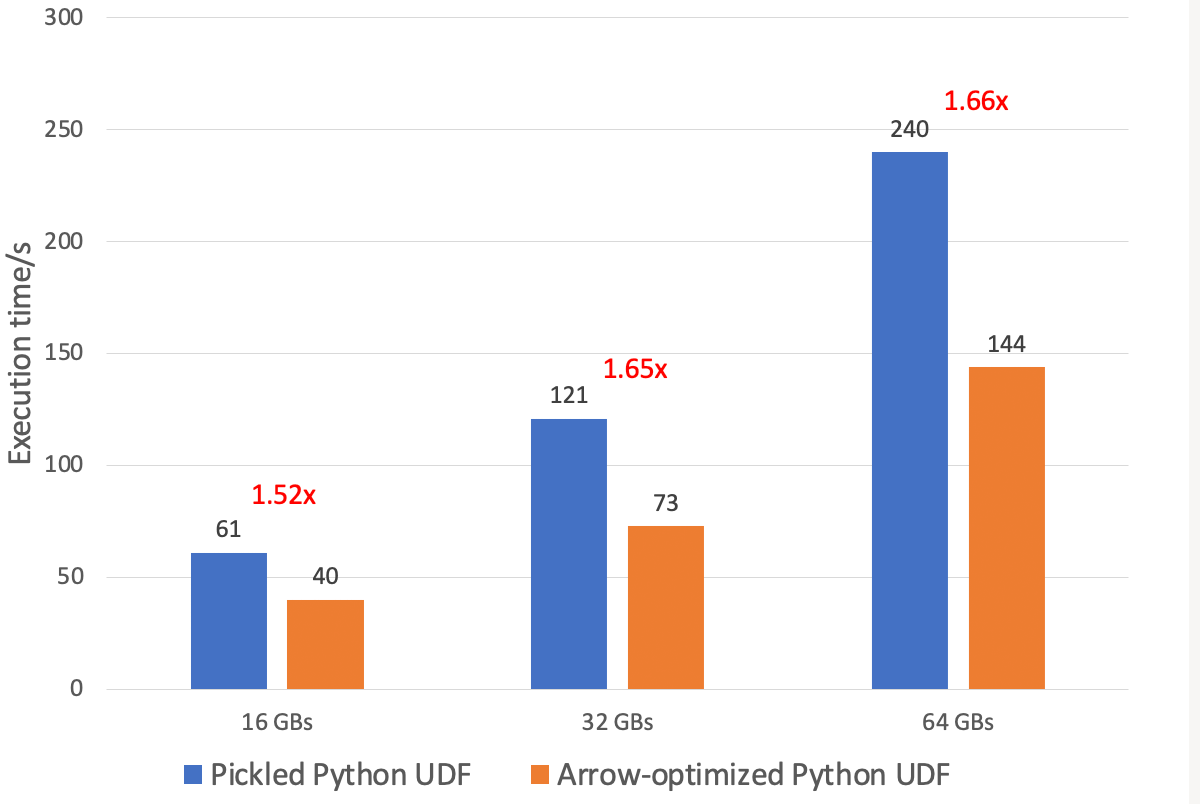
以下のグラフは、Arrowに最適化されたPython UDFが、異なるサイズの入力データセットで単一の変換を実行した場合のパフォーマンスを示しています。 クラスタは3台のワーカーと1台のドライバで構成され、クラスタの各マシンは16個のvCPUと122GiBのメモリを持つ。 Arrowに最適化されたPython UDFは、Python UDFのpickleよりも1.6倍高速です。
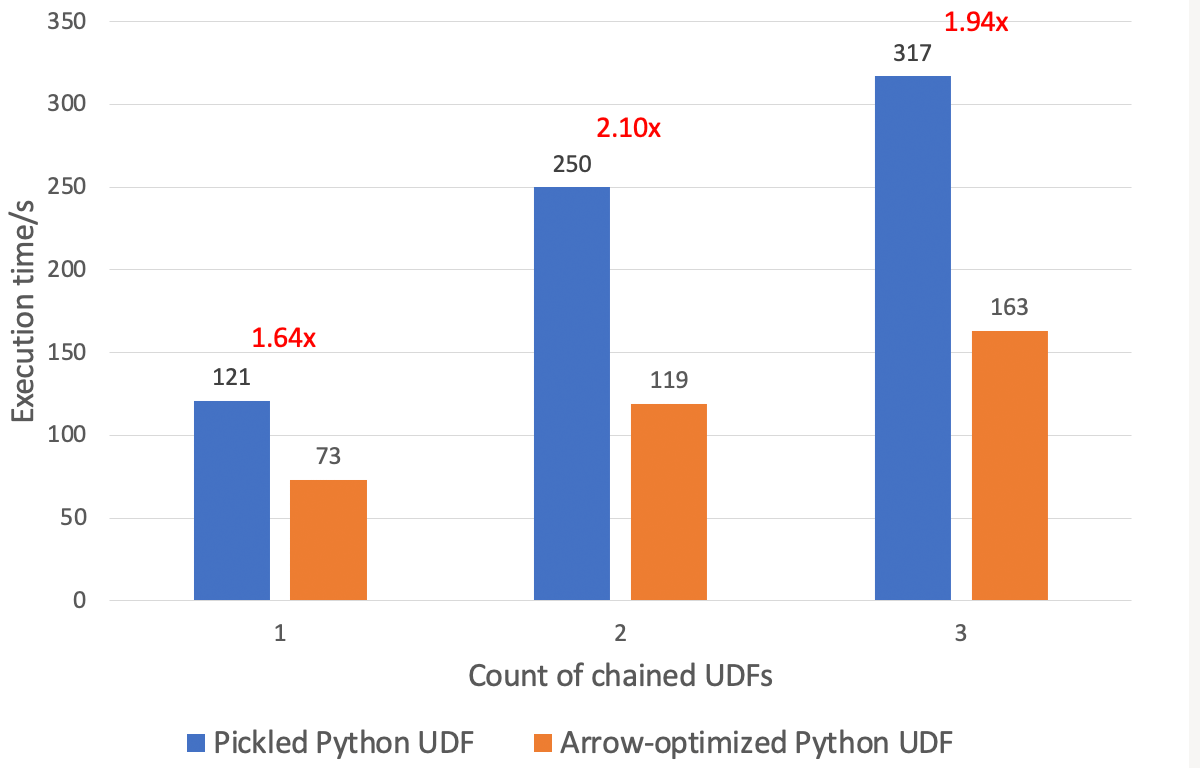
Arrowに最適化されたPython UDFは、UDFを連鎖させる上で大きな利点がある。 以下に示すように、同じクラスタにおいて、Arrowに最適化されたPython UDFは、32GBのデータセットにおいて、Python UDFのpickleよりも1.9倍高速に実行できます。
完全なベンチマークと結果はこちらを参照。
標準型強制
UDFの型の強制は、UDFによって返されるPythonの値が、ユーザーが指定した戻り値の型と一致しない場合に、問題を引き起こす。 残念なことに、デフォルトのpickle Python UDFの型強制には、型が不一致の場合のフォールバックとしてNoneに依存するような、ある種の制限があり、潜在的な曖昧さやデータの損失につながります。 さらに、日付、datetime、タプルを文字列に変換すると、あいまいな結果になることがある。 Arrowに最適化されたPython UDFは、Arrowのよく定義された型強制のルールセットを活用することで、これらの問題に対処します。
以下に示すように、Arrowに最適化されたPython UDF(useArrow=True) は、文字列として格納された整数を、指定された"int" に戻すことに成功するが、pickle Python UDF(useArrow=False) は、"NULL" に戻ってしまう。
別の例を以下に示す。Arrowに最適化されたPython UDF(useArrow=True)は、日付を文字列に正しく強制するのに対し、pickle Python UDF(useArrow=False)は、基礎となるJavaオブジェクトを公開することで、あいまいな結果を返す。
Pickleと比較して、Arrowの型強制は、変換処理中に可能な限り多くの情報と精度を維持することを目的としている。
型強制に関するPickled Python UDFとArrow最適化Python UDFの包括的な比較はこちらを参照してください。
まとめ
Arrowに最適化されたPython UDFは、UDFの入出力の(デ)シリアライゼーションにApache Arrowを利用し、デフォルトのpickle Python UDFと比較して(デ)シリアライゼーションが大幅に高速化されます。 さらに、Apache Arrowの仕様に従って型の強制ルールを標準化している。 Arrow に最適化された Python UDF は Spark 3.5 から利用可能です。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。