Databricksでのモバイルゲーム向けA/Bテスト分析フレームワークの構築
HARDlightが自動統計モデリング、ガバナンスされたインサイト、日次更新ダッシュボード、LLM生成要約で実験分析をどのようにスケールアップしたか。
によって Sanjay Ashok, Jack Holdsworth, Tingting Wan, Joel Dias, Richard Carr 、 Monika Kolodziejczyk による投稿
- データから意思決定へ:Sega HARDlightがDatabricks上でA/Bテスト分析を自動化した方法。標準化された実験取り込み、統計モデリング、結果公開により、手作業を削減し、追加の人員なしで月間実験能力を2倍にしました。
- すべてのオーディエンスのためのインサイト:LLMによる要約を備えた日次更新モニタリングと、組織全体で実行可能なインサイトへのアクセスを民主化する、段階的に詳細化されたメトリクス、診断、推奨アクション。
- 透明性による信頼:一貫した統計的推論とアクセスしやすいAI/BIビューにより、チームは結果を理解し、自信を構築し、実験に対する共有された科学的アプローチを採用することができました。
はじめに
モバイルゲームスタジオは、ゲームプレイ、収益化、ライブオペレーションを改善するために継続的な実験に依存しています。実験が拡大するにつれて、分析がボトルネックになることがよくあります。結果は手動でつなぎ合わされ、統計的手法はアナリストによって異なり、重要なシグナルが出現してから数日後にインサイトが届きます。時間の経過とともに、これは摩擦を生み出します。イテレーションが遅くなり、結論が一貫せず、A/Bテストの信頼できる意思決定ツールとしての信頼性が低下します。
課題
HARDlightにとって、課題はスピードだけでなく、信頼性でもありました。異��なるアプローチは異なる解釈につながり、連携を困難にし、科学的な意思決定ツールとしての実験への信頼を弱めました。一部のステークホルダーは単純な日次ステータスを必要とし、他のステークホルダーはプレイヤーの行動やビジネスへの影響を理解したいと考え、少数のグループは特定のゲームレバーの詳細な検証を必要としました。既存のダッシュボードとレポートは、これらのニーズの全範囲を効果的に満たすのに苦労していました。実験を拡大するには、HARDlightは推論を標準化し、さまざまなレベルの深さで結果をアクセス可能にし、共有された科学的な意思決定プロセスとしてのA/Bテストへの信頼を再構築する必要がありました。
これに対処するために、HARDlightはDatabricksネイティブのA/Bテスト分析フレームワークを構築し、実験データから意思決定準備のできたインサイトへのパスを自動化しました。統計分析は、再現可能で透明性の高い方法でアップストリームで実行され、Databricks AI/BIは、LLM生成の概要から始まり、徐々に詳細なビューでさらに深く探索できる日次更新エクスペリエンスを通じて結果を公開しました。各実験の終わりに、結果はフリーズされ保存され、テストが終了した後も意思決定、コンテキスト、学習が利用可能であることを保証しました。
