ビジネスユーザーを支えるセルフサービス型データインテリジェンスの実現
Sigma ComputingとDatabricks SQLで銀行業界におけるセキュアなデータインテリジェンスを活用
によって Ricardo Portilla による投稿
- Sigmaがどのように銀行のパーティショナーや非技術的なユーザー、例えばローンオフィサーやプロダクトマネージャーに、Databricksで作成された洞察へのアクセスを提供するかを理解する。* ビジネスユーザーが広大なデータエステートにアクセスし、データインテリジェンスを有効化し、積極的なリテールバンキング製品の提供でビジネスの結果を活性化させることを許可します。
- SigmaとDatabricksがどのようにして、Databricksのコアガバナンスとデータインテリジェンス機能に基づいた効率的なアナリスト体験を作り出すかを示します。
はじめに
データは力です。しかし、リテールバンキングにおいては、その力を行動可能なインサイトに変えると同時に、データセキュリティのリスクを慎重に管理することが求められます。金融機関は、機密データを保護しながらも、データの民主化を取り入れて顧客体験を向上させ、リスクを軽減し、イノベーションを推進するというバランスを取らなければなりません。
Sigma Computingは次世代の分析およびビジネスインテリジェンスプラットフォームとして、安全なアプローチを提供し、顧客セグメンテーション��からリスク評価までのインサイトを銀行が活用できるようにします。そして、それを実現する際にセキュリティを妥協することはありません。
ここからは、DatabricksとSigma Computingがどのようにこれらの重要なユースケースを支援し、銀行がより賢く、安全な意思決定を行えるようにしているかを掘り下げていきます。
データインテリジェンスは銀行業界の新たな生命線
