設計による分離: 10億スケールのベクトル検索
によって Zero Qu, エリック・リンドグレン, Sheng Zhan, Ankit Vij, セルゲイ・ツァレフ 、 Dima Kotlyarov による投稿
序章
ベクトル検索は、製品内検索からレコメンデーションシステム、エンティティ解決、検索拡張生成に至るまで、AIアプリケーションの基盤インフラストラクチャとなっています。しかし、データセットが数百万から数十億のベクトルにまで成長すると、それらを提供するシステムはコストのかかる形で破綻し始めます。メ�モリコストは急増し、データの取り込みがサービス提供を停止させ、スケーリングにはすべてを複製する必要があります。
Databricksでは、当初のベクトル検索機能でこれらの制限に直面しました。そこで、私たちは原点に立ち返り、ゼロから再設計を行いました。現在、Databricks ベクトル検索には2つのデプロイオプションがあります。Standard Endpointは、完全精度のベクトルをすべてメモリ内に保持し、数十ミリ秒のレイテンシーを実現します。一方、Storage Optimized Endpointは、ストレージとコンピュートを分離して、わずかなコストで数十億のベクトルを提供します。クエリーレイテンシーは数百ミリ秒となり、これは低ミリ秒の応答時間よりもコストとスケールが重要なワークロードに対する意図的なトレードオフです。
ストレージ最適化ベクトル検索は、3つの主要なエンジニアリング上の決定によって形成されました。
- ストレージとコンピュートを分離。ベクトルインデックスはクラウドのオブジェクトストレージに配置され、サービング時にのみメモリにロードされます。インジェストはエフェメラルなサーバーレス Spark クラスターで実行され、クエリパスから完全に分離されています。
- Spark 上で分散インデックス作成アルゴリズムを構築。単一マシン用のインデックス作成ライブラリに依存するのではなく、私たちは独自に、クラスターサイズに応じて線形にスケールするネイティブな Spark ジョブとして、分散クラスタリング、ベクトル圧縮、パーティションアラインされたデータlayoutを開発しました。
- デュアルランタイム アーキテクチャを備えた Rust エンジンからクエリーを処理する。専用に構築されたクエリーエンジンは、非同期 I/O と CPU バウンドのベクトル計算に別々のスレッドプールを使用するため、どちらか一方が他方を枯渇させることはありません。
その結果、10億ベクトル規模のインデックスが8時間未満で構築され、インデックス作成は20倍高速化し、サービングコストは最大で7倍削減されました。
この記事では、私たちがそれをどのように構築したかというエンジニアリングのストーリーを紹介します。
従来のベクトルデータベースの問題点
密結合の限界
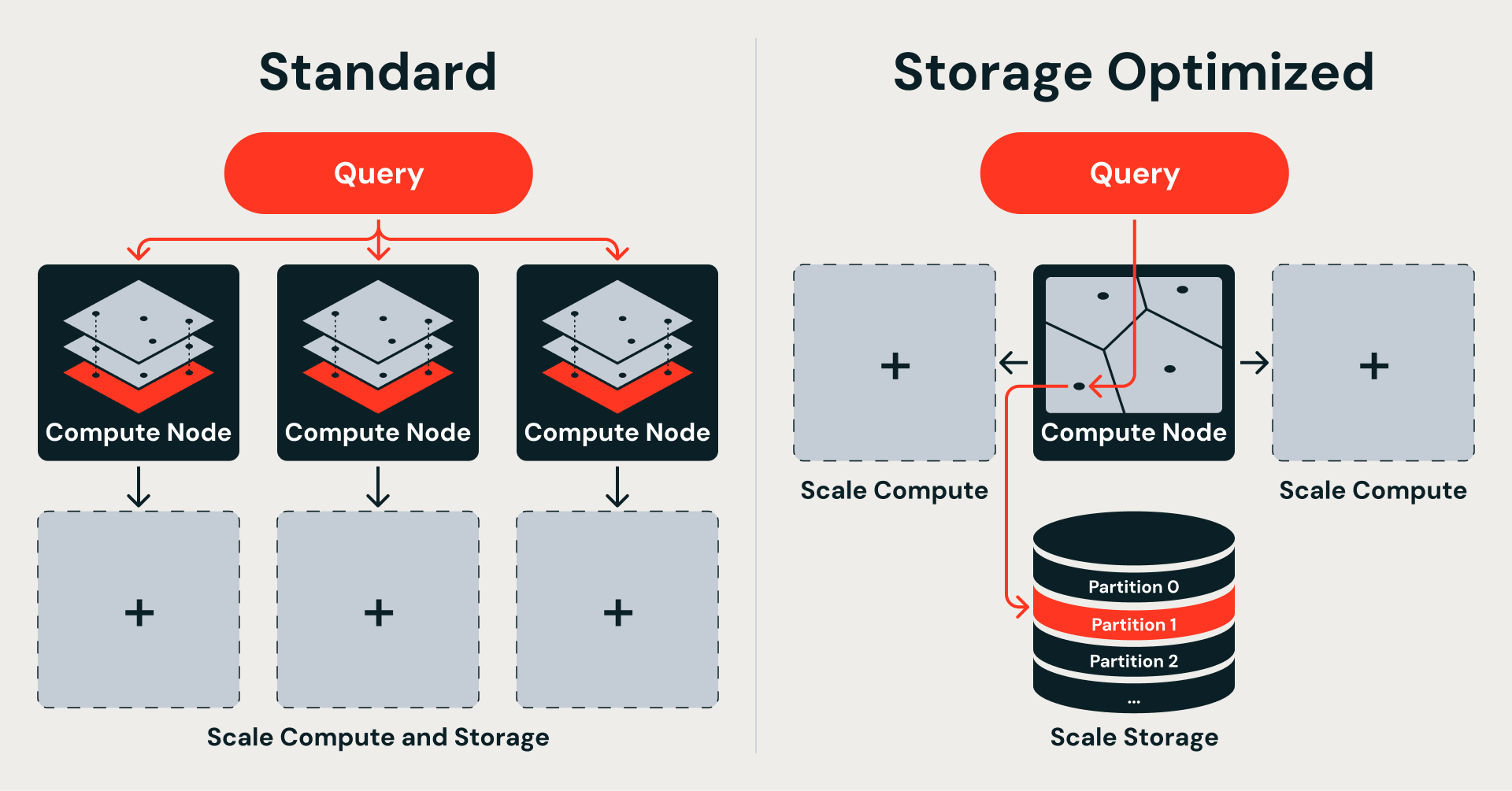
当社の Standard AI Search を含む多くの本番運用ベクトルデータベースは、分散キーワード検索から借用した共有ナッシング アーキテクチャに従っています。各ノードはデータセットのランダムなシャードを所有し、完全精度のベクトル上で独立したインメモリ HNSW(階層的ナビゲート可能スモールワールド)グラフを維持します。HNSW は優れた検索品質を提供しますが、グラフ自体は完全にメモリ内に存在する必要があるため、スケーリングに最もコストのかかるコンポーネントの 1 つとなっています。この設計は低レイテンシーを実現し、トランザクション更新をサポートします。数億ベクトルまで問題なく機能します。
