Delta Live Tablesパイプラインのためのコスト効率的で増分的なETLとサーバーレスコンピューティング
サーバーレス計算による最適化されたETL、AWSとAzureで現在GA
によって ポール・ラッパス, Michael Armbrust, Manish Dalwadi, アンドレアス・ノイマン, Xi Liang, Kiavash Kianfar 、 カール・ワン による投稿
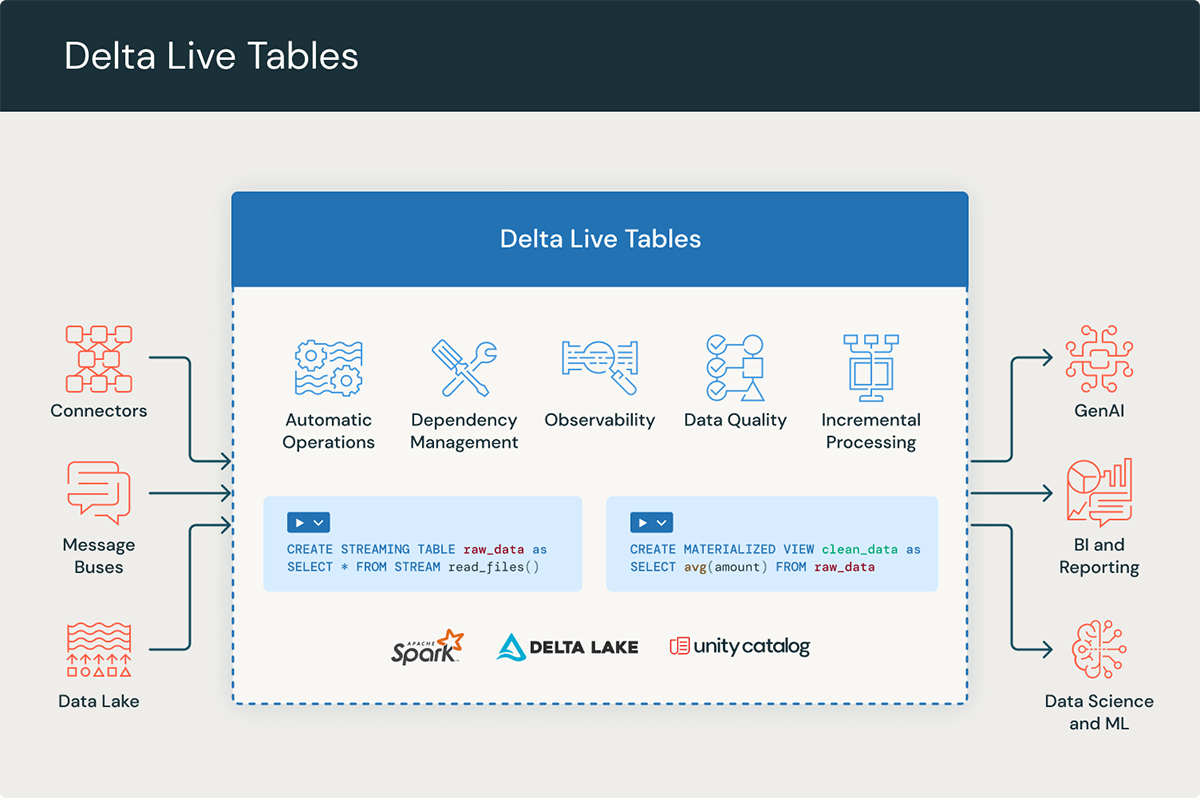
私たちは最近、ノートブック、ワークフロー、Delta Live Tables(DLT)パイプラインのサーバーレスコンピューティングの一般提供開始を発表しました。今日、DLTパイプラインで構築されたETLパイプラインが、サーバーレスコンピュートからどのように利益を得られるかを説明したいと思います。
DLTパイプラインは、シンプルで宣言的なフレームワークを使用して、コスト効率の良いストリーミングとバッチETLワークフローを簡単に構築できます。データの変換を定義し、DLTパイプラインはタスクのオーケストレーション、スケーリング、監視、データ品質、エラーハンドリングを自動的に管理します。
DLTパイプラインのサーバーレスコンピュートは、データ取り込みについては最大5倍のコストパフォーマンスを提供し、複雑な変換については最大98%のコスト節約を提供します。また、DLTクラシックコンピュートに比べて信頼性も向上します。この組み合わせにより、Databricks上で高速かつ信頼性の高いETLを大規模に実現します。こ��のブログ投稿では、DLTのサーバーレスコンピューティングがどのように卓越したシンプルさ、パフォーマンス、そして最低の総所有コスト(TCO)を達成するかについて詳しく説明します。
サーバーレスコンピューティングのDLTパイプラインは、より速く、より安価で、より信頼性が高い
サーバーレスコンピューティング上のDLTはスループットを強化し、信頼性を向上させ、総所有コスト(TCO)を削減します。この改善は、データの取り込みから変換までの全体のデータジャーニーを通じてエンドツーエンドのインクリメンタル処理を行う能力によるものです。さらに、サーバーレスDLTは、コンピューティングリソースを垂直に自動的にスケーリングすることで、より広範なワークロードをサポートし、メモリ集中型タスクの処理を改善します。
シンプルさ
