現代の臨床試験データインテリジェンスプラットフォームの構築
によって オレクサンドラ・ボフクン 、 ネハ・パンデ による投稿
データが医療の進歩の命綱となる時代において、臨床試験業界は重要な岐路に立たされています。臨床データ管理の現状は、イノベーションを阻害し、命を救う治療法の遅延を引き起こす可能性のある課題に満ちています。
今、我々は前例のない情報の洪水に直面しています。典型的なフェーズIII試験では、現在360万のデータポイントが生成され、これは15年前の3倍以上であり、毎年4000以上の新しい試験が承認されています。この結果、既存のデータプラットフォームはその負荷に耐えられなくなっています。これらの旧式なシステムは、データの孤立、統合の不十分さ、複雑さの極みといった特徴を持ち、研究者、患者、そして医学の進歩自体を阻害しています。この状況の緊急性は、厳しい統計によって強調されています:約80%の臨床試験が募集の課題により遅延または早期終了を迎えており、研究サイトの37%が十分な参加者を募集するのに苦労しています。
これらの非効率性は、製品の開発と発売が遅れるたびに、潜在的な損失が毎日60万ドルから800万ドルに達するという高額なコストを伴います。2032年までに8865億ドルに達すると予想される臨床試験市場は、新世代の臨床データリポジトリ(CDR)を求めています。
臨床データリポジトリ(CDR)の再構想
通常、臨床試験データ管理は専門的なプラットフォームに依存しています。これには多くの理由があります。標準化された当局の提出プロセス、ユーザーが特定のプラットフォームやプログラミング言語に慣れていること、そしてプラットフォームのベンダーが業界のドメイン知識を提供することに依存できることなどが挙げられます。
臨床研究のグローバルな調和と規制による電子提出の導入に伴い、グローバルな臨床開発の枠組み内で理解し、操作することが重要となります。これには、臨床データのライフサイクルを効果的に管理するためのアーキテクチャ、ポリシー、実践、ガイドライン、手順を開発し、実行するため��の標準を適用することが含まれます。
これらのプロセスには以下のようなものがあります:
- データアーキテクチャとデザイン:臨床データリポジトリやウェアハウスのためのデータモデリング
- データガバナンスとセキュリティ:標準、SOP、ガイドラインの管理とアクセス制御、アーカイブ、プライバシー、セキュリティ
- データ品質とメタデータ管理:クエリ管理、データの整合性と品質保証、データ統合、外部データ転送、メタデータの発見、公開、標準化を含む
- データウェアハウジング、BI、データベース管理:データマイニングとETLプロセスのツール
これらの要素は、臨床データの複雑さを効果的に管理するために重要です。
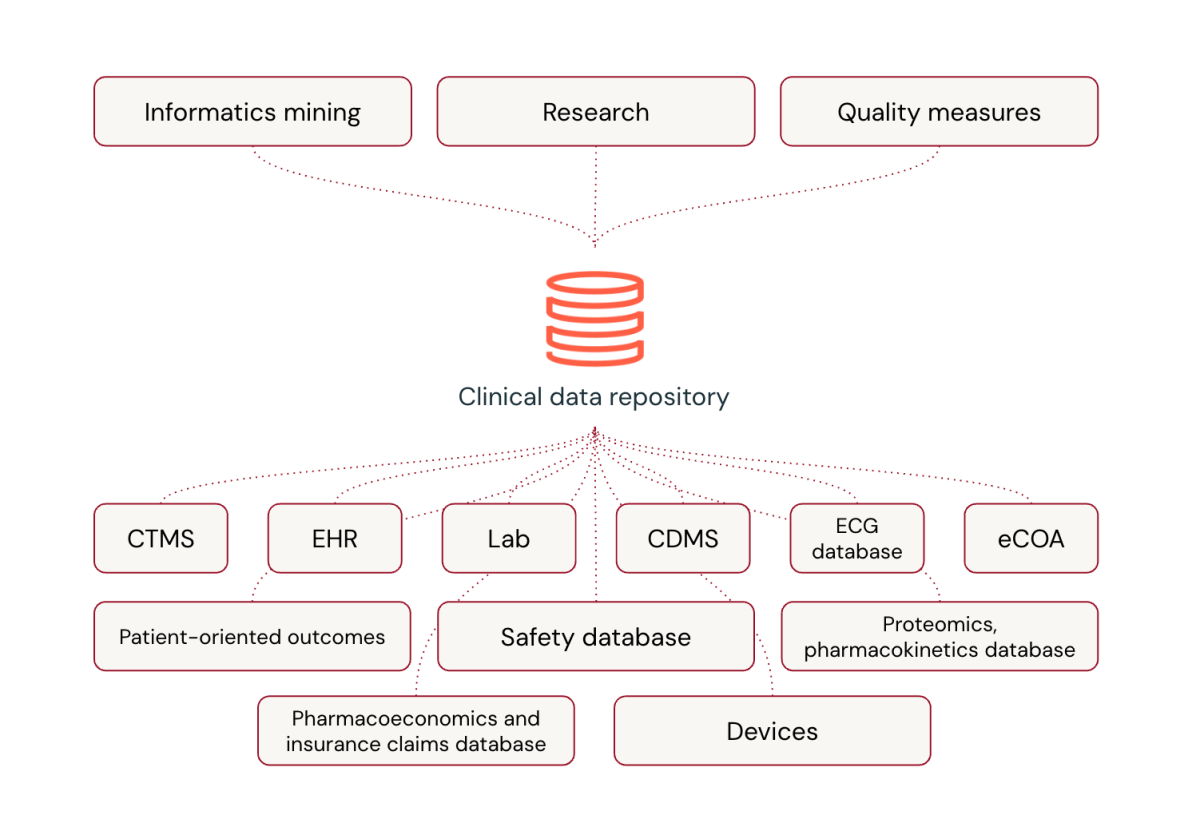