数十億規模になると、破綻してしまいます。
中心的な問題はカップリングです。インデックス、生データ、そしてそれらをサーブするコンピュートがすべて同じノー�ドに束縛されています。スケーリングとはすべてを複製することを意味します。つまり、より多くのベクトルはより多くのメモリを必要とし、それはより多くのノードを必要とします。そして各ノードは、そのシャードのインデックスとデータの完全なコピーを保持します。ストレージをコンピュートから独立してスケールさせる方法はありません。
この結合はインジェストにまで及びます。インデックスの構築は検索エンジン自体の中で行われます。つまり、クエリーを処理するのと同じコンピュートリソースが、データの再編成、インデックスの再構築、コンパクションも処理するのです。書き込み負荷の高いワークロードでは、クエリーのレイテンシが悪化します。クエリー負荷の高いワークロードでは、インジェストが非常に遅くなります。さらに悪いことに、データの変更(upsert、delete、compaction)のたびにサブインデックスの再構築がトリガーされ、クエリーの処理ではなくメンテナンスにCPUサイクルが消費されてしまいます。
メモリ常駐インデックスは高コスト
このインメモリでの常駐が、アーキテクチャを高速にする理由であり、また高価にする理由でもあります。32ビット浮動小数点数を持つ768次元では、1億個のベクトルがインデックスのオーバーヘッドを考慮する前に、ベクトルだけで約286GiBのRAMを消費します。10億個のベクトルにはテラバイト単位のメモリが必要になります。ギガバイトあたりのコストがごくわずかであるディスクストレージやオブジェクトストレージとは異なり、メモリはスタックの中で最も高価なリソースです。ベクトルを追加するたびに、RAMの費用が直接増加します。
ランダムシャーディングは問題をさらに悪化させます。ベクトルはセマンティックな類似性に関係なく分散されるため、各シャードの関連性に関わらず、すべてのクエリーが全シャードに分散(スキャッター)され、結果を収集(ギャザー)する必要があります。CPU、ネットワークオーバーヘッド、テールレイテンシーはすべてシャード数とともに増加します。ベクトルを追加することはシャードを追加することを意味し、新しいシャードはそれぞれ独自のメモリ常駐インデックスを持ちます。
設計による分離
解決策は、このアーキテクチャ内で最適化することではなく、結合そのものを断ち切ることです。
ストレージ最適化ベクトル検索は、「すべてのデータはクラウドオブジェクトストレージに存在し、クエリノードはステートレスである」という単一の前提から始まります。これにより、システムは2つの境界で分割されます。1つはストレージとコンピュートの分離(クエリーノードがデータを所有しない)、もう1つはインジェストとサービングの分離(インデックス構築がライブクエリーと競合しない)です。そして、これにより3層アーキテクチャが生まれます。
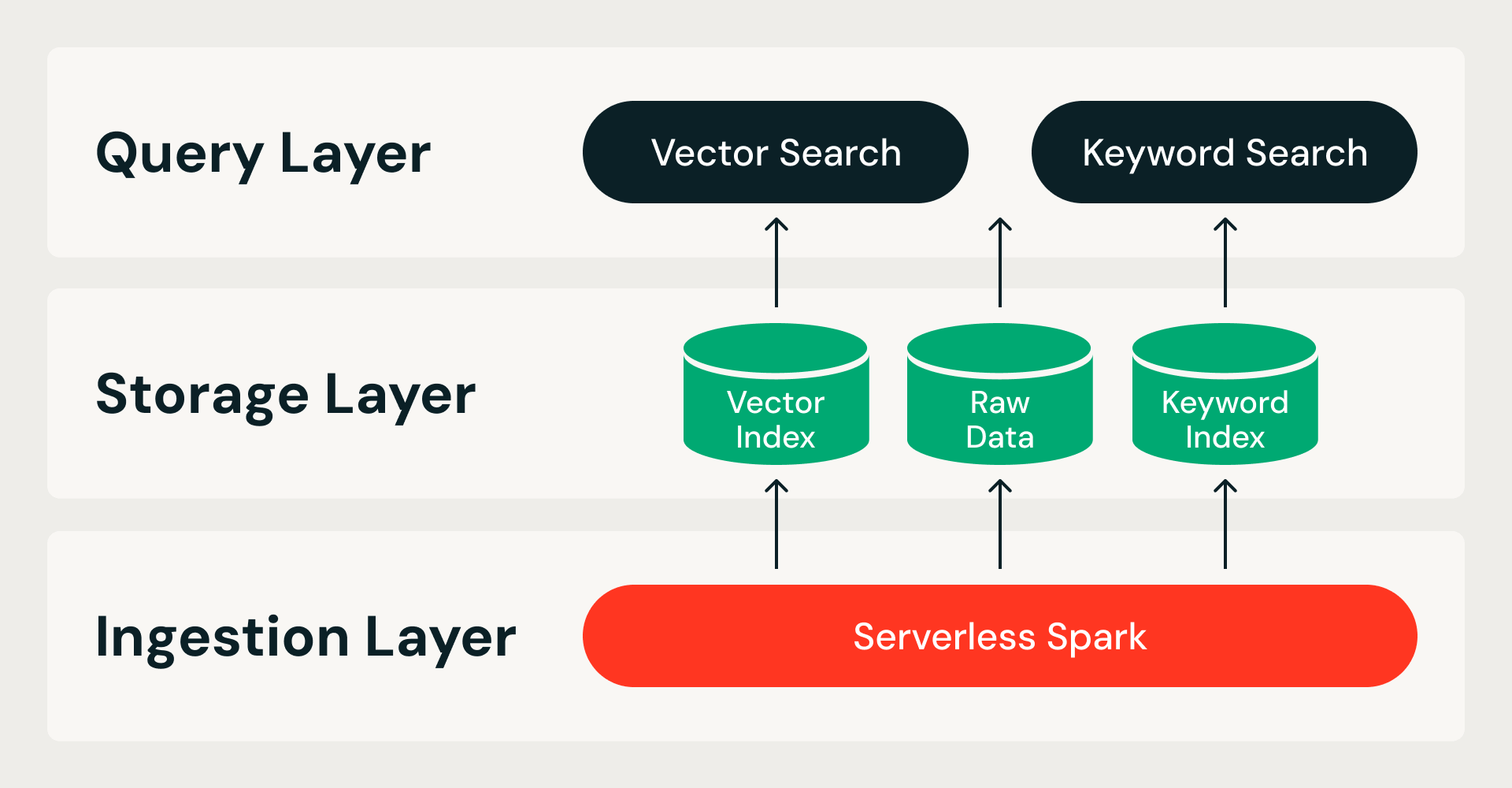
- 取り込みレイヤー。サーバーレスSpark上の分散パイプライ��ンが、生データから完成したインデックスまで、すべてのインデックス構築を処理します。各ランはべき等性があり、再試行可能です。
- ストレージ レイヤー。カスタムのクラウドネイティブなストレージ形式が、システムオブレコードとして機能します。生データとベクトルインデックス用のカラムナファイル形式と、キーワード検索用の転置インデックス形式を組み合わせており、これらすべてが不変のデータフラグメントを持つACIDトランザクションの下で実行されます。