DLTパイプラインは、運用の複雑さのほとんどを自動化することでETL開発を簡素化します。これにより、パイプラインの管理と維持ではなく、高品質なデータの提供に集中することができます。
シンプルな開発
- 宣言的プログラミング:取り込み、変換、データ品質期待値の適用のためのバッチおよびストリーミングパイプラインを簡単に構築します。
- シンプルなAPI:SCDタイプ1およびタイプ2のフォーマットからの変更データキャプチャ(CDC)をストリーミングソースとバッチソースの両方から処理します。
- データ品質:期待値でデータ品質を強制し、データ品質のための強力な観測可能性を活用します。
シンプルな操作
- 水平自動スケーリング:自動オーケストレーションとリトライにより、パイプラインを自動的に水平にスケーリングします。
- 自動アップグレード: Databricks Runtime(DBR)のアップグレードは自動的に行われ、最新の機能とセキュリティパッチを手間なく、最小のダウンタイムで受け取ることができます。
- サーバーレスインフラストラクチャ:インスタンスタイプを選択したり、コンピューティング設定を管理したりすることなく、リソースを垂直に自動スケーリングし、非専門家でも大規模なパイプラインを操作できます。
性能
サーバーレスコンピューティング上のDLTは、データ取り込みから変換まで、パイプライン全体でエンドツーエンドの増分処理を提供します。これは、サーバーレスコンピューティングで実行されるパイプラインは、データ取り込みと複雑な変換の両方でデータが増分的に処理されるため、実行速度が速く、全体的なレイテンシが低くなることを意味します。主な利点には以下のようなものがあります:
- 高速スタートアップ:サーバーレスフリートが必要に応じて常に計算を利用可能にするため、コールドスタートがなくなります。
- スループットの向上:タスクの並列化のためのストリームパイプラインによる取り込みスループットの強化。
- 効率的な変換: Enzymeのコストベースの最適化機能は、マテリアライズドビューのための迅速かつ効率的な変換を提供します。
低 TCO
DLTでのサーバーレス計算では、データは増分的に処理され、大規模で複雑なマテリアライズドビュー(MV)を持つワークロードが全体のデータ処理時間の短縮から利益を得ることができます。サーバーレスモデルはエラスティック課金を使用し、データ処理に実際に費やした時間のみが請求されます。これにより、未使用のインスタンス容量の支払いやインスタンス利用率の追跡の必要性がなくなります。サーバーレス計算上のDLTを使用すると、以下のような利点があります:
- 効率的なデータ処理: ストリーミングテーブルによる増分取り込みとマテリアライズドビューによる増分変換。
- 効率的な課金: コンピューティングがワークロードに割り当てられたときだけ課金され、リソースの取得と設定に必要な時間は課金されません。
「サーバーレスDLTパイプラインは実行時間を半分にし、コストを妥協せず、エンジニアリング効率を向上させ、複雑なデータ操作を合理化し、チームがインフラストラクチャではなくイノベーションに集中できるようにします。これは、生産環境と開発環境の両方で有効です」 —Cory Perkins、シニアデータ&AIエンジニア、Qorvo
「開発者の生産性を向上させるため、そして組み込みのデータ品質フレームワークと操作の容易さのために、DLTを選択しました。サーバーレスのオプションの利用可能性は、エンジニアリングのメンテナンスとコスト最適化の負担を軽減します。この移行は、Databricks内のすべてのパイプラインをサーバーレス環境に移行するという我々の包括的な戦略とシームレスに一致します」 —バラ・ムーアシー、シニアデータエンジニアリングマネージャー、コンパス
これらの機能の一部を詳しく見てみましょう:
エンドツーエンドの増分処理
DLTにおけるデータ処理は、取り込みと変換の2つの段階で行われます。DLTでは、データの取り込みはストリーミングテーブルによってサポートされ、データ変換はマテリアライズドビューによって処理されます。インクリメンタルなデータ処理は、最低コストで最高のパフォーマンスを達成するために重要です。これは、インクリメンタル処理により、リソースが読み取りと書き込みの両方に最適化されるためです:最後の更新以降に変更されたデータのみが読み取られ、パイプライン内の既存のデータは、必要な結果を得るために必要な場合にのみ触れられます。このアプローチは、典型的なバッチ処理アーキテクチャと比較してコストと遅延を大幅に改善します。
ストリーミングテーブルは、クラウドファイルやメッセージバスからの取り込みに対して常に増分処理をサポートしており、Spark Structured Streaming技術を活用してイベントを効率的に、正確に一度だけ配信します。
今では、サーバーレスコンピュートを備えたDLTは、複雑なMV変換のインクリメンタルリフレッシュを可能にし、取り込みと変換の両方でETLパイプライン全体のエンドツーエンドのインクリメンタル処理を可能にします。