![A sample list of potential data sources feeds data into a Clinical Data Repository to enable Informatics mining, research, and quality measures among other capabilities [2]](https://www.databricks.com/jp/sites/default/files/inline-images/modern-clinical-trial-blog-1.png){kind=link}
ユニバーサルプラットフォームは、製薬業界の臨床データ処理を変革しています。専門的なソフトウェアが一般的でしたが、ユニバーサルプラットフォームは、新しいデータタイプの組み込み、ほぼリアルタイムの処理能力、AIや機械学習のような最先端技術の統合、大量のデータを扱うことで洗練された堅牢なデータ処理手法など、大きな利点を提供します。
カスタマイズや既存のベンダーからの移行に関する懸念があるにもかかわらず、ユニバーサルプラットフォームは臨床試験データ管理において特化したソリューションを上回るパフォーマンスを発揮することができます。例えば、Databricksは、多様なデータタイプを統合し、患者の健康状態の包括的なビューを提供することで、ライフサイエンス企業が臨床試験データを扱う方法を革新しています。
本質的に、Databricksのようなユニバーサルプラットフォームは、特化したプラットフォームの能力を単にマッチングするだけでなく、それらを超越し、臨床試験データ管理における新たな効率性と革新の時代を切り開いています。
CDRの基盤としてDatabricksデータインテリジェンスプラットフォームを活用する
Databricksデータインテリジェンスプラットフォームは、レイクハウスアーキテクチャの上に構築されています。レイクハウスアーキテクチャは、データレイクとデータウェアハウスの最良の機能を組み合わせた現代のデータアーキテクチャです。これは、現代のCDRのニーズによく対応しています。
ほとんどの臨床試験データは構造化された表形式のデータを表していますが、画像やウェアラブルデバイスのような新しいデータ形式が人気を博しています。これらは、臨床試験プロセスを再定義する新しい方法です。Databricksはクラウドインフラストラクチャ上にホスト��されており、クリニカルデータを大規模に保存するためのクラウドオブジェクトストレージを使用する柔軟性を提供します。これにより、すべてのデータタイプを保存し、コストを制御することが可能になります(古いデータはコストを節約しつつ、データを保持する規制要件を満たすために、より冷たい層に移動することができます)、そしてデータの可用性と複製性を確保します。さらに、DatabricksをCDRの基盤技術として使用することで、新機能を制御されたリリースで追加できるアジャイル開発モデルに移行することが可能になります。これは、ビッグバンソフトウェアバージョンの更新とは対照的です。