NubankのようなデジタルバンクやWiseやBrexのようなフィンテック企業は、顧客にシームレスなデジタル体験、リアルタイムの金融サービス、透明な料金体系を提供することで、従来の大手銀行を凌駕しています。一方で、従来の銀行はレガシーインフラの影響で遅れを取ることが多く、この技術的負債が開発サイクルを長期化させています。その結果、新しい製品の開発や進化する顧客の期待への対応能力が制限されています。今やデータは戦略的資産であり、銀行はデータを競争優位性として活用することができます。
データインテリジェンスは、企業データの可能性を最大限に引き出す鍵です。Databricksは、すべてのユーザーにデータを民主化するというビジョンに沿って、「Genieスペース」などのツールを提供しています。Genie spacesは、ビジネスユーザーがデータを対話型で探索できるインターフェースです。Genieの差別化ポイントは、企業のビジネス用語や技術的なメタデータといったエンタープライズコンテキストを完全に取り込んでいる点にあります。この基盤を活用して、Unity Catalog(Databricksのガバナンスソリューション)を通じてビジネス上の質問に答える仕組みが組み込まれています。

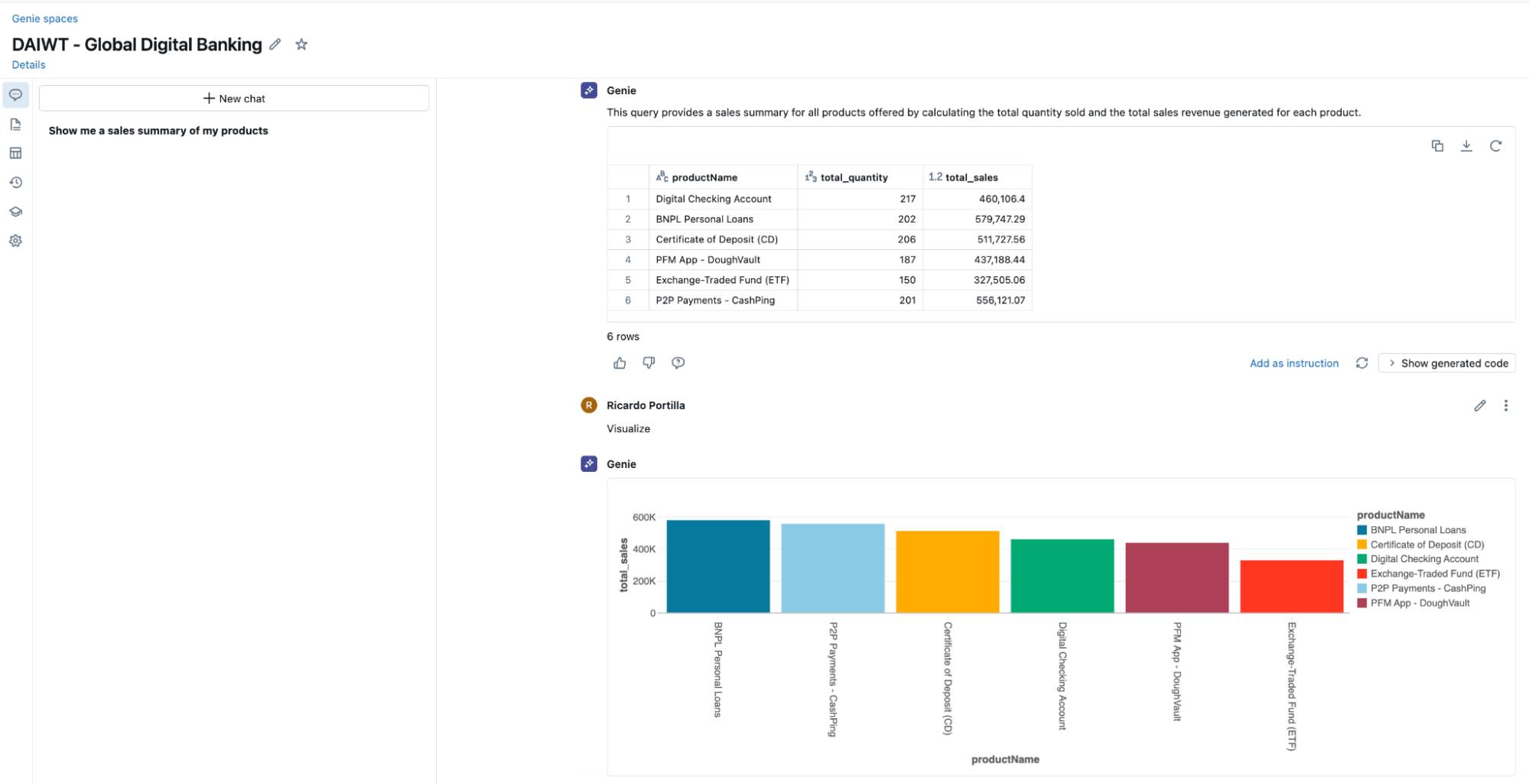{kind=link}
銀行がデータ民主化を達成するのに苦労する理由
銀行は、その性質上、厳格な規制を受けると同時にリスク回避志向が強い業界です。取引履歴から顧客の個人情報に至るまで、大量の機密データを扱うため、サイバー攻撃や内部脅威の標的になりやすいのが現状です。その中で、データの不正転送や窃盗を意味する「データ流出」のリスクは常に存在し、厳格なセキュリティプロトコルが必要とされています。しかし、この状況にはジレンマがあります。データ保護が必須である一方で、過度に制限をかけると、イノベーションを阻害し、意思決定を遅らせる結果につながるのです。