- クエリーレイヤー。2つのステートレスサービスが読み取りを処理します。ベクトル検索サービスは、圧縮されたインデックスをメモリに保持し、必要に応じてオブジェクトストレージから完全精度のデータをフェッチします。キーワード検索は、メタデータフィルタリングとキーワード検索のために転置インデックスを提供します。両方のサービスは独立してスケールするため、ワークロードに合わせてリソースを調整できます。
オブジェクトストレージのためのインデックス構造
データがオブジェクトストレージに存在する場合、インデックスはパーティション分割可能でなければなりません。つまり、クエリーエンジンは構造全体をメモリにロードするのではなく、関連するスライスのみをフェッチする必要があります。
HNSWグラフにはその特性がありません。各検索ホップはグラフ内のどこにでもジャンプできるため、単一のクエリーを処理するには、完全な構造がメモリに常駐している必要があります。HNSW グラフを、オブジェクト ストレージ ファイルに対応するフラグメントに自然に分割する方法はありません。
IVF (転置ファイルインデックス) は異なるアプローチを取ります。学習済みのセントロイドの周りで近接性によってベクトルをクラスタリングし、クエリー時には最も近いクラスターのみを検索します。各クラスターはオブジェクトストレージ上のデータフラグメントに直接マッピングされます — インデックスの残りを読み込むことなく、独立して取得可能です。
このアルゴリズムの選択は、データがどこに存在するかによって直接決まります。標準のベクトル検索は、速度のために完全なインデックスをメモリに保持するため、ストレージとコンピュートが結び付けられます。ストレージ最適化は、スケールアップのためにデータをオブジェクトストレージに移動することで、これらを解放します。しかし、自己完結型でフェッチ可能なパーティションに分解できるインデックスが必要です。IVFはまさにそれを提供します。
Spark 上の分散ベクトルインデックス作成
IVF は、分離ストレージに適したインデックス構造を提供します。エンジニアリング上の課題は、それを大規模に構築することです。ほとんどのベクトル インデックス作成ライブラリ (FAISS、ScaNN、Annoy) は、すべてのデータが 1 台のマシンに収まることを前提としています。これは数千万ベクトルで機能します。768 次元の埋め込みを持つ 10 億個のベクトルでは、インデックスの構築を開始する前に、数テラバイトの生の浮動小数点データが必要になります。1 台のマシンではそれを適切に処理できません。たとえ処理できたとしても、インジェスト時間がシリアルなボトルネックとなり、新しい行が増えるたびに長くなります。
水平にスケールするインデックス作成が必要でした。そこで、分散K-means、プロダクト量子化、パーティション整列データlayoutなど、すべてのインデックス作成アルゴリズムを、短命なserverless Sparkクラスターで実行されるネイティブPySparkジョブとして、ゼロから実装しました。クリティカルパスに単一マシンのインデックス作成ライブラリはありません。エグゼキューターを追加すると、最もコストのかかるステップの時間が線形に短縮されます。
インジェストパイプライン
各取り込みランは、ACIDトランザクションでラップされたステージの有向非巡回グラフとして実行されます。
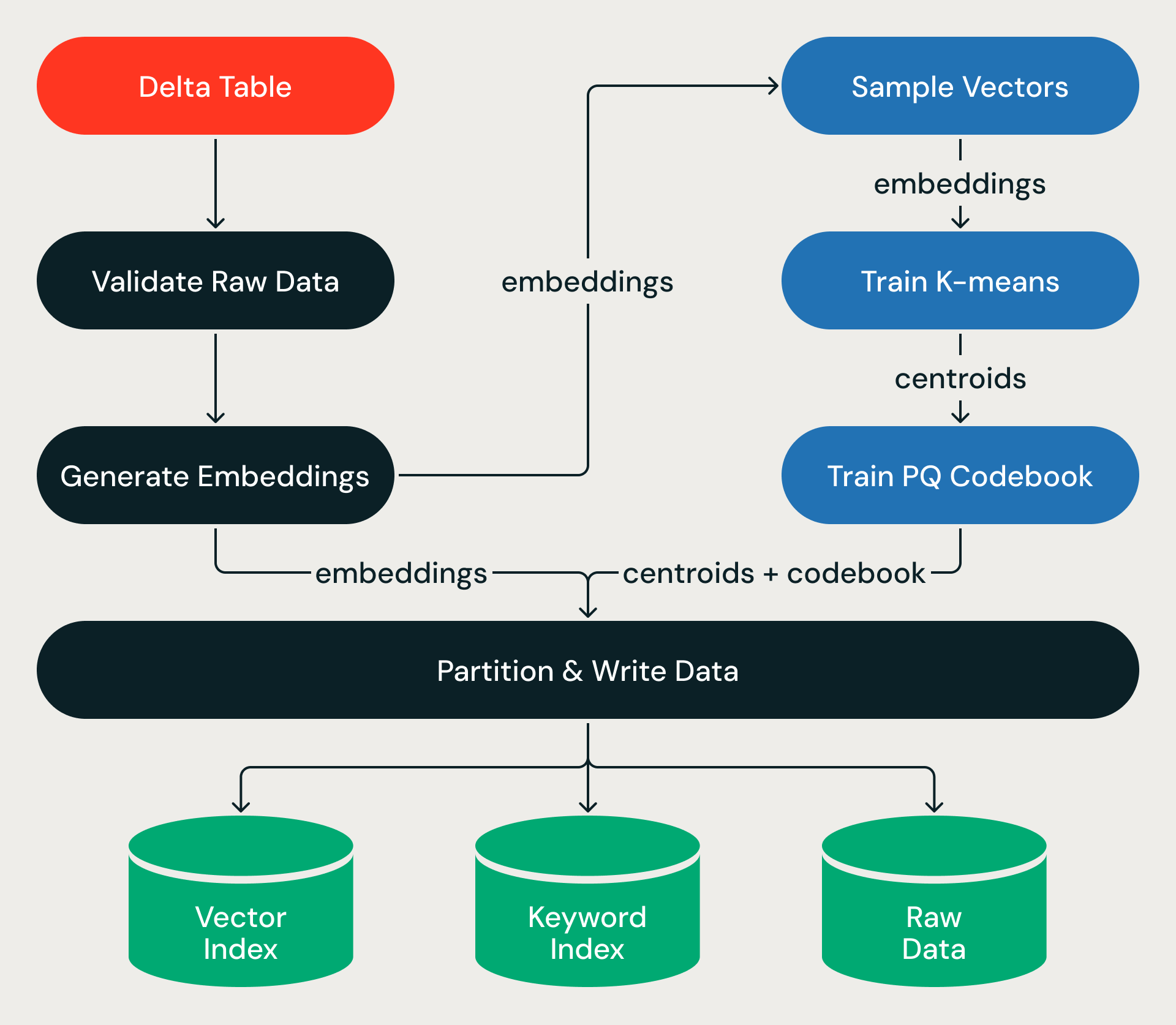
パイプラインは、ソースのDelta Tableから始まります。(事前に計算されたベクトルではなく)ソーステキストに基づくインデックスの場合、ソースデータを検証した後、パイプラインはDatabricks Model Servingを呼び出して、新規または更新された行のベクトル埋め込みを生成し、何十億ものテキストレコードを大規模に高次元ベクトルに変換します。