ソリューション: Databricksでの自動A/Bテスト
HARDlightのフレームワークは、取り込みから意思決定サポートまで、実験を自動化します。Databricks内では、実験定義とテレメトリが標準化され、統計モデリングが一貫して適用され、結果は日次更新されるレイヤードダッシュボードに公開されます。最上部のLLM概要は、アク��セスしやすいビューを提供し、より深いセクションは、専門家ユーザー向けのKPI、診断、推奨アクションを公開します。
Databricksの選択は、チーム全体でのガバナンスと再現性を可能にします。Unity Catalogは、実験アセットの権限とリネージのための単一のコントロールプレーンを提供します。Spark Declarative Pipelinesは、実験の取り込みと変換のための信頼性の高いパイプラインをオーケストレーションします。MLflowは、再現可能な分析のための実験追跡とモデルパッケージングをサポートします。これらの機能は together、Lakehouseでデータと分析を管理され、一貫性があり、運用しやすい状態に保ちます。
主要なイノベーションは、実行終了時の「フリーズされたダッシュボード」です。次の更新にロールオンするのではなく、フレームワークは最終スナップショットと、推奨されるアクションとともに下された決定を保持します。これにより、過去の実験からの学習が制度化され、ステークホルダーはあいまいさなしに結果を再訪できるようになります。
技術アーキテクチャ
実験フレームワークは、データ処理、統計推論、消費を分離するDatabricksネイティブシステムとして構築されており、すべての出力はデフォルトで管理され、再現可能に保たれます。この設計により、運用オーバーヘッドを増やしたり、チーム間の解釈を断片化したりすることなく、分析の厳密さをスケールできます。
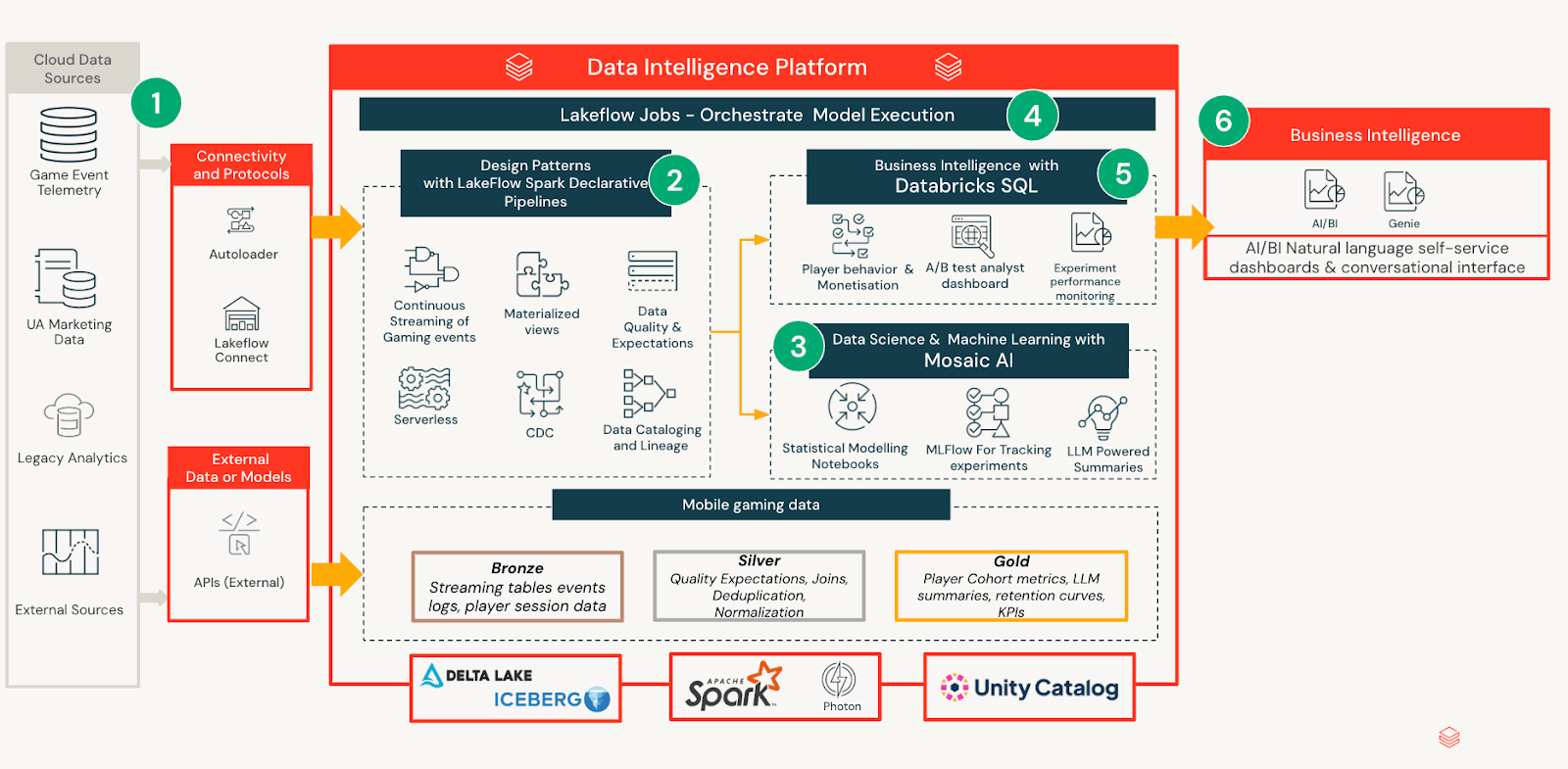
データ取り込みとモデリング
実験定義、プレイヤーテレメトリ、および結果メトリクスは、内部パイプラインから取り込まれ、一貫したスキーマを持つ管理テーブルにキュレーションされます。この標準化により、アナリストとプロダクトチームは、テスト設計や期間に関係なく、実験について一貫して推論できます。ノートブックは、効果推定値、不確実性、およびセグメントレベルの影響を時間とともに計算する統計モデルを計算するために使用されます。ダッシュボードやレポートにロジックを埋め込むのではなく、すべての分析出力は統一された実験分析モデルにマテリアライズされます。これにより、ダウンストリームの消費者が分析を再実行したり結果を再解釈したりすることなく信頼できる安定したセマンティックレイヤーが作成されます。
