サイバーセキュリティ・レイクハウス Part 4: データ正規化戦略
現場での教訓:サイバーセキュリティ・データを共通の情報モデルに正規化するための戦略
によって デレク・キング による投稿
この4部構成のブログ・シリーズ"Lessons learned from building Cybersecurity Lakehouses,"では、サイバーセキュリティ・データ用のレイクハウスを構築する際に、�組織がデータ・エンジニアリングで直面する多くの課題について議論し、それを克服するために私たちが現場で使用したソリューション、ヒント、コツ、ベスト・プラクティスを紹介する。
パート1では、まず統一されたイベントのタイムスタンプ抽出から始めた。 パート2では、ログの取り込みの遅れを発見し、対処する方法について見てきた。 そしてパート3では、半構造化された機械生成データの解析方法に取り組んだ。 このシリーズの最終回では、サイバーアナリティクスの最も重要な側面の1つである、共通の情報モデルを使用したデータの正規化について説明します。
このブログが終わるころには、サイバーセキュリティ・レイクハウスにデータを正規化する際に直面するいくつかの問題と、それを克服するために使用できるテクニックについて、しっかりと理解していることだろう。
共通情報モデル(CIM)とは何か?
サイバーセキュリティ分析エンジンには、組織内の異種システム、アプリケーション、デバイス間で、セキュリティ関連データとイベントの効果的な通信、相互運用性、理解を促進するための共通情報モデル(CIM)が必要である。
組織には、ログやイベントをさまざまな構造や形式で生成するさまざまなシステムやアプリケーションがあ��る。 CIMは、共通のデータ構造、属性、関係を定義する標準化されたモデルを提供する。 この標準化により、アナリティクス・エンジンは、異なるソースから収集されたデータを正規化し、調和させることができ、情報の効果的な処理、分析、相関が容易になる。
なぜ共通情報モデルを使うのか?
組織は、様々なベンダーの様々なセキュリティ・ツール、アプリケーション、デバイスを使用しており、それぞれのテクノロジーに固有のログを生成している。 一貫性のある分かりやすい命名規則で、データを既知の構造セットに正規化することは、データ相関、脅威検出、インシデント対応機能を実現する上で極めて重要である。
例として、ユーザ "Joe "が過去30日以内にどのシステムやアプリケーションで認証に成功したかを知りたいとする。
この質問に、単一のモデルなしで答えるには、アナリストは何十、何百ものログを検索するクエリを作成する必要がある。 各ログファイルは、ユーザー名と認証結果(成功または失敗)を、異なるフィールド名と異なる値で報告する。 アプリのフィールド名も、イベント時間と同様に異なる可能性がある。 これは実行可能な解決策ではない。 共通情報モデルと正規化プロセスに入る!
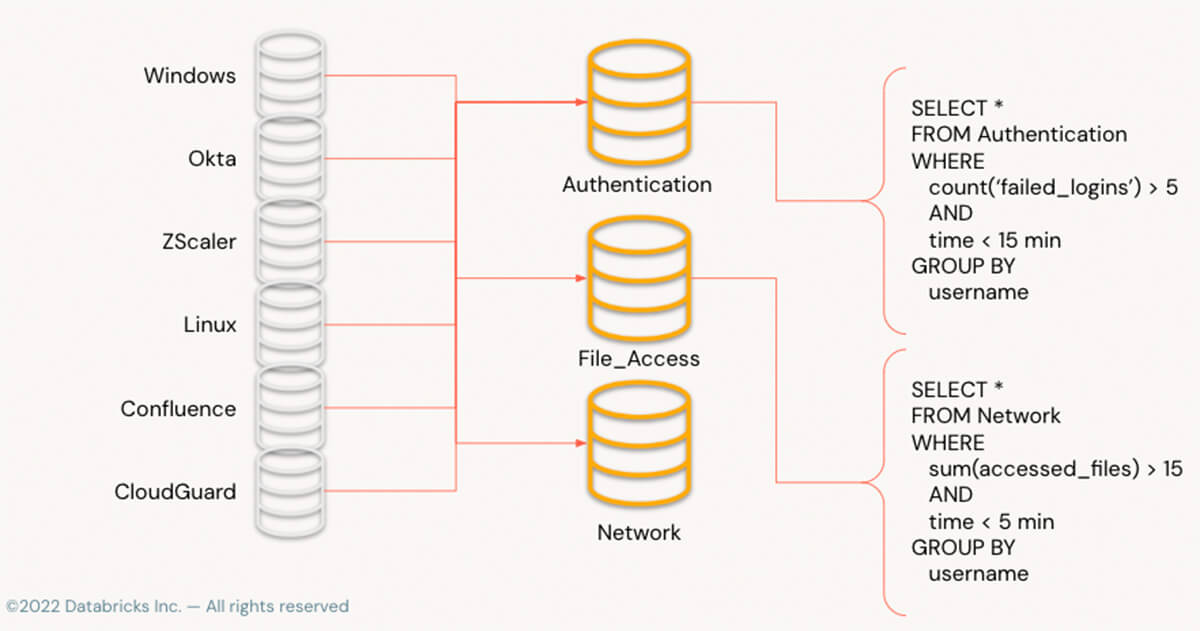
上の画像は、多くのソースからのバラバラのログが、既知のカラム名を使用して、イベントをイベント固有のテーブルにフィルタリングし、データが正規化さ�れた後、単一のシンプルなクエリで質問に答えることを可能にする方法を示している。
データを正規化する際に考慮すべきこと
異種データソースを単一のCIM準拠テーブルに正規化する際に考慮すべき条件がいくつかある:
異なるカラムタイプ:異なるデータソースと特定のイベントをCIM(イベントドリブン)テーブルに統合すると、データ型が衝突する可能性がある。
派生フィールド:正規化プロセスでは、多くの場合、1 つ以上のソース列から新しいフィールドを派生させる必要がある。