そこから、パイプラインは小さなサンプルでトレーニングを行い(ベクトル空間の構造を学習)、次にその構造を完全なデータセットに適用し、すべてのベクトルをパーティションに割り当て、圧縮し、結果をオブジェクトストレージに書き込みます。トレーニングは安価です。テラバイト級のデータをエグゼキューター間でシャッフルする、完全なデータセットでのパスに、実時間が費やされます。
K-means: 大規模なパーティショニング
K 平均法クラスタリングはベクトル空間を領域に分割します。これは、クエリがすべてのデータではなく一部のデータを検索できるようにする IVF パーティションです。10 億行のデータセットに対して、約 32K のパーティションを作成します。問題は、標準的な実装がすべてのデータが 1 台のマシンに収まることを前提としている場合に、この規模で K 平均法をどのようにランするかということです。
Spark上でゼロから構築します。
私たちの実装ではハイブリッドモデルを使用しています。Sparkが分散データ移動を処理する一方、ハードウェアで高速化された線形代数を備えた数値計算ライブラリであるJAXが、各エグゼキュータ内での計算を処理します。各K-meansイテレーションは、3ステップのSparkパイプラインです。
- 割り当て — 各エグゼキューターは、ローカルのベクトルバッチから現�在のすべてのセントロイドまでの距離をコンピュートし、各ベクトルの最も近いクラスターを見つけます。
- シャッフル — SparkはセントロイドIDによってデータを再パーティション化し、同じクラスタに割り当てられたすべてのベクトルを同一の場所に配置します。
- 集計 — 各エグゼキューターは、同一場所に配置されたベクトルから新しいセントロイドの位置をコンピュートします。
距離計算がホットループです。JAXは、個々のベクトルを反復処理するのではなく、エグゼキュータごとに単一のバッチ化された行列演算にコンパイルし、バッチごと・セントロイドごとの距離行列全体を一度に計算します。
トレーニングは完全なデータセットではなくサンプルで実行されます。10 億行の場合、約 800 万ベクトル(データの約 0.8%)です。これは任意ではありません。イテレーションあたりの K 平均法のコストは O(n × k × d) です。ここで n はサンプルサイズ、k はクラスター数、d は次元です。n と k の両方を √N に比例するように設定すると、トレーニングの総コストは O(N × d) になり、スケールに関係なくデータセットのサイズに対して線形になります。
この選択は統計的にも十分に根拠があります。コアセット理論によれば、適切に分散されたデータに対する高品質なk-meansクラスタリングにはO(k)のサンプルで十分であり、kは√Nでスケールするため、私たちのサンプルサイズは証明可能に適切です。トレーニングは数回のイテレーションで完了し、後続のパイプラインステ��ージのためにセントロイドをオブジェクトストレージにチェックポイントします。
積量子化:64倍のメモリ圧縮
K-means によって粗いパーティションが得られます。直積量子化 (PQ) はベクトルを圧縮するため、大規模な検索が可能になります。考え方としては、各 768 次元ベクトルをそれぞれ 16 次元の 48 個のサブベクトルに分割し、各サブベクトルを、学習済みコードブック内の最も近いエントリを指す 1 バイトに置き換えます。3,072 バイトのベクトルが 48 バイトになります。これは 64 倍の圧縮率です。10 億個の 768 次元ベクトルの場合、これにより約 3 TiB の生データが約 45 GiB にまで縮小されます。