AI/BI搭載インサイト配信
この管理された分析レイヤーの上に、Databricks AI/BIは実験結果を消費するためのアクセスしやすいインターフェイスを提供します。各日次更新は、非技術的なステークホルダーを対象とした簡潔なLLM概要を生成し、検証済みの統計出力を自然言語に翻訳します。ダッシュボードはプログレッシブ開示を使用します。ユーザーは満足すれば概要で停止するか、好奇心が高まるにつれてメトリクス、診断、セグメント分析のより深いレイヤーを探索できます。このレイヤードエクスペリエンスは、専門家による検証のための分析の深さを維持しながら、迅速なスキャンを可能にします。

実験ライフサイクルと永続化
ライブフェーズ中、ダッシュボードは毎日更新されるため、チームは軌跡を追跡し、シグナルに対応できます。終了時に、ダッシュボードは結果、決定、推奨アクションを保持するためにフリーズされます。このライフサイクルは、オンボーディングを加速し、将来の実験全体での重複分析を削減する監査可能なレコードを作成します。
ダッシュボードレイヤーの説明
ダッシュボードは、ユーザーを実験の結果に明確で意図的な順序で導くように設計されています。単純さから始まり、さらに探求することに興味がある人には徐々に詳細を明らかにします。各セクションは異なる質問に対処しており、読者が必要な情報を取得したら、そこで停止してもまったく問題ありません。
LLM生成の実験概要: ダッシュボードの最上部には、LLM生成の概要があります。実験がライブ中は、早期のシグナルを強調し、時期尚早な結論を出すことなく、物事がどのように進んでいるかの単純で高レベルなビューを提供します。
実験が終了すると、概要の役割が変わります。それは何が起こったのかを明確に説明するものになり、高い信頼性で、優先順位順に、平易な言葉でメトリクスを呼び出します。目標は、チームが結果とその重要性を迅速に理解できるようにすることです。
確認された結果と統計的影響: より技術的なオーディエンスのために、次のセクションでは統計的に有意な結果の構造化されたビューを示します。プレイヤーの生涯価値(LTV)やリテンションなどの��主要なメトリクスは、効果量と信頼レベルとともにリストされ、生の分析を掘り下げることなく結論を検証しやすくなります。
予測される生涯価値への影響: 次に、ダッシュボードは、コントロールグループとバリアントグループのプレイヤー生涯価値への推定影響を示します。不確実性と誤差範囲が明示的に示されており、これらが絶対的な予測ではなく、情報に基づいた推定値であることを強調しています。
収益源別の収益への影響: 結果は、広告、アプリ内購入、および総収益を含む収益ストリーム別に内訳されます。これにより、チームは変更が広範に基づいているか、特定の収益化チャネルによって推進されているかを理解するのに役立ちます。