こうした背景において、データの民主化は大きな課題となります。データの民主化は、データの可能性を解き放ち、それを活用して意思決定を行える人々(データアナリスト、プロダクトマネージャー、経営陣など)の手に渡すことを目指します��。しかし、銀行はデータへの柔軟で開かれたアクセスを必要としながらも、厳格なセキュリティ対策を維持しなければならないというジレンマに直面しています。
従来の銀行のデータシステムは分断化されており、部門間でデータを円滑に共有するのが難しい構造になっています。不正アクセスへの懸念から、限られた人々だけが重要な情報にアクセスできるという制限的な環境が生まれています。このボトルネックは、データ民主化が提供しようとする俊敏性を阻害します。さらに、銀行はGDPRやCCPAといった地域および世界的な規制基準を順守しつつ、データ駆動型の文化を育む必要があるため、さらなる複雑性が加わります。
こうした課題を解決した成功例の1つが、HSBCによるDatabricksを活用した支払いシステムの再構築です。HSBCは14のデータベースを単一のLakehouseに統合することに成功しました。また、リアルタイムでのデータマスキングによる保護を実現し、顧客セグメンテーション戦略を近代化することで、香港でナンバーワンの支払いアプリを生み出しました。
次のセクションでは、DatabricksとSigma Computingを活用して、こうした課題にどのように取り組めるのかを詳しく探ります。
コンプライアンスを遵守しながらデータインテリジェンスを解放する
ビジネスの問題
リボルビングクレジットにおける銀行商品への顧客ロイヤルティを向上させる任務を負ったビジネスアナリストのチームを想像してください。このアナリストたちに対し、内部のITチームはノーコードで技術的スキルを必要としないツールを提供しなければなりません。しかし、エクスポート機能には厳しい制��限が課される必要があります。一方で、アナリストはデータを操作し、ビジネス結果(例えば、プロアクティブなクレジットラインの引き上げ提案)をステークホルダーに説明するために、系統やメタデータへの完全なアクセスが求められます。