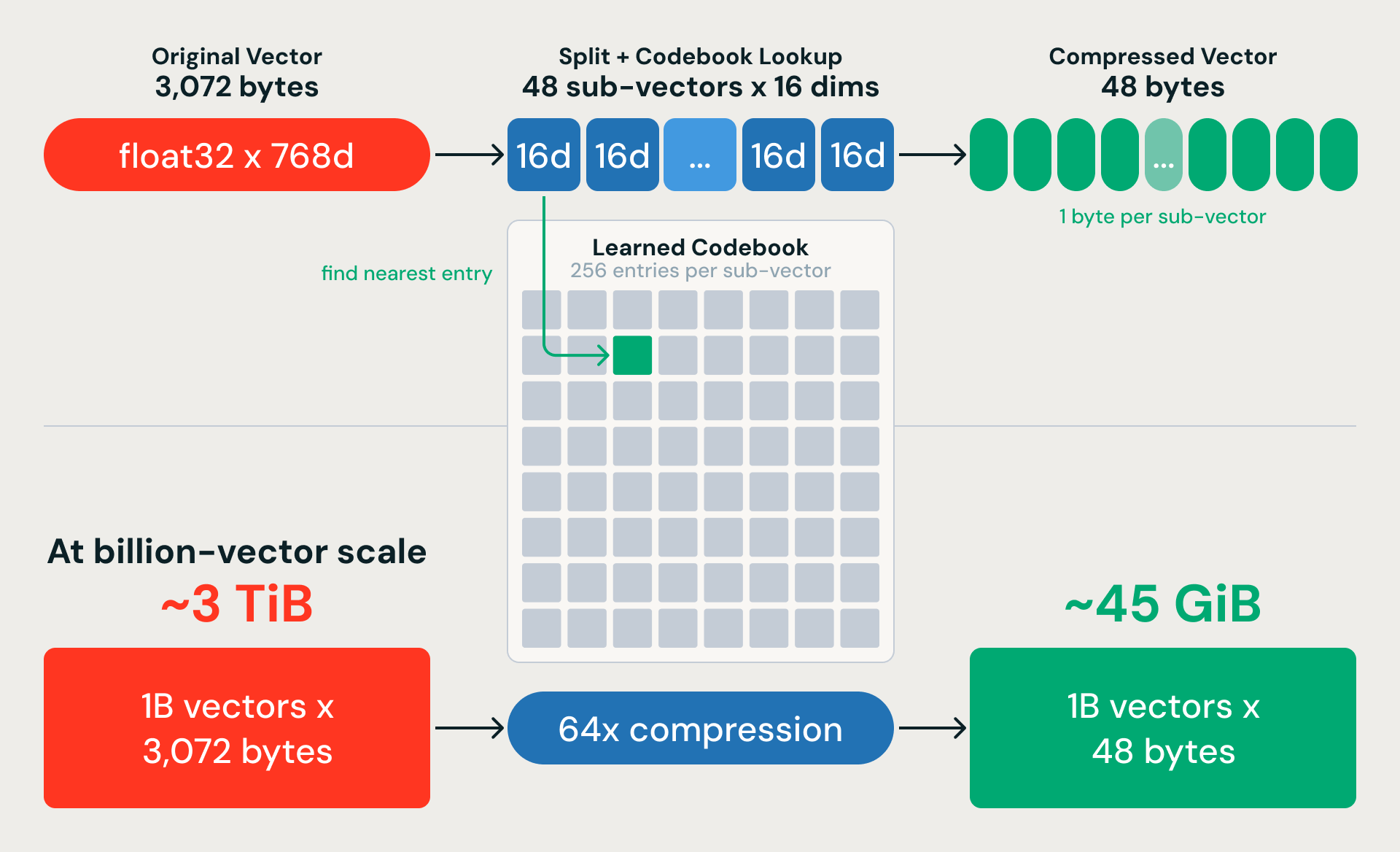
圧縮は非可逆ですが、主要な設計上の選択によって精度の大部分が回復されます。私たちは、生の埋め込みではなく、残差ベクトル(各埋め込みとその最近傍の K-means セントロイドとの差)に対して PQ をトレーニングします。K-means は大規模な構造を捉え、PQ は各パーティション内の細かなバリエーションをエンコードするだけで済みます。
トレーニングからストレージへ
サンプルでトレーニングされたセントロイドとPQコードブックを使用して、パイプラインはすべての行を処理し、各ベクトルにパーティションID(最も近いセントロイド)と圧縮されたPQコードを割り当てます。10億行のデータセットの場合、これはパイプラインの中で最もデータ集約的なステージで��あり、すべてのエグゼキューターにわたって距離とエンコーディングを計算する、データセット全体のSparkジョブです。
次にシャッフルが行われます。パイプラインはパーティションIDによってデータセット全体を再パーティション化し、同じIVFパーティションのベクトルをオブジェクトストレージ上の同じデータフラグメントに物理的に配置します。これにはコストがかかります(テラバイト単位のデータがエグゼキューター間を移動します)が、これこそがクエリーを高速化する要因なのです。同一場所への配置がなければ、単一のIVFパーティションを探索すると、読み取りが数千のファイルに分散してしまいます。これがあれば、同じ探索で少数の連続したフラグメントにヒットします。
書き込みは 3 つの出力を生成し、それぞれが異なるクエリーパス用に最適化されています。
- ベクトルインデックス — 高速なANN検索のためにクエリーエンジンがメモリにロードする形式で書き込まれた、圧縮されたPQコードとパーティションのメタデータ。
- キーワードインデックス — メタデータフィルタリングとハイブリッドキーワード検索のための転置インデックスファイル。
- 生データ — シーケンシャルスキャンとランダムアクセスの両方に最適化されたカラムナフォーマットで保存された完全精度の埋め込みで、リランキング中にオンデマンドでフェッチされます。
3つすべてがイミュータブルなフラグメントとして書き込まれます。一度書き込まれると、変更されることはありません。書き込みが完了すると、バージョンマニフェストが新�しいインデックスをアトミックに公開します。これは、インジェストとサービングの間の契約です。つまり、オブジェクトストレージ上にある、クエリーエンジンが直接読み取れる状態の、イミュータブルでパーティションアラインされたデータフラグメントのセットです。
大規模な取り込み
ストレージ最適化は、768次元で10億を超えるベクトルのインデックスをサポートします。これは、3億2000万ベクトルを上限とする標準ベクトル検索からの大きな変化です。
インジェストはサービングから完全に分離されたエフェメラルな Spark クラスターで実行されるため、スケーリングはエグゼキューターを追加するだけで済みます。実際には、これにより本番運用のインデックス構築において桁違いの改善が見られます。

インデックスが書き込まれ、アトミックにオブジェクト ストレージに公開された後、次の問題は、本番運用で十分な速さでクエリーを処理するにはどうすればよいかということです。
オブジェクトストレージ用のクエリーエンジン