プレイヤーエンゲージメントと行動: 収益を超えて、リテンションやセッション行動などのエンゲージメントメトリクスが公開され、ビジネス上の利益がプレイヤーエクスペリエンスと長期的な健全性と並んで考慮されることを保証します。
セグメントレベル分析: セグメンテーションは、HARDlightが実験を設計および評価する方法の中心です。このセクションでは、リテンション、進行、またはその他の行動特性によって定義されるかどうかにかかわらず、異なるプレイヤーセグメントが変更にどのように応答するかを示します。これにより、チームはターゲットエクスペリエンスが意図したとおりに機能し、プレイヤーベースの他の部分を損なうことなく機能することを確認できます。
収益化メカニズムとゲームエコノミー: より深いレイヤーでは、実験が広告パフォーマン�ス(プレースメント別)、アプリ内購入パフォーマンス(製品カテゴリ別)、およびハード通貨とソフト通貨のフローの変化(ソースとシンク全体)を含む、ゲーム内システムにどのように影響するかを調査します。
コアゲームループと付録: 最も深いレベルでは、詳細なチャートとテーブルが、レース、キャラクター、アイテムなどのゲームプレイメカニクス、およびサポートする統計ビジュアルをカバーします。このレイヤーは、完全な透明性を求めている、または将来の作業でインサイトを再利用する必要がある専門家ユーザーを対象としています。
これらのレイヤー together、インサイトが自然に展開されます。チームは、答えが明確な場合は迅速に進むことができ、質問が発生した場合はさらに深く掘り下げることができ、すべて同じ管理された信頼できるデータソースから作業します。
この構造は、Databricks AI/BIによって可能になります。これにより、カスタムコードやアナリストのみのワークフローをダッシュボードに埋め込むことなく、複雑な分析出力をクリーンに公開できます。統計結果、予測、セグメントレベルの分析はノートブックでアップストリームで計算され、管理テーブルにマテリアライズされます。一方、AI/BIは、その上に柔軟なプレゼンテーションレイヤーを提供します。これにより、ダッシュボード内でPythonを実行する必要がなくなり、メンテナンスが簡素化され、小規模なチームがシステムをイテレーションおよび進化させることが可能になります。
さらに重要なのは、AI/BIにより、同じ基盤データから非常に異なるオーディエンスにサービスを提供できるようになることです。ナレーション概要、表形式の結果、チャート、および詳細な診断は、ロジックを複製したり解釈を断片化したりすることなく共存できます。これは、ツールの制約により、分析の深さ、アクセスしやすさ、および持続可能性の間でトレードオフを余儀なくされた以前のアプローチからの重要な変化でした。
影響と結果