セルフサービス分析のための市場ツール
エンドユーザーにはセルフサービス分析が求められます。ほとんどの場合、この目的を達成するための主要なツールとしてExcelが使用されます。しかし、Excelでデータを提供することは、データ流出のリスクを高め、データのコピーが増殖して非効率を生む確実な方法です。そこで登場するのがSigma Computingです。
Sigmaは、データセットへの無制限のアクセスを提供することなく、エンドユーザーがデータフィードや分析を閲覧できる手段を提供します。また、スプレッドシートのユーザー体験(UX)に馴染みがあるため、特にExcelユーザーにとって採用のハードルが低くなります。さらにSigmaは、「セキュアエンベッド」と呼ばれる構造を用いて、非技術的ユーザーにデータを拡張するユニークな方法をプラットフォームチームに提供します。
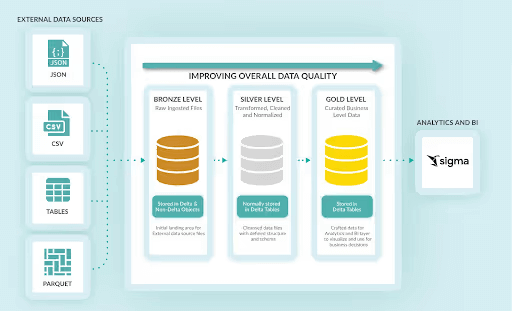
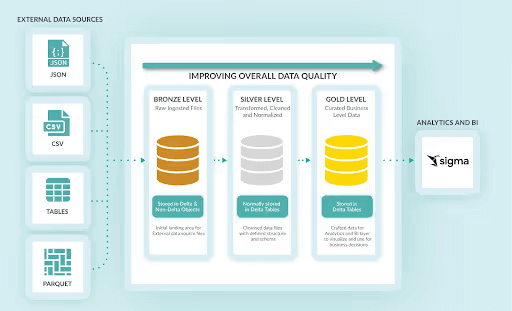{kind=link}
SigmaのSecure Embedを使用した真の自己サービスの提供
Sigmaは、お選びのアプリケーションにセキュアな埋め込み自己サービスウィジェットを作成することができます。例えば、開発者はFlaskアプリ、埋め込みメール、またはJWTトークンで認証しSigmaサービスを呼び出すTeamsの統合を作成することができます。JWT(JSON Web Tokens)は、コンパクトでURL安全なトークンで、システム間で情報を安全に伝送し、データの完全性と認証を保証します。この形式は、大企業が機密情報を露出することなくユーザーを安全に認証するための、現代のAPI駆動型アプリケーションの基盤となっています。