Databricks Data Intelligence Platformは、データ処理、オーケストレーション、AI機能を一つの場所に集約した全規模のデータプラットフォームです。これには、ネイティブコネクタを含む多くのデフォルトのデータ取り込み機能があり、カスタムのものを実装することも可能です。これにより、CDRをデータソースやダウンストリームアプリケーションと簡単に統合することができます。この能力は、柔軟性とエンドツーエンドのデータ品質と監視を提供します。ストリーミングのネイティブサポートにより、CDRにIoMTデータを追加して、データが利用可能になるとすぐにほぼリアルタイムの洞察を得ることができます。プラットフォームの観測性は、厳格な規制要件だけでなく、データの二次利用と洞察の生成を可能にするため、CDRにとって大きなトピックです。これは最終的に臨床試験のプロセス全体を改善することができます。Databricksで臨床データを処理することで、プロセスに洞察を得るための柔軟なソリューションを実装することが可能になります。例えば、MRI画像の処理はCTテスト結果の処理よりもリソースを多く消費するでしょうか?
臨床データリポジトリの実装:Databricksを用いたレイヤードアプローチ
臨床データリポジトリは、臨床データの保存と処理を統合する高度なプラットフォームです。レイクハウスメダリオンアーキテクチャは、データ処理のレイヤードアプローチとして、特にCDRに適しています。このアーキテクチャは通常、3つのレイヤーで構成され、それぞれがデータ品質を徐々に洗練しています:
- ブロンズレイヤー:さまざまなソースとプロトコルから取り込まれた生データ
- シルバーレイヤー:標準フォーマット(例えば、SDTM)に準拠し、検証されたデータ
- ゴールドレイヤー:レビューや統計分析の準備が整った集約され、フィルタリングされたデータ
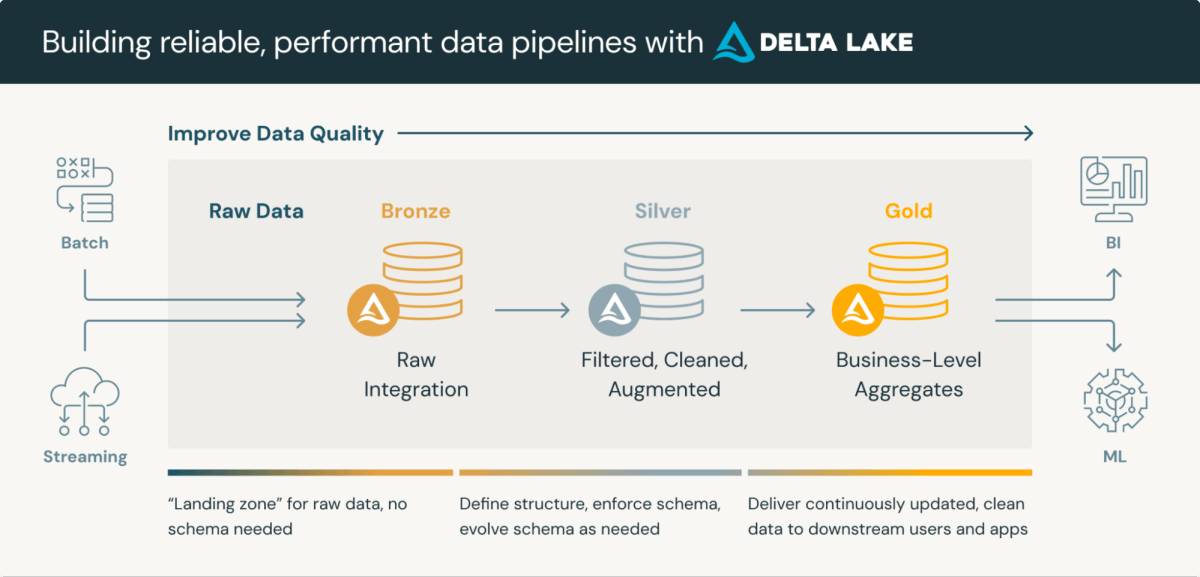
Databricksでのデータストレージにデルタレイク形式を利用することは、スキーマ検証やタイムトラベル機能などの固有の利点を提供します。これらの機能は、規制要件を完全に満たすためには強化が必要ですが、コンプライア��ンスと効率的な処理のための堅固な基盤を提供します。
Databricks Data Intelligence Platformは、堅牢なガバナンスツールを備えています。Unity Catalogという重要なコンポーネントは、プラットフォーム内で包括的なデータガバナンス、監査、アクセス制御を提供します。CDRの文脈では、Unity Catalogが以下を可能にします:
- テーブルと列の系譜の追跡
- データ履歴と変更ログの保存
- 細かいアクセス制御と監査トレイル
- 外部システムからの系統の統合
- 不正なデータアクセスを防ぐための厳格な権限フレームワークの実装
データ処理を超えて、CDRはデータ検証プロセスの記録を維持するために重要です。検証チェックはコードリポジトリでバージョン管理されるべきで、複数のバージョンが共存し、異なる研究にリンクできるようにするべきです。DatabricksはGitリポジトリと確立されたCI/CDの実践をサポートし、堅牢な検証チェックライブラリの実装を可能にします。
DatabricksでのCDRの実装方法は、データの整合性とコンプライアンスを確保し、現代の臨床データ管理に必要な柔軟性とスケーラビリティを提供します。

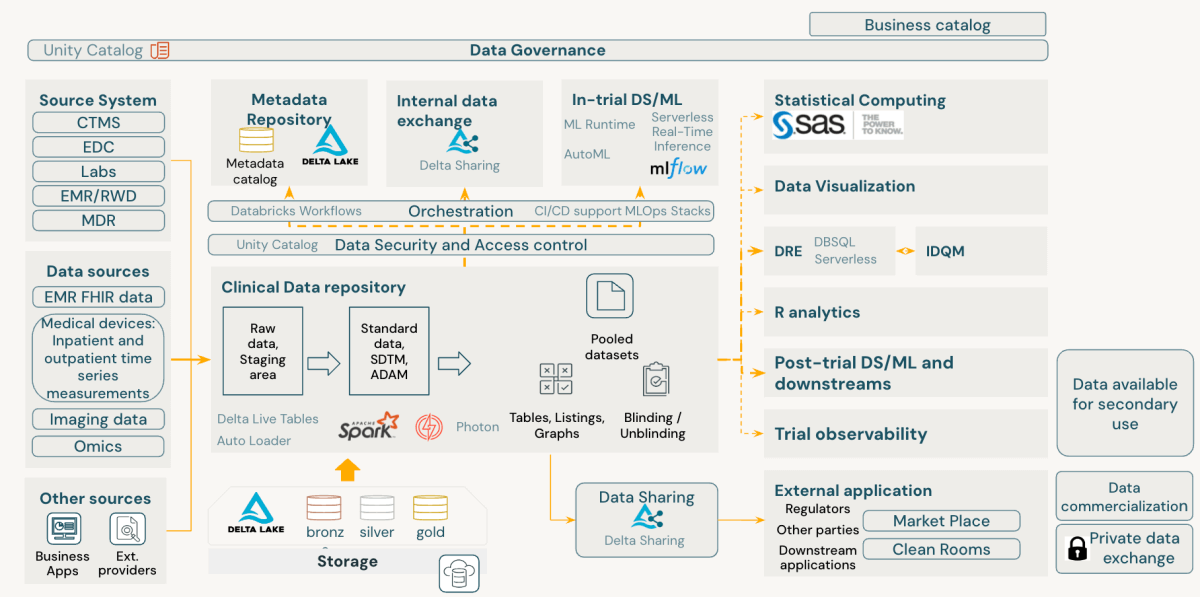{kind=link}
Databricks Data Intelligence Platformは、科学データ管理のFAIR原則と本質的に一致し、臨床開発データ管理に先進的なアプローチを提供します。これは、堅牢なセキュリティとコンプライアンスを中心に保ちつつ、データの検索性、アクセシビリティ、相互運用性、再利用性を向上させます。
現代のCDRの実装における課題
新しいアプローチには必ず課題が伴います。臨床データ管理は大いにSASに依存していますが、現代のデータプラットフォームは主にPython、R、SQLを利用しています。これは技術的な切断だけでなく、より実用的な統合の課題も明らかに導入します。Rは二つの世界をつなぐ橋であり、DatabricksはPositとパートナーシップを結び、Rユーザーに一流のR体験を提供します。同時に、DatabricksをSASと統合することで、移行と遷移をサポートすることが可能です。Databricks Assistantは、特定の言語にあまり詳しくないユーザーが高品質のコードを書き、既存のコードサンプルを理解するための必要なサポートを得ることを可能にします。
ユニバーサルプラットフォームの上に構築されたデータ処理プラットフォームは、ドメイン固有の機能を実装する際に常に遅れています��。実装パートナーとの強力な協力は、このリスクを軽減するのに役立ちます。さらに、消費ベースの価格モデルを採用するには、プラットフォームの監視と観測性、適切なユーザートレーニング、ベストプラクティスへの遵守を確保するために、コストに特別な注意が必要です。