フィールドの欠落:フィールドは予期せず存在しなかったり、NULL値を含んでいたりします。 CIMが欠損値やヌル値のデータ型に対応していることを確認する。
リテラル・フィールド:対象となるCIMフィールドをサポートするデータを作成する必要があるか、統一された検索機能を確保するために、フィールドを"成功" または"失敗" のようなリテラル値に設定する必要があるかもしれない。 例えば(ここで action="Success")
スキーマの進化:データもCIMも時間とともに進化する可能性がある。 データの変更に対応するために、特にCIMテーブル内で後方互換性を提供するメカニズムがあることを確認する。
エンリッチメント:CIMデータは多くの場合、脅威データや資産情報などの他のコンテキストで強化されている。 収集されたイベントの包括的なビューを提供するために、これらの情報を追加する方法を検討する。
どのモデルを選ぶべきか?
サイバーセキュリティ・レイクハウスを構築する際には、オープンソースのモデルからベンダー固有の公開モデルまで、多くの一般的な情報モデルから選択することができる。 何を使うかは、主に個々のユースケースによる。
いくつか考慮すべき点がある:
- 他のSIEMやSOAR製品でDelta Lakeを補強していますか? 統合を容易にするために、そちらを採用することに意味はあるのでしょうか?
- 特定のユースケースのためだけにサイバーセキュリティ・レイクハウスを構築するのか? 例えば、マイクロソフトのエンドポイントデータだけを分析したいのか? もしそうなら、マイクロソフトのASIMモデルに合わせることに意味があるのだろうか?
- 組織の主要なサイバー分析プラットフォームとしてレイクハウスを構築していますか? OCSFや OSSEMのようなオープンソースモデルと連携することに意味があるのか、それとも独自に構築することに意味があるのか。
最終的には、ニーズに応じて組織ごとに選択することになる。 もうひとつ考慮すべきは、選んだモデルの完成度だ。 モデルは一般的なものであり、ニーズに合わせて多少の適合が必要になる可能性が高い。しかし、事後的なモデル変更には時間がかかるため、モデルの採用を開始する前に、主にデータと要件をサポートする必要がある。
ヒントとベストプラ��クティス
どのモデルを選択するにせよ、全体的なセキュリティ態勢にギャップが存在しないようにするためのヒントがいくつかある。
- ほとんどのクエリーはエンティティに大きく依存している。 送信元ホスト、送信先ホスト、送信元ユーザー、および使用アプリケーションは、おそらくどのテーブルでも最も検索される列だ。 これらのマップが適切に作成され、正規化されていることを確認する。
- モデルは通常、フィールドカバレッジに関するガイダンス(必須、推奨、オプション)を提供する。 一貫性のある検索環境のために、必須フィールドがマッピングされ、データ整合性チェックが適用されていることを最低限確認する。
まとめ
共通情報モデルベースのテーブルは、効果的なサイバー分析プラットフォームの礎石である。 サイバーセキュリティ・レイクハウスを構築する際に採用するモデルは組織ごとに異なるが、どのモデルであっても、開始する前に組織のニーズにほぼ適合している必要がある。
お問い合わせ
Databricksのサイバーソリューションが、サイバー脅威を特定し、軽減するためにどのようにあなたの組織を強化できるかについてもっと知りたい場合は、cybersecurity@databricks.comまでご連絡ください。 レイクハウス・フォー・サイバーセキュリティ・アプリケーションのウェブページをご覧ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。