このSigma ComputingとDatabricksの統合では、JWTはユーザーにリアルタイムでパーソナライズされたワークブックとダッシュボードへのアクセスを保証します。JWTは、金融データへのセキュアなクライアントアクセスを可能にし、この実装はダッシュボードへのアクセスを保護し、各トークン内にユーザー固有のクレームを埋め込むことでパフォーマンスとセキュリティを維持します。
ワークスペースの権限がない埋め込みユーザー
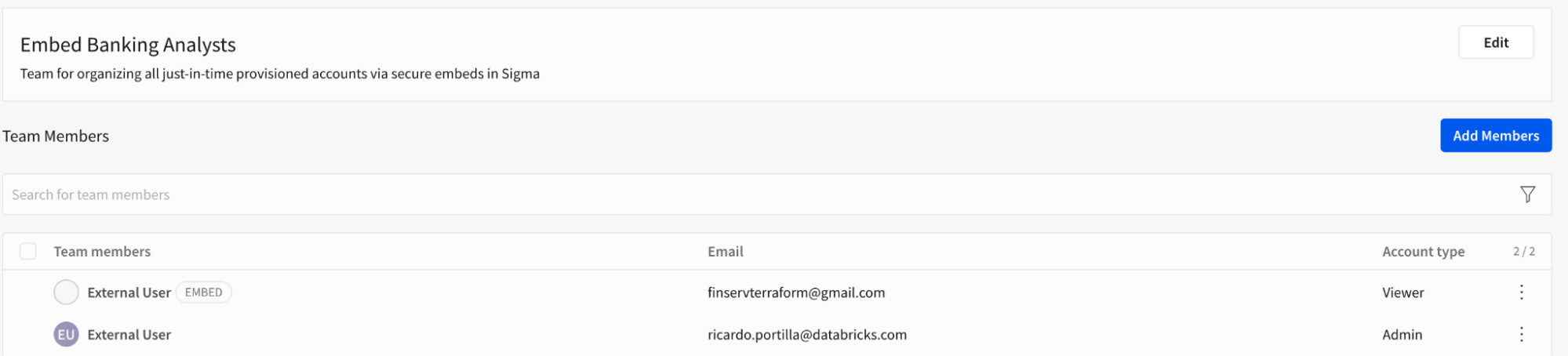
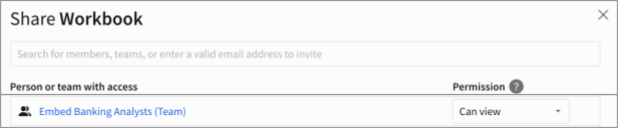
ユーザーは今や簡単にデータにアクセスでき、ロールベースのアクセス制御を適用して、ワークブックの所有者が一度だけの切り替えで制限されたアクセスを提供できます。参考のために以下の画像をご覧ください。ここでは、外部ユーザーは「Embed Banking Analysts」チームに所属しています。分析ワークブックの所有者は、埋め込みユーザーチームに一度だけアクセスを提供し、エンドユーザーは自分が利用できる任意のデータセットを消費する準備ができています。Unity Catalogの一部として定義されたすべての細かいアクセス制御は、特に行と列レベルのフィルタリングにおいてDatabricksのグループに拡張されます。
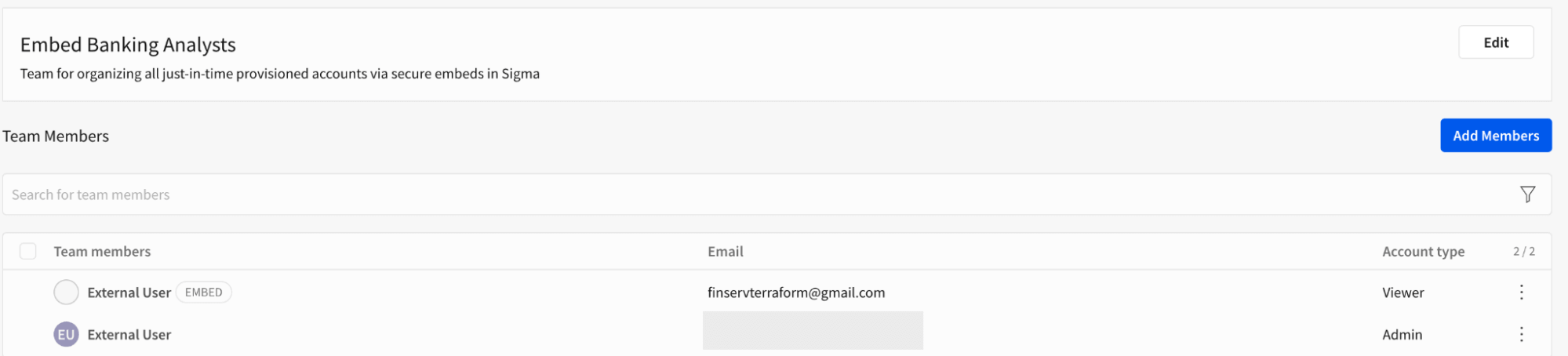
{kind=link}

{kind=link}
ドメインインテリジェンスレイクハウス上での金融分析アプリのデプロイメント
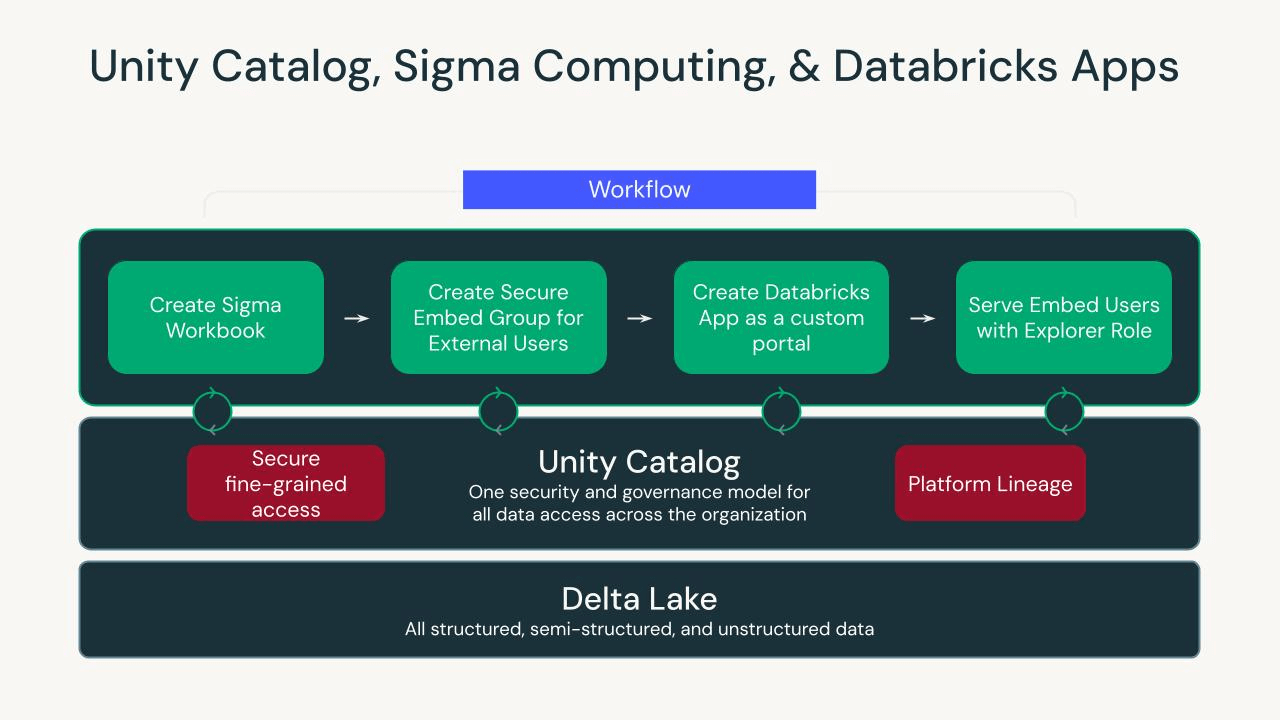
Databricksは現在、アプリケーションをセキュアな埋め込みユーザーに提供するための新しく、洗練された方法を提供しています - Databricks Apps。