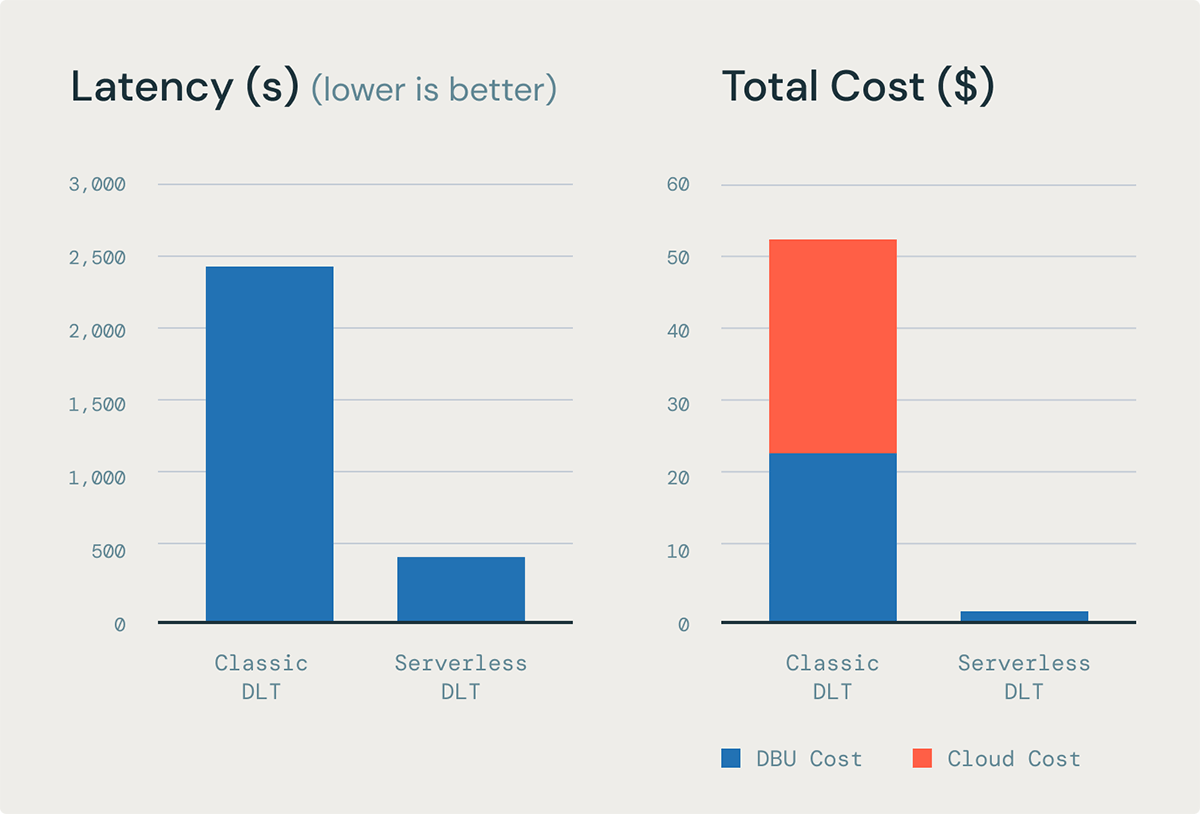
マテリアライズドビューの増分リフレッシュにより、低コストでより良いデータの新鮮さを実現
大規模なMVの完全な再計算は高コストと高レイテンシーを招く可能性があります。以前は、複雑な変換のためのインクリメンタル処理を行うために、ユーザーは1つの選択肢しかありませんでした:PySparkで複雑なMERGEとforEachBatch()ステートメントを書いて、ゴールドレイヤーでのインクリメンタル処理を実装します。
サーバーレスコンピュート上のDLTは、コストベースの最適化器("Enzyme")を含むため、ユーザーが複雑なロジックを書くことなく、マテリアライズドビューを自動的にインクリメンタルにリフレッシュします。Enzymeは、ETLを行うプロセスを高速化し、コストを大幅に削減します。これにより、はるかに低いコストでより良いデータの新鮮さを得ることができます。
2000億行のテーブルに対する内部ベンチマークに基づくと、Enzymeは、DLTクラシックコンピュート上の同等のMVリフレッシュに比べて、最大6.5倍のスループットと85%低いレイテンシを提供できます。
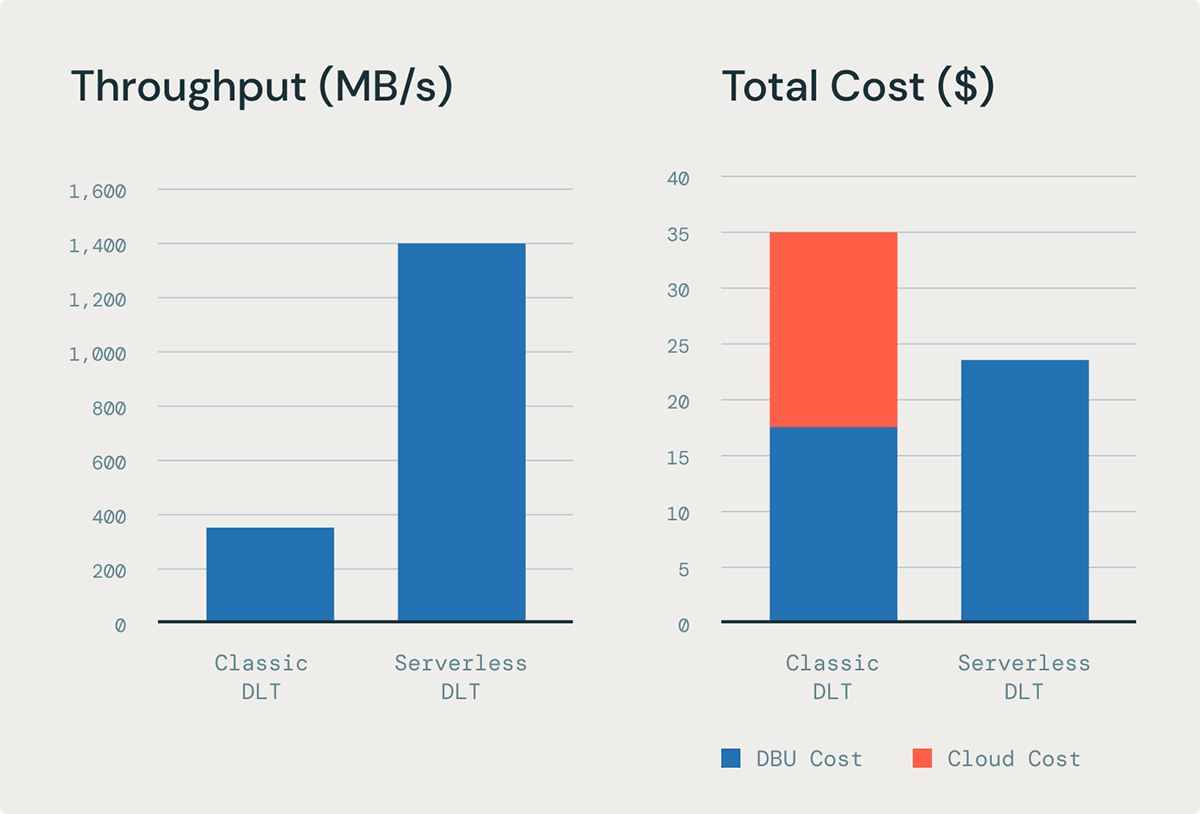
ストリームパイプラインによるより速く、より安価なデータ取り込み
ストリーミングパイプラインは、ストリーミングテーブルを使用してDLTでファイルやイベントをロードするスループットを向上させます。以前は、クラシックコンピューティングでは、一部のタスクが早く終了し、スロットがアイドル状態になるため、インスタンスリソースを完全に利用することが困難でした。サーバーレスコンピューティングでのDLTを用いたストリームパイプラインは、これを解決します。SparkTM Structured Streaming(ストリーミングテーブルを支える技術)を並行して処理することを可能にします。これらすべてが、コストを増やすことなくストリーミング取り込みの遅延を大幅に改善します。
DLTを使用して100KのJSONファイルをロードする内部ベンチマークに基づくと、ストリームパイプラインは、DLTクラシックパイプライン上の同等の取り込みワークロードに比べて、価格性能が5倍良好であることが示されています。
自動的な垂直スケーリングでメモリ集約型のETLワークロードを有効にします
