DatabricksでSpark JDBCを使用してSAP HANAのリアルタイムデータを最も速く統合する方法
によって クリシュナ・サティアバラプ による投稿
SAPとDatabricksの戦略的パートナーシップに関する最近の発表は、SAP顧客の間で大きな興奮を呼んでいます。データとAIの専門家であるDatabricksは、SAP HANAとDatabricksを統合することで、分析およびML/AI機能を活用するための魅力的な機会を提供します。このコラボレーションへの多大な関心を受けて、私たちは詳細なブログシリーズを開始できることを嬉しく思います。
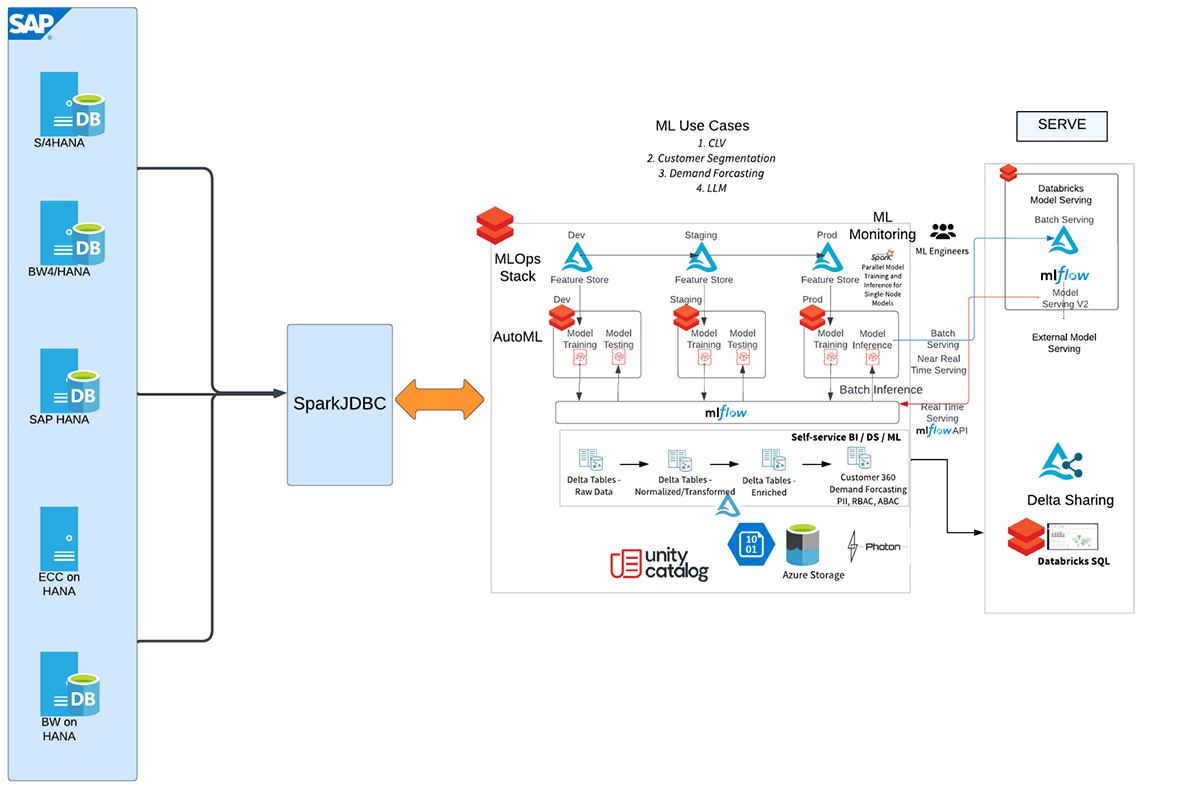
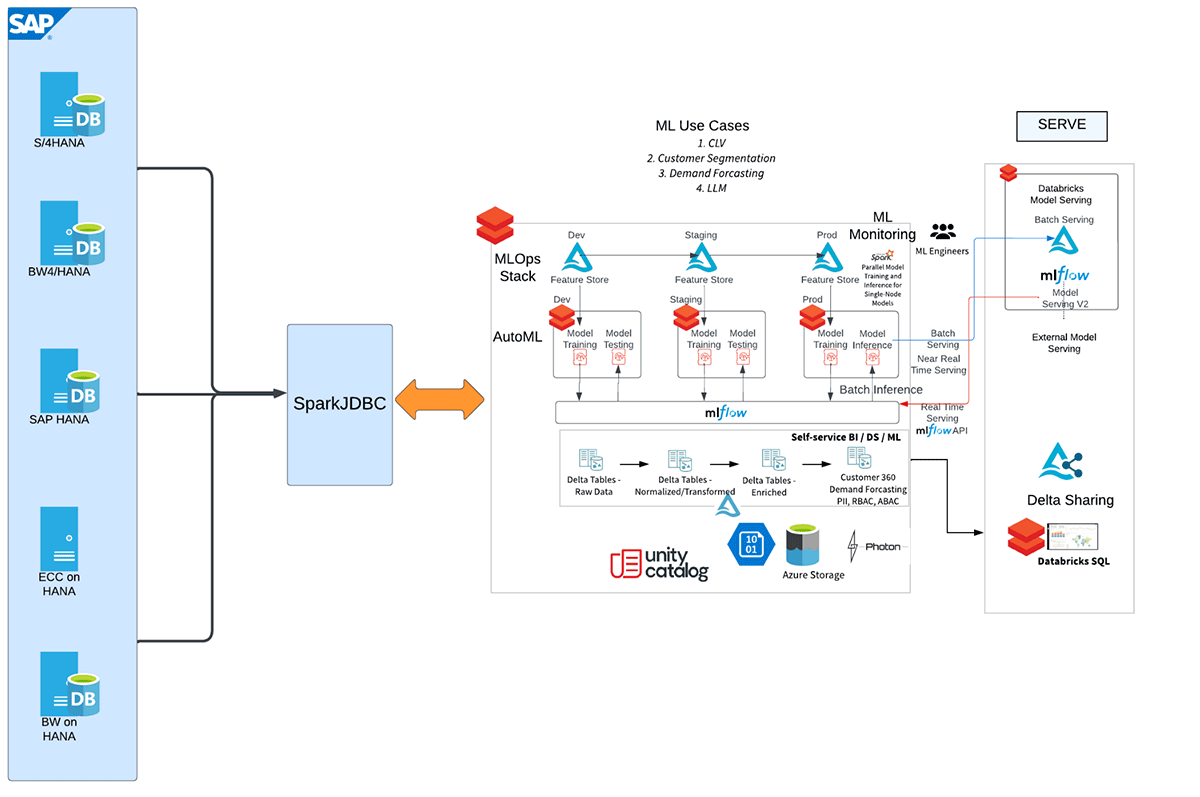
多くの顧客シナリオでは、SAP CRM、SAP ERP/ECC、SAP BWを含むさまざまなソースシステムからのデータ基盤としてSAP HANAシステムが主要な役割を果たします。ここで、この堅牢なSAP HANA分析サイドカーシステムをDatabricksとシームレスに統合し、組織のデータ機能をさらに強化するというエキサイティングな可能性が生まれます。SAP HANA(HANA Enterprise