Databricks Appsを使用すると、データエンジニアリングチームはコードをDatabricksワークスペースに開発し同期させ、数分以内にアプリケーションをデプロイすることができ、標準的なカスタムポータルでのように、アナリストや非技術的なユーザーがデータにアクセスできるようになります。Databricks Appsを使用しているか、自己ホスティングのアプリケーションを使用しているか(私たちはAppsデモでFlaskを使用しています)、プラットフォームチームは、ピボットテーブルや即席の比率を銀行のユースケースで利用するのに慣れている非技術的なユーザーにデータを完全に民主化するために、埋め込みユーザーをオンボードすることができます。
{kind=link}
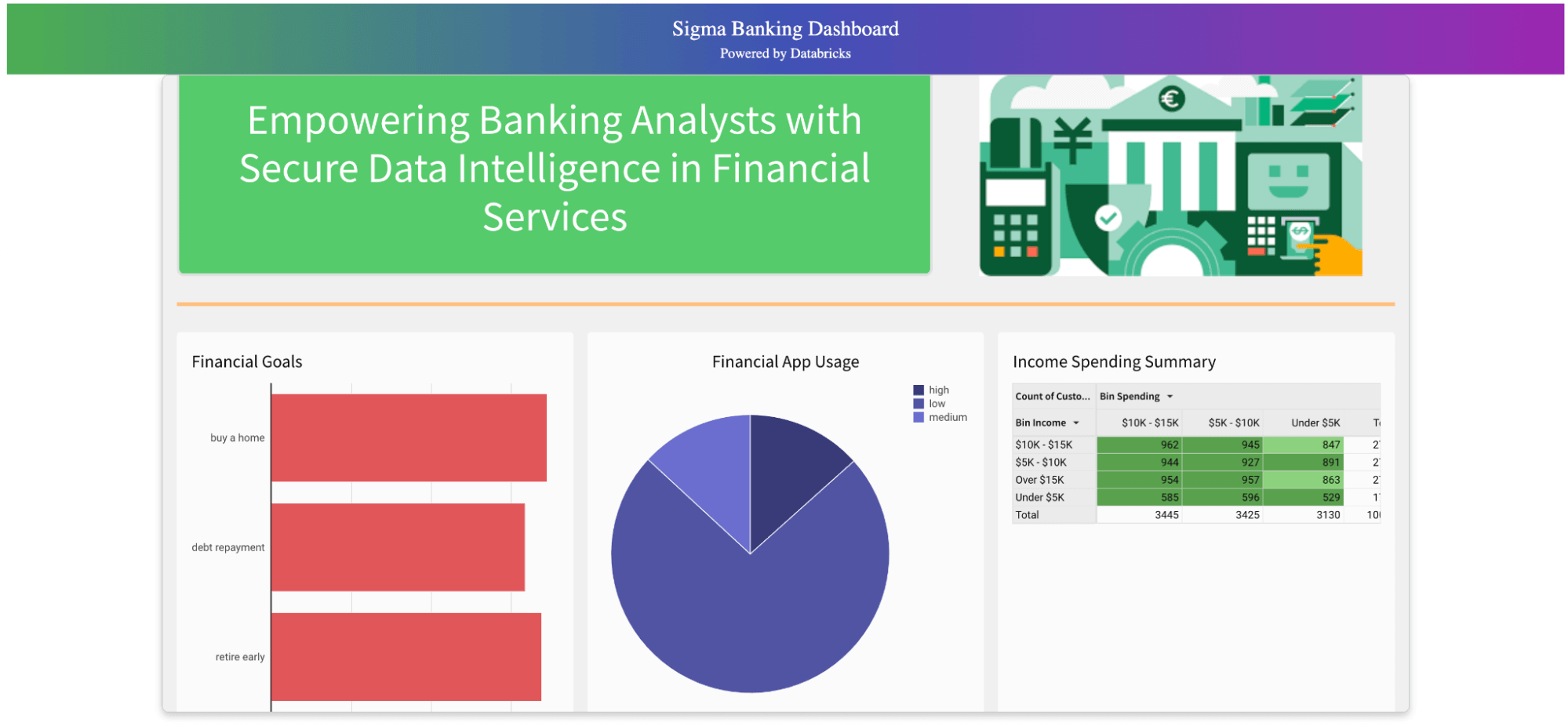
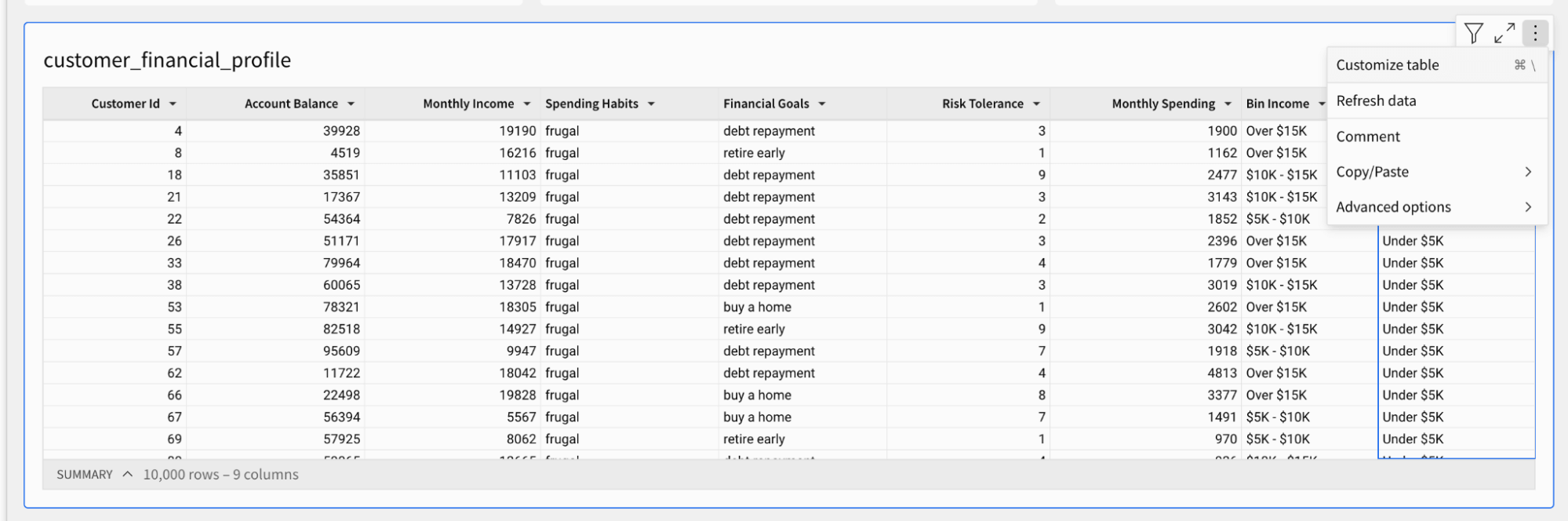
�私たちのサンプルアプリでは、内部プロファイルを持つ顧客と、クレジットビューロ(例:TransUnion)やPlaid、Yodleeなどの金融アグリゲータからの外部データに焦点を当てています。これらはクレジットスコア、クレジットライン、金融商品の使用傾向を提供します。当初の要約(以下、赤字)では、ほとんどの顧客が住宅所有に興味があることが示されています。一方で、エンゲージメントは低く、私たちが働く銀行はロイヤルティを高めることに興味があります。出発点として、埋め込みユーザーは迅速に流動性比率を見て、積極的なクレジットラインの増加を目指す顧客セグメントをターゲットにすることができます。
{kind=link}
私たちが見る分析は有用ですが、データエクスフィルトレーションのリスクを犠牲にせずに、埋め込みユーザーにより良い探索体験をどのように提供できるでしょうか?
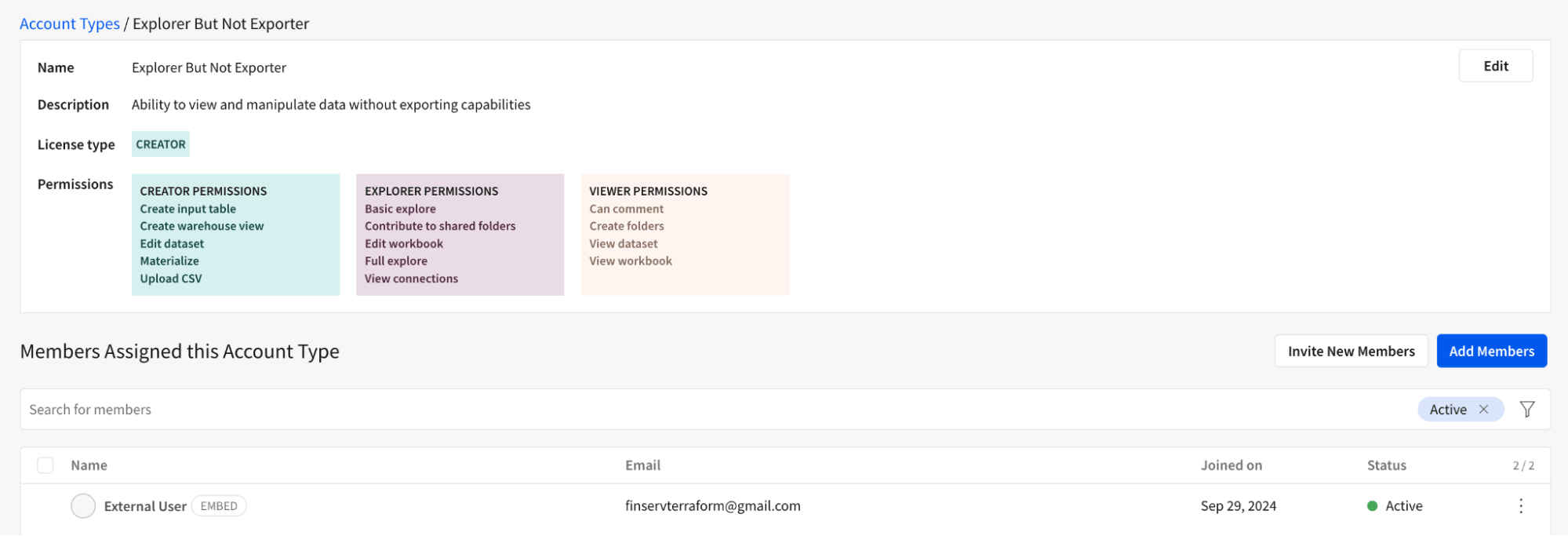
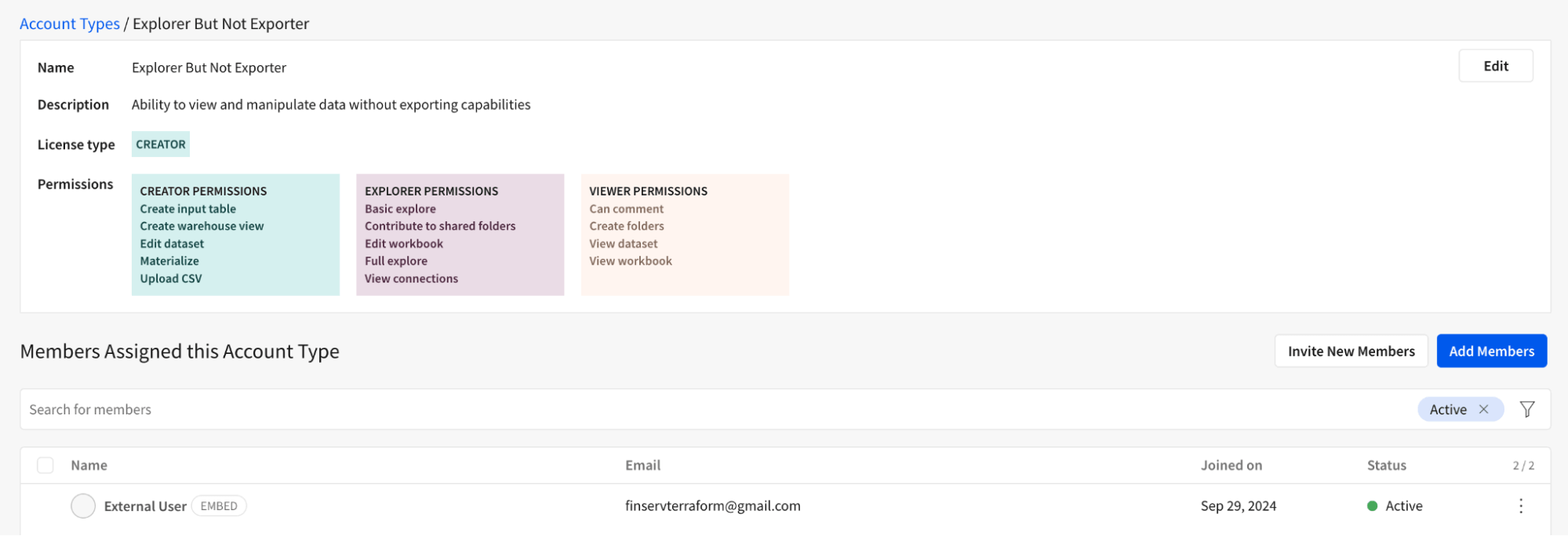
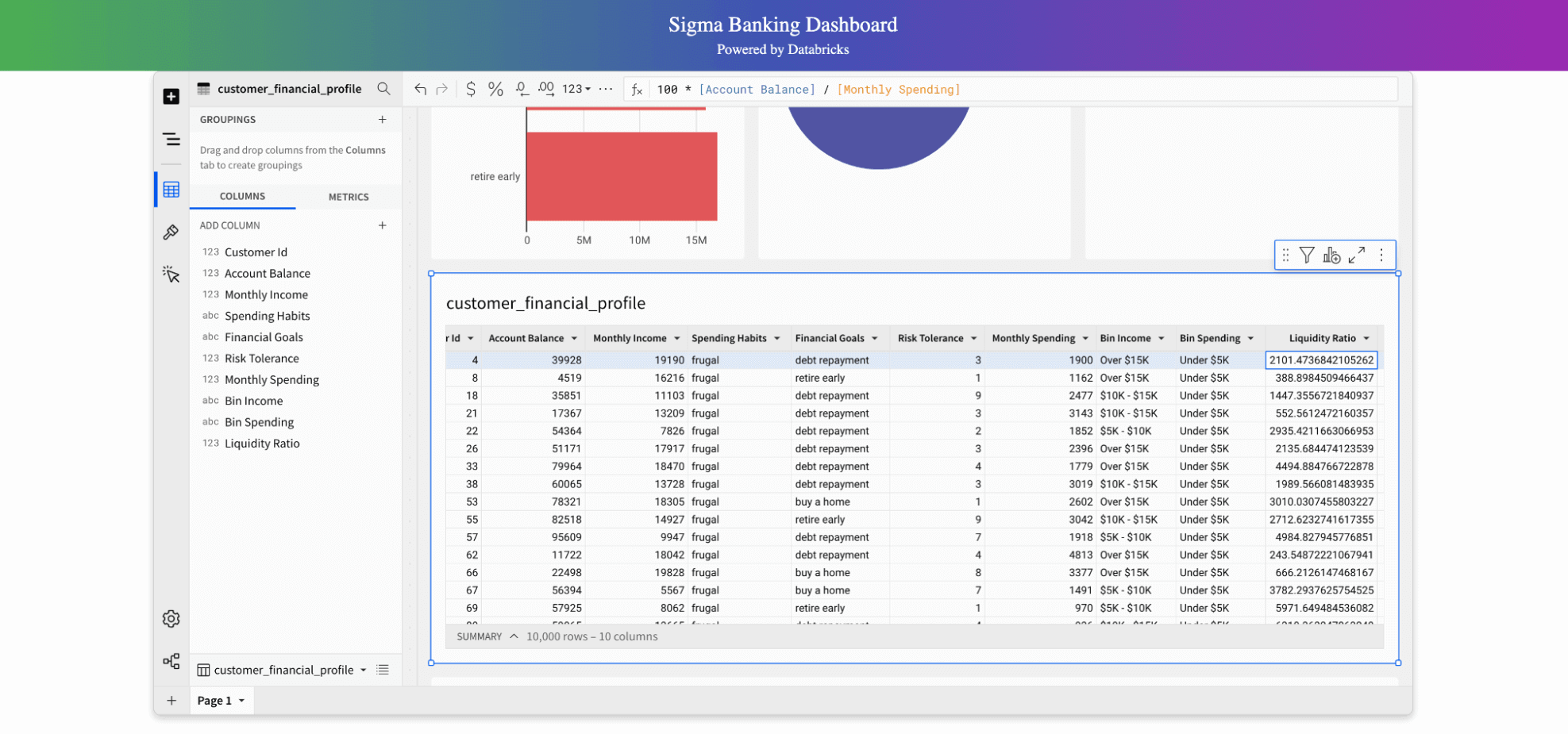