ストレージとコンピュートを分離することで、コストの問題が解決します。しかし、それは新たな問題を引き起こします。つまり、すべてのクエリーがオブジェクトストレージへのネットワークラウンドトリップを伴うようになったのです。圧縮されたインデックス(メモリに収まるほど小さい)はstartup時にロー��ドされますが、完全精度の埋め込みはBLOBストレージに残り、オンデマンドでフェッチされるか、ローカルディスクキャッシュから提供されます。サービングレイヤーは、データをオフノードに移動してもクエリーのレイテンシーが損なわれないように、十分に高速でなければなりません。
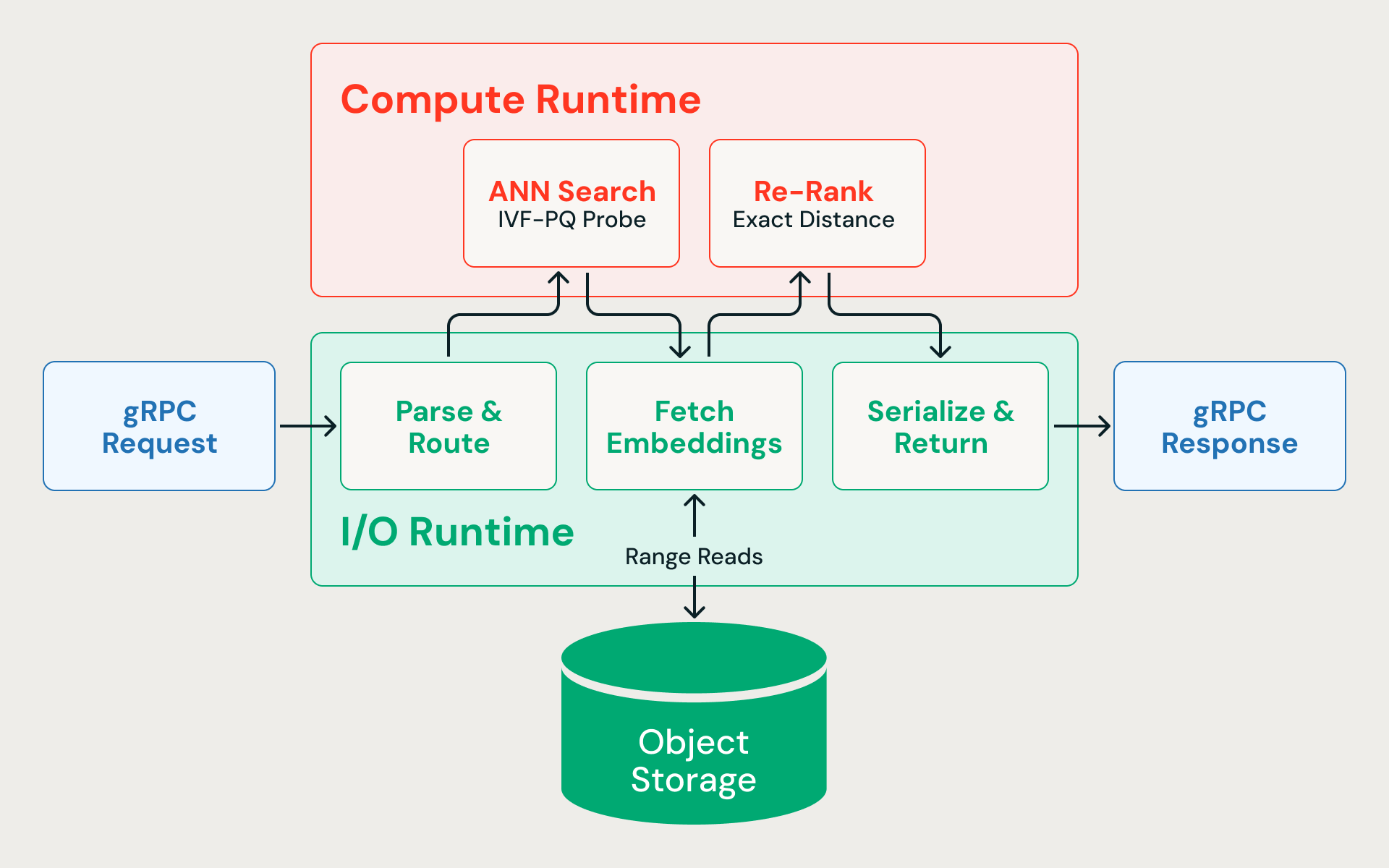
クエリーの構造
最近傍探索がエンジンに到達したときに起こることは次のとおりです。
- 解析 & ルーティング (I/O)。gRPC リクエストは非同期 I/O ランタイムに到着し、デシリアライズされ、正しいインデックスにルーティングされます。
- ANN 検索 (CPU)。クエリベクトルは IVF クラスターのセントロイドと比較され、最も関連性の高いパーティションが特定されます。それらのパーティションのみがプローブされ、圧縮されたベクトルをスキャンして近似距離をコンピュートします。検索では意図的に候補を多めに取得(オーバーフェッチ)します。たとえば、呼び出し元が10件を要求した場合に400件を取得するなどです。これは、量子化された距離が近似値であり、初期の網を広げることで再ランキング後の最終的な再現率が向上するためです。
- 完全精度のベクトルをフェッチ(I/O)。並列バイト範囲読み取りにより、各候補の生の埋め込みがクラウドストレージからフェッチされます。インジェストパイプラインが同じIVFパーティションの行を同じデータフラグメントに配置するため、これらの読み取りはパーティションプルーニングされ、データセット全体にランダムアクセスするのではなく、少数のファイルにヒットします。このステップが、エンドツー��エンドのレイテンシーの大部分を占めます。
- 再ランキング (CPU)。完全精度の埋め込みは、正確な距離計算を使用してスコアリングされ、圧縮によって失われた精度を回復します。
- シリアライズして返す(I/O)。最終的な上位 N 件の結果は、関連するメタデータとともにシリアライズされ、呼び出し元に返送されます。
すべてのクエリーは、非同期 I/O と CPU バウンドな計算を交互に繰り返します。距離計算が非同期ランタイムをブロックすると、保留中のストレージ読み取りが山積みになり、レイテンシが急上昇します。
2つのランタイム
解決策は、それらを同じスレッドで競合させないことです。クエリエンジンは、GCの一時停止なしで予測可能なレイテンシを実現するためにRustで書かれており、2つの専用スレッドプール(1つは非同期I/O用、もう1つはCPUバウンドのベクトル計算用)に実行を分割します。どちらのワークロードも他方を枯渇させることはありません。
I/OランタイムはTokio非同期エグゼキューター上で実行され、gRPCリクエストの解析、ブロブストレージの範囲読み取り、サービス間通信、および応答のシリアル化を処理します。ストレージの読み取りがレイテンシのボトルネックであるため、このランタイムはブロッキングすることなく、数百の並列リクエストを処理し続ける必要があります。
コンピュートランタイムは、独自のスレッドプールでベクトル距離計算、パーティションプロービング、再ランキングを実行します。CPU コアのサブセットは I/O ランタイム用に明示的に予約されており、コンピュートがマシン全体を消費することは決してありません。