このフレームワークは、HARDlightでの実験の運用方法を根本的に変えました。分析の自動化と統計的推論の標準化により、データチームは手作業による作業時間を週に8時間以上削減しました。 Databricks Workflowsで実験実行を標準化することにより、チームは以前は各分析で必要とされていた手作業によるセットアップ作業の多くを排除しました。これにより、実験あたり約1日を節約でき、人員を増やさずに月間のA/Bテスト能力をターゲットどおり2倍にすることができました。
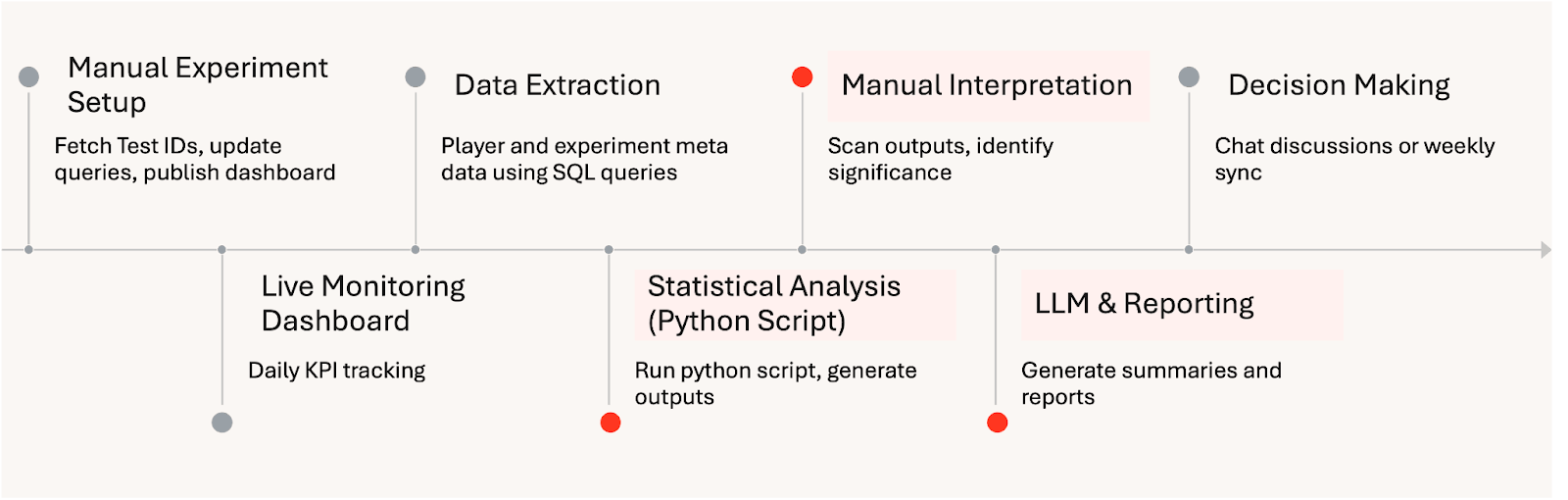
手動実験分析ワークフロー:
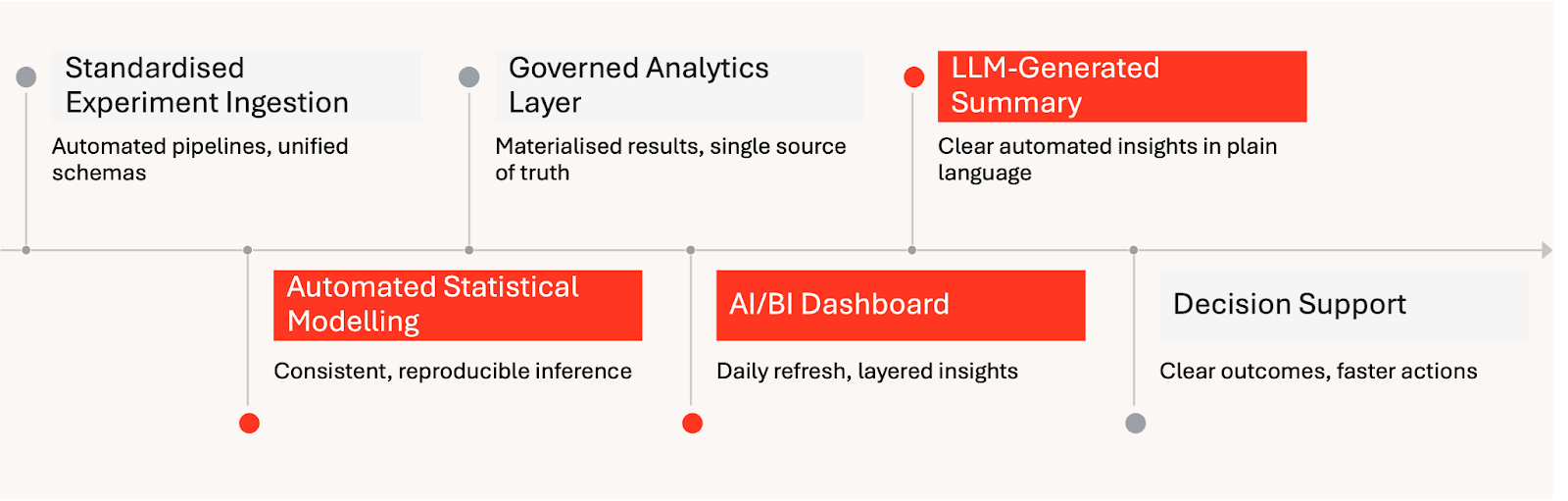
Databricksでの自動実験インサイト配信:
効率化の向上に加えて、このシステムは結果の一貫性と信頼性を向上させました。凍結されたダッシュボードアーカイブは、完了した実験の信頼できる情報源として機能し、繰り返し分析を減らし、チームが過去の決定を完全なコンテキストで容易に再確認できるようにします。これにより、チーム間の履歴知識の維持にかかるオーバーヘッドが大幅に削減されました。
おそらく最も重要なことは、このフレームワークがスタジオ全体でインサイトがどのように消費されるかを変えたことです。複数の実験が並行して実行されるため、チームは現在、数日かかる手動集計と解釈に取って代わる、AI/BI対応の毎日の更新を受け取っています。Genieはダッシュボードで直接利用できるようになり、ユーザーは表示されている内容について質問したり、基盤となるデータモデルを理解する必要なく、自分の言葉で結果を探索したりできるようになります。要約、ガバナンスされたメトリクス、透明性の高い統計出力、および会話型アクセスが組み合わさることで、プロダクト、LiveOps、およびエンジニアリングチーム全体での信頼構築に役立ち、実験を共有された科学的な作業方法として強化しています。
次は何ですか
HARDlightは、予測アプリケーションでフレームワークを拡張し、記述的および推論的分析から将来を見据えたガイダンスへとフレームワークを拡張する予定です。より広範なビジョンは、予測実験とクローズドループ最適化です。Lakehouseを使用して、ガバナンスと一貫性をUnity Catalog、Spark Declarative Pipelines、およびMLflowで維持しながら、仮説からデプロイメントまでのサイクルをさらに自動化します。このダッシュボードファーストのアプローチは、同様のニーズを持つ他のスタジオに大きな影響を与える可能性があり、ガバナンスされたメトリクスと診断の上にLLM要約を重ねることで、Databricksで自信を持って実験をスケーリングできます。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。