下記のように、Sigma環境内で完全にカスタマイズされた「エクスプローラーだがエクスポーターではない」という役割を作成し、ユーザーがダウンロードボタンを使用してデータをエクスポートするのを防ぐことができます。イノベーションの精神で、アナリストユーザーにワークブックの編集権限を与えます。例えば、新しい列の計算や作成など、これによりより豊かな体験が可能となり、銀行クライアントのための積極的なクレジットラインの増加や投資の機会を効率的に評価するための流動性比率などの計算を追加できます。ユーザーは今、自分の質問に合わせた分析を追加することが完全に可能になりました。
{kind=link}
{kind=link}
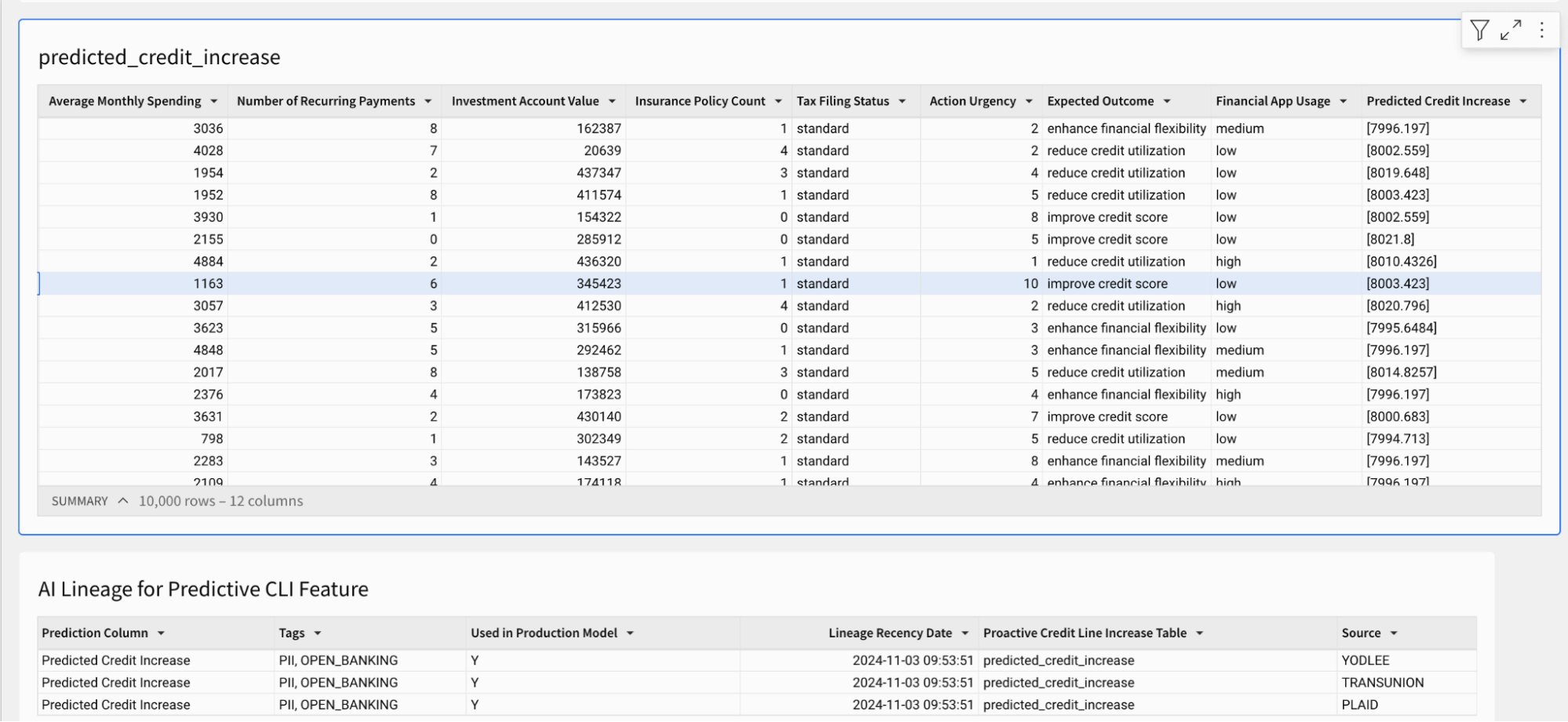
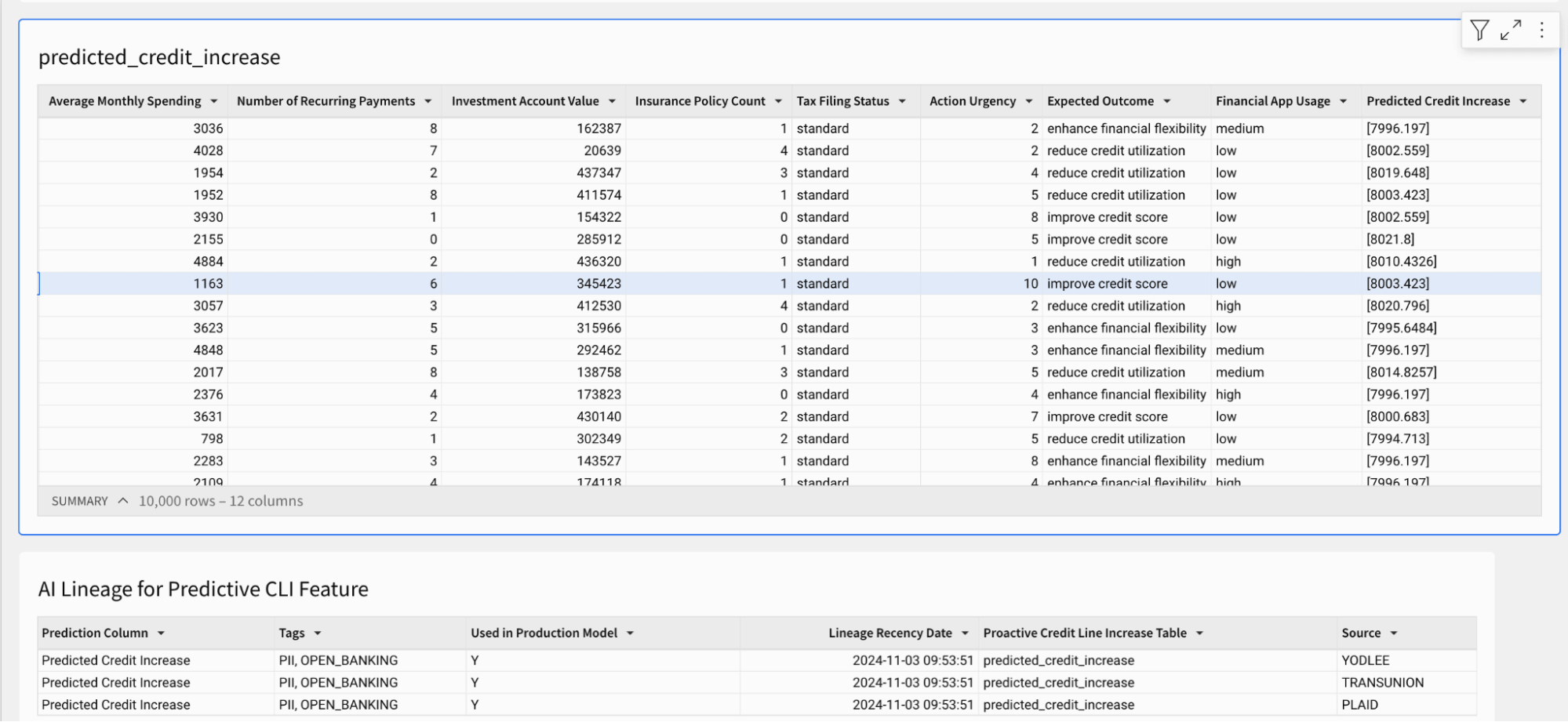
新しいビニング、ヒートマップ、セグメンテーションリストの作成が可能になった一方で、どのようにして生成されたデータの信頼性を確保するのでしょうか?アプリケーションのサンプルテーブルでは、積極的なクレジットラインの増加予測を示しており、これを今すぐターゲットセグメントに適用することができます。アナリストは、分析と結果をビジネスのステークホルダーやエグゼクティブに説明するために、予測がどこから来たのかを理解する必要があります。Unity Catalogに組み込まれたラインエージは、データだけでなくモデル、ダッシュボード、機能、関数にまで及び、予測が正確にどこから来たのかを特定することができます。以下のすべての派生元情報とタグは、Unity Catalogシステムテーブルから簡単に取得できます(AWS | Azure | GCP)、これによりビジネスとの信頼性と説明可能性が高まります。
{kind=link}
まとめ
