Databricks Unity CatalogをオープンなApache Hive Metastore APIで拡張可能になりました
統一されたガバナンスによるオープンで相互運用可能なエンタープライズデータカタログの構築
によって トッド・グリーンスティン, Junlin Zeng, Vihang Karajgaonkar, ジーシャン・パッパ, Abhishek Pratap Singh, サチン タクール 、 Matei Zaharia による投稿
Original: Extending Databricks Unity Catalog with an Open Apache Hive Metastore API
翻訳: saki.kitaoka
本日、Databricks Unity CatalogのHive Metastore(HMS)インターフェイスのプレビューを発表しました。Apache Hiveは、業界で最も広くサポートされているカタログインターフェースであり、事実上すべての主要なコンピューティングプラットフォームで使用可能です。この機能により、企業はデータ管理、発見、ガバナンスをUnity Catalogに一元化し、Amazon Elastic MapReduce(EMR)、オープンソースのApache Spark、Amazon Athena、Presto、Trinoなど、さまざまなコンピュータプラットフォームから接続することができます。また、これらのプラットフォーム間で一貫したデータガバナンスを確保することができます。
このプレビューに参加するには、Databricksの担当者にお問い合わせください。
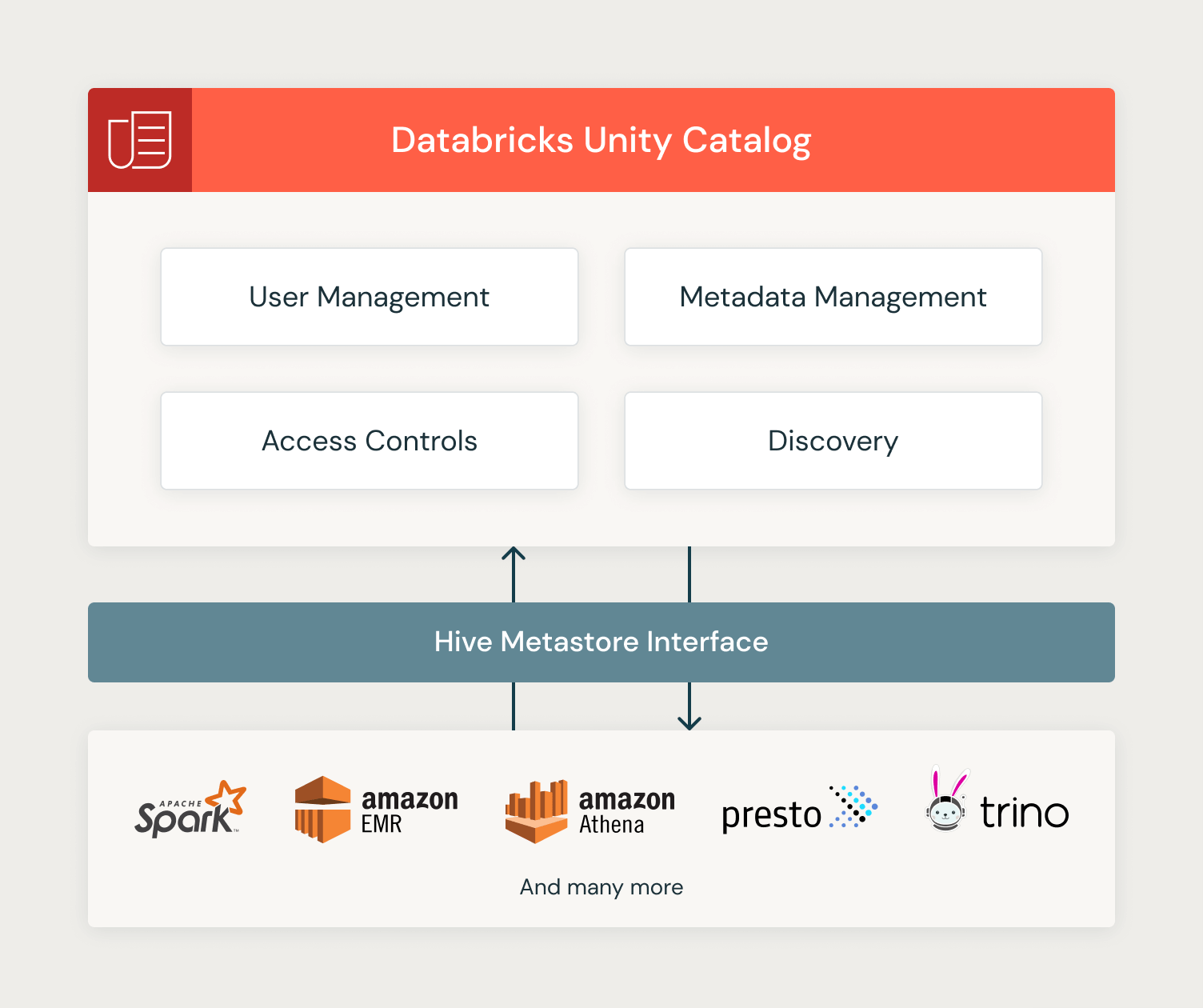
急速に進化する今日のデータ管理環境では、多くの組織が複数のコンピューティング・プラットフォームを運用し、それら全体で一貫してデータ発見とガバナンスを実施するという課題に直面しています。そのため、データチームは複数のデータカタログやガバナンスツールをやりくりしなければならないことが多く、運用上のオーバーヘッドが大きくなり、データの発見、アクセス管理、監査が困難になることがあります。
Databricks Unity Catalogは、データの発見、権限の管理、アクセスの監査、データの系統と品質の追跡、組織間でのデータの共有といったシンプルな機能を備えた、データ、アナリティクス、AI向けの統合ガバナンス・ソリューションです。HMSインターフェイスにより、業界標準のApache Hive APIをサポートするあらゆるソフトウェアをUnityに接続できるようになり、コンピューティングプラットフォーム間のガバナンスが大幅に簡素化されました。
このブログでは、この機能の利点と、データ管理の実践をどのように強化できるかを探ります。
Unity CatalogにHive Metastoreのインターフェイスを構築した理由
オープン性