変動し予測不能なデータ量に対して最適なパフォーマンスを発揮するための適切なインスタンスタイプを選択することは、特に大規模で複雑な変換やストリーミング集約の場合、困難であり、しばしばオーバープロビジョニングにつながります。変換が利用可能なメモリよりも多くのメモリを必要とする場合、メモリ不足(OOM)エラーやパイプラインのクラッシュを引き起こすことがあります。これには手動でインスタンスサイズを増やす必要があり、これは面倒で時間がかかり、パイプラインのダウンタイムを引き起こします。
サーバーレスコンピュート上のDLTは、コンピューティングとメモリリソースの自動垂直オートスケーリングにより、これに対応します。システムは自動的に、ワークロードのメモリ要件を満たすための適切な計算設定を選択します。さらに、DLTは、ワークロードが時間とともに少ないメモリを必要とすると判断した場合、インスタンスのサイズを縮小してスケールダウンします。

サーバーレスコンピューティング上のDLTはすでに利用可能です
サーバーレスコンピューティング上のDLTは現在利用可能で、私たちは常にそれを改善するために努力しています。これからの強化点については以下の通りです:
- マルチクラウド対応: 現在、AzureとAWSで利用可能で、GCPのサポートは公開プレビュー中で、今年後半にGAの発表が予定されています。
- コストとパフォーマンスのための継続的な最適化: 現在は高速な起動、スケーリング、パフォーマンスに最適化されていますが、ユーザーは近いうちに低コストなどの目標を優先することができるようになります。
- プライベートネットワーキングとエグレスコントロール:プライベートネットワーク内のリソースに接続し、パブリックインターネットへのアクセスを制御します。
- 強制的な帰属: ノートブック、ワークフロー、DLTパイプラインにタグを付けて、特定のコストセンターにコストを割り当てます。たとえば、チャージバックのためなど。
今日からサーバーレスコンピューティングでDLTを始めましょう
今日からサーバーレスコンピューティングでDLTを使用するには:
- あなたのアカウントでAWSまたはAzureのサーバーレスコンピューティングを有効にします
- あなたのワークスペースがUnity Catalogを使用できるように設定されていて、対応リージョンにあることを確認してください
- Delta Live Tablesを始めるための具体的な指示に従ってください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。