Editionライセンスが必要)をDatabricksに接続することで、企業はDatabricksの高度な分析および機械学習機能(MLflow、AutoML、MLOpsなど)を活用しながら、SAP HANA内に保存されている豊富で統合されたデータを活用できます。この統合により、企業は貴重な洞察を引き出し、SAPシステム全体でデータに基づいた意思決定を推進するための多くの可能性が開かれます。
DatabricksでSAP HANAテーブル、SQLビュー、および計算ビューを統合するには、複数のアプローチがあります。しかし、最も速い方法はSparkJDBCを使用することです。SparkJDBCの最大の利点は、SparkワーカーノードからリモートHANAエンドポイントへの並列JDBC接続をサポートしていることです。
{kind=link}
SAP HANAとDatabricksの統合から始めましょう
まず、SAP HANA 2.0がAzureクラウドにインストールされており、Databricksとの統合をテストしました。
AzureにインストールされたSAP HANA情報:
| バージョン | 2.00.061.00.1644229038 |
| ブランチ | fa/hana2sp06 |
| オペレーティングシステム | SUSE Linux Enterprise Server 15 SP1 |
この統合のさまざまなステップを示す、ハイレベルなワークフローを以下に示します。
SparkJDBCを使用してSAP HANAの計算ビューおよびテーブルからDatabricksにデータを抽出するための、より詳細な手順については、添付のノートブックを参照してください。

{kind=link}
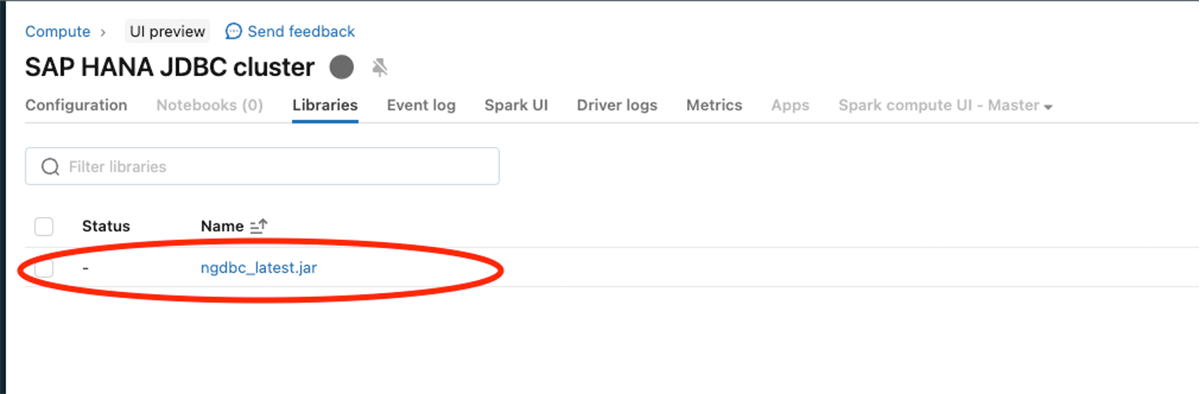
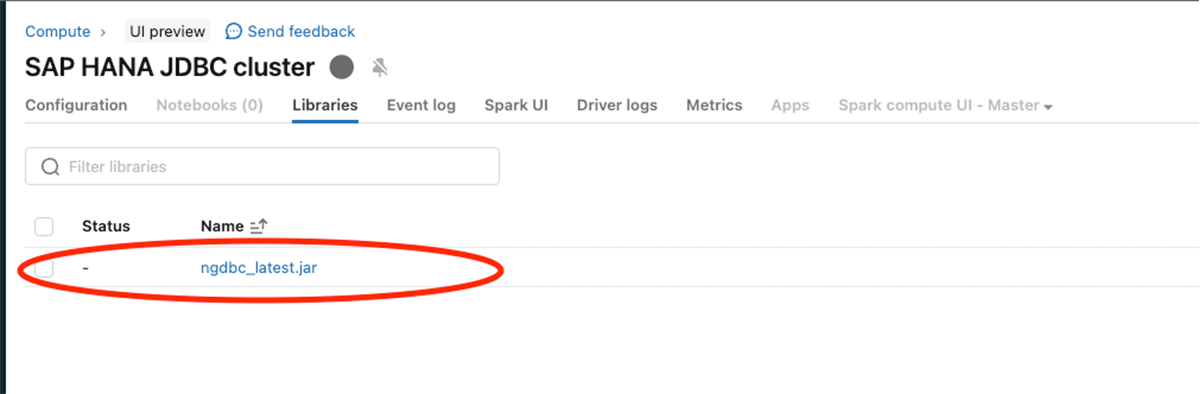
以下の画像に示すように、SAP HANA JDBC jar(ngdbc.jar)を構成します。
{kind=link}