多様なデータエコシステムでは、シームレスなデータ統合とコラボレーションにおいて、オープン性が重要な役割を果たします。Apache Hiveは、業界で最も広くサポートされているカタログAPIです。Unity CatalogのオープンHMSインターフェースは、当社のオープンレイクハウスプラットフォーム戦略に合致しており、企業データへのアクセスやベンダーロックインを回避するための統一的かつ標準的なアプローチを提供します。このオープンインターフェースでUnity Catalogを使用することで、組織はデータ管理アーキテクチャを簡素化し、現在および将��来のツールの両方をサポートできるようにすることができます。
一貫性のあるデータガバナンス
複数のプラットフォームにまたがるデータを管理することは、一貫したガバナンスを維持する上で大きな課題となっています。Unity CatalogのHMSインターフェースは、Unity Catalogが提供するエンタープライズグレードのガバナンスを多様なコンピュートプラットフォームに拡張することで、この課題に効果的に取り組みます。この統合により、一貫したデータコンプライアンスを確保し、セキュリティ対策を強化し、堅牢なアクセス制御を実施し、集中的な監査を容易にすることができます。
レガシーワークロードをモダナイズする簡単な手段
異なるコンピューティングプラットフォームで稼働する長年のレガシーワークロードをお持ちのお客様は、HMSインターフェース統合により、レガシーワークロードとDatabricksワークロードの両方を包含するメタデータとアクセスコントロールをUnity Catalogに集中化することができます。この統合により、Amazon EMRなどのプラットフォームで稼働しているワークロードを、移行プロセスを通じて一貫性を確保しながら、簡単に移行できるようになります。
コスト最適化
UnityカタログのHMSインターフェースは、組織にコスト最適化の大きな利点をもたらします。従来、組織は複数のカタログを管理するために多大な時間とリソースを費やす必要があり、追加コストが発生するだけでなく、複雑さや潜在的な不整合も生じていました。また、複数のカタログ間でデータやポリシーを同期させることは、壊れやすく、エラーが発生しやすいものです。この�統合により、別々のデータカタログを管理、維持、同期する必要がなくなります。
まとめ
Unity CatalogのHMSインターフェースは、オープンな相互運用性とエンタープライズグレードのガバナンスという、両者の長所を融合させたものです。Unity Catalogを多様なコンピュート・プラットフォームと接続することで、企業はデータへのアクセス性の向上、ガバナンスの改善、スケーラビリティ、コストの最適化、相互運用性、将来性の確保を実現し、複数のデータプラットフォームを管理するための高い運用コストを排除できます。これにより、企業はデータ資産を最大限に活用することに集中することができます。
このエキサイティングなプレビューに参加するには、Databricksの担当者にお問い合わせください!
また、データおよびAIガバナンスに関するさらなるエキサイティングな最新情報をお見逃しなく!Data and AI Summit.のセッションにぜひご登録ください!
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。