読み取りの結合
スレッド分離だけでなく、I/Oパス自体のチューニングも必要でした。初期のプロファイリングにより、エンジンがオブジェクトストレージに対して多数の小さな単一ベクトルの範囲読み取りを発行していることが明らかになりました。各呼び出しにはリクエストごとのオーバーヘッドとレイテンシの変動が伴い、そのロングテールは数百ミリ秒に達するため、多数の小さなリクエストはクエリーごとのレイテンシの大きなばらつきを意味しました。
解決策は読み取りの統合でした。つまり、ベクトルごとに1つの範囲読み取りを発行する代わりに、ストレージレイヤーが保留中のバイト範囲リクエストをファイルオフセットで並べ替え、設定可能なブロックサイズのウィンドウ内に収まるものをすべて単一の読み取りにマージします。リクエストの数を減らしてサイズを大きくすると、呼び出しごとのオーバーヘッドは減少しますが、マージされた各読み取りではクエリーに不要なバイトもフェッチしてしまいます — これがリードアンプリフィケーションです。このトレードオフには、経験的なチューニングが必要でした。
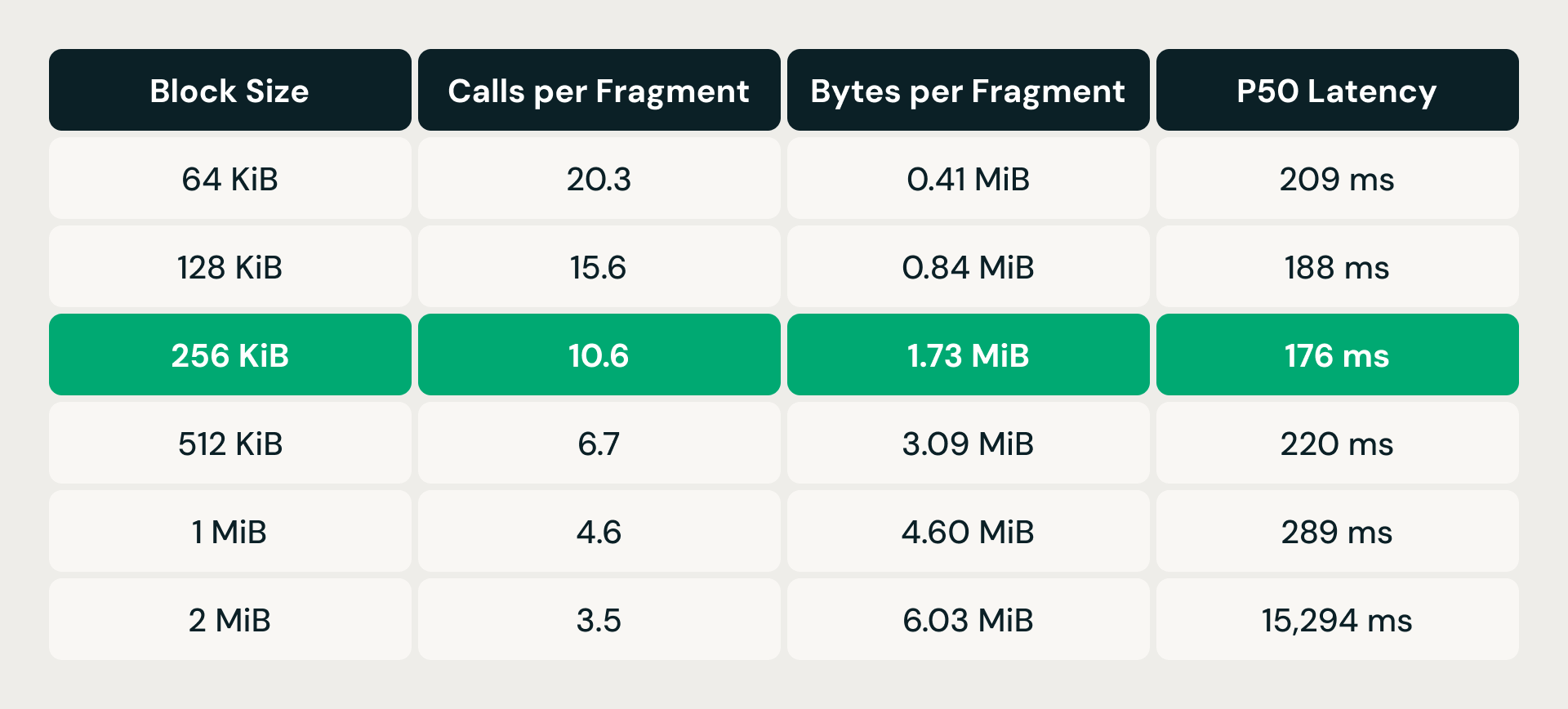
64 KiB の場合、各データフラグメントは 20 回を超えるストレージ呼び出しを必要としましたが、取得したのは 0.5 メガバイト未満でした。リクエストごとのオーバーヘッドが大部分を占めていたのです。ブロックサイズを倍にすると呼び出し回数が着実に減少し、レイテンシは 256 KiB まで改善しました。しかし、そのポイントを過ぎると、リード増幅が優勢になりました。呼び出し回数がはるかに少ないにもかかわらず、512 KiBではレイテンシーが64 KiBのベースラインを上回るまで上昇しました。2 MiBでは15秒以上に急増しました。256 KiBのスイートスポットは、リード増幅をフラグメントあたり2 MiB未満に抑えながら、呼び出し回数を約半分に削減し、テストされたどの構成よりも低いp50レイテンシーを実現しました。
考察
このアーキテクチャのすべてにおいて、クエリーのレイテンシと引き換えにスケールとコストを優先しています。768次元で上位10件の結果の場合、再現率 (返された真の最近傍の割合) は、1,000万ベクトルで94%以上、1億ベクトルで91%以上を維持し、10億ベクトルでも90%を維持します。再ランキングのステップでは、オブジェクトストレージから完全精度のベクトルを取得して正確な距離を再計算することで、圧縮コードだけでは大規模になると失われる精度を回復します。その再ランキングのラウンドトリップもまた、クエリー時間を占める主な要因です。すべてをメモリ内に保持する標準Endpointでは20~50ミリ秒であるのに対し、クエリーは1,000万ベクトルで約300ミリ秒、10億ベクトルではおよそ500ミリ秒で返されます。
�このわずかな追加時間で得られるメリット: 10億ベクトル規模のインデックス構築が8時間未満で完了し、大規模なデータセットではStandardよりも20倍高速になります。積量子化はメモリ内フットプリントを1桁以上圧縮し、取り込みは各ビルド後にリソースを解放するエフェメラルなSpark クラスターで実行され、ストレージとサービングを分離することはどちらの側も過剰にプロビジョニングされないことを意味します。その結果、同じスケールで顧客のコストが最大で7倍低くなります。