上記の手順を実行したら、SAP HANAサーバーとJDBCポートを使用してSpark読み込みを実行します。
{kind=link}
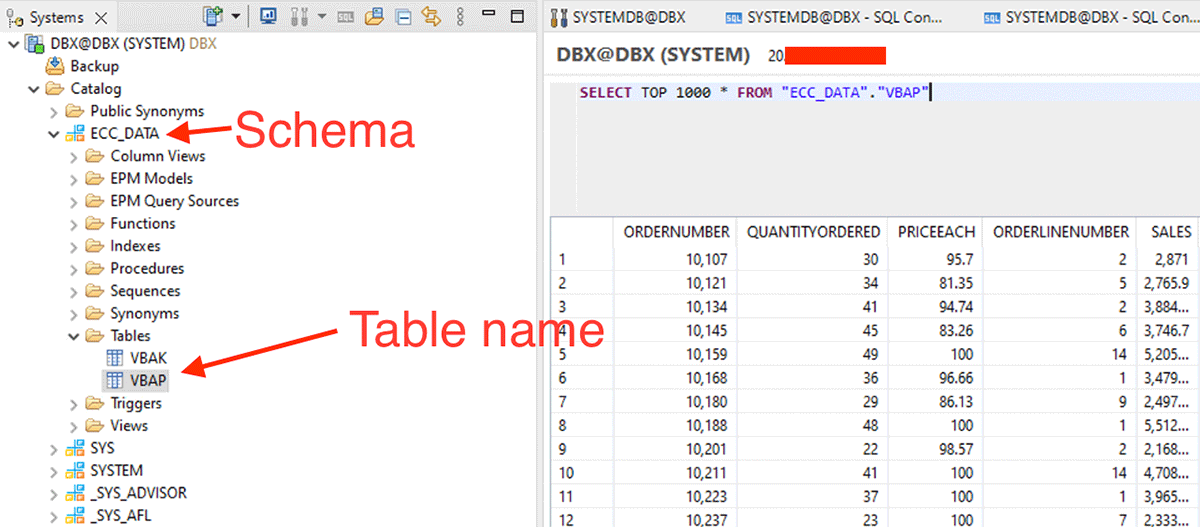
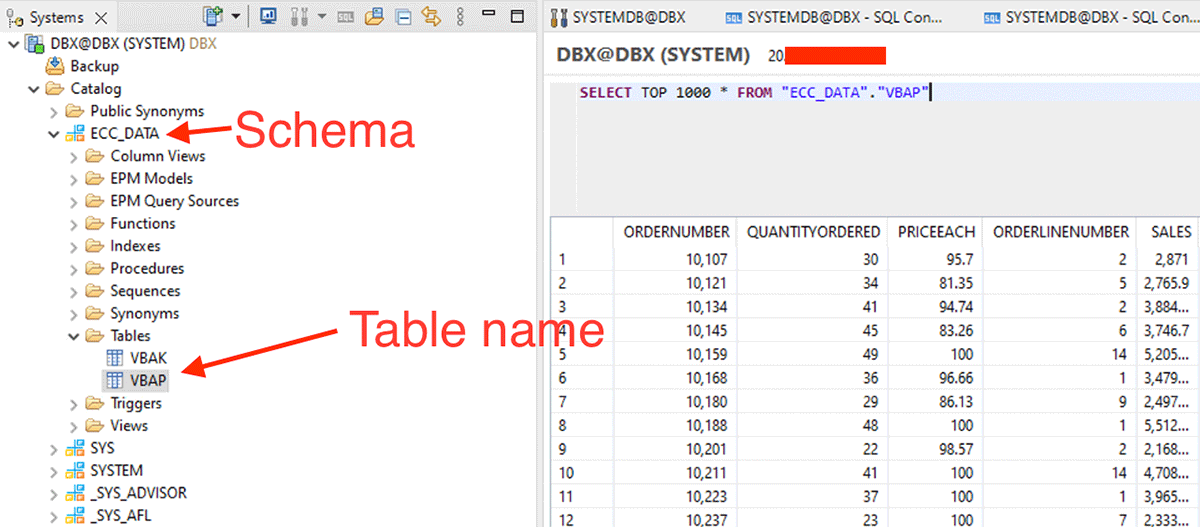
以下に示すスキーマとテーブル名を使用して、データフレームの作成を開始します。
また、dbtableオプションでSQLステートメントを渡すことで、フィルタープッシュダウン��を実行することもできます。
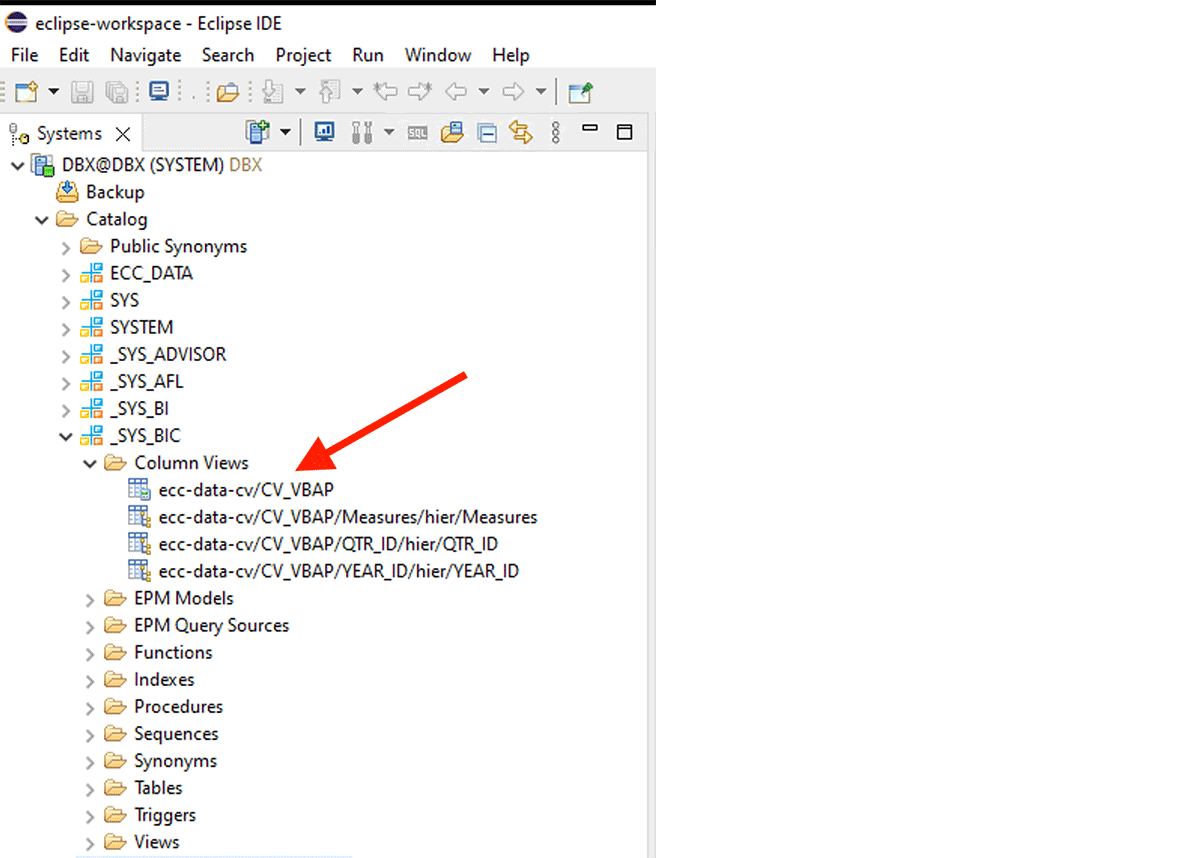
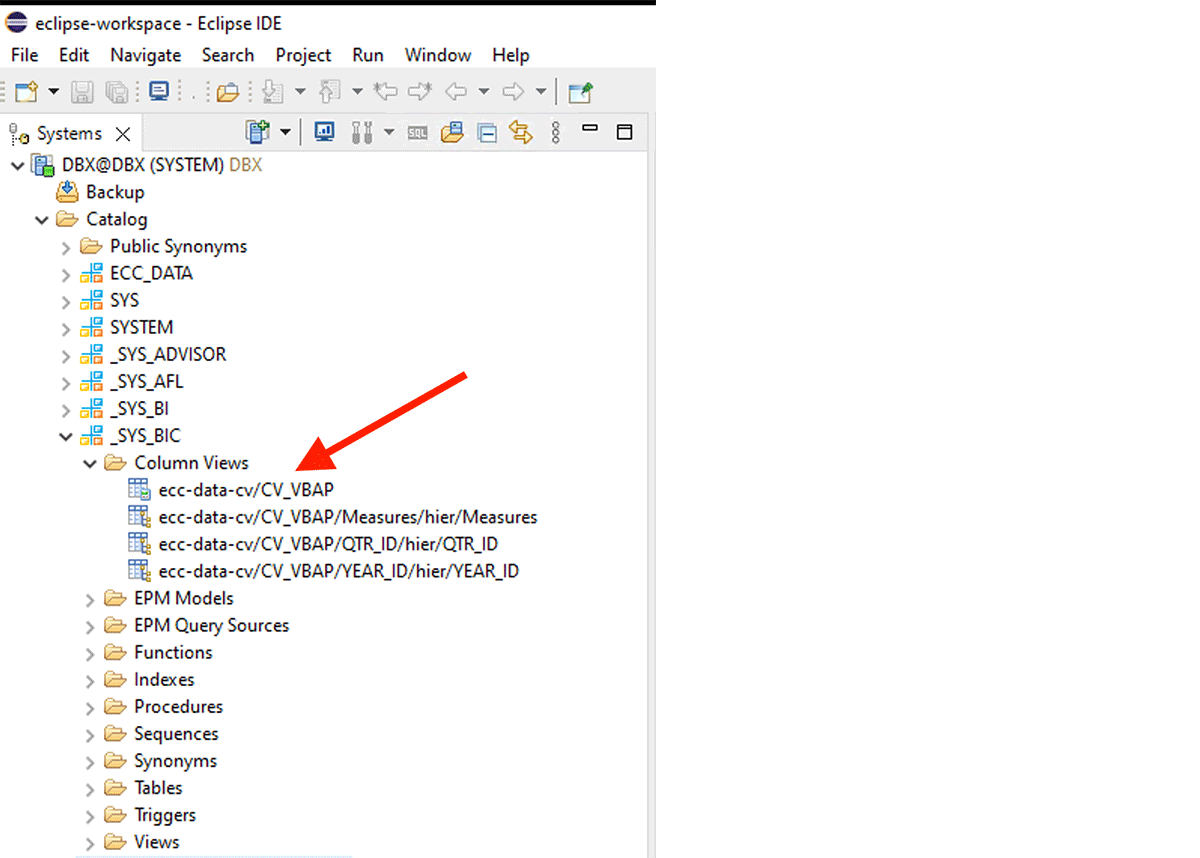
