
AI 研究2026年3月5日<1分で読めます
KARL のご紹介:カスタム RL を活用した、より高速なエンタープライズナレッジエージェント
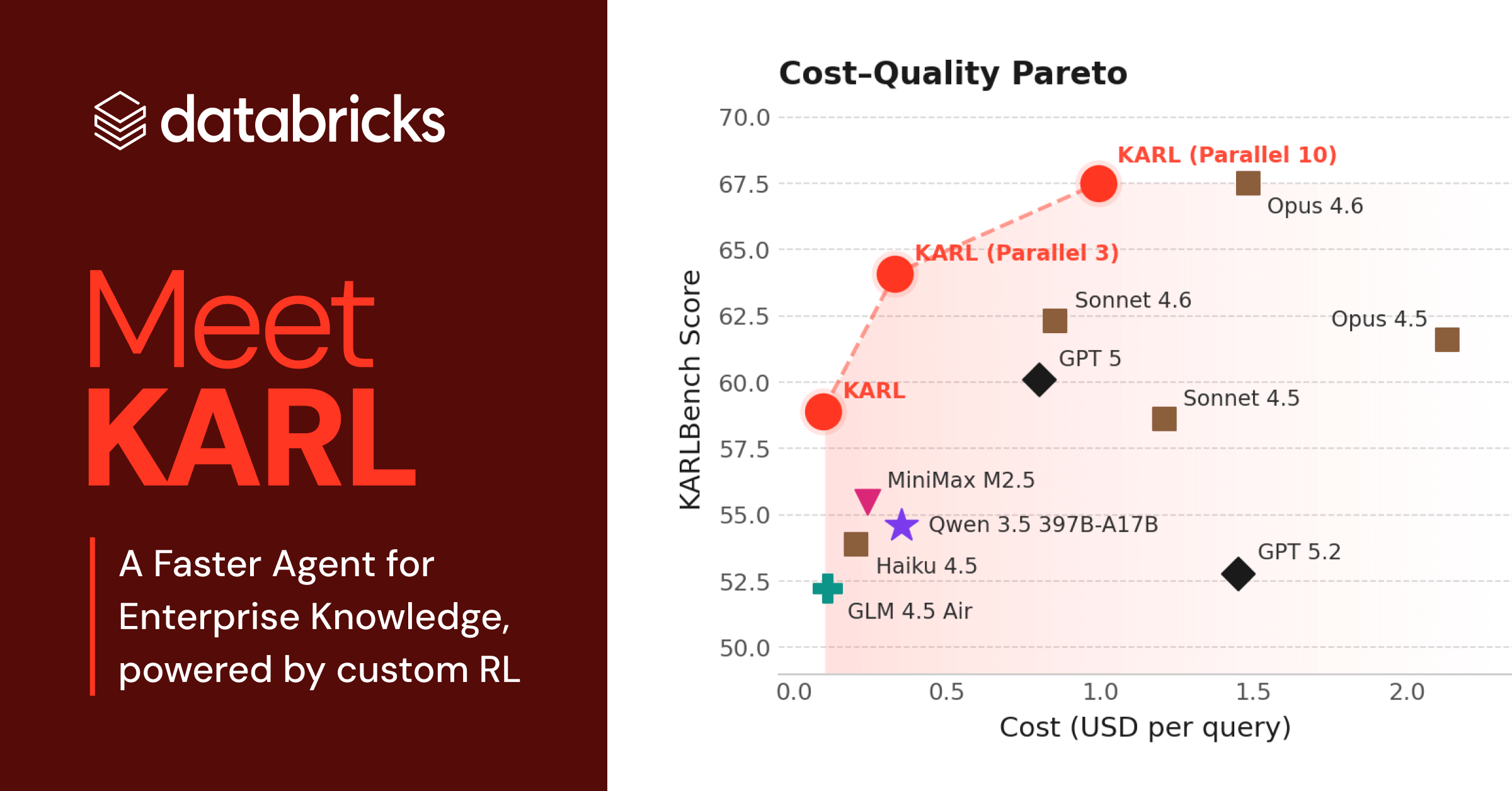
エンタープライズエージェント向けの強化学習 技術レポートの全文は、 こちらをクリック してください。貴社のエンタープライズエージェントでDatabricksカスタムRLをお試しになりたい場合は、 こちらをクリック してください。 現在のモデルの推論能力の向上は、コードの記述、エンタープライズデータに関する質問、一般的なワークフローの自動化といったナレッジワークのためにデプロイされるエージェントの爆発的な増加につながっています。エンタープライズタスクで使用されるモデルは非常に強力ですが、同時に非常に高価でもあり、多くのユースケースで推論コストが持続不可能なほど増大し始めています。この記事と 対応する技術レポート では、当社のAgent Bricks製品の重要な部分であるユースケースを強化するために、強化学習(RL)を使用してカスタムモデルを構築した経験について説明します。この例は、比較的低コストで、推論コスト、レイテンシ、品質という3つの重要な側面すべてにおいて、フロンティアモデルを完全に凌駕するカスタムモデルを構築することが可能であることを示しています。私たちの調査結果は、Cursorの Composerモデル のような他の業界の観察結果と一致しており、そこではRLベースのカスタマイズによって代替案と比較して速度と品質の両方を劇的に向上させることができました。 KARL:Databricks ユーザー向けのより高速、高性能、低コストなナレッジエージェント 私たちがトレーニングしたKARLというモデルは、 グラウンデッドリーズニング という重要なエンタープライズ機能に対応します。これは、ドキュメントの検索、事実の発見、情報の相互参照、そして数十から数百のステップにわたる推論によって質問に答えることです。グラウンデッドリーズニングは、Agent Bricks Knowledge Assistantなど、いくつかのDatabricks製品で必要とされます。数学やコーディングとは異なり、グラウンデッドリーズニングのタスクは 検証が困難 です。つまり、単一の正解がないことがよくあります。このような状況では、強化学習を良い解決策に導くことは特に困難になります。 Databricksで開発された...