セマンティック検索、推薦パイプライン、検索拡張生成など、多くのワークロードにとって、そのトレードオフは明らかにスケールとコストを優先します。取得後のステージ(ランキング、フィルタリング、LLM 生成)がエンドツーエンドの時間を占めることが多く、40ミリ秒と400ミリ秒の違いはエンドユーザーには見えません。ミリ秒単位の差が重要となるレイテンシの影響を受けやすいサービングでは、標準ベクトル検索のほうが優れたツールです。2つのオプションは補完的であり、それぞれ異なるワークロードに対応するツールです。
学んだこと
既存のシステムを最適化するのではなく、ベクトル検索システムを一から構築したことで、組み合わせることで初めて成果が上がる一連の賭けをせざるを得ませんでした。
ストレージとコンピュートの分離は、クエリーエンジンが十分に高速である場合にのみ機能します。データをオフノードに移動するとコストを節約できますが、オブジェクトストレージへのネットワークラウンドトリップやローカルディスクキャッシュ��からの読み取りなど、すべてのクエリーにI/Oが追加されます。デュアルランタイムのRustエンジンは、まさにそのレイテンシを吸収するために存在します。非同期I/Oが数百の読み取りを並行処理し続ける一方で、CPUスレッドがブロッキングなしで距離計算を処理します。そのエンジンがなければ、このアーキテクチャは安価なストレージと低速なクエリーを提供するだけで、魅力的なトレードオフにはなりません。
分散インデックス作成は、インデックス形式がそれをサポートしている場合にのみ機能します。Spark上でK-meansとPQを構築することで、取り込みの水平スケールが可能になりますが、出力は、クエリーエンジンが再構築ステップなしでオブジェクトストレージから直接提供できるものでなければなりません。カスタムストレージ形式 — 不変のデータフラグメント、分離されたトランザクションマニフェスト、クラウドストレージ上のACIDセマンティクス — が、そのループを完結させます。取り込みは、クエリーエンジンが読み取る形式に直接書き込みます。
圧縮は経済性を左右する要因です。Product Quantizationは、単にメモリコストを削減するだけではありません。アーキテクチャの実行可能性そのものを変えるのです。このレベルの圧縮がなければ、10億ベクトルの量子化コードをメモリに保存するには依然としてテラバイト単位のRAMが必要になり、標準的なベクトル検索に対するコスト優位性は失われてしまうでしょう。PQにより、ANN検索フェーズをメモリ内に保持しつつ、それ以外のすべてをオブジェクトストレージに移行することが可能になります。
これらは独��立した最適化ではありません。どれか1つでも欠けると、システムはコストが高すぎるか、ビルドが遅すぎるか、あるいはサービングが遅すぎて実用的ではなくなります。
まとめ
今後の困難な問題は、これらのトレードオフから直接生じます。よりスマートなキャッシュ、階層型ストレージ、より高密度なインメモリ表現を通じて、クエリーパフォーマンスをさらに向上させること(より高速な応答、より高いスループット、より優れた同時実行性)。10億規模での更新をほぼリアルタイムにすること。最終的なランキングシグナルとして生のベクトル距離を超えること。つまり、ベクトルの類似性、キーワードの関連性、ドメインのコンテキストを組み合わせて、単に最も近いだけでなく、最も有用な結果を導き出す、学習された多段階のランキングを目指すこと。
私たちは、次世代のAI製品はまだ発明されていないインフラストラクチャ上に構築され、そのインフラストラクチャを構築するエンジニアがAIの可能性を形作っていくと信じています。あなたがその一員になりたいのであれば、私たちと一緒に構築しましょう!
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購��読して、最新の投稿を受信トレイにお届けします。