計算ビューからデータを取得するには、次の手順を実行する必要があります。
たとえば、このXSクラシック計算ビューは内部スキーマ「_SYS_BIC」に作成されています。
{kind=link}
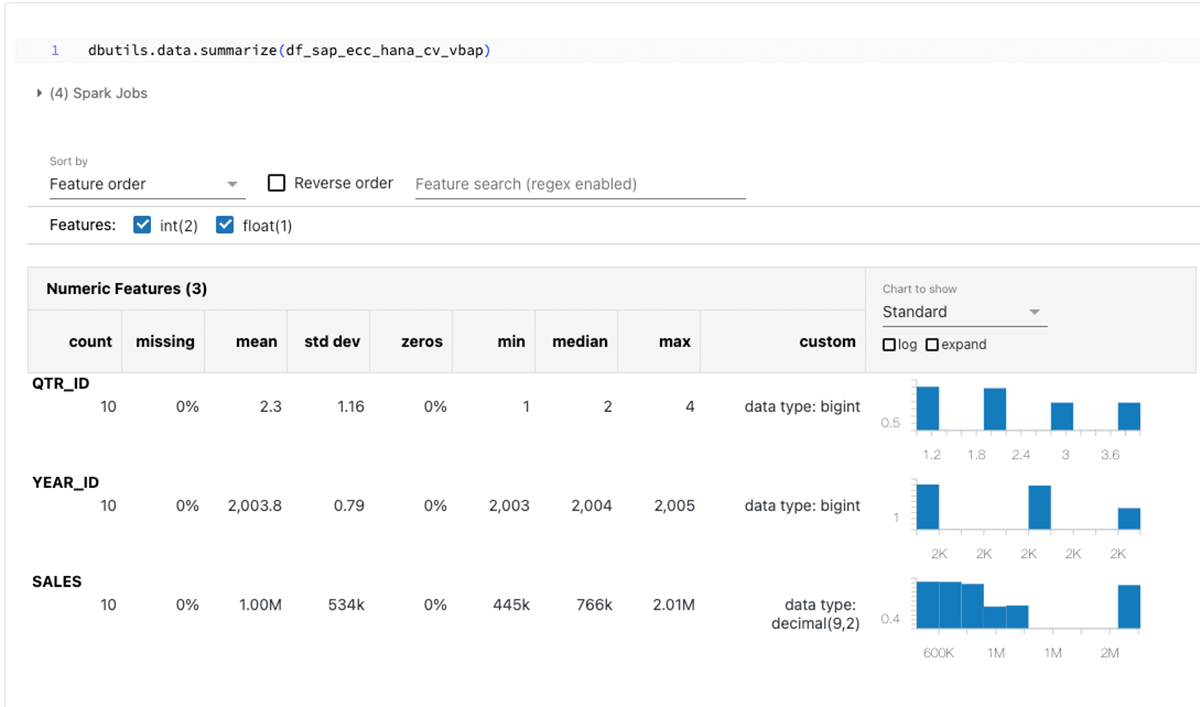
このコードスニペットは、PySparkデータフレーム「df_sap_ecc_hana_cv_vbap」を作成し、SAP HANAシステム(この場合はCV_VBAP)の計算ビューからそれを生成します。
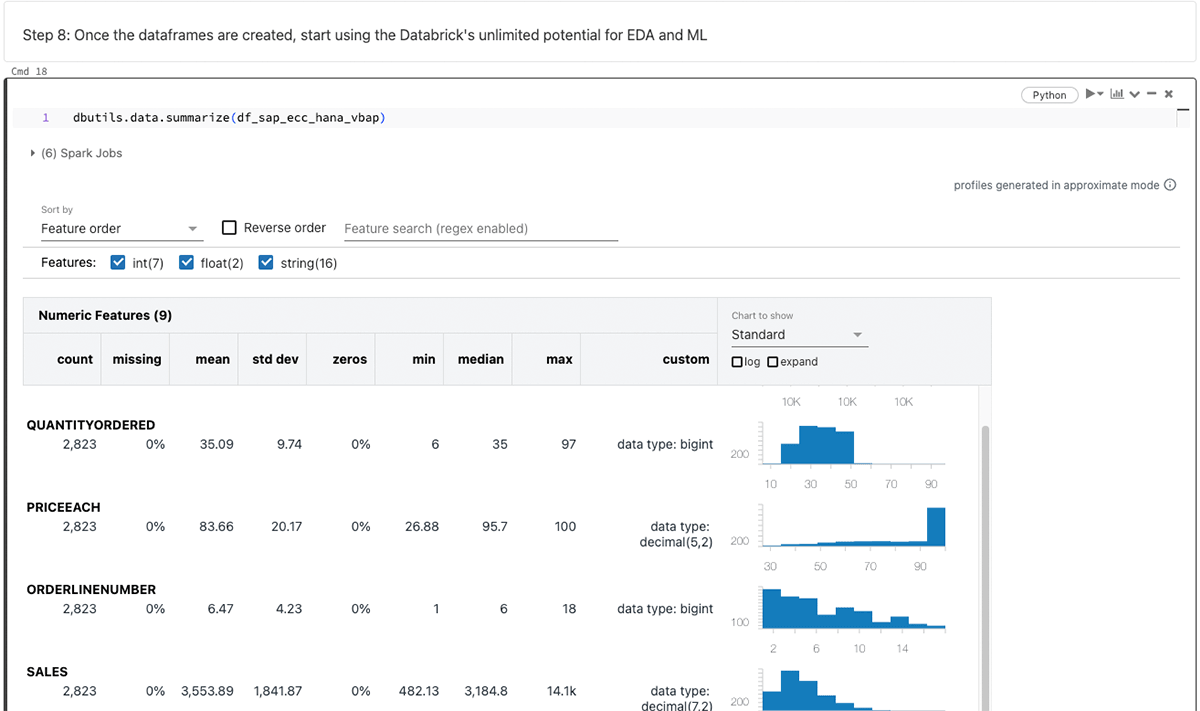