最大の課題は、これらのタイプの実装の全体的な成功率です。製薬会社は、常に臨床試験データプラットフォームの近代化を模索しています。これは、臨床試験の期間を短縮したり、成功しそうにない試験を早く中止するための魅力的な分野です。現在、平均的な製薬会社が収集しているデータの量には、議論を待つだけの大量の洞察が含まれています。同時に、このようなプロジェクトの大半は失敗します。100%の成功率を保証する銀の弾丸のレシピはありませんが、Databricksのようなユニバーサルプラットフォームを採用することで、既存のプラットフォームの上にCDRを薄いレイヤーとして実装し、一般的なデータとインフラストラクチャの問題を解消することが可能です。
次のステップ
すべてのCDR実装は要件のインベントリから始まります。産業がデータモデルとデータ処理の両方に厳格な基準を遵守しているにもかかわらず、各組織でのCDRの境界を理解することは、プロジェクトの成功を確保するために不可欠です。Databricks Data Intelligence PlatformはCDRに多くの追加機能を開放することができるため、その動作方法と提供内容を理解することが必要です。Databricks Data Intelligence Platformの探索から始めてみてください。統一されたガバナンスとUnity Catalog、��データ取り込みパイプラインとLakeflow、データインテリジェンススイートとAI/BI、AI機能とDatabricksは、成功した未来志向のCDRを実装するためには知らないといけない用語です。さらに、Positとの統合や高度なデータ観測機能は、CDRを全体の臨床データ処理パイプラインの一部ではなく、臨床データエコシステムの中核として見る可能性を開くべきです。
ますます多くの企業が、Lakehouseのような現代的なアーキテクチャを利用して、臨床データプラットフォームを近代化しています。しかし、大きな変化はまだこれからです。生成的AIやその他のAI技術の拡大はすでに他の産業を革新していますが、製薬業界は規制制限、高リスク、誤った結果に対する価格のために遅れています。Databricksのようなプラットフォームは、臨床試験に対するクロスインダストリーのイノベーションとデータ駆動型の開発を可能にし、一般的な臨床試験についての新しい考え方を生み出します。
今日からDatabricksを始めましょう。
引用:
[1] 2024年の臨床試験統計:フェーズ、定義、介入による
[2] Lu, Z., & Su, J. (2010).臨床データ管理:現状、課題、産業視点からの未来の方向性。Open Access Journal of Clinical Trials, 2, 93–105。https://doi.org/10.2147/OAJCT.S8172
詳細を学ぶ Databricks Data Intelligence Platform for Healthcare and Life Sciencesについて。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。