金融サービス業界は岐路に立っています。従来の銀行は、フィンテックの破壊者がリアルタイムのデータインテリジェンスを通じて顧客体験を再定義し続ける中、古く、孤立したデータシステムに縛られたままでいることはもはや許されません。この高リスクな環境では、安全なデータの民主化は単なる贅沢ではなく、生命線となります。
Sigma Computingの安全な埋め込み機能と、Databricksの堅牢なアプリケーションデプロイメントプラットフォームとデータレイクハウスを組み合わせたものは、セキュリティを妥協することなくデータを活用しようとする銀行にとって変革的なソリューションを提供します。Sigmaの安全な埋め込みは、厳格な規制要件に完全に合致した制御された体験を提供します。Sigmaを使用すると、銀行はアナリスト、調査員、プロダクトマネージャー、営業チームに、より安全でコンプライアンスを満たした環境で重要な洞察を得る能力を与えることができます。
Databricksにアプリケーションをデプロイすることで、金融機関は安全なデータアクセスを迅速かつシームレスに拡張し、ユーザーを組み込みながら、データセキュリティに鉄壁の握りを維持し、体��験をカスタマイズすることができます。エラーの余地がほとんどない業界では、安全な組み込みアプリケーションを通じてデータ駆動型の洞察を提供する能力が競争優位性となります。
金融機関へのメッセージは明確です:受動的なデータ戦略の時代は終わりました。セキュアで自己サービス型のデータインテリジェンスを採用することで、リスクを軽減し、今日のデジタル市場で成功するために必要な機動性を解放します。銀行は今すぐ進化しなければならず、Sigma ComputingやDatabricksのようなツールを活用することで、生の情報を行動に移せる洞察に変えるデータ駆動型の文化を活性化することができます。
安全で、セルフサービスのデータインテリジェンスを有効にするために、今日DatabricksとSigmaにサインアップしてください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。