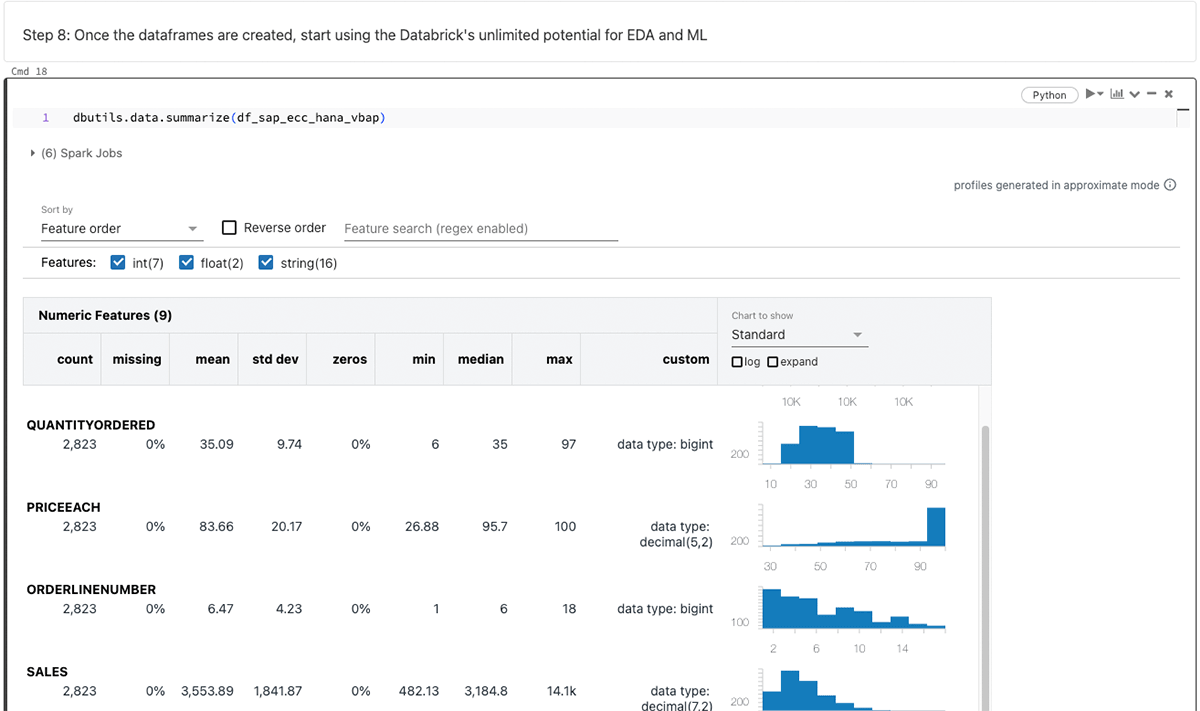
PySparkデータフレームを生成した後、Databricksの無限の機能を利用して、探索的データ分析(EDA)および機械学習/人工知能(ML/AI)を実行します。
上記のデータフレームを要約します。
{kind=link}
このブログの焦点はSAP HANA用のSparkJDBCを中心に展開していますが、同様の目的でFedML、hdbcli、およびhana_mlなどの代替方法も利用可能であることに注意してください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。